车道线检测网络-LaneNet(论文简述)
摘要
无论是辅助驾驶还是自动驾驶,车道线识别都是非常重要的。以前的算法需要很多人工的操作或者无法很好的适应不同的车道线场景。本文主要是使用semantic segmentation的方式来对车道线进行划分,可以适应变化的车道环境,并且速度可以达到50FPS。
一介绍
现在的自动驾驶主要集中在计算机视觉和机器人领域的研究,还处于学术和工业水平,并没有大众化使用。研究的目的就是希望通过各种sensor和控制模块来完全明白汽车周围的环境。基于摄像头的车道线检测就是很重要的一步,能够知道汽车所在的车道位置。对车道偏移检测和轨迹规划都很重要。所以基于摄像头的车道线事实检测是实现自动驾驶中很重要的一个点。传统的车道线识别方法需要使用精心设计的特征来识别车道,然后结合霍夫变换和卡尔曼过滤器。识别出车道后还需要使用后处理的技术过滤识别错误的部分,将分割的组合并起来做为最后的车道。事实上这些传统不能很好的适应多样变化的道路情况。
最近的一些算法开始摈弃手工设计feature的检测器而使用上了深度学习的算法去预测车道,比如基于像素的车道分割。但是论文[11]和[19]的算法中只有路面状况复杂的时候才会使用CNN做图片增强。而论文[16][13][22][21]尤其是[16]可以估计出车道哪怕没有车道标记,但是在识别出车道的基础上,我们还需要将不同车道划分为不同实例。
为了解决这个问题,有些算法比如[19][12]依据几何性质进行后处理,但是这种处理比较消耗计算量并且对路面变化不太鲁棒。另外一种方法[20]直接将车道分成不同的实例分割问题,这种算法可以端到端训练,把不同车道分成不同实例,但是必须预先确定车道数量,不同适应不同车道数量的情况。
在这篇文章里面,超越了上面提到的限制,把车道检测问题转化成了实例分割问题,每一条车道都属于自己的车道类别。作者设计了一个多任务的网络,一个车道分割分支和一个车道嵌入分支,可以进行端到端的训练。车道分割分支的输出是两类,背景或者车道,车道嵌入分支进一步将分割出来的车道像素划分为不同的车道实例。通过把车道识别的问题转化为两个任务,我们可以完全利用车道分割分支的强大能力,而不用将不同的类直接分配给不同的车道,取而代之的是使用车道嵌入分支,通过聚类的损失函数为每个pixel分配一个车道id并且可以忽略属于背景的pixel,因此可以处理不同车道数量的问题。
知道每个pixel属于哪个车道后,最后一个步骤,将每一个车道实例转化为参数化描述,最后使用在论文中广泛使用的曲线拟合算法。常见的曲线拟合算法有cubic polynomials [32], [25], splines [1] or clothoids [10]。为了在保证计算效率的情况下提升拟合质量,一般会把图片转换为鸟瞰图的形式并且在它的基础上进行曲线拟合。在鸟瞰图的模式下拟合的曲线可以通过矩阵转换到原始图片上。转换矩阵基于一张图片计算并且保持固定,但是如果地平面发生变化这个转换矩阵就不再有效。车道靠近地平线的点可以投射到无限远,以负面方式影响线条拟合。
