Tensorflow + Caffe + Torch 的详细安装指南(GPU版本)
1.TensorFlow的安装
补充说明:
TensorFlow的安装主要参考的是下面这个网站:
网址:http://blog.csdn.net/v_july_v/article/details/52658965
(非常感谢~)
这个网站中的配置为:
GTX 1070 cuda 8.0 Ubuntu 14.04 cudnn 5.1 tensorflow gpu
由于使用的是 GTX1070 所以必须下载 cuda8.0!其他低版本的GPU可以下载以前的cuda!网上很多教程说必须下载 cudnn v4 的版本,但是我的实测表明 v5 的版本也是可以的!
步骤主要参考tensorflow的官网(任何安装还是都要先看一下官网~):
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/g3doc/get_started/os_setup.md
1.1 首先安装一些tensorflow必须的依赖包(与python有关)
$ sudo apt-get install python-pip python-dev Python-scipy Pythoy-numpy Git1.2 下载tensorflow的软件包 (一定要下载GPU版本的!)
官网提示,在安装了上述的软件包之后就可以使用 pip 命令 下载tensorflow:
(依据自己的python版本进行选择)
# Python 2
$ sudo pip install --upgrade $TF_BINARY_URL
# Python 3
$ sudo pip3 install --upgrade $TF_BINARY_URL个人建议,可以从github上下载安装包:
$ git clone --recurse-submodules https://github.com/tensorflow/tensorflow1.3 为了能够让tensorflow使用CUDA的库,需要在环境变量中配置CUDA的路径
$ sudo gedit ~/.bash_profile
输入:
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64"
export CUDA_HOME=/usr/local/cuda
保存,之后运行下列的命令:
$ source ~/.bash_profile此时,可以验证一下tensflow是否下载安装正确:
首先,在命令行输入:$ python
出现>>>之后,依次输入以下:
>>> import tensorflow as tf
>>> hello = tf.constant('Hello, TensorFlow!')
>>> sess = tf.Session()
>>> print(sess.run(hello))
Hello, TensorFlow!
>>> a = tf.constant(10)
>>> b = tf.constant(32)
>>> print(sess.run(a + b))
42
>>>出现以上结果表明安装正确~~~
下面是tensorflow的配置和CUDA与tensorflow的连接
1.4 Bazel安装
参考网页: https://www.bazel.io/versions/master/docs/install.html

选择UBUNTU版本
注意!!! 官网上提示:
If you are running Ubuntu Wily (15.10), you can skip this step. But for Ubuntu Trusty (14.04 LTS) users, since OpenJDK 8 is not available on Trusty, please install Oracle JDK 8:
如果是15.10以上的版本要安装的是OpenJDK 8, 而由于14.04版本没有包含OpenJDK 8,只能够安装Oracle JDK 8版本,步骤如下(仅限于Ubuntu14.04版本):
1) Install JDK 8
$ sudo add-apt-repository ppa:webupd8team/java
$ sudo apt-get update
$ sudo apt-get install oracle-java8-installer2) Add Bazel distribution URI as a package source (one time setup)
$ echo "deb [arch=amd64] http://storage.googleapis.com/bazel-apt stable jdk1.8" | sudo tee /etc/apt/sources.list.d/bazel.list
$ curl https://storage.googleapis.com/bazel-apt/doc/apt-key.pub.gpg | sudo apt-key add –3) Update and install Bazel
$ sudo apt-get update && sudo apt-get install bazel
$ sudo apt-get upgrade bazel4) Install other required packages
$ sudo apt-get install pkg-config zip g++ zlib1g-dev unzip5) 下载Bazel的包并使用Installer安装
网址: https://github.com/bazelbuild/bazel/releases
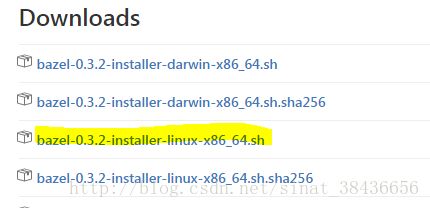
下载linux-x86_64的版本!
