一、MyCat
1.简介
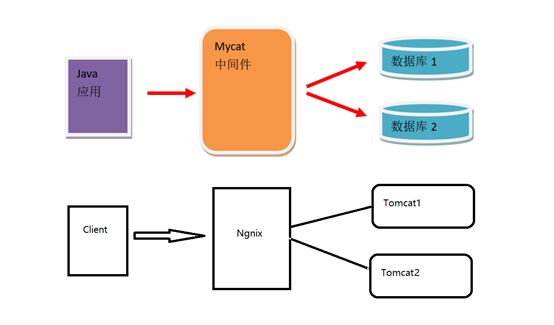
MyCat是目前最流行的基于Java语言编写的数据库中间件,是要给实现了MySQL协议的服器,前端用户可以把它看作是一个数据库代理,用MySQL客户端工具和命令行访问,而其后端可以用MySQL原生协议与多个MySQL服务器通信,也可以同JDBC协议与大多数主流数据库服务器通信,其核心功能是分库分表,配合数据库的主从模式还可以实现读写分离
MyCat 是基于阿里开源的 Cobar 产品而研发,Cobar 的稳定性、可靠性、优秀的架构和 性能以及众多成熟的使用案例使得 MyCat 变得非常的强大。
MyCat 发展到目前的版本,已经不是一个单纯的 MySQL 代理了,它的后端可以支持 MySQL、SQL Server、Oracle、DB2、PostgreSQL 等主流数据库,也支持 MongoDB 这种新型 NoSQL 方式的存储,未来还会支持更多类型的存储。而在最终用户看来,无论是那种存储方 式,在 MyCat 里,都是一个传统的数据库表,支持标准的 SQL 语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度。
MyCat 官网:http://www.mycat.io/
2.MyCate的优势
数据量级
单一的 MySQL 其数据存储量级和操作量级有限. Mycat 可以管理若干 MySQL 数据库,同时实现数据的存储和操作.
开源性质
Mycat 是 java 编写的中间件. 开源,免费. 有非常多的人和组织对 Mycat 实行开发,维护,管理,更新. Mycat 版本提升较快,可以跟随环境发展.如果有问题,可以快速解决. Mycat有开源网站和开源社区.且有官方发布的电子书籍. Mycat 是阿里原应用 corba 转型而来的.
市场应用
2015 年左右,Mycat 在互联网应用中占比非常高.
使用MyCat后的结构图
二、MyCat中的概念
1.切分:逻辑上的切分,在物理层面,是使用多库【database】,多表【table】实现的切分
2.纵向切分/垂直切分:就是把原本存储于一个库的数据存储到多个库上
由于对数据的读写都是对一个库进行操作,所以单库并不能解决大规模并发写入的问题
例如:我们会建立定义数据库workDB、商品数据库payDB、用户数据库userDB、日期数据库logDB等,分别用户存储项目数据定义表、商品定义表、用户数据表、日志数据表等。
优点:
1)减少增量数据写入时的锁对查询的影响;
2)由于单表数量下降,常见的操作由于减少了需要扫描的记录,使得单表单词查询所需的检索行数变少,减少了磁盘IO,时延变短。
2.横向切分/水平切分:把原本存储于一个表的数据分块存储到多个表上,当一个表中的数据量过大时,我们可以把该表的数据按照某种规则进行划分,然后存储到多个结构相同的表,和不同的库上。
例如,我们 userDB 中的 userTable 中数据量很大,那么可以把 userDB 切分为结构相同 的多个 userDB:part0DB、part1DB 等,再将userDB 上的 userTable,切分为很多userTable: userTable0、userTable1等,然后将这些表按照一定的规则存储到多个 userDB 上。
优点:
1)单表的并发能力提高了,磁盘 I/O 性能也提高了。
2)如果出现高并发的话,总表可以根据不同的查询,将并发压力分到不同的小表里面。 缺点:无法实现表连接查询
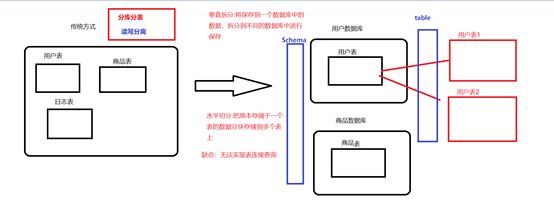
逻辑库—Schema:MyCat中定义的database是逻辑存在的,在物理上是不存在的,主要是针对纵向切分提供的概念。
逻辑表—table:MyCat中定义的table是逻辑存在的,在物理上是不存在的,主要是针对横向切分提供的概念。
数据主机—dataHost:物理MySQL存放的主机地址,可以使用主机名,IP,域名定义。
数据节点—dataNode:配置物理的database,数据保存的物理节点就是,database
分片规则:当控制数据的时候,如何访问物理database和table,就是访问dataHost和dataNode的算法
在MyCat处理具体的数据CRUD的时候,如何访问dataHost和dataNode的算法
如:哈希算法,crc32算法等。
常用工具的默认端口:
MySQL 默认端口是3306
Mycat 默认端口是8066
tomcat 默认端口是8080
Oracle 默认端口是1521
nginx 默认端口是80
http 协议默认端口80
redis 默认端口6379
三、读写分离
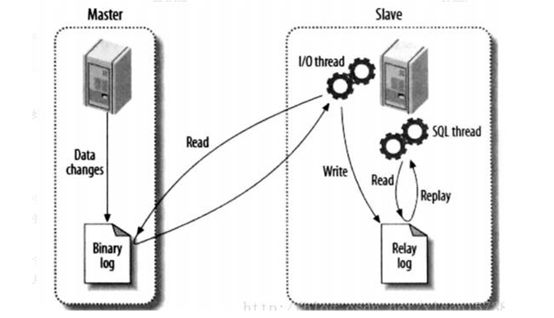
1.读写分离原理:需要搭建主从模式,让主数据库(master)处理事务性增、删、改操作(INSERT、UPDATE、DELETE),而从数据库(slave)处理SELECT查询操作
主从备份:就是一种主备模式的数据库应用
主库(Master)数据和从库/备库(Slave)数据完全一致,实现数据的多重备份,保证数据的安全
可以在Master【InnoDB】和Slave[MyISAM]中使用不同的数据库引擎,实现读写的分离
主从备份目的:
1.保证数据安全,尽量避免数据丢失的可能
2.实现读写分离,使用不同的数据库引擎,实现读写分离,提高所有的操作效率,InnoDB使用DML语法操作,MyISAM使用DQL语法操作
主从备份模式实现数据同步
所有对 Master 的操作,都会同步到 Slave 中. 如果 Master 和 Salve 天生上环境不同 , 那么对 Master的操作 , 可能会在Slave中出现错误
如:
在创建主从模式之前 ,Master有 database : db1, db2, db3. Slave有database:db1, db2.
创建主从模式 . 现在的情况Master和 Slave天生不同
主从模式创建成功后 , 在Master中 drop
database db3. Slave中抛出数据库 SQL异常. 后续所有的命令不能同步 .
一旦出现错误 . 只能重新实现主从模式
主从模式下的逻辑图:
四、创建主从模式
1.首先准备准备两个虚拟机,配置好基本环境,两个分别安装好mysql数据库,这里的主库使用192.168.199.129环境,从库使用192.168.199.133
2.Master【主库】配置
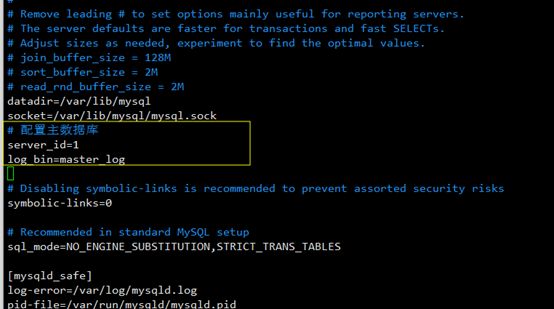
2.1修改/ect/my.cnf文件,配置server_id,和log_bin的值,然后重启mysql
2.2访问mysql,执行命令,直接创建从节点用户,然后刷新权限
grant all privileges on *.* to 'myslave'@'192.168.199.133'identified by 'myslave' with grant option;


