log::Reader-levelDB源码解析
要想理解reader,需要理解两个概念,即逻辑记录,物理记录,这个log format有讲
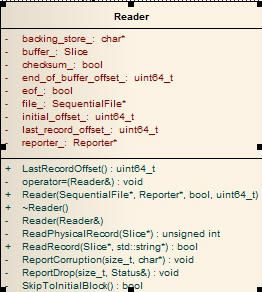
【数据成员介绍】
blocking_store_:read以block为单位去从磁盘取数据,取完数据就是存在blocking_store_里面,其实就是读取数据的buffer;
buffer_:指向blocking_store_的slice对象,方便对blocking_store_的操作;
end_of_buffer_offset_:当前block的结束位置往后的位置;
eof_:是否读到文件尾;
file_:PosixSequentialFile对象,里面有个fopen产生的FILE*,当file_->read()时,其实就是调fread;
initial_offset_:初始指定的在整个文件中的offset;
last_record_offset_:上一条逻辑记录在整个文件中的offset;
report_:用来报告错误消息;
【方法成员介绍】
bool Reader::SkipToInitialBlock()
作用:fseek到initial_offset_指定的块的开始,为读取整个block做准备;
这个方法的思路就是通过initial_offset_,计算出initial_offset_所在block的初始位置,然后fseek到那里;
bool Reader::SkipToInitialBlock() {
//计算出在当前block中的offset
size_t offset_in_block = initial_offset_ % kBlockSize;
//计算出当前block的开始,在整个文件中的offset
uint64_t block_start_location = initial_offset_ - offset_in_block;
// 当最后只剩6个字节时,是用\x00填充的,所以要重新开始一块,这个地方我觉得应该是kBlockSize - 7
if (offset_in_block > kBlockSize - 6) {
offset_in_block = 0;
block_start_location += kBlockSize;
}
end_of_buffer_offset_ = block_start_location;
// 将offser定为到block_start_location,这里其实调的是fseek
if (block_start_location > 0) {
Status skip_status = file_->Skip(block_start_location);
if (!skip_status.ok()) {
ReportDrop(block_start_location, skip_status);
return false;
}
}
return true;
}
unsigned int Reader::ReadPhysicalRecord(Slice* result)
作用:从磁盘读取一个block,并根据header指定的data大小,保存到result;
unsigned int Reader::ReadPhysicalRecord(Slice* result) {
while (true) {
if (buffer_.size() < kHeaderSize) {
if (!eof_) {
// 上次读是一次完整的读,也就是说要么把这块读完,没读完要么继续以一个记录,但绝不会在剩余小于7个字节的时候开始一个新的头,所以这里的情况就是尾部用\x00填充的情况;
buffer_.clear();
Status status = file_->Read(kBlockSize, &buffer_, backing_store_);
end_of_buffer_offset_ += buffer_.size();
if (!status.ok()) {
buffer_.clear();
ReportDrop(kBlockSize, status);
eof_ = true;
return kEof;
} else if (buffer_.size() < kBlockSize) {
eof_ = true;
}
continue;
} else if (buffer_.size() == 0) {
// End of file
return kEof;
} else {
size_t drop_size = buffer_.size();
buffer_.clear();
ReportCorruption(drop_size, "truncated record at end of file");
return kEof;
}
}
//解析header
const char* header = buffer_.data();
const uint32_t a = static_cast
const uint32_t b = static_cast
const unsigned int type = header[6];
const uint32_t length = a | (b << 8);
if (kHeaderSize + length > buffer_.size()) {
size_t drop_size = buffer_.size();
buffer_.clear();
ReportCorruption(drop_size, "bad record length");
return kBadRecord;
}
if (type == kZeroType && length == 0) {
// Skip zero length record without reporting any drops since
// such records are produced by the mmap based writing code in
// env_posix.cc that preallocates file regions.
buffer_.clear();
return kBadRecord;
}
// 校验crc对不对
if (checksum_) {
uint32_t expected_crc = crc32c::Unmask(DecodeFixed32(header));
uint32_t actual_crc = crc32c::Value(header + 6, 1 + length);
if (actual_crc != expected_crc) {
// Drop the rest of the buffer since "length" itself may have
// been corrupted and if we trust it, we could find some
// fragment of a real log record that just happens to look
// like a valid log record.
