Pandas reindex 重建索引和自动填充(6)Python 数据分析从零开始
写任何有关pandas的代码前,我们应该先导入pandas
import pandas as pd
我们下面出现全部的pd都代表对pandas的引用
重建索引
重建索引是Pandas的一个重要方法,主要用于创建一个符合我们需要索引内容的新对象。如果某个索引的值并之前不存在,则会被赋予一个缺失值。
新对象 = Series/Dataframe对象.reindex( [ 新索引 ] )
import pandas as pd
dynasty=pd.Series([405,319,289,276],index=['汉朝','宋朝','唐朝','明朝'])
dyn1=dynasty.reindex(['汉朝','宋朝','唐朝','明朝','清朝'])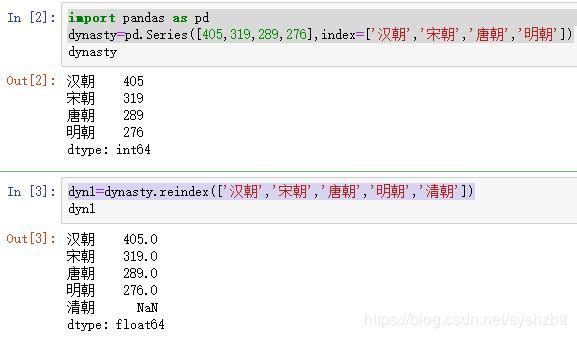
data=[['晴','阴','雨'],['多云','雨','雨'],['多云','晴','阴']]
wxr=pd.DataFrame(data,index=['周一','周二','周三'],columns=['北京','上海','广州'])
wxr1=wxr.reindex(['周一','周二','周三','周四'],columns=['北京','上海','广州','深圳']) 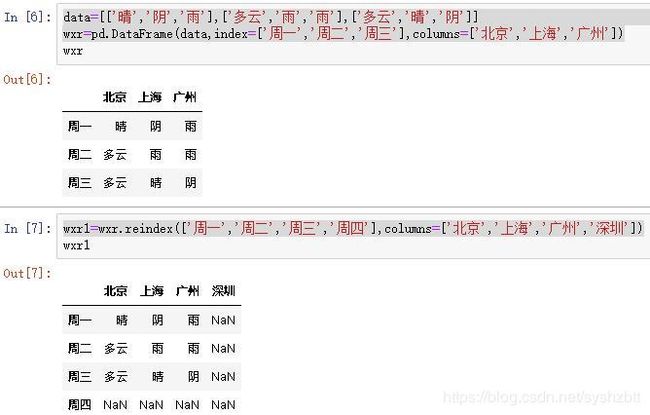
自动填充指定默认值
我们在重建索引后,如果出现缺失值数据会很不连贯,所以需要根据需要进行填入值。这个功能就由reindex里的method参数提供。
Series/Dataframe对象.reindex( [ 新索引 ] , fill_value='填充值' )
import pandas as pd
dynasty=pd.Series([405,319,289,276],index=['汉朝','宋朝','唐朝','明朝'])
dyn2=dynasty.reindex(['汉朝','晋朝','唐朝','宋朝','明朝','清朝'],fill_value=300) 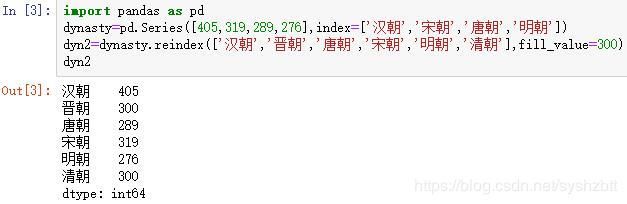
data=[['晴','阴','雨'],['多云','雨','雨'],['多云','晴','阴']]
wxr=pd.DataFrame(data,index=['周一','周二','周三'],columns=['北京','上海','广州'])
wxr2=wxr.reindex(['周一','周二','周三','周四'],columns=['北京','上海','广州','深圳'],fill_value='晴')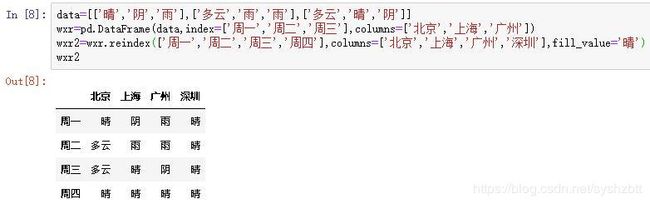
根据前后数据值自动填充
如果我们的对象索引是一个有序的排列,日期、数值等。那么可以使用method参数自动根据前后的数据填写缺少的值。ffill是使用前面的值填充,bfill是使用后面的值填充。这个有序的含义要是机器可以识别的有序,朝代名不算是有序。
Series/Dataframe对象.reindex( [ 新索引 ] , method='ffill/bfill' )
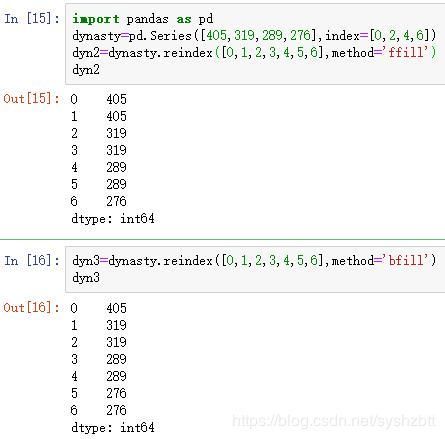
import pandas as pd
dynasty=pd.Series([405,319,289,276],index=[0,2,4,6])
dyn2=dynasty.reindex([0,1,2,3,4,5,6],method='ffill')