solr8学习
一:Solr简介
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
Solr是一个高性能,采用Java5开发,
Solr
基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎
二:Solr服务器的搭建
步骤:
(1)从solr官网下载http://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/8.0.0/solr-8.0.0.tgz下载
(2)配置java环境变量,jdk8
(3)解压下载的压缩包
进入bin目录
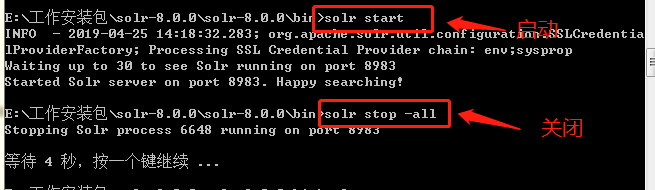
启动之后localhost:8983进入管理页面
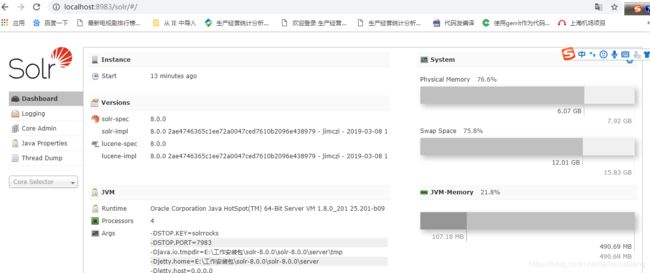
点击coreadmin进入创建核心的页面

点击addCore之前,首先要在 solr文件夹下创建和instanceDir同名的文件夹
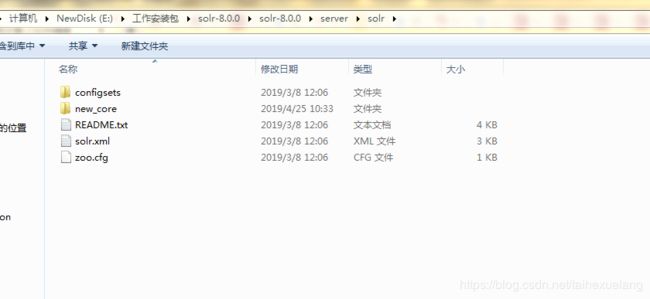
同时把solr-8.0.0\server\solr\configsets\_default下的conf文件夹拷贝到新建的new_core文件夹下,然后点击addcore,则新建成功。
在solr管理页面的coreselector中就可以找到新建new_core核心。
三:Solr服务器配置中文分词器
步骤:
(1)拷贝中文分词器ik-analyzer-solr5-5.x.jar到server\solr-webapp\webapp\WEB-INF\lib文件夹下
(2)在Solr中的server\solr-webapp\webapp\WEB-INF下面创建classes文件目录,用于存放中文分词器的分词配置
ext.dic的内容,比如如下:
高富帅
黑马程序员
二维表
这样的话,碰到这样的词就不会进行拆分了,所以,一些网络新词就可以在这里进行配置。
IKAnalyer.cfg.xml文件
stopwords.dic内容:
我
是
的
a
an
and
are
as
这样的话,对于上面的字就不会进行显示处理了,因为这些都是没有意义的词汇。
(3)在核心solr家中,找到配置文件schema.xml,添加中文分词器的配置。
添加如下内容:
(5)访问Solr主页,进行测试
四:Solr导入数据
(1)增加jar包,在server\solr\new_core\文件夹下创建lib包,把
放进去
(2)创建配置文件
在server\solr\new_core\conf 中创建data-config.xml文件,
url="jdbc:mysql://127.0.0.1:3306/test?serverTimezone=GMT%2B8"
user="root"
password="admin"/>
把data-config.xml配置到solrconfig.xml中,
(3)导入数据,
重新启动solr,在管理页面
entity中就是配置对象。
点击execute按钮把数据库中数据导入到solr服务器中。可以勾选auto-refresh status进行实时处理。
至此导入数据完成

进行测试,但是发现一个问题,就是那么没有出来,只有id。
最后发现了,原来是我在date-config.xml中配置了name这个字段,在managed-schema没有配置
加上这句,最后测试正常了。后来发现这样配置还是有问题,不能检索,如果我name的值是中国人在西边中的瓜,我用中国人来检索却检索不出来,后来发现
中的type应该是中文分词类型。
对于java编程部分,参考上一遍solr文章