size_t drop_size = buffer_.size();
buffer_.clear();
ReportCorruption(drop_size, "checksum mismatch");
return kBadRecord;
}
}
//注意这里,buffer_的位置已经移到下个记录的开始了
buffer_.remove_prefix(kHeaderSize + length);
// Skip physical record that started before initial_offset_
if (end_of_buffer_offset_ - buffer_.size() - kHeaderSize - length <
initial_offset_) {
result->clear();
return kBadRecord;
}
*result = Slice(header + kHeaderSize, length);
return type;
}
}
bool Reader::ReadRecord(Slice* record, std::string* scratch)
作用:读取一条逻辑记录,record指向结果,当逻辑记录的大小>kBlockSize时,结果是保存在scratch里面,否则是在blocking_store_里面,这里的目的是为了节省内存,但是对于调用者来说可能是个坑,因为scratch可能为空;
bool Reader::ReadRecord(Slice* record, std::string* scratch) {
//定位到指定block的开始,这么做是为了保证在需要的时候才调用SkipToInitialBlock()
if (last_record_offset_ < initial_offset_) {
if (!SkipToInitialBlock()) {
return false;
}
}
scratch->clear();
record->clear();
//逻辑记录是否是分片的,即逻辑记录是不是在多个block上
bool in_fragmented_record = false;
//逻辑记录的偏移量
uint64_t prospective_record_offset = 0;
Slice fragment;
while (true) {
//每个物理记录的开始
uint64_t physical_record_offset = end_of_buffer_offset_ - buffer_.size();
const unsigned int record_type = ReadPhysicalRecord(&fragment);
switch (record_type) {
case kFullType:
if (in_fragmented_record) {
//当为kFirstType、kFullType时,以前版本的bug导致拿到的内容可能为空.
if (scratch->empty()) {
//代表记录没有分段
in_fragmented_record = false;
} else {
ReportCorruption(scratch->size(), "partial record without end(1)");
}
}
//当为kFullType时,物理记录和逻辑记录1:1的关系,所以offset也是一样的;
prospective_record_offset = physical_record_offset;
//注意这里scratch为空
scratch->clear();
*record = fragment;
//逻辑记录结束,更新最近一条逻辑记录的offset
last_record_offset_ = prospective_record_offset;
//数据取完了,直接退出循环
return true;
case kFirstType:
if (in_fragmented_record) {
//当为kFirstType、kFullType时,以前版本的bug导致拿到的内容可能为空.
if (scratch->empty()) {
in_fragmented_record = false;
} else {
ReportCorruption(scratch->size(), "partial record without end(2)");
}
}
//因为是第一块,所以物理记录的offset,也是逻辑记录的offset
prospective_record_offset = physical_record_offset;
//因为是第一块,所以是assign,而不是append
scratch->assign(fragment.data(), fragment.size());
//因为是第一块,,所以这个逻辑记录肯定是分段的
in_fragmented_record = true;
break;
case kMiddleType:
if (!in_fragmented_record) {
ReportCorruption(fragment.size(),
"missing start of fragmented record(1)");
} else {
//因为是中间块,所以是append,而不是assign
scratch->append(fragment.data(), fragment.size());
}
break;
case kLastType:
if (!in_fragmented_record) {
ReportCorruption(fragment.size(),
"missing start of fragmented record(2)");
} else {
//因为是最后一块,所以是append,而不是assign
scratch->append(fragment.data(), fragment.size());
并将record的值指向scratch
*record = Slice(*scratch);
//逻辑记录结束,更新最近一条逻辑记录的offset
last_record_offset_ = prospective_record_offset;
return true;
}
break;
case kEof:
if (in_fragmented_record) {
ReportCorruption(scratch->size(), "partial record without end(3)");
scratch->clear();
}
return false;
case kBadRecord:
if (in_fragmented_record) {
ReportCorruption(scratch->size(), "error in middle of record");
in_fragmented_record = false;
scratch->clear();
}
break;
default: {
char buf[40];
snprintf(buf, sizeof(buf), "unknown record type %u", record_type);
ReportCorruption(
(fragment.size() + (in_fragmented_record ? scratch->size() : 0)),
buf);
in_fragmented_record = false;
scratch->clear();
break;
}
}
}
return false;
}