1 K-Means聚类收敛性怎么证明?一定会收敛???
2 聚类中止条件:迭代次数、簇中心变化率、最小平方误差MSE???
3 聚类初值的选择,对聚类结果的影响???(K-Means对初值是敏感的)
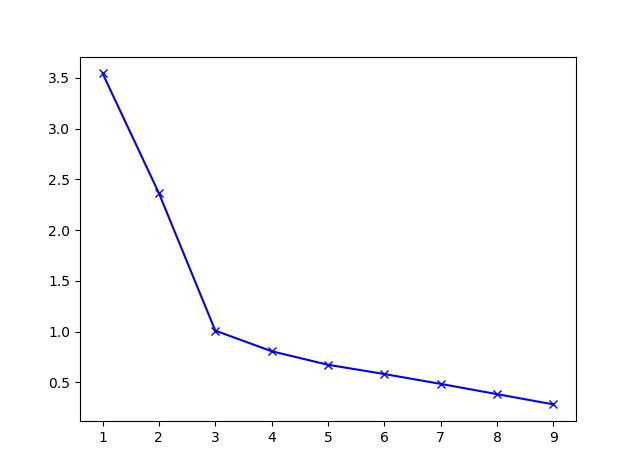
4 肘部选择法——确定聚类数K
没有所谓最好的选择聚类数的方法,通常是需要根据不同的问题,人工进行选择的。选择的时候思考我们运用 K-均值算法聚类的动机是什么,然后选择能最好服务于该目的标聚类数。当人们在讨论,选择聚类数目的方法时,有一个可能会谈及的方法叫作“肘部法则”。关于“肘部法则”,我们所需要做的是改变 K 值,也就是聚类类别数目的总数。我们用一个聚类来运行 K 均值聚类方法。这就意味着,所有的数据都会分到一个聚类里,然后计算成本函数J,K 代表聚类种类。

我们可能会得到一条类似于这样的曲线。像一个人的肘部。这就是“肘部法则”所做的,让我们来看这样一个图,看起来就好像有一个很清楚的肘在那儿。好像人的手臂,如果你伸出你的胳膊,那么这就是你的肩关节、肘关节、手。这就是“肘部法则”。你会发现这种模式,它的畸变值会迅速下降,从 1 到 2,从 2 到 3 之后,你会在 3 的时候达到一个肘点。在此之后,畸变值就下降的非常慢,看起来就像使用 3 个聚类来进行聚类是正确的,这是因为那个点是曲线的肘点,畸变值下降得很快,K 等于 3 之后就下降得很慢,那么我们就选 K 等于 3。当你应用“肘部法则”的时候,如果你得到了一个像上面这样的图,那么这将是一种用来选择聚类个数的合理方法。
uk是第k 个类的重心位置。成本函数是各个类畸变程度(distortions)之和。每个类的畸变程度等于该类重心与其内部成员位置距离的平方和。若类内部的成员彼此间越紧凑则类的畸变程度越小,反之,若类内部的成员彼此间越分散则类的畸变程度越大。求解成本函数最小化的参数就是一个重复配置每个类包含的观测值,并不断移动类重心的过程。
importnumpyasnpimportmatplotlib.pyplotaspltfromsklearn.clusterimportKMeansfromscipy.spatial.distanceimportcdistx = np.array([1,2,3,1,5,6,5,5,6,7,8,9,7,9])y = np.array([1,3,2,2,8,6,7,6,7,1,2,1,1,3])data = np.array(list(zip(x, y)))# 肘部法则 求解最佳分类数# K-Means参数的最优解也是以成本函数最小化为目标# 成本函数是各个类畸变程度(distortions)之和。每个类的畸变程度等于该类重心与其内部成员位置距离的平方和# 画肘部图aa=[]K = range(1,10)forkinrange(1,10): kmeans=KMeans(n_clusters=k) kmeans.fit(data) aa.append(sum(np.min(cdist(data, kmeans.cluster_centers_,'euclidean'),axis=1))/data.shape[0])plt.figure()plt.plot(np.array(K), aa,'bx-')plt.show()# 绘制散点图及聚类结果中心点plt.figure()plt.axis([0,10,0,10])plt.grid(True)plt.plot(x, y,'k.')kmeans = KMeans(n_clusters=3)kmeans.fit(data)plt.plot(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,1],'r.')plt.show()