6) 安装Bazel
将下载的Bazel安装包放在/home目录下,在命令行输入:
$ chmod +x PATH_TO_INSTALL.SH
$ ./PATH_TO_INSTALL.SH --user注意,这里的PATH_TO_INSTALL.SH要改为我们下载的安装包的名称(进入/home文件夹下,输入B按Tab键会自动补全名称!)
7) 安装好之后,接着下载一些必要的依赖包
# For Python 2.7:
$ sudo apt-get install python-numpy swig python-dev python-wheel
# For Python 3.x:
$ sudo apt-get install python3-numpy swig python3-dev python3-wheel8) 安装numpy库
git clone git://github.com/numpy/numpy.git numpy1.5 Tensorflow安装
安装好的Tensorflow会在home下有一个独立的文件夹,在命令行下进入Tensorflow所在的目录,输入如下的命令进行配置
$ ./configure出现如下的内容,按要求回答问题:
Please specify the location of python. [Default is /usr/bin/python]: (python的默认地址不用改)
Do you wish to build TensorFlow with Google Cloud Platform support? [y/N] N
No Google Cloud Platform support will be enabled for TensorFlow
Do you wish to build TensorFlow with GPU support? [y/N] y (选择使用GPU!)
GPU support will be enabled for TensorFlow
Please specify which gcc nvcc should use as the host compiler. [Default is /usr/bin/gcc]:
Please specify the Cuda SDK version you want to use, e.g. 7.0. [Leave empty to use system default]: 7.5 (这里依据安装的CUDA版本填写,我的是7.5)
Please specify the location where CUDA 7.5 toolkit is installed. Refer to README.md for more details. [Default is /usr/local/cuda]: (CUDA的默认地址,不用改)
Please specify the cuDNN version you want to use. [Leave empty to use system default]: 5(我的cudnn是v5的版本)
Please specify the location where cuDNN 5 library is installed. Refer to README.md for more details. [Default is /usr/local/cuda]: (默认地址,不用改)
Please specify a list of comma-separated Cuda compute capabilities you want to build with.
You can find the compute capability of your device at: https://developer.nvidia.com/cuda-gpus.
Please note that each additional compute capability significantly increases your build time and binary size.
[Default is: “3.5,5.2”]: 3.0 (写3.0也可以)
Setting up Cuda include
Setting up Cuda lib
Setting up Cuda bin
Setting up Cuda nvvm
Setting up CUPTI include
Setting up CUPTI lib64
Configuration finished
1.6使用Bazel配置一些CUDA和PIP的环境
$ bazel build -c opt //tensorflow/tools/pip_package:build_pip_package
# To build with GPU support:
$ bazel build -c opt --config=cuda //tensorflow/tools/pip_package:build_pip_package
$ bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
# The name of the .whl file will depend on your platform.
$ sudo pip install /tmp/tensorflow_pkg/tensorflow-0.11.0rc0-py2-none-any.whl
(注意: 这里tensorflow-0.11.0rc0-py2-none-any.whl版本要依据自己的定,如果并不知道自己的Tensflow是什么版本,可以先安装下面一个步骤,下面一个步骤装完会显示例如“tensorflow-0.11.0rc0-py2”这样的版本)
1.7设置一些Tensflow中的python环境
bazel build -c opt //tensorflow/tools/pip_package:build_pip_package
# To build with GPU support:
bazel build -c opt --config=cuda //tensorflow/tools/pip_package:build_pip_package
mkdir _python_build
cd _python_build
ln-s ../bazel-bin/tensorflow/tools/pip_package/build_pip_package.runfiles/org_tensorflow/* .
ln-s ../tensorflow/tools/pip_package/* .
python setup.py develop1.8 Tensorflow的GPU训练测试(检测能否用GPU加速)
$ cd tensorflow/models/image/mnist
$ python convolutional.py显示:
Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes.
Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes.
Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes.
Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes.
Extracting data/train-images-idx3-ubyte.gz
Extracting data/train-labels-idx1-ubyte.gz
Extracting data/t10k-images-idx3-ubyte.gz
Extracting data/t10k-labels-idx1-ubyte.gz
Initialized!
