机器学习经典算法详解及Python实现---朴素贝叶斯分类及其在文本分类、垃圾邮件检测中的应用
摘要:
朴素贝叶斯分类是贝叶斯分类器的一种,贝叶斯分类算法是统计学的一种分类方法,利用概率统计知识进行分类,其分类原理就是利用贝叶斯公式根据某对象的先验概率计算出其后验概率(即该对象属于某一类的概率),然后选择具有最大后验概率的类作为该对象所属的类。总的来说:当样本特征个数较多或者特征之间相关性较大时,朴素贝叶斯分类效率比不上决策树模型;当各特征相关性较小时,朴素贝叶斯分类性能最为良好。另外朴素贝叶斯的计算过程类条件概率等计算彼此是独立的,因此特别适于分布式计算。本文详述了朴素贝叶斯分类的统计学原理,并在文本分类中实现了该算法。朴素贝叶斯分类器用于文本分类时有多项式模型和贝努利模型两种,本算法实现了这两种模型并分别用于垃圾邮件检测,性能显著。
Note:个人认为,《机器学习实战》朴素贝叶斯这一章关于文本分类的算法是错误的,无论是其贝努利模型(书中称“词集”)还是多项式模型(书中称“词袋”),因为其计算公式不符合多项式和贝努利模型。详见本文“文本分类的两种模型”。
(一)认识朴素贝叶斯分类
决策树算法中提到朴素贝叶斯分类模型是应用最为广泛的分类模型之一,朴素贝叶斯分类是贝叶斯分类器的一种,贝叶斯分类算法是统计学的一种分类方法,利用概率统计知识进行分类,其分类原理就是利用贝叶斯公式根据某对象的先验概率计算出其后验概率(即该对象属于某一类的概率),然后选择具有最大后验概率的类作为该对象所属的类。目前研究较多的贝叶斯分类器主要有四种分别是:朴素贝叶斯分类、TAN(tree augmented Bayes network)算法、BAN(BN Augmented Naive Bayes)分类和GBN(General Bayesian Network)。本文重点详细阐述朴素贝叶斯分类的原理,通过Python实现了该算法,并介绍了朴素贝叶斯分类的一个应用--垃圾邮件检测。
朴素贝叶斯的思想基础是这样的:根据贝叶斯公式,计算待分类项x出现的条件下各个类别(预先已知的几个类别)出现的概率P(yi|x),最后哪个概率值最大,就判定该待分类项属于哪个类别。训练数据的目的就在于获取样本各个特征在各个分类下的先验概率。之所以称之为“朴素”,是因为贝叶斯分类只做最原始、最简单的假设--1,所有的特征之间是统计独立的;2,所有的特征地位相同。那么假设某样本x有a1,...,aM个属性,那么有:
P(x)=P(a1,...,aM) = P(a1)*...*P(aM)
朴素贝叶斯分类发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率,其优点是算法简单、所需估计参数很少、对缺失数据不太敏感。理论上,朴素贝叶斯分类与其他分类方法相比具有最小的误差率,但实际上并非总是如此,因为朴素贝叶斯分类假设样本各个特征之间相互独立,这个假设在实际应用中往往是不成立的,从而影响分类正确性。因此,当样本特征个数较多或者特征之间相关性较大时,朴素贝叶斯分类效率比不上决策树模型;当各特征相关性较小时,朴素贝叶斯分类性能最为良好。总的来说,朴素贝叶斯分类算法简单有效,对两类、多类问题都适用。另外朴素贝叶斯的计算过程类条件概率等计算彼此是独立的,因此特别适于分布式计算。
(二)朴素贝叶斯分类数学原理
1,贝叶斯定理
贝叶斯定理是关于随机事件A和B的条件概率(或边缘概率)的一则定理。
其中P(A|B)是在B发生的情况下A发生的可能性。
在贝叶斯定理中,每个名词都有约定俗成的名称:
P(A)是A的先验概率或边缘概率。之所以称为"先验"是因为它不考虑任何B方面的因素。
P(A|B)是已知B发生后A的条件概率,也由于得自B的取值而被称作A的后验概率。
P(B|A)是已知A发生后B的条件概率,也由于得自A的取值而被称作B的后验概率。
P(B)是B的先验概率或边缘概率,也作标准化常量(normalizing constant).
