王童:知行合一 · 当大数据遇到生物学 | 优秀毕业生专访

[ 导读 ]清华-青岛数据科学研究院(以下简称“数据院”)自2014年4月成立以来,秉承“学校统筹,问题引导,社科突破,商科优势,工科整合,业界联盟”的指导原则,搭建跨学科交叉融合平台,创新跨学科交叉培养模式,培养具有大数据思维和创新能力的“Π”型人才。
大数据能力提升项目由清华大学研究生院,数据院及相关院系共同组织,面向在校研究生(包括硕士和博士)。项目形成大数据思维与技能、跨界学习、实操应用相结合的大数据课程体系和线上线下混合式教学模式,旨在提升学生数据分析和管理数据的能力,让学生在本专业的学习和实践中扩宽思维,并锻炼在本专业领域的数据研究能力。
截至2019年6月,已有来自31个院系的271名同学获得“大数据能力提升项目”证书,其中信息类同学160人,非信息类同学111人。
大数据能力提升项目究竟为同学们带来了什么改变?下面,就让我们聆听优秀毕业生们与大数据结缘的故事,一起发现大数据对他们学习、科研和创业的启发与帮助吧!

2019年毕业于生命科学学院生物学专业计算生物学方向的博士生王童,在2015年加入大数据能力提升项目。在大数据的四年中,他将大数据技术与生物学原理紧密结合,利用深度学习和大数据技术进行蛋白质三维结构预测和蛋白折叠机理的研究,第一次把深度学习技术和大数据技术应用到了片段组装法的蛋白质结构预测中。他即将入职微软亚太研究集团,任高级算法工程师。
一、我与大数据:专业结合,综合培养,团队合作,长期追踪
与大数据结缘,王童更多是出于自己的专业。计算生物学经常面对的是百亿到千亿量级的数据量,需要多次处理、清洗的庞杂数据。
“生物信息也是一种大数据。”
大数据能力提升项目的课程包括了大数据理论学习、大数据实践实习以及相关知名企业的参观走访等内容。
理论学习主要是对本科所学的数理基础知识、统计学习方法,高等数学学习方法等的回顾、总结和梳理。项目实践主要是将理论知识运用到具体的项目和实践中。
以王童印象最深的徐葳老师的大数据系统课程为例,前三分之一以讲授经典算法、软件和操作等大数据基础知识;后三分之二则是分组做一个真实的数据课题。他当时参与的一个课题是《微博水军的判别》。该课题颇具挑战性:数据量多达数千万条,需要用老师上课教的memory reduce的算法进行数据处理;数据很杂,需要做大量的数据清洗。
“理论和实践相结合,知行合一。”王童在采访中反复强调了这一观点。“清华的同学很聪明也很努力。但是在实际应用和工作中还是需要重新去学一些东西和如何将理论运用到实际当中。实现从理论到应用的过渡,我建议大家利用好在大数据实践课和实践项目中应用课堂上学习的内容的机会;并且,将大数据理论运用到研究生的实习或者博士生的课题中也是一个很值得尝试的方法。”
企业对接需要了解企业的需求,汇报工作进展和协商企业可提供的帮助。在这个过程中,王童真实地感知到这个行业的现状,有助于他今后的实习和职业选择。他也建议同学们要勇于和项目、企业、公司合作。“大数据离不开实际的项目,只有真正和企业沟通与合作,你才能真正了解企业的需求以及如何把技术转变为生产力,再把生产机转化为产品和价值。技术落地和技术变现是在课堂上和实验室很少涉及的,但是却是需要同学们认真考虑的一个很重要的问题。”
大数据能力提升项目汇集了来自不同专业、不同年龄、不同背景的同学,在团队合作中,虽然开始可能会有障碍,但最后收获的是思维的碰撞和深厚的友谊。
团队组成很多样,文理工科都有,组员各自发挥自己所长,计算机系同学工程能力和代码实践能力强,我作为组里唯一的博士生负责设计科研路线和模型算法,文科的同学则负责项目需求调研和与客户的交流,明确客户的需求和协商我们需要的帮助,整个课题做下来,我们这个团队里建立了非常深厚的友谊。
”对学员的长期追踪是大数据能力提升项目的突出特点。在大数据的四年里,王童学到了很多。而在毕业以后,他与大数据的联系也不曾间断。
“我一直和老师们保持联系,积极参加一些相关的活动,老师们也对我有长期的跟踪和关注,也很关心我的毕业去向和工作。我觉得这种长期跟踪的培养模式对项目里的学员有非常大的帮助。”
二、大数据与生物:优化预测蛋白质结构的算法
王童的博士研究课题是蛋白质结构预测,预测的模型经过两个阶段的优化,各项指标都取得了巨大飞跃:
“我的博士研究课题可以分为两个阶段,第一个课题是和哈佛大学合作的联合项目,这个项目将序列预测蛋白质结构的F1-Score从之前其他优秀算法取得的45%提高到了约60%,第二个课题则在世界范围内首先开发了一些相关算法,进一步改善第一个课题中的模型,将第一个课题中的F1-Score从60%提升到90%。可以说我们的研究成果是在所有指标上都是领先世界的。”
在优化模型的过程中,大数据算法在其中发挥了重要作用。
“第一个课题主要运用了传统机器学习的算法,包括逻辑回归模型、集成学习的方法去建模,处理的是百亿量级的数据。我们尝试了经典传统机器学习的三种模型:逻辑回归,随机森林,支持向量机,最后发现逻辑回归特别适合海量数据样本的处理,效率高、速度快。在准确性差不多的情况下逻辑回归的速度是其他两种方法的几十倍甚至上百倍。但是逻辑回归模型的问题是它的准确性不高。
第二个课题用的技术是LSTM(长短时记忆网络)、聚合残差网络ResNeXt和知识蒸馏技术。前两个技术特别适合处理序列问题和对序列信息建模,也提高了准确率,但是与此同时速度也减慢了。而知识蒸馏技术主要是用来对模型进行加速,也可以说是一种‘加速算法’,在准确性几乎不变的情况下,我们的模型运行时间缩短了三倍以上。”
王童用图表生动地为我们展示了他们算法的优势:
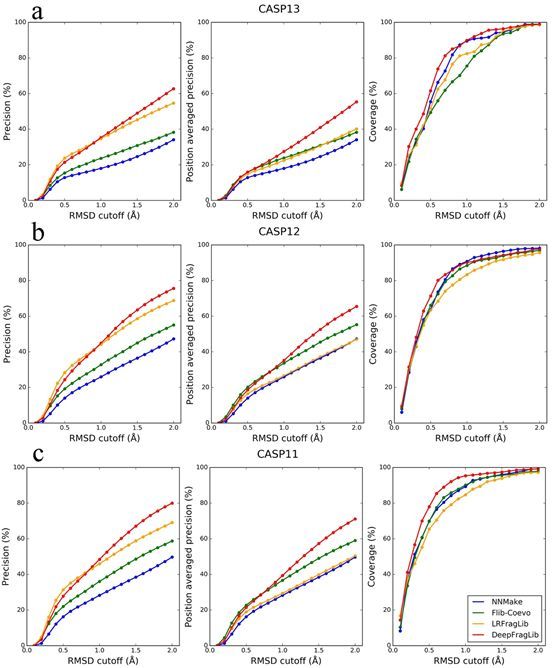
我们DeepFragLib算法与其他SOTA算法相比在各项指标上提升明显,使用我们算法产生的预测结构(蓝色)比其他算法产生的预测结构(红色)与真实晶体结构(绿色)相比更为接近。

