图表示学习入门3——图神经网络
图神经网络(Graph Neural Network)在社交网络、推荐系统、知识图谱上的效果初见端倪,成为近2年大热的一个研究热点。然而,什么是图神经网络?图和神经网络为什么要关联?怎么关联?
本文将以浅显直觉的方式,介绍GNN的灵感来源,构造方法,训练方式等,参考《Representation Learning on Networks》中GNN部分,做了具体的解读和诠释,并增补了一些代码中才有的实现细节,帮助初学者理解。
代码实现:(https://github.com/leichaocn/graph_representation_learning)
文章目录
- 卷积神经网络的启示
- 核心想法
- 传播机制
- 传播机制举例
- 基础版本
- 图卷积网络(Graph Convolutional Networks)
- GraphSAGE
- 训练的方式
- 无监督的训练
- 有监督的训练
- 一般的设计步骤
- Node2Vec与GNN的对比
- 总结
- 参考文献
卷积神经网络的启示
回顾对图像的简单卷积:

如图1所示:一幅图(image)所抽取的特征图(features map)里每个元素,可以理解为图(image)上的对应点的像素及周边点的像素的加权和(还需要再激活一下)。
同样可以设想:一个图(graph)所抽取的特征图(也就是特征向量)里的每个元素,也可以理解为图(graph)上对应节点的向量与周边节点的向量的加权和。
这种迁移联想值得好好体会。
体会明白后,那具体怎么做呢?
核心想法
正如上面讨论的,归纳为一句话:用周围点的向量传播出自己的Embedding。
一个非常简单的例子就能搞明白。

对于图2来说,要求节点A的Embedding,我们有以下的两条想法:
- 节点A的Embedding,是它的邻接节点B、C、D的Embedding的前向传播的结果
- 而节点B、C、D的Embedding,又是由它们各自的邻接节点的Embedding传播的结果。
但是你可能会说,这样不断追溯,何时能结束?所以为了避免无穷无尽,我们就搞上面这两层就行了。
根据上面的讨论,我们可以构造图3的传播关系。
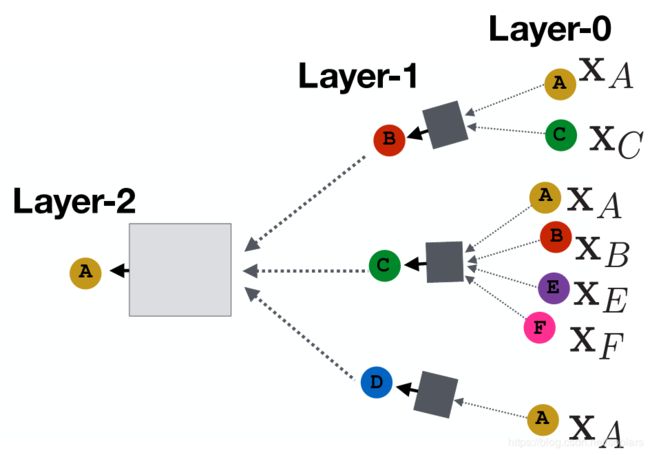
第0层即输入层,为每个节点的初始向量(根据所处领域里特征数据进行构建),不妨称为初始Embedding。
-
第一层
节点B的Embedding来自它的邻接点A、C的Embedding的传播。
节点C的Embedding来自它的邻接点A、B、C、D的Embedding的传播。
节点D的Embedding来自它的邻接点A的Embedding的传播。
-
第二层
节点A的Embedding来自它的邻接点B、C、D的Embedding的传播。
好了,大概可能有点感觉了,可是传播到底是什么?图中的小方块里到底在什么什么?
(注意:图中所有的方块代表的操作均相同,大小、颜色的差异没有任何含义)
传播机制
小方块里做的就两件事:
-
收集(Aggregation)
简言之,就是对上一层的所有邻接节点的Embedding,如何进行汇总,获得一个Embedding,供本层进行更新。
-
更新(Update)
即对本层已“收集完毕”的邻接点数据,是否添加自身节点的上一层Embedding,如果是如何添加,如何激活,等等方式,最终输出本层的Embedding。
表达成数学公式,即下面这个式子:

先解释其中的符号含义: h h h表示节点的Embedding,下标 v v v或 u u u表示节点的索引,上标 k k k表示第几层的意思, σ \sigma σ表示激活函数, W k W_k Wk和 B k B_k Bk表示矩阵, N ( v ) N(v) N(v)表示节点 v v v的邻接点集合, A G G ( ⋅ ) AGG(\cdot) AGG(⋅)表示收集操作。
这个公式其实就做了两件事:
- 收集:即 A G G ( ⋅ ) AGG(\cdot) AGG(⋅)部分
- 更新:等号右边除了 A G G ( ⋅ ) AGG(\cdot) AGG(⋅)的其他部分。
这个公式毕竟太抽象,我们不如举例说明,看看常见的图神经网络的传播具体是如何设计的。
传播机制举例
基础版本

收集即直接对上一层所有节点的Embedding求平均。更新即为用收集完毕的Embedding与本节点上一层的Embedding进行了加权和,然后再激活。显然,由于上一层Embedding与本层Embedding维度相同,所以 W k W_k Wk和 B k B_k Bk为方阵。
图卷积网络(Graph Convolutional Networks)