为了解决这个问题,我们还是在曲线拟合之前进行图像视野转换,但是与以前固定的转换矩阵不一样,我们使用神经网络训练输出转换系数。这个神经网络以图片作为输入,使用loss函数进行优化车道拟合问题。这样可以根据路面平面的变化进行自动适应,可以更好的拟合车道。下图是一个示意图
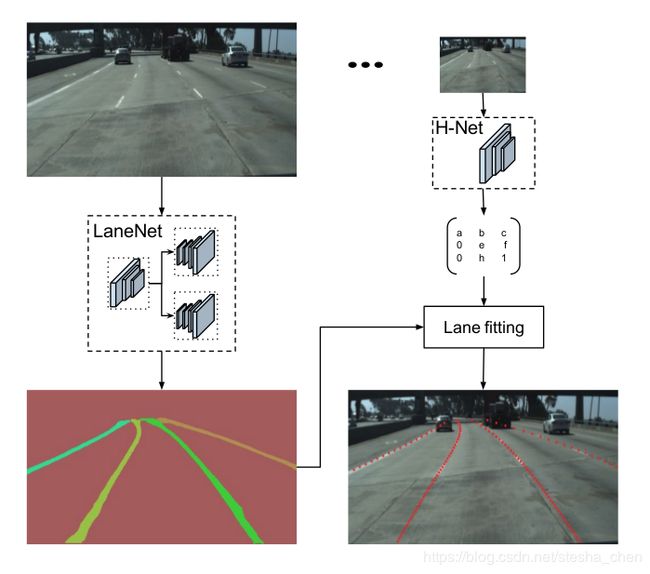
从上图可以看出LaneNet这边有两个分支,一个是车道分割,一个是车道嵌入,另一边还有一个Hnet用来预测转换视图的矩阵。
总结这篇文章的贡献有两点:
- 使用分支的多任务架构,车道分割分支+车道嵌入分支
- 使用网络预测图片和视图的变换参数,可以更好的适应路面变化,比如上下坡
二方法
本文是针对车道分割问题而设计的可以端到端训练的神经网络,主要为了解决之前的算法不能自动适应车道数量的变化的情况。实现的方法就是把车道检测问题看成实例分割问题来解决。这部分的网络叫做LaneNet,结合了车道实例二分割和聚类方法进行一次性实例分割,LaneNet的输出是每个车道pixel分配了车道ID。第II-A节会详细介绍。
在LaneNet输出每个车道的像素集合后,我们还需要通过这些像素拟合曲线才能获得最终信息。 通常,车道像素会投射到“鸟瞰图”使用固定变换矩阵。 但是,由于这一事实对于所有图像,转换参数是固定的,这引起了遇到非平坦地平面时的问题,例如 在
连续下坡。 为了缓解这个问题,作者训练了一个网络叫做H-Net,估计“理想”的参数变换,以输入图像为条件。这种转变不一定是典型的“鸟瞰”视图”。 相反,它是车道可以进行的转换最佳拟合低阶多项式。 第II-B节会详细介绍。
A.LANENET
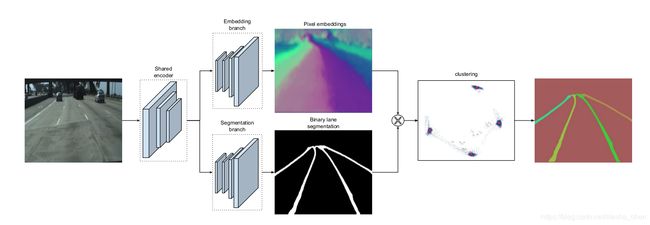
上图是lanenet的网络模型,可以看到是两个分支加一个聚类。
二分分割
是上图的分割分支,训练后输出是一个二分分割图,表明pixel是背景还是车道。将标记的gt中每个车道的点连接起来形成每条车道线,需要注意在标记这些车道线的时候如果遇到了汽车等物体遮挡也应该通过遮挡物,这样训练出来的网络可以学会对这当初进行车道线预测。分割网络使用标准的crossentropy,但是正负样本非常不平衡,所以需要增加权重。
实例分割
实例分割就是要区分车道像素分别属于哪个车道,训练了LaneNet中的第二个分支嵌入分支来实现。最流行的检测分割算法都不适用于车道实例分割,因为边界框检测更适合紧凑物体,车道不是。因此我们使用一次性方法,使用距离测量学习,可以很容易地与之集成为标准的前馈网络,并且能够满足实时处理的要求。
通过使用他们的聚类损失函数,实例嵌入分支训练后输出是每个车道的嵌入像素,因此同一个车道的嵌入像素之间的距离很小,同时不同车道的嵌入像素之间的距离很大。通过这样做,同一个车道的嵌入像素就会聚类在一起,为每个车道形成独一无二的聚类。是通过两个方面的约束来实现的,一个是方差![]() ,这个代表每个车道的平均嵌入像素对其他像素之间的一个拉力。另外还有一个是