三、选择大数据:认清方向,提升自我
谈到对当前在大数据能力提升项目学习、将来可能进入大数据的同学的建议时,王童说:
“
我觉得在大数据的学习也是一个认清自己,进行职业生涯选择的过程。因为我们加入项目比较早,对自己的职业生涯也比较迷茫。在大数据能力提升项目中从理论到实践到实习的过程中,真正地在企业工作、和企业打交道会发现自己是更喜欢企业的氛围还是纯科研的氛围,从而找到自己职业生涯发展方向。
”“此外我觉得大数据能力提升项目包容性很强,同学们来自学校的各个专业、年龄也不同。无论是什么专业、什么年龄的同学,只要有出色的能力和成果都能获得奖学金。
大家一定要趁早学,积极学。加入项目四年来,数据院给我带来了很多的收获和支持。如果大家加入了这个项目,坚持下来一定会有收获。大数据能力提升项目发展至今,从小到大,资源从少到多,能提供给学员的也越来越多,建议大家在项目中要积极地参与。
最后,从我自己的经历中来说,我觉得无论是科研还是实习、找工作,更多受重视的是综合实力。我希望学弟学妹能够充分利用学校的资源,多走出书本,多锻炼自己,提高自己的语言表达能力、交流能力和组织协调能力,提高综合素质。”
口述:王童
采访:陈沅倩
整理:肖祎涵
往期毕业生专访:
任谦:实践是大数据提升项目的灵魂丨优秀毕业生专访
刘云鹏:大数据,让我离生活更近 | 优秀毕业生专访
朱思宇:做大数据的受益者和传播者 | 优秀毕业生专访
付睿:对新事物的追寻之旅 | 优秀毕业生专访
刘念宏:道与术,怎样才能真正学好大数据?
聂聪:数据科学让我为城市规划注入创新价值
姚振宇:数据科学培养下 我成为了那个不安分的"细菌"
张玉萍:数据科学的“融”是学术中的“锦上添花”
王斐:大数据学习助我完成行业撑杆跳
金语泽:大数据交叉思维让我更具创新力
王瑞琰:大数据引领我发现法学“新大陆”
龚亚丽:大数据助我打开传统行业发展新思路
张甜甜:在实践中迈进数据科学领域
