StarRocks分布式元数据源码解析
1. 支持元数据表
https://github.com/StarRocks/starrocks/pull/44276/files
核心类:LogicalIcebergMetadataTable,Iceberg元数据表,将元数据的各个字段做成表的列,后期可以通过sql操作从元数据获取字段,这个表的组成字段是DataFile相关的字段
public static LogicalIcebergMetadataTable create(String catalogName, String originDb, String originTable) {
return new LogicalIcebergMetadataTable(catalogName,
ConnectorTableId.CONNECTOR_ID_GENERATOR.getNextId().asInt(),
ICEBERG_LOGICAL_METADATA_TABLE_NAME,
Table.TableType.METADATA,
builder()
.columns(PLACEHOLDER_COLUMNS)
.column("content", ScalarType.createType(PrimitiveType.INT))
.column("file_path", ScalarType.createVarcharType())
.column("file_format", ScalarType.createVarcharType())
.column("spec_id", ScalarType.createType(PrimitiveType.INT))
.column("partition_data", ScalarType.createType(PrimitiveType.VARBINARY))
.column("record_count", ScalarType.createType(PrimitiveType.BIGINT))
.column("file_size_in_bytes", ScalarType.createType(PrimitiveType.BIGINT))
.column("split_offsets", ARRAY_BIGINT)
.column("sort_id", ScalarType.createType(PrimitiveType.INT))
.column("equality_ids", ARRAY_INT)
.column("file_sequence_number", ScalarType.createType(PrimitiveType.BIGINT))
.column("data_sequence_number", ScalarType.createType(PrimitiveType.BIGINT))
.column("column_stats", ScalarType.createType(PrimitiveType.VARBINARY))
.column("key_metadata", ScalarType.createType(PrimitiveType.VARBINARY))
.build(),
originDb,
originTable,
MetadataTableType.LOGICAL_ICEBERG_METADATA);
}2. Iceberg表扫描
https://github.com/StarRocks/starrocks/pull/44313
核心类:StarRocksIcebergTableScan,扫描Iceberg表的实现类,基于Iceberg的上层接口实现,类似Iceberg默认提供的DataTableScan,doPlanFiles中定义实际的元数据文件扫描逻辑
这一块应当属于数据上层扫描逻辑
protected CloseableIterable doPlanFiles() {
List dataManifests = findMatchingDataManifests(snapshot());
List deleteManifests = findMatchingDeleteManifests(snapshot());
boolean mayHaveEqualityDeletes = !deleteManifests.isEmpty() && mayHaveEqualityDeletes(snapshot());
boolean loadColumnStats = mayHaveEqualityDeletes || shouldReturnColumnStats();
if (shouldPlanLocally(dataManifests, loadColumnStats)) {
return planFileTasksLocally(dataManifests, deleteManifests);
} else {
return planFileTasksRemotely(dataManifests, deleteManifests);
}
} 3. Iceberg元数据信息接口
[Feature] Introduce meta spec interface by stephen-shelby · Pull Request #44527 · StarRocks/starrocks · GitHub
核心类:IcebergMetaSpec,Iceberg元数据描述,核心是RemoteMetaSplit的一个List,代表了元数据文件的列表,基于这个做分布式解析
这一块应当属于元数据文件的切片逻辑
public List getSplits() {
return splits;
} 4. Iceberg元数据扫描节点
https://github.com/StarRocks/starrocks/pull/44581
核心类:IcebergMetadataScanNode,Iceberg元数据的扫描节点,袭乘自PlanNode类,主要是把上节的RemoteMetaSplit放到StarRocks的执行结构当中
这一块属于Iceberg逻辑向StarRocks逻辑的中间转换层
private void addSplitScanRangeLocations(RemoteMetaSplit split) {
TScanRangeLocations scanRangeLocations = new TScanRangeLocations();
THdfsScanRange hdfsScanRange = new THdfsScanRange();
hdfsScanRange.setUse_iceberg_jni_metadata_reader(true);
hdfsScanRange.setSerialized_split(split.getSerializeSplit());
hdfsScanRange.setFile_length(split.length());
hdfsScanRange.setLength(split.length());
// for distributed scheduler
hdfsScanRange.setFull_path(split.path());
hdfsScanRange.setOffset(0);
TScanRange scanRange = new TScanRange();
scanRange.setHdfs_scan_range(hdfsScanRange);
scanRangeLocations.setScan_range(scanRange);
TScanRangeLocation scanRangeLocation = new TScanRangeLocation(new TNetworkAddress("-1", -1));
scanRangeLocations.addToLocations(scanRangeLocation);
result.add(scanRangeLocations);
}5. Iceberg元数据读取
https://github.com/StarRocks/starrocks/pull/44632
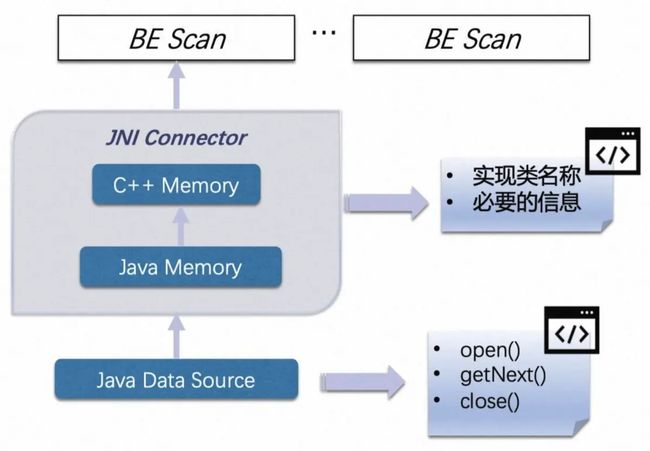
核心类:IcebergMetadataScanner,这个应该是Iceberg元数据的实际读取类,实现自StarRocks的ConnectorScanner
ConnectorScanner是StarRocks的设计的介于C++-based的BE和Java-based的大数据组件之间的JNI抽象中间层,可以直接复用Java SDK,规避了对BE代码的侵入以及使用C++访问大数据存储的诸多不便
这一块属于时实际元数据文件读取的Java侧代码
public int getNext() throws IOException {
try (ThreadContextClassLoader ignored = new ThreadContextClassLoader(classLoader)) {
int numRows = 0;
for (; numRows < getTableSize(); numRows++) {
if (!reader.hasNext()) {
break;
}
ContentFile file = reader.next();
for (int i = 0; i < requiredFields.length; i++) {
Object fieldData = get(requiredFields[i], file);
if (fieldData == null) {
appendData(i, null);
} else {
ColumnValue fieldValue = new IcebergMetadataColumnValue(fieldData);
appendData(i, fieldValue);
}
}
}
return numRows;
} catch (Exception e) {
close();
LOG.error("Failed to get the next off-heap table chunk of iceberg metadata.", e);
throw new IOException("Failed to get the next off-heap table chunk of iceberg metadata.", e);
}
}这一块目前没有找到Java侧的上层调用,应该在C++中调用,如下,其构造类是在C++中的
// ---------------iceberg metadata jni scanner------------------
std::unique_ptr create_iceberg_metadata_jni_scanner(const JniScanner::CreateOptions& options) {
const auto& scan_range = *(options.scan_range);
;
const auto* hdfs_table = dynamic_cast(options.hive_table);
std::map jni_scanner_params;
jni_scanner_params["required_fields"] = hdfs_table->get_hive_column_names();
jni_scanner_params["metadata_column_types"] = hdfs_table->get_hive_column_types();
jni_scanner_params["serialized_predicate"] = options.scan_node->serialized_predicate;
jni_scanner_params["serialized_table"] = options.scan_node->serialized_table;
jni_scanner_params["split_info"] = scan_range.serialized_split;
jni_scanner_params["load_column_stats"] = options.scan_node->load_column_stats ? "true" : "false";
const std::string scanner_factory_class = "com/starrocks/connector/iceberg/IcebergMetadataScannerFactory";
return std::make_unique(scanner_factory_class, jni_scanner_params);
} 6. 元数据收集任务
https://github.com/StarRocks/starrocks/pull/44679/files
核心类:IcebergMetadataCollectJob,Iceberg元数据的收集类,实现自MetadataCollectJob,目前看就是通过执行SQL语句,从前文的LogicalIcebergMetadataTable表当中获取数据
这一块属于最终的元数据收集
private static final String ICEBERG_METADATA_TEMPLATE = "SELECT content" + // INTEGER
", file_path" + // VARCHAR
", file_format" + // VARCHAR
", spec_id" + // INTEGER
", partition_data" + // BINARY
", record_count" + // BIGINT
", file_size_in_bytes" + // BIGINT
", split_offsets" + // ARRAY
", sort_id" + // INTEGER
", equality_ids" + // ARRAY
", file_sequence_number" + // BIGINT
", data_sequence_number " + // BIGINT
", column_stats " + // BINARY
", key_metadata " + // BINARY