2,朴素贝叶斯分类的概率论原理
2.1 贝叶斯分类概率论描述
用概率论来表达朴素贝叶斯分类的过程就是:
1、![]() 是一个待分类的项,ai为x的特征属性(地位相同、相互独立),共m个。
是一个待分类的项,ai为x的特征属性(地位相同、相互独立),共m个。
2、有类别集合![]() 。
。
3、计算![]() 。
。
4、如果![]() ,则
,则![]() 。
。
显然,问题的关键在于第三步-求出各分类项的后验概率,用到的就是贝叶斯公式。
则根据贝叶斯定理有如下推导:
![]()
分母对于所有类别来说都是为常数,因此只需计算分子即可。又因为各个特征具有相同的地位且各自出现的概率相互独立,所以有:
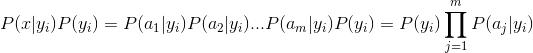
上式中,P(aj|yi)是关键,其含义就是样本各个特征在各个分类下的条件概率,计算各个划分的条件概率是朴素贝叶斯分类的关键性步骤,也就是数据训练阶段的任务所在。至于样本每个特征的概率分布则可能是离散的,也可能是连续的。
2.2 先验条件概率的计算方法
由上文看出,计算各个划分的条件概率P(a|y)是朴素贝叶斯分类的关键性步骤,下面说明特征属性为离散分布或者连续分布的计算、处理方法。
1,离散分布-当特征属性为离散值时,只要统计训练样本中各个划分在每个类别中出现的频率即可用来估计P(a|y)。
由于贝叶斯分类需要计算多个特征值概率以获得事物项属于某一类的概率,若某一特征值的概率为0则会使整个概率乘积变为0(称为数据稀疏),这破坏了各特征值地位相同的假设条件,使分类准确率大大降低。因此为了降低破坏率,离散分布必须进行校准-如Laplace校准:每个类别下所有特征划分的计数都加1,训练样本集数量足够大,因此并不会对结果产生影响,但却解决了上述概率为0的尴尬局面;另外从运算效率上,加法也比乘法提高了一个量级。
数据稀疏是机器学习中很大的问题,比拉普拉斯平滑更好的解决数据稀疏的方法是:通过聚类将未出现的词找出系统相关词,根据相关词的概率求一个平均值。如果:系统有“苹果”,“葡萄”等词,但是没有“榴莲”,我们可以根据“苹果”,“葡萄”等平均值作为“榴莲”的概率,这样更合理。
2,连续分布-当特征属性为连续值时,通常假定其值服从高斯分布(正态分布)。即:
![]()
而![]()
对于连续分布的样本特征的训练就是计算其均值和方差。
2.3 算法改进
实际项目中,概率P往往是值很小的小数,连续的微小小数相乘容易造成下溢出使乘积为0或者得不到正确答案。一种解决办法就是对乘积取自然对数,将连乘变为连加,ln(AB)=lnA+lnB。采用自然对数处理不会带来任何损失,可以避免下溢出或者浮点数舍入导致的错误。下图给出了f(x)和ln(f(x))函数的曲线,对比可以发现:相同区域内两者同增或者同减、在相同点取得极值,因此采用自然对数不会影响最终比较结果。

因此下式的计算可以转变为其对数的计算,概率的比较也可以转换为概率对数的比较。
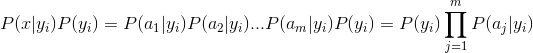
(三)Python实现朴素贝叶斯分类算法
贝叶斯分类器构造过程中,对于样本大小为N的样本序列常被分为较大数目的训练集和较小数目的测试集两种,训练集用来产生分类器、测试集则用来测试分类器准确率,这种过程称为“留存交叉验证”。测试集中的M个序列是在样本序列中随机选取,余下的作为训练集。
第四节中通过--文本分类的多项式模型和贝努利模型实现了朴素贝叶斯分类算法,并将其用在了垃圾邮件检测中。
(四)朴素贝叶斯分类用于文本分类
1,文本分类的两种模型
什么是文本分类?所谓文本分类,是指对所给出的文本,给出预定义的一个或多个类别标号,对文本进行准确、高效的分类.它是许多数据管理任务的重要组成部分。新闻类别(财经、体育、教育等)划分、垃圾邮件检测等都属于文本分类。关于文本分类详细的叙述可参考“文本分类概述”。文本分类可以采用Rocchio算法、朴素贝叶斯分类算法、K-近邻算法、决策树算法、神经网络算法和支持向量机算法等,本节就采用朴素贝叶斯完成分本分类任务。
文本分类的基础是切词,切词是一个很重要的研究方向,英文切词相对自然比较容易--几乎是切成一个个单词即可,中文切词比较麻烦(预处理阶段需要特殊的处理),Python中好用的的中文切词库有(jieba—中文断词工具、SnowNLP —中文文本处理库、loso—另一个中文断词库)。本文的重点是采取朴素贝叶斯进行文本的分类,假设文档已经完成了切词(实际就简单采用了Python string的split方法)。
文本分类中有两种朴素贝叶斯的概率计算模型可以使用,下面以二分类为模型说明两者类先验概率P(c)和各个词的类条件概率P(tk|c)的具体计算方法,P(tk|c)可以看作是单词tk在证明文本d属于类c上提供了多大的证据,而P(c)则可以认为是类别c在整体上占多大比例(有多大可能性)。
朴素贝叶斯算法用于文本分类时,特征词的选取是一个很重要的性能因素。若将所有单词作为特征词无疑会消耗巨量的内存,计算性能也会下降。所以特征词的选取策略要根据实际做一些优化,如训练数据先进行人工筛选、只取出现次数大于N(N>=1)的词等。
(i)多项式模型(multinomial model)即为词频型--根据分类中某词出现的次数计算概率。
可以说多项式模型概率计算是以“词”为基础单位,设某文本d=(t1,t2,…,tk),tk是该文档中出现过的单词,允许重复,则在多项式模型中类先验概率和各个单词类条件概率的计算方法为:
先验概率P(c)= 类c下单词总数/整个训练样本的单词总数
类条件概率P(tk|c) = (类c下单词tk在各个文档中出现过的次数之和+1)/(类c下单词总数+|V|)
V是训练样本的单词表(即抽取单词,单词出现多次,只算一个),|V|则表示训练样本包含多少种单词。
多项式模型中各单词类条件概率计算考虑了词出现的次数,相当于考虑了词的权重,这更符合自然语言的特点。另外,根据斯坦福的《Introduction to Information Retrieval 》课件上所说,多项式模型计算准确率更高。待分类项类别判断时仅根据其中出现的单词进行后验概率计算,即:
P(t1|c)*P(t2|c),...,*P(tk|c)*p(c)
(ii)贝努利模型(Bernoulli model)即词集型--根据分类中某词是否出现计算概率。贝努利模型不考虑词在文档中出现的次数,只考虑出不出现,因此在这个意义上相当于假设词是等权重的。
先看贝努利模型的定义--对随机实验中某事件是否发生,试验的可能结果只有两个,这种只有两个可能结果的实验称为贝努利试验。贝努利模型中甭管哪一类,每个单词只有出现或者不出现两种,因此可以这么理解二分类的贝叶斯贝努利模型--文本中某些词的出现与否决定了该文本的分类,这实际上包含了两部分:一些词出现了,另外一些词没有出现。因此贝努利模型中各个单词类条件概率的计算是:在文本中出现的单词作为“正方”参与计算,没有在文本中出现但在该类全局单词表中出现的单词作为“反方”参与计算。
贝努利模型概率计算的是以“文本”为基础单位,设某文本d=(t1,t2,…,tk),tk是该文档中出现过的单词,不允许重复,贝努利模型类先验概率和各个单词类条件概率的计算方法为:
P(c) = 类c下文件总数/整个训练样本的文件总数
P(tk|c) = (类c下包含某单词tk的文件数+1)/(类c下文件总数+2)
其中计算P(tk|c)时,分子+1是引入Laplace校准,分母加2是因为词只有出现与否两种情况,估计也是为了数据校准(TBD)。对待分类项进行类别判断计算后验概率时,“正方”的概率就是P(tk|c),“反方”的概率是(1-P(word|c))(word是虽然不在d中,但出现在该类全局单词表上的词。因为Laplace校准的存在,实际上相当于全部的单词都参与计算),即:
P(t1|c)*P(t2|c),...,*P(tk|c)*(1-P(word0|c)*,..., *(1-P(wordm|c)*p(c)
关于两个模型的博文还可以参考‘朴素贝叶斯文本分类算法学习’,本文实现了两种模型。
2,Python实现
2.1 naviebayes 对象
naviebayes模块中定义了一个navieBayes对象,包含的属性如__init__函数所示:
- class navieBayes(object):
- def __init__(self,vocabSet = None, classPriorP= None, conditionP = None,\
- classPriorP_ber= None, conditionP_ber = None,negConditionP_ber = None,lapFactor = 1,\
- classlabelList = None, **args):
- '''modelType is NB model type,'multinomial' or 'bernoulli', the default type is'multinomial'
- parameters:
- classPriorP is (1,m)log of class prior probability list, m is class number, multinomial
- conditionP is (m,n) log of condition probability list, n is the count of vocabulary,mutinomial
- classPriorP_ber, conditionP_ber, bernoulli
- negConditionP_ber is the negtive condition probability for bernoulli model, actually log(1-condition probability)
- vocabSet is the vocabulary set
- lapFactor is the laplace adjust factor
