支持向量机的核函数及其选择
目录
一、支持向量机与核函数
二、几种常用的核函数:
1.线性核(Linear Kernel)
2.多项式核(Polynomial Kernel)
3.径向基核函数(Radial Basis Function)/ 高斯核(Gaussian Kernel)
4.Sigmoid核(Sigmoid Kernel)
5.字符串核函数
6.傅立叶核
7.样条核
三、核函数的选择
1.先验知识
2.交叉验证
3.混合核函数
吴恩达的课
四、参考资料
一、支持向量机与核函数
支持向量机的理论基础(凸二次规划)决定了它最终求得的为全局最优值而不是局部最优值,也保证了它对未知样本的良好泛化能力。
支持向量机是建立在统计学习理论基础之上的新一代机器学习算法,支持向量机的优势主要体现在解决线性不可分问题,它通过引入核函数,巧妙地解决了在高维空间中的内积运算,从而很好地解决了非线性分类问题。
低维映射到高维
对于核技巧我们知道,其目的是希望通过将输入空间内线性不可分的数据映射到一个高纬的特征空间内,使得数据在特征空间内是可分的,我们定义这种映射为ϕ(x),那么我们就可以把求解约束最优化问题变为

但是由于从输入空间到特征空间的这种映射会使得维度发生爆炸式的增长,因此上述约束问题中内积ϕi⋅ϕj的运算会非常的大以至于无法承受,因此通常我们会构造一个核函数
![]()
从而避免了在特征空间内的运算,只需要在输入空间内就可以进行特征空间的内积运算。
要想构造核函数κ,我们首先要确定输入空间到特征空间的映射,但是如果想要知道输入空间到映射空间的映射,我们需要明确输入空间内数据的分布情况,但大多数情况下,我们并不知道自己所处理的数据的具体分布,故一般很难构造出完全符合输入空间的核函数,
二、几种常用的核函数:
构造出一个具有良好性能的SVM,核函数的选择是关键.核函数的选择包括两部分工作:一是核函数类型的选择,二是确定核函数类型后相关参数的选择.
1.线性核(Linear Kernel)
![]()
线性核,主要用于线性可分的情况,我们可以看到特征空间到输入空间的维度是一样的,
在原始空间中寻找最优线性分类器,具有参数少速度快的优势。对于线性可分数据,其分类效果很理想,
因此我们通常首先尝试用线性核函数来做分类,看看效果如何,如果不行再换别的
2.多项式核(Polynomial Kernel)
![]()
多项式核函数可以实现将低维的输入空间映射到高纬的特征空间
多项式核适合于正交归一化(向量正交且模为1)数据。
属于全局核函数,允许相距很远的数据点对核函数的值有影响。参数d越大,映射的维度越高,计算量就会越大。
但是多项式核函数的参数多,当多项式的阶数d比较高的时候,由于学习复杂性也会过高,易出现“过拟合"现象,核矩阵的元素值将趋于无穷大或者无穷小,计算复杂度会大到无法计算。
3.径向基核函数(Radial Basis Function)/ 高斯核(Gaussian Kernel)

也叫高斯核(Gaussian Kernel),因为可以看成如下核函数的领一个种形式:

径向基函数是指取值仅仅依赖于特定点距离的实值函数,也就是 。
。
任意一个满足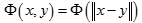 特性的函数 Φ都叫做径向量函数,标准的一般使用欧氏距离,尽管其他距离函数也是可以的。所以另外两个比较常用的核函数,幂指数核,拉普拉斯核也属于径向基核函数。此外不太常用的径向基核还有ANOVA核,二次有理核,多元二次核,逆多元二次核。
特性的函数 Φ都叫做径向量函数,标准的一般使用欧氏距离,尽管其他距离函数也是可以的。所以另外两个比较常用的核函数,幂指数核,拉普拉斯核也属于径向基核函数。此外不太常用的径向基核还有ANOVA核,二次有理核,多元二次核,逆多元二次核。
高斯径向基函数是一种局部性强的核函数,其可以将一个样本映射到一个更高维的空间内,该核函数是应用最广的一个,无论大样本还是小样本都有比较好的性能,而且其相对于多项式核函数参数要少,因此大多数情况下在不知道用什么核函数的时候,优先使用高斯核函数。
径向基核函数属于局部核函数,当数据点距离中心点变远时,取值会变小。高斯径向基核对数据中存在的噪声有着较好的抗干扰能力,由于其很强的局部性,其参数决定了函数作用范围,随着参数σ的增大而减弱。
幂指数核(Exponential Kernel)

拉普拉斯核(Laplacian Kernel)

ANOVA核(ANOVA Kernel)
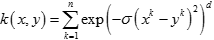
二次有理核(Rational Quadratic Kernel)
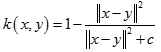
多元二次核(Multiquadric Kernel)
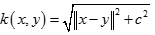
逆多元二次核(Inverse Multiquadric Kernel)

4.Sigmoid核(Sigmoid Kernel)
Sigmoid核函数来源于神经网络,被广泛用于深度学习和机器学习中

采用Sigmoid函数作为核函数时,支持向量机实现的就是一种多层感知器神经网络。
5.字符串核函数
核函数不仅可以定义在欧氏空间上,还可以定义在离散数据的集合上。字符串核函数是定义在字符串集合上的核函数,可以直观地理解为度量一对字符串的相似度,在文本分类、信息检索等方面都有应用。
6.傅立叶核
少见
K ( x , x i ) = 1 − q 2 2 ( 1 − 2 q cos ( x − x i ) + q 2 )
7.样条核
少见
K ( x , x i ) = B 2 n + 1 ( x − x i )
三、核函数的选择
1.先验知识
一是利用专家的先验知识预先选定核函数;
2.交叉验证
二是采用Cross-Validation方法,即在进行核函数选取时,分别试用不同的核函数,归纳误差最小的核函数就是最好的核函数.如针对傅立叶核、RBF核,结合信号处理问题中的函数回归问题,通过仿真实验,对比分析了在相同数据条件下,采用傅立叶核的SVM要比采用RBF核的SVM误差小很多.
3.混合核函数
三是采用由Smits等人提出的混合核函数方法,该方法较之前两者是目前选取核函数的主流方法,也是关于如何构造核函数的又一开创性的工作.将不同的核函数结合起来后会有更好的特性,这是混合核函数方法的基本思想
吴恩达的课
曾经给出过一系列的选择核函数的方法,Andrew的说法是:
1.当样本的特征很多时,特征的维数很高,这是往往样本线性可分,可考虑用线性核函数的SVM或LR(如果不考虑核函数,LR和SVM都是线性分类算法,也就是说他们的分类决策面都是线性的)。
2.当样本的数量很多,但特征较少时,可以手动添加一些特征,使样本线性可分,再考虑用线性核函数的SVM或LR。
3.当样特征维度不高时,样本数量也不多时,考虑用高斯核函数(RBF核函数的一种,指数核函数和拉普拉斯核函数也属于RBF核函数)。
四、参考资料
https://blog.csdn.net/xiaowei_cqu/article/details/35993729
https://blog.csdn.net/weixin_37141955/article/details/78266710
https://blog.csdn.net/w5688414/article/details/79343542
https://blog.csdn.net/lihaitao000/article/details/51173459
https://blog.csdn.net/batuwuhanpei/article/details/52354822