,这个代表每个车道的平均嵌入像素对其他像素之间的一个拉力。另外还有一个是![]() ,将每个聚类的中心都推离彼此。这两部分是折线:拉力只有当嵌入像素跟它的中心的距离大于
,将每个聚类的中心都推离彼此。这两部分是折线:拉力只有当嵌入像素跟它的中心的距离大于![]() 才会被激活,不同中心之间的推力只有当他们的距离小于
才会被激活,不同中心之间的推力只有当他们的距离小于![]() 才会被激活。
才会被激活。
 代表聚类的个数
代表聚类的个数
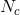 代表每个聚类
代表每个聚类 里面元素的个数
里面元素的个数
 是嵌入像素
是嵌入像素
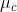 是聚类的嵌入像素的平均值
是聚类的嵌入像素的平均值
![]() 是L2距离,
是L2距离,
![]()
总的Loss是两个loss之和![]()
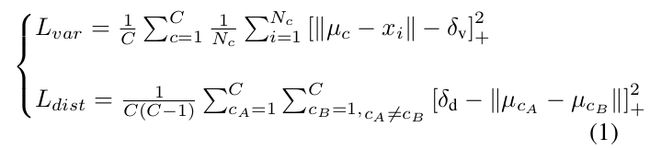
一旦网络开始起作用,车道嵌入的像素就会聚类在一起,每个聚类和彼此之间的距离会大于![]() ,而每个聚类的半径会小于
,而每个聚类的半径会小于![]() 。
。
聚类
对上面的loss设置![]() >6
>6![]() ,在进行聚类时,首先使用mean shift聚类,防止将离群点选入相同的簇中;之后对像素进行划分:以簇中心为圆心,以2
,在进行聚类时,首先使用mean shift聚类,防止将离群点选入相同的簇中;之后对像素进行划分:以簇中心为圆心,以2![]() 为半径,选取圆中所有的像素归为同一车道线。重复该步骤,直到将所有的车道线像素分配给对应的车道。关于mean shift聚类方法的理解可以参考mean shift clustering
为半径,选取圆中所有的像素归为同一车道线。重复该步骤,直到将所有的车道线像素分配给对应的车道。关于mean shift聚类方法的理解可以参考mean shift clustering
网络结构
LaneNet的网络架构是基于encoder-decoder的网络ENet,只是后面将网络改成了两个分支。ENet的encoder比decoder包含更多的参数,这两个分支如果完全共享encoder的所有网络,结果不会太让人满意。因此,原始的ENet的encoder包含三个stage,LaneNet只会对这两个分支共享前两个stage,把第三个stage和decoder对这两个分支单独训练。分割分支最后输出的是一个channel的图片(二分分割),嵌入分支输出的是Nchannel的图片,N是嵌入尺寸。每个分支的loss是相等的权重,然后通过网络进行反向传播。
B.使用HNet曲线拟合
正如前面提到的,LaneNet的输出是每条车道的像素集合,在原始的图片空间中对这些像素进行多项式拟合不是太理想,因为我们必须使用高阶多项式才能够应付曲线车道。关于这个问题的一个常用解决方法是将图片转成鸟瞰图视图,这样车道之间是彼此平行的,曲线的车道就可以通过2阶或者3阶的多项式进行拟合。
然而在这种方法中,转换矩阵 计算一次,并且所有的图片都使用同一个转换矩阵。这样水平面发生变化的时候会导致错误,那些消失的点会投射到无穷远,上下移动。
计算一次,并且所有的图片都使用同一个转换矩阵。这样水平面发生变化的时候会导致错误,那些消失的点会投射到无穷远,上下移动。

从上图可以看出,当使用固定的转换矩阵的时候(第二行),绿色的点是曲线拟合的就不太准确。
为了解决这个问题,作者训练了一个神经网络叫做HNet,这个网络可以进行端到端的训练,预测出来的是转换矩阵的参数,通过这个转换矩阵,车道的点可以使用二阶或者三阶多项式进行拟合。输入是图片,网络会调整转换矩阵中的参数以适应水平面的变化,这样做后车道拟合就会是正确的,参考上图第三行。有6个参数,矩阵形式如下

矩阵中的0就是为了约束水平线在转换后仍然是水平线。
曲线拟合
在对车道的像素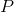 进行曲线拟合之前,需要先用HNet生成的转换矩阵进行转换。
进行曲线拟合之前,需要先用HNet生成的转换矩阵进行转换。
给定:![]() ,通过矩阵转换后得到:
,通过矩阵转换后得到:![]() 就是
就是![]() ,然后使用最小二乘法进行n阶的多项式拟合,得到
,然后使用最小二乘法进行n阶的多项式拟合,得到![]() ,是根据
,是根据![]() 拟合出的。
拟合出的。
我们最终的目标是希望在原图上的车道点 作为输入,希望输出基于原图的
作为输入,希望输出基于原图的![]() ,那么可以这样计算,
,那么可以这样计算,![]() 然后转换得到
然后转换得到![]() ,然后可以计算
,然后可以计算![]() ,其中
,其中 表示我们不关系这个值。那么可以得到了
表示我们不关系这个值。那么可以得到了![]() ,最后使用逆计算得到基于原图的
,最后使用逆计算得到基于原图的![]() ,
,![]() 就可以得到
就可以得到![]() 。这个过程也可以从下图看出来,总的来说就是矩阵计算后曲线拟合,然后矩阵逆计算。
。这个过程也可以从下图看出来,总的来说就是矩阵计算后曲线拟合,然后矩阵逆计算。
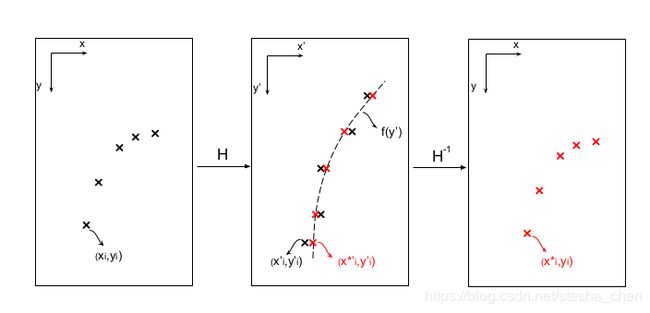
损失函数
给定N个车道的真值点,![]() ,可以通过转换矩阵计算出
,可以通过转换矩阵计算出![]() 得到
得到![]() 。拟合
。拟合![]() 这个方程式,使用近似最小二乘法的解决方法可以得到:
这个方程式,使用近似最小二乘法的解决方法可以得到:
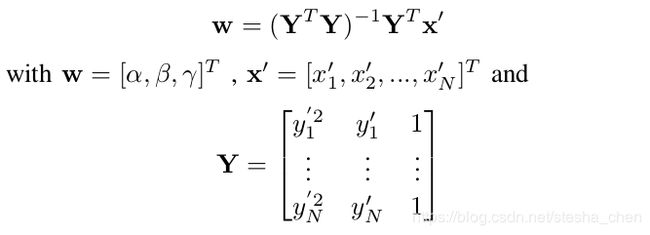
这是一个2阶拟合的例子。拟合好的多项式可以给出![]() 后得到预测出来的
后得到预测出来的![]() ,同样通过
,同样通过![]() 可以计算出
可以计算出![]() ,所以loss就是MSE
,所以loss就是MSE
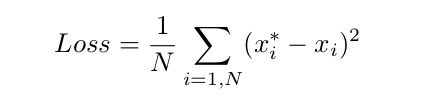
网络模型
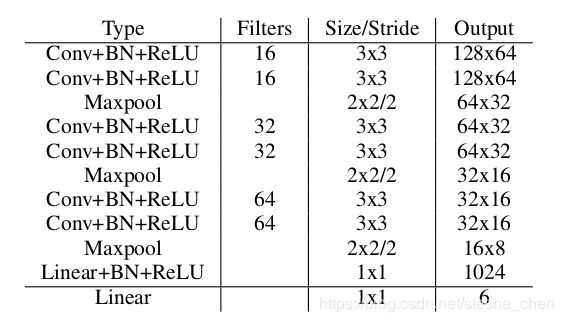
HNet的网络模型很简单,主要是3x3的卷积加上BN加上ReLU,使用maxpooling降维,最后连接两层FC,下图可以清晰的看到网络结构
三结果
A.数据
使用tuSimple数据集,3626训练样本,2782测试图片,拍摄的图片中有好的天气和一般的天气。图片集中有2车道/3车道/4车道和高速公路,拍摄时间也是在一天中的不同时刻。每张图片提供了19张前面帧没有标记的图片。标记的信息是json格式,指明了x坐标和离散化的y坐标。也标记除了当前车道和左右车道,并且希望验证的时候也可以预测出这个信息。
精确度衡量:
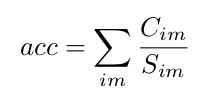
其中![]() 是标记正确的点,
是标记正确的点,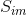 是真实的点。标记的点和真实的点之间的距离小于一个阀值就认为标记正确。
是真实的点。标记的点和真实的点之间的距离小于一个阀值就认为标记正确。
也可以用FP和FN来衡量精度

![]() 是识别错误的点,
是识别错误的点,![]() 是识别出来的点,
是识别出来的点,![]() 是漏识别的点,
是漏识别的点,![]() 是gt的所有点。
是gt的所有点。
B.配置
LaneNet
嵌入分支的维度N是4, ![]() ,输入图片的尺寸为512x256,使用Adam优化,batchsize为8,学习率为5e-5.
,输入图片的尺寸为512x256,使用Adam优化,batchsize为8,学习率为5e-5.
H-Net
使用3阶多项式拟合,输入图片尺寸为128x64。使用Adam优化,batchsize为10,学习率为5e-5。
速度
输入为512x256,嵌入分支的维度N是4,使用3阶多项式拟合的条件下检测算法速度可以达到50FPS,每个阶段的时间耗费可以看下表,使用的是NVIDIA 1080Ti的显卡

C.实验
比较
不使用矩阵转换,使用固定的矩阵转换和使用HNet学习的矩阵进行转换之间的误差比较如下

可以看到使用Hnet学习的矩阵进行转换后使用三阶拟合误差最小。
tuSimple结果
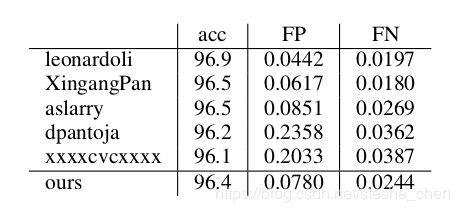
通过使用LaneNet和3阶拟合加上HNet学习转换矩阵,在tuSimple的比较中可以拿到第四名的位置,与第一名只相差0.5%,但是并不知道其他成绩的预测速度如何。
四总结
这篇文章做作者展示了一种端到端的车道检测的方法,可以达到50FPS的速度。这个方法有最近的实例分割的例子而激发,可以检测车道数量变化的情况。
为了让分割出来的车道像素可以用低阶多项式进行拟合,训练了一个以来不同图片生成转换矩阵的网络,使用这种方式曲线拟合是最优的。能够很好的适应道路的坡度变化,而达到不错的精确度。