"FROM `$catalogName`.`$dbName`.`$tableName$logical_iceberg_metadata` " +
"FOR VERSION AS OF $snapshotId " +
"WHERE $predicate'"; 7. 流程梳理
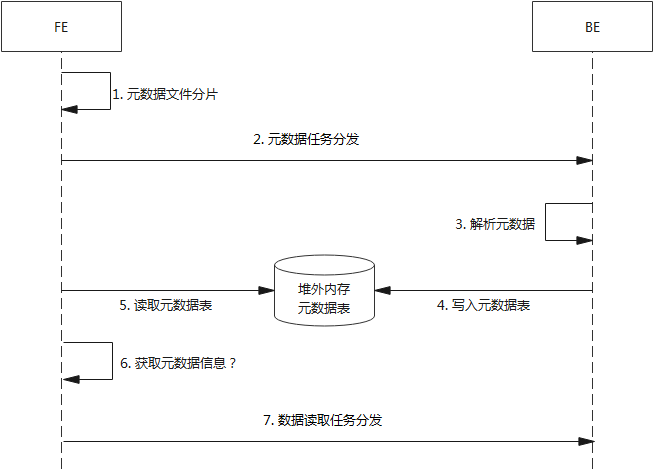
1. IcebergMetadataCollectJob的调用
IcebergMetadataCollectJob -> StarRocksIcebergTableScan.planFileTasksRemotely -> StarRocksIcebergTableScan.doPlanFiles -> 由Iceberg定义的TableScan流程触发
2. StarRocksIcebergTableScan的构建
StarRocksIcebergTableScan -> IcebergCatalog.getTableScan -> IcebergMetadata.collectTableStatisticsAndCacheIcebergSplit -> prepareMetadata()和triggerIcebergPlanFilesIfNeeded()
prepareMetadata()线路由PrepareCollectMetaTask任务触发,其执行逻辑中调用了prepareMetadata()接口。PrepareCollectMetaTask是OptimizerTask的子类,属于StarRocks优化器的一环,在Optimizer类执行优化的时候会。这一块属于CBO优化,默认是false,没找到设置成true的地方,目前应该没有启用
triggerIcebergPlanFilesIfNeeded()路线有几个调用的地方,主路线应该是getRemoteFileInfos(),其他两个看内容属于统计信息之类的信息收集
IcebergMetadata.getRemoteFileInfos -> IcebergScanNode.setupScanRangeLocations -> PlanFragmentBuilder.visitPhysicalIcebergScan -> PhysicalIcebergScanOperator
这一条调用链最终源头到PhysicalIcebergScanOperator,这个应当是IcebergScanNode经过SQL计划转换后的实际执行节点类
3. 元数据扫描
IcebergMetaSpec -> IcebergMetadata.getSerializedMetaSpec -> MetadataMgr.getSerializedMetaSpec -> IcebergMetadataScanNode.setupScanRangeLocations -> PlanFragmentBuilder.visitPhysicalIcebergMetadataScan -> PhysicalIcebergMetadataScanOperator
元数据扫描这一块源头最终走到PhysicalIcebergMetadataScanOperator,也就是IcebergMetadataScanNode对应的执行类
4. 元数据扫描和数据扫描的逻辑关系
目前整体流程在最上层就差PhysicalIcebergMetadataScanOperator和PhysicalIcebergScanOperator的逻辑关系,这个逻辑在StarRocks的SQL到执行计划的转换过程当中
往上追踪到BackendSelectorFactory,注意这里有两个扫描节点的分配策略:LocalFragmentAssignmentStrategy、RemoteFragmentAssignmentStrategy。根据类的说明,最左节点为scanNode的时候,使用LocalFragmentAssignmentStrategy,它首先将扫描范围分配给 worker,然后将分配给每个 worker 的扫描范围分派给片段实例
在LocalFragmentAssignmentStrategy的assignFragmentToWorker当中可以看到入参包含很多scanNode,追踪上层到CoordinatorPreprocessor,scanNode的来源是StarRocks的DAG图。这之后的源头就涉及到任务解析和DAG图的顺序构建,应当是先扫描元数据再扫描数据这样构建
for (ExecutionFragment execFragment : executionDAG.getFragmentsInPostorder()) {
fragmentAssignmentStrategyFactory.create(execFragment, workerProvider).assignFragmentToWorker(execFragment);
}8. 代码解析
1. 元数据扫描
-
LogicalIcebergMetadataTable
首先从PhysicalIcebergMetadataScanOperator出发,访问者模式调用接口accept,走到PlanFragmentBuilder.visitPhysicalIcebergMetadataScan
这里首先跟LogicalIcebergMetadataTable关联了起来,这里PhysicalIcebergMetadataScanOperator里包含的表是LogicalIcebergMetadataTable表
LogicalIcebergMetadataTable的初始创建根据调用链追踪应当由CatalogMgr.createCatalog触发
PhysicalIcebergMetadataScanOperator node = (PhysicalIcebergMetadataScanOperator) optExpression.getOp();
LogicalIcebergMetadataTable table = (LogicalIcebergMetadataTable) node.getTable();-
IcebergMetadataScanNode
中间经历一些列的设置,之后构建了IcebergMetadataScanNode
IcebergMetadataScanNode metadataScanNode =
new IcebergMetadataScanNode(context.getNextNodeId(), tupleDescriptor,
"IcebergMetadataScanNode", node.getTemporalClause());构建之后调用了setupScanRangeLocations,走到了IcebergMetadataScanNode的类逻辑,首先获取元数据文件的分片信息
IcebergMetaSpec serializedMetaSpec = GlobalStateMgr.getCurrentState().getMetadataMgr()
.getSerializedMetaSpec(catalogName, originDbName, originTableName, snapshotId, icebergPredicate).cast();-