Epoch 0.00
Minibatch loss: 12.054, learning rate: 0.010000
Minibatch error: 90.6%
Validation error: 84.6%
Epoch 0.12
Minibatch loss: 3.285, learning rate: 0.010000
Minibatch error: 6.2%
Validation error: 7.0%
补充: Tflearn的安装
Tflean是一个集成度很高的用于在Tensorflow中用于搭建CNN等网络的工具。
网址:tflearn.org (点击左侧的installation)
输入:$ sudo pip install tflearn
2.Caffe 的安装
2.1 caffe 的安装主要参考caffe的官网:
安装指南: http://caffe.berkeleyvision.org/installation.html
1.首先,安装一些caffe使用的依赖库:

由于我们使用的是UBUNTU14.04的系统,所以选择UBUNTU installation这个选项。
接着,安装一些必要的依赖库:
$sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler
$sudo apt-get install --no-install-recommends libboost-all-dev再接着,安装BLAS:
BLAS:
install ATLAS by sudo apt-get install libatlas-base-dev or install OpenBLAS or MKL for better CPU performance.
其中,$ sudo apt-get install libatlas-base-dev 安装的是ATLAS,也可以选择安装OpenBLAS或者MKL,MKL的性能比ATLAS好,但是安装麻烦,安装好之后需要配置环境变量,如果需要安装MKL,可以采用下面的方式(这里我安装的是ATLAS):
首先,下载并安装英特尔® 数学内核库 Linux* 版MKL,下载链接是:
https://software.intel.com/en-us/intel-education-offerings,
请下载Student版,先申请,然后会立马收到一个邮件(里面有安装序列号),打开照着下载就行了。下载完之后,要把文件解压到home文件夹(或直接把tar.gz文件拷贝到home文件夹,为了节省空间,安装完记得把压缩文件给删除喔~),或者其他的ext4的文件系统中。
接下来是安装过程,先授权,然后安装:
$ tar zxvfparallel_studio_xe_2015_update3.tgz(如果你是直接拷贝压缩文件过来的)
$ chmod a+xparallel_studio_xe_2015_update3 –R
$ sudo /home/ls/ parallel_studio_xe_2015_update3/install_GUI.sh
安装序列号:SKCG-XCR7XLXXMKL的环境变量配置:
首先,新建intel_mkl.conf, 并编辑之:
$ sudo gedit /etc/ld.so.conf.d/intel_mkl.conf
/opt/intel/lib/intel64
/opt/intel/mkl/lib/intel64完成Lib文件的连接操作,执行:
$ sudo ldconfig –v2.2Caffe软件的安装
首先,我们需要去caffe的github官网下载caffe的文件:
$ git clone git://github.com/BVLC/caffe.git等待安装好了之后,进入caffe文件所在的目录(一般安装好之后,会在主文件加下出现一个caffe的文件夹,在命令行想要进入这个文件夹就输入: cd /home/audi/caffe , audi是我们自己的电脑账户名,需要依情况修改)
$ cp Makefile.config.example Makefile.config上面一句话是复制一份caffe的配置文件,在配置文件里面可以修改一些配置,复制好了之后,进入配置文件Makefile.config配置:
$ vi Makefile.config打开配置文件,里面是这样的:







以上是Makefile.config中所有需要配置的选项的说明,在官网上给出了如下的说明:
For CPU & GPU accelerated Caffe, no changes are needed.
For cuDNN acceleration using NVIDIA’s proprietary cuDNN software, uncomment the USE_CUDNN := 1 switch in Makefile.config. cuDNN is sometimes but not always faster than Caffe’s GPU acceleration.
For CPU-only Caffe, uncomment CPU_ONLY := 1 in Makefile.config.
