kaggle——泰坦尼克数据集
1.问题描述
RMS泰坦尼克号的沉没是历史上最臭名昭着的沉船之一。1912年4月15日,在首次航行期间,泰坦尼克号撞上冰山后沉没,2224名乘客和机组人员中有1502人遇难。这场轰动的悲剧震撼了国际社会,并导致了更好的船舶安全条例。
海难导致生命损失的原因之一是没有足够的救生艇给乘客和机组人员。虽然幸存下来的运气有一些因素,但一些人比其他人更有可能生存,比如妇女,儿童和上层阶级。
在这个挑战中,我们要求你完成对哪些人可能生存的分析。特别是,我们要求您运用机器学习的工具来预测哪些乘客幸免于难。
2.数据集描述
题目提供的训练数据集包含11个特征,分别是:
Survived:0代表死亡,1代表存活
Pclass:乘客所持票类,有三种值(1,2,3)
Name:乘客姓名
Sex:乘客性别
Age:乘客年龄(有缺失)
SibSp:乘客兄弟姐妹/配偶的个数(整数值)
Parch:乘客父母/孩子的个数(整数值)
Ticket:票号(字符串)
Fare:乘客所持票的价格(浮点数,0-500不等)
Cabin:乘客所在船舱(有缺失)
Embark:乘客登船港口:S、C、Q(有缺失)
3.数据可视化和预处理
对于提供的数据集,首先进行可视化处理,判断哪些特征跟存活的相关性大。
Pclass:
Pclass=1 Pclass=2 Pclass=3
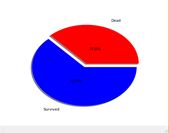


从上图可以分析出,第3类票的乘客死亡率最高,其次是第二类票的乘客。所以,Pclass也是与存活具有相关性
Name:
从主观层次出发,名字与存活率没有联系,将其舍弃。
Sex:
男性 女性
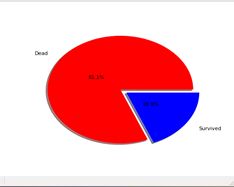
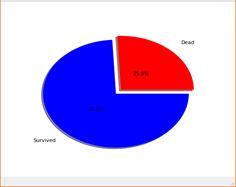
可以看出男性的死亡率显著高于女性的死亡率,性别这一特征跟存活存在相关性。
Age:
有年龄特征 无年龄特征
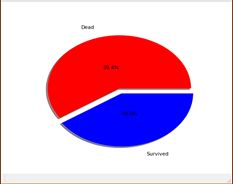

在数据集年龄特征中,存在不少的缺失项,需要考虑是否将缺失项作为特征值的一种还是将其用其他值进行填补。从上面两图可以看出,对于没有年龄特征记录的乘客死亡率比有年龄特征记录的乘客死亡率更高,所以可以将无年龄特征也视作为一项特征值进行处理。
对有年龄特征记录的数据,我们还可以根据数值进行进一步划分:
由于年龄数值过多,首先按照国际对年龄划分的标准,将年龄分为三类:未成年人(0-17),青年人(18-65),中年人(66-)。各年龄段生存和死亡人数如下图所示:

由上图可以看出,成年人人数最多且其死亡率超过50%,中年人虽然人数少,但其死亡率接近90%。所以,不同的年龄段存在不同的死亡率。
SibSp:
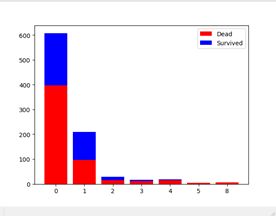
从上图可以看出,大部分乘客SibSp的个数为0(即1人乘船)。此外,能看出0的死亡率较高,1和2的死亡率都在50%附近,其余的乘客死亡率很高。为了简化数据,对于SibSp特征,将其分成3类:I类(0),II类(1,2),III(其余)。
Parch:

从上图可以看出,大部分乘客Parch的个数为0。再看死亡人数与存活人数的比较,Parch为0的乘客死亡率远高于其他,当Parch=1或2时,死亡率将近50%,当Parch>=3时,数据量太小不能直观的判断死亡率,只好把它们全归为一类进行判断。所以,将Parch特征分为3类:I类(0),II类(1,2),III(其余)。
Tciket:
光从Ticket提取不出有用信息,将此类特征舍弃。
Fare:

由于票价数据是数值型,不同值数目过多,将其全部一一显示不方便,先硬性规定将票价归为4类:0-10为第一类,10-50为第二类,50-100为第三类,100-为第四类。上图所示就是四类票对应乘客的生还人数和死亡人数。我们可以得出的结论是:票价越高,生存的几率也就越大。
在预测数据集当中有Fare数据缺失的项,由上图可知购买第二类票的人最多,所以缺失项是属于第二类票的概率最大。
Cabin:
有船舱记录的乘客 无船舱记录的乘客


船舱数据的丢失也很严重,先将无船舱记录也作为一项特征值进行可视化,结果如上图所示。可以发现,有船舱记录的乘客死亡率明显低于无船舱记录的乘客死亡率,说明能将船舱记录为空作为一项特征值进行处理。
Embark:
S港 C港 Q港


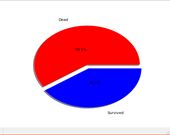
对不同港口上船的乘客进行统计,其中在S港和Q港上船的乘客死亡率比在C港上船的乘客死亡率高,也能说明登船港口与生存具有相关性。
在预测数据集中,有的数据项缺失Embark,本文根据登船人数最多的港口进行填充:
各港口登船人数占比
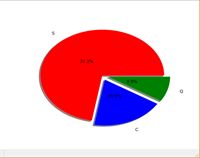
由图可知,在S港登船的人数最多,缺失项为S的概率最大。
4.建立模型及其基本原理
采用三种预测模型(决策树、Adaboost、SVM)进行混合来求得预测结果。
先介绍三种模型的基本原理。
决策树:
决策树中采取CART算法,属于最小二乘回归树生成算法。
算法实现步骤:
1)计算现有样本D的基尼指数,之后利用样本中每一个特征A,及A的每一个可能取值a,根据A>=a与A 2)找出对应基尼指数最小Gini(D,A)的最优切分特征及取值,并判断是否切分停止条件,否,则输出最优切分点 3)递归调用1)2) 4)生成CART决策树 基尼系数: 在分类问题中,假设有K类,样本点属于第k类的概率为pk,则概率分布的基尼指数定义为: Gini(p)=∑Kk=1pk(1−pk)=(p1+p2+...+pK)−∑Kk=1p2k=1−∑Kk=1p2k 对于分类问题:设Ck为D中属于第k类的样本子集,则基尼指数为: Gini(D)=1−∑Kk=1(|Ck||D|)2 设条件A将样本D切分为D1和D2两个数据子集,则在条件A下的样本D的基尼指数为: Gini(D,A)=|D1|DGini(D1)+|D2|DGini(D2) 基尼指数也表示样本的不确定性,基尼指数值越大,样本集合的不确定性越大。 参考:https://blog.csdn.net/LY_ysys629/article/details/72809129 Adaboost: Adaboost是将不同的分类器组合在一起将测试数据集进行分类的方法,分类的结果是基于所有分类器的加权求和结果的,所以分类器的权重并不相等,每个权重代表的是其对应分类器在上一轮迭代中的成功度。 AdaBoost的流程如下: 首先需要给训练数据中的每个样本都要赋予一个权重,这些权重构成了向量D,在算法的最开始,D向量中每个值都是相等的。再通过训练数据训练出分类器,但此时的分类器是弱分类器,不会满足我们的需求,这里可以得到每个分类器的错误率。根据第一次得到的错误率,我们可以更新每一个样本的权重,第一次分对的样本的权重会降低,分错的样本的权重会提高。Adaboost算法也给了每个分类器分配了权重alpha,alpha值的更新也是根据错误率进行计算。 错误率: 分类器权重alpha: 正确分类的样本权重: 错误分类的样本权重: SVM: 支持向量机是一种分类方法,对已有数据集进行多个超平面的划分,将数据分为几类。 参考:https://blog.csdn.net/taichitaichi/article/details/80377900 上图是只用CART决策树得出来的最佳结果,将三种模型的结果一齐进行比较得出的结果反而更差,没有预想中的提升。 分析原因如下: 1.三个模型各自的正确率为:70%(决策树),60%(SVM),50%(Adaboost),在进行多数判断时,可能会比单个判断错的更多。
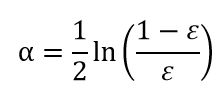

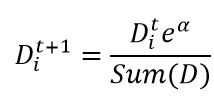


5.最终结果
