Python爬虫入门-python之爬取pexels高清图片
先上张图片:

首先打开网址:https://www.pexels.com/,然后下来会发现下面的图片是慢慢的加载出来的,也就是通过Ajax请求得到的。在搜索框中输入关键字:beauty,打开F12,刷新,选中XHR,然后一直下拉下拉:
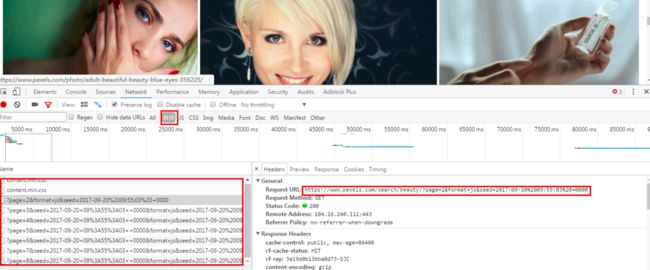
会发现左侧中的URL只有一个page是在发生变化的,在通过对URL中参数的分析我尝试的将URL中的参数js和format去掉,构造出类似于:https://www.pexels.com/search/beauty/?page=2
其中page代表的是页数是会发生变化的,然后复制到浏览器中可以打开图片,改变page的值也没有问题。
以https://www.pexels.com/search/beauty/?page=2为例,在浏览器中打开,再打开F12刷新,切换到Preview选项卡:
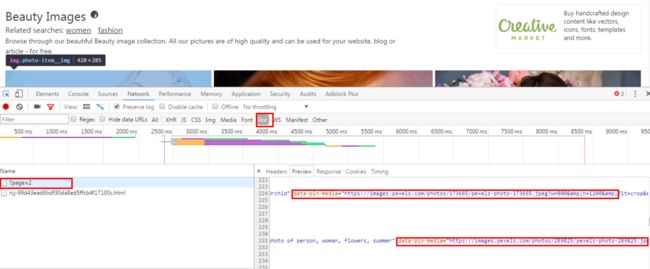
这里面就有当前页面一张张图片的信息,我们可以通过请求这个页面,将相关图片的链接解析出来,就可以拿到我们想要的图片了。
我们打开其中一张美女图片,点击右侧的下载按钮,页面进行跳转:
从浏览器中发现图片的地址为:
https://static.pexels.com/photos/220423/pexels-photo-220423.jpeg
这个与上图中的 data-pin-media 属性的值很像有没有,多打开几张大图重复这个过程真是的图片的高清地址是将data-pin-media中的images替换为static即可。
下面就可以开始写代码了:
打算使用PyQuery库进行解析,练习一下这种用法:
import requests
from requests.exceptions import RequestException
from pyquery import PyQuery as pq
keyword='beauty'
headers={
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'accept-encoding':'gzip, deflate,sdch,br',
'cookie':'__cfduid=d3e43ad7f4bb07152deb3e9b4ca571b271505889614; locale=en; _ga=GA1.2.127776053.1505890636; _gid=GA1.2.783458515.1505890636; _gat=1',
'user-agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
def get_index(url):
response=requests.get(url,headers=headers)
try:
if response.status_code==200:
return response.text
return None
except RequestException:
return None
def parse_index(html):
doc=pq(html)
links=doc('.photos .photo-item a img')
for link in links:
# title=link.attr('alt').replace(',','')
url=link.attr('data-pin-media').replace('images','static').split('?')[0]
yield url
def main(page):
url = 'https://www.pexels.com/search/'+keyword+'/?page='+str(page)
html=get_index(url)
if html:
urls=parse_index(html)
print(urls)
if __name__=='__main__':
main(1)运行这个程序,没有跑起来,发生报错:
没有attr这个属性,还有
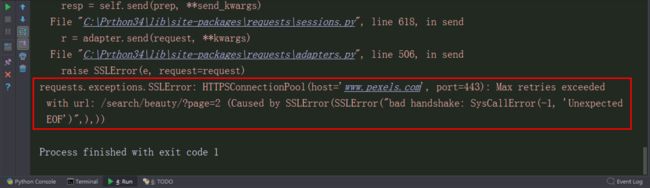
Google一下:

发现PyQuery的写法好像有问题,小白就是这样经常在一个基础的地方踩上坑,于是:
将url=link.attr(‘data-pin-media’).replace(‘images’,’static’).split(‘?’)[0],改成:url=pq(link).attr(‘data-pin-media’).replace(‘images’,’static’).split(‘?’)[0]
可以跑起来了。
然后就是保存图片:
def download_img(url):
response=requests.get(url)
try:
if response.status_code==200:
return response.content
return None
except RequestException:
return None
def save_image(content):
path_name='{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(path_name):
with open(path_name,'wb') as f:
f.write(content)
f.close()
def main(page):
url = 'https://www.pexels.com/search/'+keyword+'/?page='+str(page)
html=get_index(url)
if html:
urls=parse_index(html)
for url in urls:
print('正在下载:%r'%url)
content=download_img(url)
save_image(content)
print('下载完成:%r'%url)
time.sleep(3)运行结果如下:

但是这个下载速度实在是蛋疼的很啊(谁让这个图片这么大呢),开了多进程也一样,而且一开始程序一直卡着我一直以为自己的代码有什么问题跑不起来了,瞎捉摸了老半天也找不出原因,后面去洗澡了,洗完后发现下载了几张图片下来了:
所以我在想要是能写个下载进度条就好了,可以方便查看下载的进度,特别是对于这种大图片的下载,等以后学习了,可以再做些修改。