- classlabelList is the class labels
- '''
- obj_list = inspect.stack()[1][-2]
- self.__name__ = obj_list[0].split('=')[0].strip()
- #self.modelType = modelType
- self.classPriorP = array(classPriorP)
- self.conditionP = array(conditionP)
- self.classPriorP_ber = array(classPriorP_ber)
- self.conditionP_ber = array(conditionP_ber)
- self.negConditionP_ber = array(negConditionP_ber)
- self.vocabSet = vocabSet
- if vocabSet:
- self.vocabsetLen = len(self.vocabSet)
- self.lapFactor = lapFactor
- self.classlabelList = classlabelList
navieBayes对象的属性Laplace factor是用于Laplace校准的,防止词条的条件概率为0,可以通过调整Laplace factor取值使词库的统计分布更接近实际,从而增强分类性能。在一个包含超大数量的词汇库中,若按照出现次数大于1的条件取特征词,那么LaplaceFactor =1显然就不合理了,为了精确的描述的词的统计分布规律,可取LaplaceFactor =0.0001或者更小的值。
另外navieBayes对象支持两种分类模型,默认modelType = 'multinomial'多项式模型。因为先验概率和类条件概率都是采用了其对数值,因此若要实现贝努利模型则还要增加一个属性表示‘反方’条件概率log(1-P),在贝努利模型类别判断时作为“反方”参与计算。
navieBayes包含trainNB和classifyNB等方法,根据modelType类型选取多项式或者贝努利模型的train、classify函数产生相应的朴素贝叶斯分类器。其中trainNB方法的输入数据格式如下所示:
- postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
- ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
- ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
- ['stop', 'posting', 'stupid', 'worthless', 'garbage'],
- ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
- ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
- classVec = [0,1,0,1,0,1] or ['a','b','a','b','a','b']//class list
2.2,NavieBayes用于标示垃圾邮件测试
使用朴素贝叶斯解决一些现实生活中的问题时,需要先从文本内容得到字符串列表,然后生成词向量。下面这个例子中,我们将了解朴素贝叶斯的一个最著名的应用:垃圾邮件过滤。
现有垃圾邮件(spam)和非垃圾邮件(ham)各25封,将其切词后按照navieBayes对象trainNB定义的格式存放在一个列表中,邮件分类则存放于另外一个列表。另外,分类器训练过程中,为了验证训练得到的分类器的有效性,从邮件样本列表中随机抽取10个作为测试数据。
无论采取多项式模型还是贝努利模型,上述朴素贝叶斯分类器在Laplace factor取值为[1, 0.5, 0.1, 0.01, 0.001, 0.00001]时垃圾邮件识别的错误率都为0。性能如此好,估计是训练数据和测试数据经过抽取后特征词都比较鲜明。
多项式和贝努利模型的朴素贝叶斯文本分类学习包的下载地址是:
Machine learning navieBayes algorithm
另外,“机器学习实战”--第四章:朴素贝叶斯中称其词集型为贝努利模型的说法个人认为是不准确的,因为在类条件概率计算时该程序是按照统计单词数计算的,分类决断时也没有计算"反方"概率。若将其定义为多项式模型也不妥,因为它只统计了词出现与否,对于文中定义的词袋型倒可以称为多项式模型,但是其类条件概率的计算公式也不准确。
引用
算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification)
朴素贝叶斯文本分类算法学习
本文作者Adan,来源于:机器学习经典算法详解及Python实现---朴素贝叶斯分类及其在文本分类、垃圾邮件检测中的应用。转载请注明出处。