2.3查看用户,查看Master信息 切换到mysql数据库,查看用户信息

show master status;查看Master信息

3.Slave【从库】配置
3.1先修改/etc/my.cnf配置文件,添加唯一标识server_id,唯一标识的值要大于Master库的值

3.2然后重启mysql服务,配置Slave,首先停止Slave,配置主库信息,再启动Slave
配置Slave
执行命令配置从库信息:change master to master_host=’ip’,master_user=’username’,master_password=’password’,master_log_file=’log_file_name‘;

3.3可以使用show slave status \G;查看Slave配置

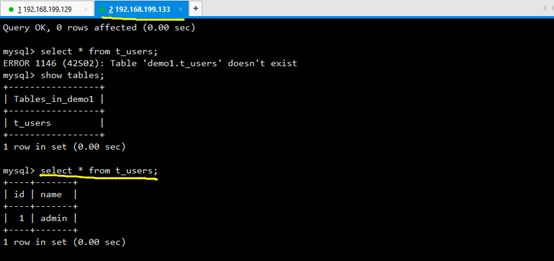
4.测试主从,注意:主库中的数据库和表以及从库中的数据库和表要相同

然后在主库中添加数据,会自动同步到从库中


在从库中查看
五、安装MyCat
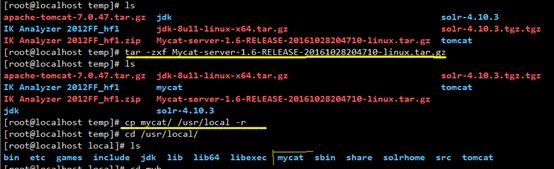
1.下载MyCat For Linux的tar包
2.解压并指定位置
3.启动测试

六、MyCat的分片规则以及分库注意事项
以 500 万为单位,实现分片规则.
逻辑库 A 对应 dataNode - db1 和 db2. 1-500 万保存在 db1 中, 500 万零 1 到 1000 万保存在 db2 中,1000 万零 1 到 1500 万保存在 db1 中.依次类推
crc32slot的分片规则:在 CRUD 操作时,根据具体数据的 crc32 算法计算,数据应该保存在哪一个 dataNode 中
配置分片规则时需要注意:
1)
2)所有的 tableRule 只能使用一次。如果需要为多个表配置相同的分片规则,那么需要在此重新定义该规则。
3)在 crc32Slot 算法中的分片数量一旦给定,MyCat 会将该分片数量和 slor 的取值范围保存到文中。在次修改分片数量时是不会生效的,需要将该文件删除。文件位置位于 conf 目录中的 ruledata 目录中
使用MyCat分库时需要注意:
1)使用 MyCat 实现分库时,先在 MyCat 中定义逻辑库与逻辑表,然后在 MyCat 的链接 中执行创建表的命令必须要在 MyCat 中运行。因为 MyCat 在创建表时,会在表中添加一个 新的列,列名为_slot。
2)使用 MyCat 插入数据时,语句中必须要指定所有的列。即便是一个完全项插入也不 允许省略列名。
在MyCat中配置分库

然后在rule.xml中配置