如果是使用CPU和GPU加速的电脑,配置文件可以不用修改(修改的方式,哪个需要就将后面的值变为1,然后前面的#去掉),如果使用cudnn,那么就将配置文件里面第一行的USE_CUDNN前的#去掉。如果没有GPU的话就只将第二行的中的CPU_ONLY前的#去掉,修改完毕之后,输入:,然后输入wq保存文件。
修改完配置文件之后,执行以下的3句话:
$make all
$make test
$make runtest能够顺利编译通过就没有什么问题了,如果提示一些类似于找不到lib之类的,可能是前面的cudnn和CUDA的环境变量没有配置好,如果想再次修改配置文件但是修改完之后执行make这三句话出错,建议去主文件夹下将caffe删除,再下载一次,然后重新配置。
如果以上环节都没有问题,那么通过下面的mnist例子就可以试验caffe安装的有效性了:
首先,获取mnist数据(注意,新版的caffe所有的命令执行必须在caffe/这个根目录下!!!)
$ cd /home/audi/caffe
$ sh ./data/mnist/get_mnist.sh然后,将下载的数据转换成能够在caffe中使用的lmdb格式:
$ sh ./examples/mnist/create_mnist.sh最后,开始,训练cnn,注意:在这个mnist的文件下有个配置文件lenet_solver.prototxt,这个文件里面最后一行会规定使用的是CPU还是GPU,一定要依据情况做修改(默认是GPU)
$ cd caffe/examples/mnist
$ vi lenet_solver.prototxt拉到文件的最后一行,将solver_mode修改成:
solver_mode: GPU (只有CPU,这里就写成CPU)配置好了之后就可以开始训练网络了,回到caffe根目录下:
$ sh ./examples/mnist/train_lenet.sh会出现以下的训练过程:

这就表示,caffe安装成功了,并且GPU也可以用了~~~
再接着,可以选择安装Python:
Python (optional): if you use the default Python you will need to :
$ sudo apt-get install python-devpackage to have the Python headers for building the pycaffe interface.
补充:
caffe中python环境的安装:
1) 安装pycaffe必须的一些依赖项:
$sudo apt-get install -y python-numpy python-scipy python-matplotlib python-sklearn python-skimage python-h5py python-protobuf python-leveldb python-networkx python-nose python-pandas python-gflags Cython ipython
$ sudo apt-get install -y protobuf-c-compiler protobuf-compiler2) 切换到Caffe的文件夹,生成Makefile.config配置文件,执行:
$ cd /caffe-master
$ cp Makefile.config.example Makefile.config3) 配置Makefile.config文件(仅列出修改部分)
$ sudo gedit /caffe-master/Makefile.config
a. 配置一些引用文件(增加部分主要是解决新版本下,HDF5的路径问题)可以验证一下路径是否正确
INCLUDE_DIRS:=$(PYTHON_INCLUDE)/usr/local/include/usr/lib/x86_64-linux-gnu/hdf5/serial/include
LIBRARY_DIRS := $(PYTHON_LIB)/usr/local/lib /usr/lib /usr/lib/x86_64-linux-gnu/hdf5/serialb. 配置路径,实现caffe对Python接口的支持
PYTHON_LIB := /usr/local/lib(在新版的caffe中,打开Makefile配置文件,python的路径都是默认设定好的,看看有关Python路径配置前的#有没有去掉,另外,如果用的是Anaconda来配置python的环境,则需要先下载安装Anaconda,然后在caffe的配置文件里面也要选择python的路径为Anaconda的路径!我这里没有使用Anaconda!所以配置文件里python的路径为python2.7的所在路径!)
4) 编译caffe!
“-j8”是使用CPU的多核进行编译,可以极大地加速编译的速度,建议使用。
$ make all-j8 (这个是配置完所有的caffe文件之后的一个步骤!!!)
$ make test-j8
$ make runtest -j8编译Python用到的caffe文件
$ make pycaffe -j8 (注意,配置完caffe的python环境之后,一定要make一下pycaffe!)如果遇到warning,make:*[build_release/src/caffe…..]error问题可不用管
5) 此时,在Python中还无法连接到caffe的环境,我们需要将caffe的环境放入python的路径中(把环境变量放入 ~./bashrc文件中):
$ sudo vi ~./bashrc
将一下两句添加到文件中:
export PYTHONPATH=~/caffe/python
export JAVA_HOME=”~/caffe/python”
最后,让文件生效:
$ source ~./bashrc6) 最后,在终端输入python,然后import caffe 成功,OK!