有意思了,观察下有哪些变化。
由 u ∈ N ( v ) ∪ v u\in N(v)\cup v u∈N(v)∪v可知,收集的输入Embeddings不仅仅包括节点 v v v的邻接点们的Embedding,还包括节点 v v v自身的Embedding,而分母变成了 ∣ N ( u ) ∣ ∣ N ( v ) ∣ \sqrt{\mid N(u) \mid \mid N(v) \mid} ∣N(u)∣∣N(v)∣,是一种更复杂的加权和,不仅考虑了节点 v v v的邻接点的个数,还考虑了每个邻接点 u u u自身的邻接接个数。(基础版本中的平均是最简单的加权和)
更新显然比基础版本简单多了,不再考虑节点 v v v自己的上一层Embedding,直接让收集好的Embedding乘上矩阵 W k W_k Wk后再激活完事。
GraphSAGE
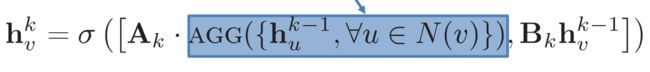
这不就是咱们上面提到的那个概念公式?是的,GraphSAGE由于其变体较多,所以需要用这个最抽象的公式来概括它。
先说更新部分,收集好的Embedding经过矩阵 A k A_k Ak变换,节点 v v v自己上一层的Embedding经过矩阵 B k B_k Bk变换,我们即可得到两个Embedding,把它俩给按列拼接起来。
这里要注意:它俩不是相加;矩阵 A k A_k Ak和矩阵 B k B_k Bk都不是方阵,均自带降维功能。 A G G ( ⋅ ) AGG(\cdot) AGG(⋅)输出是 d d d维, h v k − 1 h^{k-1}_v hvk−1是 d d d维,但是经过军阵变换后,它俩都成了 d / 2 d/2 d/2维,经过拼接,又恢复成 d d d维。
再说说收集部分,你可以有如下的收集方式。
1)直接平均,这是最简单的收集方式
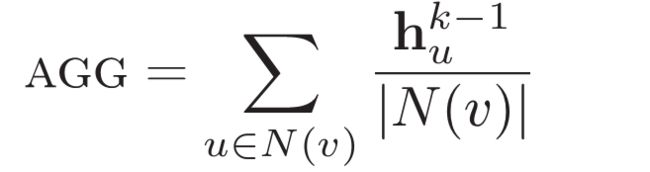
2)池化

3)LSTM
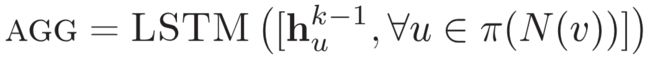
训练的方式
无监督的训练
跑不同的Aggregation和Update方法,结合自定义的损失函数,都可以训练出这些权重。这里的自定义损失函数,需要根据你对节点Embedding的最终期望,让它附加上一个什么样的效果来设计。
在无监督任务中,获取经过神经网络优化的Embedding,就是我们的目的。
有监督的训练
如果我们想要实现节点分类,那么我们就需要有带标签的训练数据,设计损失函数,即可进行训练。
例如,我们有一批带label的图结构的数据,已经标记好了哪些是水军,哪些是普通用户。我们就可以构造如下的交叉熵损失函数。
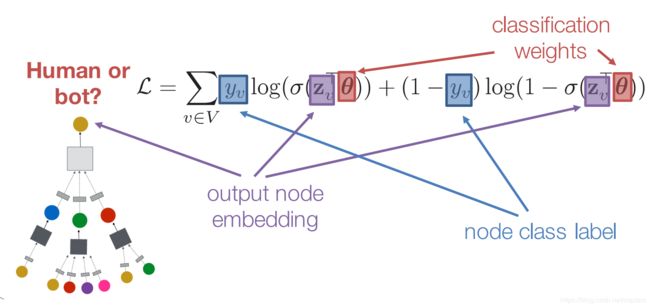
-
转换矩阵
注意其中的 z v z_v zv即节点 v v v的Embedding, y v y_v yv是节点 v v v的label,那 θ \theta θ是什么鬼?
如刚才我们讨论的,图神经网络的传播结果,是所有节点经过“传播”优化的Embedding,这些Embedding的维度均为 d d d维(在初始化时定义好的),而我们分类任务可能是 c c c类,所以,需要再前向传播的最后一层,加入矩阵,把 d d d维的输出映射成 c c c维的输出,这样才能让交叉熵损失函数对应起来。
由于我们列举的是二分类任务,图4中也用的是二分类的交叉熵损失,因此只需要1维输出足矣,所以在这里的 c c c为1, θ \theta θ为一个向量(可视为把 d d d维压缩为1维的特殊矩阵)。
在有监督任务中,获取经过神经网络优化的Embedding,还需要进行分类。所以Embedding不是目的,只是实现分类的手段。
一般的设计步骤
综上,各类图神经网络架构主要区别是:
- 传播机制的区别,即收集和更新的设计(图3中小方块)。
- 有无监督及损失函数的区别。
设计图神经网络的一般步骤是:
- 定义收集与更新方式。
- 定义损失函数。
- 在一批节点上进行训练。
- 生成Embedding,即使是模型未见过的Embedding,模型也可以对其初始化Embedding进行“传播优化”。
Node2Vec与GNN的对比
由于Embedding这个术语被我以广义的方式,用了太多次,很容易导致混淆,所以这里对Embedding在不同状态时做一个总结。

总结
-
图神经网络是以邻接点Embedding的浅层传播来训练Embedding。
-
改变Aggregation和update的方式,可以构造不同的图神经网络;
-
既可以用无监督的方式获得Embedding,也可以用有监督的方式直接训练分类任务。
参考文献
[1] Jure Leskovec, 《Graph Representation Learning》
[2] Jure Leskovec, 《Representation Learning on Networks》
http://snap.stanford.edu/proj/embeddings-www/