5 K-Means优缺点及适用范围
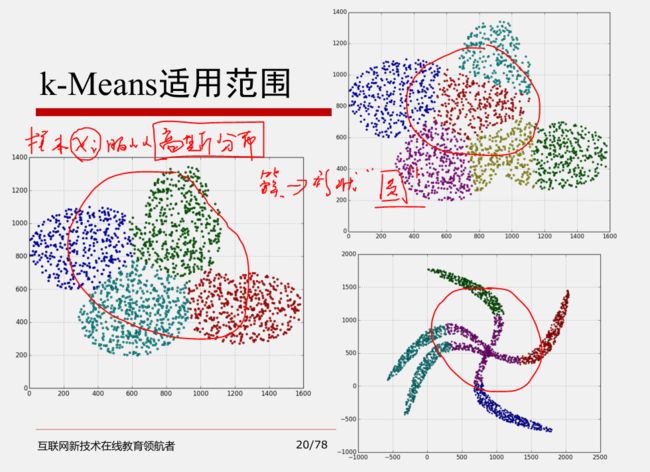

K值需要预先给定,属于预先知识,很多情况下K值的估计是非常困难的,对于像计算全部微信用户的交往圈这样的场景就完全的没办法用K-Means进行。对于可以确定K值不会太大但不明确精确的K值的场景,可以进行迭代运算,然后找出Cost Function最小时所对应的K值,这个值往往能较好的描述有多少个簇类。
K-Means算法对初始选取的聚类中心点是敏感的,不同的随机种子点得到的聚类结果完全不同
K-Means算法并不是适用所有的样本类型。它不能处理非球形簇、不同尺寸和不同密度的簇。
K-Means算法对离群点的数据进行聚类时,K均值也有问题,这种情况下,离群点检测和删除有很大的帮助。(异常值对聚类中心影响很大,需要离群点检测和剔除)
5.K-Means算法对噪声和离群点敏感,最重要是结果不一定是全局最优,只能保证局部最优。
6 从K-Means 到 Gaussian Mixture Model
数据表示
在 k-means 中,我们用单个点来对 cluster 进行建模,这实际上是一种最简化的数据建模形式。这种用点来对 cluster 进行建模实际上就已经假设了各 cluster 的数据是呈圆形(或者高维球形)分布的。但在实际生活中,很少能有这种情况。所以在 GMM 中,我们使用一种更加一般的数据表示,也就是高斯分布。
数据先验
在 k-means 中,我们假设各个 cluster 的先验概率是一样的,但是各个 cluster 的数据量可能是不均匀的。举个例子,cluster A 中包含了10000个样本,cluster B 中只包含了100个。那么对于一个新的样本,在不考虑其与 A B cluster 相似度的情况,其属于 cluster A 的概率肯定是要大于 cluster B的。在 GMM 中,同样对数据先验进行了建模。
相似度衡量
在 k-means 中,我们通常采用欧氏距离来衡量样本与各个 cluster 的相似度。这种距离实际上假设了数据的各个维度对于相似度的衡量作用是一样的。但在 GMM 中,相似度的衡量使用的是后验概率
通过引入协方差矩阵,我们就可以对各维度数据的不同重要性进行建模。
数据分配
在 k-means 中,各个样本点只属于与其相似度最高的那个cluster,这实际上是一种hard clustering。在 GMM 中则使用的是后验概率来对各个cluster 按比例分配,是一种 fuzzy clustering。
Hierarchical Clustering与K-Means和GMM这一派系的聚类算法不太相同:
K-Means 与 GMM 更像是一种 top-down 的思想,它们首先要解决的问题是,确定 cluster 数量,也就是 k 的取值。在确定了 k 后,再来进行数据的聚类。
Hierarchical Clustering 则是一种 bottom-up 的形式,先有数据,然后通过不断选取最相似的数据进行聚类。
K-Means业界用得多的原因之一就是收敛快,现在还能通过分布式计算加速,别的原因有调参就一个K。
作者:7125messi
链接:https://www.jianshu.com/p/cc74c124c00b
來源:
著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。