IcebergMetadata
这段逻辑跟IcebergMetadata关联了起来,调用其getSerializedMetaSpec接口,接口中就是获取Iceberg的元数据文件,中间经历了一定的过滤
List dataManifests = snapshot.dataManifests(nativeTable.io());
List matchingDataManifests = filterManifests(dataManifests, nativeTable, predicate);
for (ManifestFile file : matchingDataManifests) {
remoteMetaSplits.add(IcebergMetaSplit.from(file));
} 获取分片之后就是按StarRocks的扫描结构组装TScanRangeLocations,最终在实际执行时分布式分配解析
private void addSplitScanRangeLocations(RemoteMetaSplit split) {
TScanRangeLocations scanRangeLocations = new TScanRangeLocations();
THdfsScanRange hdfsScanRange = new THdfsScanRange();
hdfsScanRange.setUse_iceberg_jni_metadata_reader(true);
hdfsScanRange.setSerialized_split(split.getSerializeSplit());
hdfsScanRange.setFile_length(split.length());
hdfsScanRange.setLength(split.length());
// for distributed scheduler
hdfsScanRange.setFull_path(split.path());
hdfsScanRange.setOffset(0);
TScanRange scanRange = new TScanRange();
scanRange.setHdfs_scan_range(hdfsScanRange);
scanRangeLocations.setScan_range(scanRange);
TScanRangeLocation scanRangeLocation = new TScanRangeLocation(new TNetworkAddress("-1", -1));
scanRangeLocations.addToLocations(scanRangeLocation);
result.add(scanRangeLocations);
}-
PlanFragment
visitPhysicalIcebergMetadataScan接口最终组装的是一个PlanFragment,这大体类似于Spark的stage,是物理执行计划的计划块
PlanFragment fragment =
new PlanFragment(context.getNextFragmentId(), metadataScanNode, DataPartition.RANDOM);
context.getFragments().add(fragment);
return fragment-
IcebergMetadataScanner
IcebergMetadataScanner由于其调用逻辑来自于C++的代码,暂未梳理其逻辑,但是假定其执行了,可以看其效果,主要在getNext()接口中读取数据
可以看到其读取后的数据结构是ContentFile,是Iceberg中DataFile的上层父类
ContentFile file = reader.next();
for (int i = 0; i < requiredFields.length; i++) {
Object fieldData = get(requiredFields[i], file);
if (fieldData == null) {
appendData(i, null);
} else {
ColumnValue fieldValue = new IcebergMetadataColumnValue(fieldData);
appendData(i, fieldValue);
}
}主要在appendData接口当中,向表添加数据,可以看到这里设置了一个offHeapTable
offHeapTable是 StarRocks 中的一个特殊表类型,简单来说就是在堆外内存中建立一个表结构,将数据对应存储到堆外内存,之后可以以表形式去访问
protected void appendData(int index, ColumnValue value) {
offHeapTable.appendData(index, value);
}2. 数据扫描中的元数据解析
首先同样到PlanFragmentBuilder.visitPhysicalIcebergScan,流程与visitPhysicalIcebergMetadataScan类似
首先是这里的表是数据表
Table referenceTable = node.getTable();
context.getDescTbl().addReferencedTable(referenceTable);
TupleDescriptor tupleDescriptor = context.getDescTbl().createTupleDescriptor();
tupleDescriptor.setTable(referenceTable);
// set slot
prepareContextSlots(node, context, tupleDescriptor);之后是IcebergScanNode
IcebergScanNode icebergScanNode =
new IcebergScanNode(context.getNextNodeId(), tupleDescriptor, "IcebergScanNode",
equalityDeleteTupleDesc);IcebergScanNode这里核心是调用setupScanRangeLocations
icebergScanNode.setupScanRangeLocations(context.getDescTbl());最终同样封装成PlanFragment
PlanFragment fragment =
new PlanFragment(context.getNextFragmentId(), icebergScanNode, DataPartition.RANDOM);
context.getFragments().add(fragment);
return fragment;-
IcebergScanNode
在setupScanRangeLocations当中,有一个操作是getRemoteFileInfos,这个就是获取数据文件信息,因此内部包含了元数据解析的部分