最后,安装一些lib的包(注意,官网上提示说CUDA8.0只适用于UBUNTU16.04,而UBUNTU14.0底下所有的依赖包都已经打包好了,可以直接下载,我们使用的是UBUNTU14.04,所以直接运行下面的命令):
$ sudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev最后,OPenCV也是caffe编译必须用到的库,我们也需要安装:
首先,下载安装脚本:https://github.com/bearpaw/Install-OpenCV
然后,进入文件的目录:Install-OpenCV/Ubuntu/2.4 (这里下载的是2.4.10所以目录是2.4)
执行脚本:
$ sh sudo ./opencv2_4_10.sh补充:1. 安装python中一些必要的库
(都是为了后续能够在caffe中使用R-CNN图像识别库安装的一些python库)
Python在科学计算的应用越来越丰度,而hdf(5)数据的应用也非常广泛。python提供了h5py包供开发者处理数据(hdf(5)数据是在著名的图像识别程序:R-CNN/Fast-RCNN/Faster-RCNN中使用的数据格式):
网址: http://www.h5py.org/
(1)使用: sudo apt-get install python-pip 安装 pip 工具,然后使用 pip install numpy 和 pip install numpy 安装基本环境。
(2)使用: sudo apt-get install libhdf5-dev 安装 hdf 的开发库(重要)。否则会报出:
#include “hdf5.h”
compilation terminated.
error: command ‘gcc’ failed with exit status:1(3)安装HDF5: 按照官方文档的说明就可以
地址:
ftp://ftp.hdfgroup.org/HDF5/current/src/unpacked/release_docs/INSTALL
首先,下载HDF5的安装包:
地址: ftp://ftp.hdfgroup.org/HDF5/current/src

下载.tar.gz格式的文件。
然后,执行:
$ tar zxf hdf5-X.Y.Z.tar.gz (X.Y.Z表示hdf5的版本号)
$ cd hdf5-X.Y.Z
$ ./configure --prefix=/usr/local/hdf5
$ sudo make
$ sudo make check # run test suite.
$ sudo make install
$ sudo make check-install # verify installation.(4)使用:sudo pip install h5py 安装h5py库, 当你看到 Successfully install h5py. Cleaning up…就大功告成了。
2.安装 R-CNN需要使用的一些python库
Selective Search
选择性搜索,选择性搜索综合了蛮力搜索(exhaustive search)和分割(segmentation)的方法,意在:找出可能的目标位置来进行物体的识别。
安装的网址: https://github.com/AlpacaDB/selectivesearch
安装语句: $ pip install selectivesearch
3.SVM分类器的包
安装语句: $ pip install sklearn
3.Torch安装
Torch 的安装地址: https://github.com/torch/torch7
Torch 的安装教程: http://torch.ch/docs/getting-started.html
安装步骤:
1.ubuntu终端窗口输入(以下所有命令均在root用户下执行):
apt-get update (更新源)
2.打开搭建 torch7 网址
git clone https://github.com/torch/distro.git ~/torch --recursive (克隆torch到~/torch文件下)
cd ~/torch; bash install-deps; (执行install-deps)
./install.sh (执行程序)
source ~/.bashrc (Ubuntu14.04一般情况执行这个,更新.bashrc文件)
source ~/.zshrc (不放心了把这个也执行了)
如果用Lua5.2就执行如下,没有就跳过
第一个git忽略,开始搭建时候已经下载过了
cd ~/torch (进入torch文件)
./clean.sh (执行clean.sh)
TORCH_LUA_VERSION=LUA52 ./install.sh(执行命令)
luarocks install image (安装image)
luarocks list (安装list)
th (测试能否用torch7,出现如上图标志,表示能用)如果在安装过程中出现 torch7 的环境变量未能添加到PATH内,解决办法如下:
在终端输入:
vi /etc/profile
进入文件后,在最后添加如下命令:
PATH=~/torch/install/bin:$PATH按Esc 接着输入: q (退出)
执行 source /etc/profile (更新一下)