Elasticsearch品读—第七章:聚合(第二节)
上一章:Elasticsearch品读-第六章:聚合(第一节)
目录
3.桶聚合
3.1 filter
3.2 filtets
3.3 global
3.4 range
3.5 date_range
3.6 ip_range
3.7 histogram
3.8 date_histogram
3.9 geo_distance
3.10 geohash_grid
3.11 missing
3.12 nested
3.13 terms
补充:
terms聚合的不确定性
es聚合返回文档信息
3.桶聚合
Bucket aggregation,即存储桶聚合。它不会像度量聚合一样计算字段上的值,而是创建文档桶。每个桶与一个标准(即聚合类型)相关联,该标准确定当前上下文中的文档是否能"落入"其中。
存储桶聚合可以保存子聚合,这些子聚合只对由其父聚合创建的存储桶进行聚合。ES可以嵌套聚合,而且可以多层:父聚合→子聚合→孙聚合...。聚合的顺序是:由外到内聚合,最外层即父聚合先完成,然后在父聚合结果的基础上进行子聚合...以此类推。例如:有公司-部门-产品这种关系,如果对其进行嵌套聚合,顺序为:1、先按照公司划分存储桶;2、在每个公司的存储桶上按照部门划分存储桶;3、在每个公司的每个部门存储桶上按照产品划分文档集。
3.1 filter
filter aggregation,即单桶聚合。过滤当前上下文中与指定过滤器匹配的所有文档,构成一个独立的存储桶,用于将当前聚合上下文缩小到特定文档集。
注意:过滤器使用的语法是DSL语法,不是聚合语法。
语法:

例子:
①计算所有T恤类型产品的平均价格

3.2 filtets
filters aggregation,即多桶聚合。定义多个存储桶,每个桶与过滤器关联,每个存储桶将收集与其关联过滤器匹配的所有文档。当使用filters聚合且有子聚合时,每个过滤器关联的存储桶都会执行这个子聚合。
语法:
例子:
①设置两个存储桶,一个过滤出age=39的文档集,一个过滤出gender=F的文档集。并且设置第一个存储桶名称(ES称为密钥)为age39,第二个存储桶名称为genderF。

返回结果:

②匿名Filters聚合,不设置桶的名称(ES称为密钥),用数组形式定义过滤规则。返回结果按定义规则的顺序返回聚合结果。

返回结果:

额外参数:
①other_bucket:是否聚合与任何给定过滤器都不匹配的所有文档,true为要聚合。若使用命名过滤器,则该桶默认名称为" _other_",若使用匿名过滤器,则该桶为返回数组的最后一个桶。
②other_bucket_key:修改other_bucket存储桶的名称,如果使用了这个参数,则隐式地将other_bucket设置true。
3.3 global
global aggregation,全局聚合。将当前搜索执行上下文中的所有文档作为一个存储桶。该上下文由搜索的index和type定义,但不会受到查询语句本身的影响global aggregation只能作为顶级聚合器放置,因为在另一个桶聚合器中嵌入全局聚合器没有任何意义。
语法:

例子:
下面的聚合演示了如何在搜索上下文中的所有文档上计算聚合,在下面示例中为第一个聚合的avg_price,无论查询如何,它将计算目录中所有产品的平均价格,而不仅仅是“衬衫”。而第二个聚合的 t_shirts 受到 query 查询的影响,它将计算目录中类型为衬衫的平均价格。

3.4 range
range aggregation,即范围聚合。此聚合定义一组范围,每个范围代表一个存储桶。并根据文档指定字段的值判断文档该落入哪一个桶内。请注意:range聚合包含from值,并排除每个范围的to值。如果range聚合存在子聚合,则每个范围表示的存储桶都会执行子聚合。
语法:

额外参数:
①keyed:设置为true,将唯一的字符串键与每个存储桶关联,并将范围作为哈希而不是数组返回。
例子:
①聚合<50、50≤x<100、≤100的文档

返回结果:

②当有子聚合时,每个范围桶都会执行这个子聚合

3.5 date_range
date_range aggregation,即日期范围聚合。此聚合与正常范围聚合range之间的主要区别在于:from和to选项可以使用Date Math表达式,并且可以指定日期格式,通过此日期格式可以返回from和to响应字段。请注意:date_range聚合包括from值,但排除每个范围的to值。
语法:

例子:
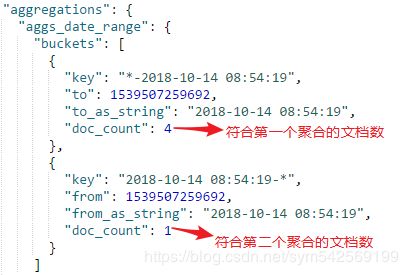
①ranges是一个数组,一个对象就是一个聚合,下例中表示2个聚合:
"from": "now-10d",表示聚合"大于等于当前时间扣去10天的数据"
"to":"now-10d",表示聚合"小于当前时间扣去10天的数据"
now表示当前时间,10d表示10天,日期表达式可以看Date Math

返回结果:
额外参数:
keyed:设置为true会将唯一的字符串键与每个存储桶关联,并将范围作为哈希而不是数组返回。
time_zone:将日期从另一个时区转换为UTC。
3.6 ip_range
ip_range aggregation,IP范围聚合。在range聚合的基础上针对IP地址的聚合。同样的,它也是包含from指定的IP地址,去除to指定的IP地址。
语法:

例子:

3.7 histogram
histogram aggregation,即直方图聚合。基于文档中提取的数值,动态地在值上构建固定大小的存储桶,并将文档向下舍入到其最近的存储桶。
例如:
有文档集的值范围是[65,86,95]
如果固定大小设为5,则存储桶为[65,70,75,80,85,90,95]
如果固定大小设为7,则存储桶为[63,70,77,84,91]
释义:
...存储桶的取值区间会根据文档集的取值区间,配合用户设置的固定大小来设置,以上面的例子:固定大小为5,正好5*13=65,所以存储桶的取值区间从65开始;固定大小为7,7*9=63最接近65,所以存储桶的取值区间从63开始。同样,存储桶的取值区间结束也是依据这个理。...文档是向下舍入到最近的存储桶中,以上面的例子:固定大小为5,存储桶的取值区间为[65,70,75,80,85,90,95],值65的文档落入值65的存储桶中;值86的文档落入值为85的存储桶中;值95的文档落入值95存储桶。
也可以这样理解:每个存储桶的取值范围为:65~69,70~74,75~79,80~84,85~89,90~94,95~99,文档的值位于哪个范围就落入那个存储桶中。
语法:

额外参数:
①min_doc_count:默认情况下,当没有文档落入存储桶,ES将使用空桶填充直方图中的间隙;如果设置了min_doc_count,只会返回存储桶中文档数大于等于min_doc_count的存储桶。
②extended_bounds:可以“强制”直方图聚合以extended_bounds.min构建存储桶,并继续构建存储桶达到最大值。但是,当extended_bounds.min高于从文档提取的值区间的最小值,ES仍是以文档集的最小值构建存储桶,最大值也是如此。
③order:默认情况下,聚合返回的存储桶按照桶的键值升序排序。可以通过order控制存储桶返回的顺序:_key:asc,_count:desc。_key表示按照存储桶的键值,_count表示按照存储桶包含的文档数
例子:

返回结果:

3.8 date_histogram
date_histogram aggregation,即日期直方图聚合。它以指定字段的最早日期和最晚日期为区间,对其中的日期按照指定间隔划分时间段,并统计落在各个时间段上的文档数量。使用date_histogram必须指定2个参数:
①field:指定要聚合数据类型为date的字段
②interval:指定划分的时间间隔,取值有:year、quarter(季度)、month、week、day、hour、minute、second
额外参数有:
③format:对聚合结果的时间进行格式化,例如"yyyy-MM-dd"
④time_zone:此参数用于以UTC格式存储日期的字段, 指明应该使用的时区
⑤offset:用于将每个桶的起始时间更改为指定的正(+)或负偏移(-)时间
⑥keyed:此参数设为true,会将唯一的字符串键与每个存储桶关联,并将结果作为哈希返回,而不是数组返回
⑦missing:定义如何处理缺少值的文档,默认是忽略,也可以指定一个值。所有缺少值的文档都按照这个值来处理。
语法:

例子:
①以"年"为间隔划分时间段,统计每个时间段的文档数量,并将返回结果格式化
注意:它是以字段的最早日期和最晚日期作为时间区间。
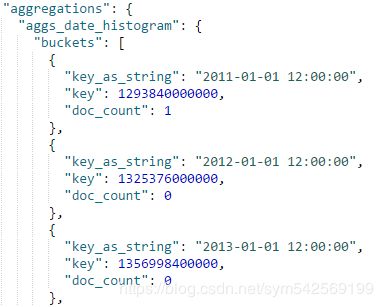
返回结果为:
②将keyed设为true,将以哈希返回。使用offset可以将起始时间正偏移或负偏移一定时间值

返回结果为:

3.9 geo_distance
geo_distance aggregation,即geo范围聚合。通过定义中心点和一组距离范围桶,聚合评估每个文档指定geo_point字段的值与中心点的距离,根据范围确定该文档所属的桶(如果文档与中心点之间的距离落在桶的距离范围内,则文档属于桶)。
语法:

额外参数:
①unit:指定距离范围的单位,默认为米(m),详见distance units
②distance_type:指定距离计算模式,默认为src模式,即圆弧模式
③keyed:将keyed标志设置为true会将唯一的字符串键与每个存储桶关联,并将范围作为哈希而不是数组返回。
例子:
①指定多个与中心点的距离范围
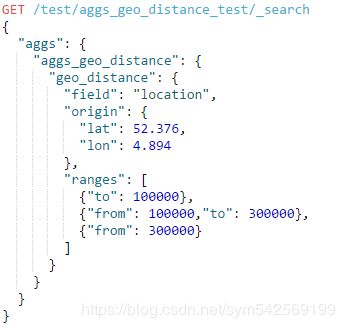 返回结果:
返回结果:
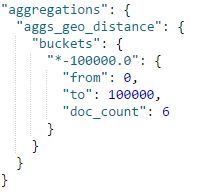
②指定距离单位,并且指定计算模式,同时将keyed设置为true,但是只定义一个距离范围

返回结果:
3.10 geohash_grid
geohash_grid aggregation,即geo网格聚合。根据文档集中geo_point字段的经纬度范围,聚合出一个用geohash表示的网格(网格中是一个个基本的单元格),如下图所示,红点表示落入(1001单元格)中:

ES聚合出来的网格也类似上面的例子,将文档集中的geo_point字段的经纬度值按照精度参数precision聚合出一个网格,网格由一个个单元格组成,每一个单元格为一个存储桶,统计落在存储桶(单元格)中的文档数量,存储桶的唯一标识是单元格表示的geohash值。
语法:
precision值越大,精度越高,单元格越多,单元格表示的geohash值越大。它的取值范围为:1~12,值为12的最高精度geohash产生的单元覆盖不到一平方米的土地。

额外参数:
①size:要返回的最大geohash存储桶数(默认为10000)。根据包含的文档量对存储桶进行优先级排序。
②shard_size:设置每个分片需要返回的存储桶,默认从每个分片返回max(10,(size x of-shards))个存储桶。
补充:
下表显示了各种字符串长度的geohash所涵盖的单元格的度量标准维度;
单元尺寸随纬度而变化,因此该表适用于赤道最坏的情况:

例子:
①精度小的geohash_grid聚合,可以直接使用

返回结果:每个存储桶的Key为聚合单元格的geohash值

②精度大的geohash_grid聚合,由于ES是将指定文档集中所有的geo_point
字段拿去聚合成一个网格,这些字段间的经纬度位置差距会导致返回的单元格
(即存储桶)很多,甚至达到百万级别。因此先用Filter聚合和geo过滤器缩
小搜索的范围:

3.11 missing
missing aggregation,即缺值聚合。该聚合创建当前上下文中缺少字段值(缺少字段或具有配置的NULL值)的所有文档的存储桶。通常与其它字段数据聚合(例如range aggregation)结合使用,用来返回由于缺少字段数据值而无法放置在任何其他存储区中的所有文档的信息。
语法:

3.12 nested
nested aggregation,即嵌套文档聚合。该聚合只能用于字段类型是nested dataType的文档集,创建一个存储桶,将嵌套文档放入该桶内。对这个存储桶作子聚合,就可以在这些嵌套文档上定义任何类型的聚合。
PS:nested aggregation的子聚合在使用嵌套文档的字段时,需要结合顶级文档中的字段,如例如①所示。
语法:

例子:
①计算产品(product)的最小价格(price),其中价格是作为嵌套文档保存到 产品中

3.13 terms
terms aggregation,即术语聚合。根据字段的值构建存储桶,每个唯一值构建一个存储桶。当ES存在多个主分片时,协调节点会从每个分片上请求提供其自己的最大大小的术语桶,这将意味着返回的列表略有偏差且不准确,详见
terms聚合的不确定性。
语法:

额外参数:
①size:设置size参数以定义应从整个术语列表中返回多少个术语桶。
②shard size:设置协调节点将从每个分片请求多少个术语桶。该参数的大小应该要大于参数size的大小(不然没意义,分片只返回3个,但是结果需要5个,协调节点无法整合)。shard size请求的大小越高,结果越准确,但计算结果更高。
③order:设置返回结果的存储桶的顺序,默认情况下,存储桶按其doc_count降序排序。(doc_count是聚合后落入该桶的文档数量)
④min_doc_count:设置仅返回超过min_doc_count指定数量的术语存储桶。
例子:
①对code字段的值进行术语整合,每种值作为一个存储桶,按doc_count排序只返回前4个桶

返回结果:
doc_count_error_upper_bound:每个术语的文档错误的上限。
sum_other_doc_count:当有很多独特的术语时,ES只返回顶部术语,此字段是不属于响应的所有存储桶的文档计数总和。

补充:
terms聚合的不确定性
术语聚合( terms aggregation)的文档计数(以及任何子聚合的结果)并不总是准确的。 这是因为每个分片都提供了自己的有序列表应该是什么的视图,并将它们组合在一起以给出最终视图。例如:存在这种情况:
①请求获取产品中的前5个术语,按照具有3个分片的索引的降序文档计数排序。 在这种情况下,要求每个分片给出前5个术语。
三个分片中的每个分片的术语如下所示,其各自的文档计数用括号表示:

分片将返回它们的前5个术语,因此3个分片的结果将是:

协调节点将从每个分片中获取前5个结果(根据要求)并将它们组合成最终的前5个列表会产生以下结果:

因为产品A是从所有分片返回的,所以我们知道它的文档计数值是准确的。 产品C仅由分片A和C返回,因此其文档计数显示为50,但这不是准确的计数。 产品C存在于分片B上,但其数量不足以将产品C放入该分片的前5个列表中。 产品Z也只返回2个分片,但第三个分片不包含该术语。 在将结果组合在一起以产生最终术语列表时,无法知道产品C的文档计数存在错误,而产品Z的文档计数存在错误。产品H的文档数量为44 ,但是3个分片都没有将其包含在最终的术语列表中,因为它没有进入任何分片的前五个术语。
ES聚合返回文档信息
ES聚合只统计符合聚合条件的文档的数量,并没有返回具体的文档信息,如果需求中需要知道聚合后的文档信息,可以借助top_hits聚合来返回,将它作为子聚合即可:
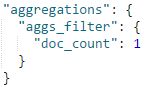
①若没有使用top_hits聚合,下面的聚合只会返回文档数量

返回结果:
②必须为aggs_filter聚合添加一个子聚合top_hits,让它会在父聚合的基础上再做聚合,并且结合top_hits自身的特性,将父聚合上的文档返回。使用top_hits时,最好是指定sort和size,让文档有顺序的返回,当然如果父聚合后的文档没有任何顺序,那只要指定size即可。

返回结果:
