大数据系列之Sqoop(十、大数据ETL工具Sqoop)
Sqoop是用来做什么的
Sqoop官网是这样介绍:
Apache Sqoop(TM) is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured
datastores such as relational databases.
就是说Sqoop是一款用来在Hadoop(Hive)和关系型数据库之间传输数据的工具。
Sqoop在Hadoop生态中的位置:
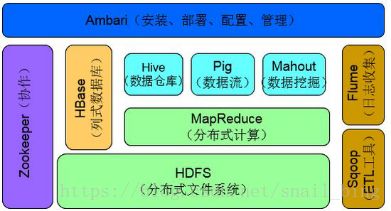
功能概述:
主要用于在HDFS/Hive与关系型数据库(Mysql、Oracle、SQLserver、...)之间进行数据的传输,可以将一个关系型数据库中的数据导入到HDFS(Hive)中,也可以将HDFS中的数据导入到关系型数据库中。
安装配置
1、下载安装包,上传到服务器,解压安装包(官方建议生产环境最好不要使用Sqoop2相应版本,建议使用1.4.x版本),官方解释:
Latest stable release is 1.4.7. Latest cut of Sqoop2 is 1.99.7. Note that 1.99.7 is not compatible with 1.4.7 and not
feature complete, it is not intended for production deployment.
2、配置环境变量,在系统环境变量中配置即可。
export SQOOP_HOME=[path]
export PATH=$PATH:$SQOOP_HOME/bin3、刷新环境变量
source /etc/profile4、配置Sqoop,在${SQOOP_HOME}/conf中执行命令:
mv sqoop-env-template.sh sqoop-env.sh修改配置文件sqoop-env.sh
export HADOOP_COMMON_HOME=[hadoopPath]
export HADOOP_MAPRED_HOME=[hadoopPath]
export HIVE_HOME=[hivePath]使用Sqoop
Sqoop参数说明
--connect:连接数据库
--username:数据库登录名
--password:数据库登录密码
--table:导入哪张表,表名要大写
--target_dir:导出目录使用 --query 必填
--columns:导出指定列
--delete-target-dir:如果目标目录存在,则删除。如果不设置这个,目标目录存在则会报错
--direct:直接导入模式,使用的是关系数据库自带的导入导出工具。官网上是说这样导入会更快
--verbose:打印详细日志
--split-by:按字段分割map,结合参数m进行使用
--hive-import:导入数据至hive
--null-string:源表数据字段为字符且为空时,用指定字符代替
--null-non-string:源表数据字段不为字符且为空时,用指定字符代替
--hive-overwrite:覆盖导入,全覆盖
--m:几个并发任务同时执行默认4
--where:过滤条件
--query:查询导入,where后边必须$CONDITIONS
--check-column(col):用来作为判断的列名,如id
--incremental(mode) append:追加,比如对大于last-value指定的值之后的记录进行追加导入。lastmodified:最后的修改时间,追加last-value指定的日期之后的记录
–last-value (value):指定自从上次导入后列的最大值(大于该指定的值),也可以自己设定某一值。
关系型数据库数据导入HDFS/HIVE
列出Mysql数据库中的所有库:
sqoop list-databases --connect jdbc:mysql://localhost:3306 --username xxx --password xxx 列出数据库中某库中所有表:
sqoop list-tables --connect jdbc:mysql://127.0.0.1/[库名] --username xxx --password xxx直接导入数据到Hive:
sqoop import --hive-import --connect jdbc:oracle:thin:@localhost:1521:dbName
--username xxx
--password xxx
--verbose -m 1
--table tableName
--hive-database hiveDbName
导入指定字段并加入过滤条件:
sqoop import --hive-import --connect jdbc:oracle:thin:@localhost:1521:dbName
--username xxx
--password xxx
--verbose -m 1
--table tableName
--columns "id,name,age"
--where "start_date > '2018-01-01'"
--hive-database hiveDbName
--hive-table hiveTableName创建一个具有相同名字和相同表结构的表:
sqoop create-hive-table --connect jdbc:oracle:thin:@//localhost:1521/dbName
--username xxx
--password xxx
--table tableNamesqoop增量导入:
sqoop import --hive-import --connect jdbc:oracle:thin:@xxxxx:31521/dbName
--username xxx --password xxx --verbose -m 1
--table tableName
--hive-database hiveDbName
--hive-table hiveTableName
--incremental lastmodified|append #两种模式
--check-column CREATE_TIME #CREATE_TIME必须是日期类型
--last-value '2012-06-02 00:00:00' #第一次导入的下界,从第二次开始,sqoop会自动更新该值为上一次导入的上界sqoop导出数据到Mysql数据库
sqoop-export --connect jdbc:mysql://localhost:3306/dbName
--username xxx --password xxx
--table tableName
--update-key clxxbh
--update-mode allowinsert
--export-dir /hive/warehouse/logdb.db/dataclear
--input-fields-terminated-by '|'
--columns"id,url,referer,keyword,type,guid,pageId,moduleId,linkId"参数说明:
--connect:要导入数据库的地址和库名(mysql)。
--username:数据库登录名(mysql)。
--password:数据库登录密码(mysql)。
--table:要导入的表名(mysql的表)。
--update-key clxxbh:表示如果后期导入的数据关键字和MySQL数据库中数据存在相同的,则更新该行记录。
--update-mode allowinsert:表示将目标数据库中原来不存在的数据也导入到数据库 表中,即存在的数据保留,新的数据插入,它后接另一个参数是updateonly,即只 更新数据,不插入新数据。
--export-dir:要导出的数据在hdfs中的路径。
--input-fields-terminated-by '|':根据什么分隔数据。
--columns:要导出的字段。
注意:
1、不能直接从hive表里导出(不能--hive-table),只能从hdfs导出。
2、必须指定字段--columns。
3、字段分割符号要和hdfs文件里的一致 --fields-terminated-by '|'。