List splits = GlobalStateMgr.getCurrentState().getMetadataMgr().getRemoteFileInfos(
catalogName, icebergTable, null, snapshotId, predicate, null, -1); -
IcebergMetadata
getRemoteFileInfos是在IcebergMetadata当中,会调用triggerIcebergPlanFilesIfNeeded,看接口名字可以明确这是用来触发Iceberg的元数据解析的,最终走到了collectTableStatisticsAndCacheIcebergSplit
private void triggerIcebergPlanFilesIfNeeded(IcebergFilter key, IcebergTable table, ScalarOperator predicate,
long limit, Tracers tracers, ConnectContext connectContext) {
if (!scannedTables.contains(key)) {
tracers = tracers == null ? Tracers.get() : tracers;
try (Timer ignored = Tracers.watchScope(tracers, EXTERNAL, "ICEBERG.processSplit." + key)) {
collectTableStatisticsAndCacheIcebergSplit(table, predicate, limit, tracers, connectContext);
}
}
}collectTableStatisticsAndCacheIcebergSplit当中获取了TableScan,这里的Scan就是StarRocksIcebergTableScan
TableScan scan = icebergCatalog.getTableScan(nativeTbl, new StarRocksIcebergTableScanContext(
catalogName, dbName, tableName, planMode(connectContext), connectContext))
.useSnapshot(snapshotId)
.metricsReporter(metricsReporter)
.planWith(jobPlanningExecutor);-
StarRocksIcebergTableScan
之后走scan.planFiles(),这个中间会基于Iceberg的逻辑进行调用
CloseableIterable fileScanTaskIterable = TableScanUtil.splitFiles(
scan.planFiles(), scan.targetSplitSize()); Icberg的逻辑中planFiles最终会调用TableScan的doPlanFiles,这里调用的就是StarRocksIcebergTableScan的实现接口,根据场景有本地和远程的调用方式
if (shouldPlanLocally(dataManifests, loadColumnStats)) {
return planFileTasksLocally(dataManifests, deleteManifests);
} else {
return planFileTasksRemotely(dataManifests, deleteManifests);
}Iceberg应当是使用的planFileTasksRemotely,内部会构建IcebergMetadataCollectJob
MetadataCollectJob metadataCollectJob = new IcebergMetadataCollectJob(
catalogName, dbName, tableName, TResultSinkType.METADATA_ICEBERG, snapshotId(), icebergSerializedPredicate);
metadataCollectJob.init(connectContext.getSessionVariable());
long currentTimestamp = System.currentTimeMillis();
String threadNamePrefix = String.format("%s-%s-%s-%d", catalogName, dbName, tableName, currentTimestamp);
executeInNewThread(threadNamePrefix + "-fetch_result", metadataCollectJob::asyncCollectMetadata);-
MetadataExecutor执行
IcebergMetadataCollectJob的执行在MetadataExecutor当中,就是基本的SQL执行,这里是异步的
public void asyncExecuteSQL(MetadataCollectJob job) {
ConnectContext context = job.getContext();
context.setThreadLocalInfo();
String sql = job.getSql();
ExecPlan execPlan;
StatementBase parsedStmt;
try {
parsedStmt = SqlParser.parseOneWithStarRocksDialect(sql, context.getSessionVariable());
execPlan = StatementPlanner.plan(parsedStmt, context, job.getSinkType());
} catch (Exception e) {
context.getState().setError(e.getMessage());
return;
}
this.executor = new StmtExecutor(context, parsedStmt);
context.setExecutor(executor);
context.setQueryId(UUIDUtil.genUUID());
context.getSessionVariable().setEnableMaterializedViewRewrite(false);
LOG.info("Start to execute metadata collect job on {}.{}.{}", job.getCatalogName(), job.getDbName(), job.getTableName());
executor.executeStmtWithResultQueue(context, execPlan, job.getResultQueue());
}