OpenMiner数据挖掘引擎的主要技术和大体框架
1 数据挖掘技术的基本概述
1.1 数据挖掘技术的基本概念
随着计算机技术的发展,各行各业都开始采用计算机及相应的信息技术进行管理和运营,这使得企业生成、收集、存贮和处理数据的能力大大提高,数据量与日俱增。企业数据实际上是企业的经验积累,当其积累到一定程度时,必然会反映出规律性的东西;对企业来,堆积如山的数据无异于一个巨大的宝库。在这样的背景下,人们迫切需要新一代的计算技术和工具来开采数据库中蕴藏的宝藏,使其成为有用的知识,指导企业的技术决策和经营决策,使企业在竞争中立于不败之地。另一方面,近十余年来,计算机和信息技术也有了长足的进展,产生了许多新概念和新技术,如更高性能的计算机和操作系统、因特网(intemet)、数据仓库(datawarehouse)、神经网络等等。在市场需求和技术基础这两个因素都具备的环境下,数据挖掘技术或称KDD(KnowledgeDiscovery in Databases;数据库知识发现)的概念和技术就应运而生了。
数据挖掘(Data Mining)旨在从大量的、不完全的、有噪声的、模糊的、随机的数据中, 提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识。还有很多和这一术语相近似的术语,如从数据库中发现知识(KDD)、数据分析、数据融合(Data Fusion)以及决策支持等。
1.2 数据挖掘的基本任务
数据挖掘的任务主要是关联分析、聚类分析、分类、预测、时序模式和偏差分析等。
1.
关联分析(association analysis)
关联规则挖掘由Rakesh Apwal等人首先提出。两个或两个以上变量的取值之间存在的规律性称为关联。数据关联是数据库中存在的一类重要的、可被发现的知识。关联分为简单关联、时序关联和因果关联。关联分析的目的是找出数据库中隐藏的关联网。一般用支持度和可信度两个阀值来度量关联规则的相关性,还不断引入兴趣度、相关性等参数,使得所挖掘的规则更符合需求。
2.
聚类分析(clustering)
聚类是把数据按照相似性归纳成若干类别,同一类中的数据彼此相似,不同类中的数据相异。聚 类分析可以建立宏观的概念,发现数据的分布模式,以及可能的数据属性之间的相互关系。
3.
分类(classification)
分类就是找出一个类别的概念描述,它代表了这类数据的整体信息,即该类的内涵描述,并用这 种描述来构造模型,一般用规则或决策树模式表示。分类是利用训练数据集通过一定的算法而求得分类规则。分类可被用于规则描述和预测。
4.
预测(predication)
预测是利用历史数据找出变化规律,建立模型,并由此模型对未来数据的种类及特征进行预测。 预测关心的是精度和不确定性,通常用预测方差来度量。
5.
时序模式(time-series pattern)
时序模式是指通过时间序列搜索出的重复发生概率较高的模式。与回归一样,它也是用己知的数据预测未来的值,但这些数据的区别是变量所处时间的不同。
6.
偏差分析(deviation)
在偏差中包括很多有用的知识,数据库中的数据存在很多异常情况,发现数据库中数据存在的异常情况是非常重要的。偏差检验的基本方法就是寻找观察结果与参照之间的差别。
1.3 数据挖掘常的基本技术
1.
统计学
统计学虽然是一门“古老的”学科,但它依然是最基本的数据挖掘技术,特别是多元统计分析,如判别分析、主成分分析、因子分析、相关分析、多元回归分析等。
统计学虽然是一门“古老的”学科,但它依然是最基本的数据挖掘技术,特别是多元统计分析,如判别分析、主成分分析、因子分析、相关分析、多元回归分析等。
2.
聚类分析和模式识别
聚类分析主要是根据事物的特征对其进行聚类或分类,即所谓物以类聚,以期从中发现规律和典型模式。这类技术是数据挖掘的最重要的技术之一。除传统的基于多元统计分析的聚类方法外,近些年来模糊聚类和神经网络聚类方法也有了长足的发展。
聚类分析主要是根据事物的特征对其进行聚类或分类,即所谓物以类聚,以期从中发现规律和典型模式。这类技术是数据挖掘的最重要的技术之一。除传统的基于多元统计分析的聚类方法外,近些年来模糊聚类和神经网络聚类方法也有了长足的发展。
3.
决策树分类技术
决策树分类是根据不同的重要特征,以树型结构表示分类或决策集合,从而产生规则和发现规律。
4.
人工神经网络和遗传基因算法
人工神经网络是一个迅速发展的前沿研究领域,对计算机科学 人工智能、认知科学以及信息技术等产生了重要而深远的影响,而它在数据挖掘中也扮演着非常重要的角色。人工神经网络可通过示例学习,形成描述复杂非线性系统的非线性函数,这实际上是得到了客观规律的定量描述,有了这个基础,预测的难题就会迎刃而解。目前在数据挖掘中,最常使用的两种神经网络是BP网络和RBF网络 不过,由于人工神经网络还是一个新兴学科,一些重要的理论问题尚未解决。
5.
规则归纳
规则归纳相对来讲是数据挖掘特有的技术。它指的是在大型数据库或数据仓库中搜索和挖掘以往不知道的规则和规律,这大致包括以下几种形式:IF … THEN …
6.
可视化技术
可视化技术是数据挖掘不可忽视的辅助技术。数据挖掘通常会涉及较复杂的数学方法和信息技术,为了方便用户理解和使用这类技术,必须借助图形、图象、动画等手段形象地指导操作、引导挖掘和表达结果等,否则很难推广普及数据挖掘技术。
1.4 数据挖掘技术实施的步骤
数据挖掘的过程
可以分为
6
个步骤:
1)
理解业务:从商业的角度理解项目目标和需求,将其转换成一种数据挖掘的问题定义,设计出达到目标的一个初步计划。
2)
理解数据:收集初步的数据,进行各种熟悉数据的活动。包括数据描述,数据探索和数据质量验证等。
3)
准备数据:将最初的原始数据构造成最终适合建模工具处理的数据集。包括表、记录和属性的选择,数据转换和数据清理等。
4)
建模:选择和应用各种建模技术,并对其参数进行优化。
5)
模型评估:对模型进行较为彻底的评价,并检查构建模型的每个步骤,确认其是否真正实现了预定的商业目的。
6)
模型部署:创建完模型并不意味着项目的结束,即使模型的目的是为了增进对数据的了解,所获得的知识也要用一种用户可以使用的方式来组织和表示。通常要将活动模型应用到决策制订的过程中去。该阶段可以简单到只生成一份报告,也可以复杂到在企业内实施一个可重复的数据挖掘过程。控制得到普遍承认。
1.5 数据挖掘的应用现状
数据挖掘是一个新兴的边缘学科,它汇集了来自机器学习、模式识别、数据库、统计学、人工智能以及管理信息系统等各学科的成果。多学科的相互交融和相互促进,使得这一新学科得以蓬勃发展,而且已初具规模。在美国国家科学基金会(NSF)的数据库研究项目中,KDD被列为90年代最有价值的研究项目。人工智能研究领域的科学家也普遍认为,下一个人工智能应用的重要课题之一,将是以机器学习算法为主要工具的大规模的数据库知识发现。尽管数据挖掘还是一个很新的研究课题,但它所固有的为企业创造巨大经济效益的潜力,已使其很快有了许多成功的应用,具有代表性的应用领域有市场预测、投资、制造业、银行、通讯等。
美国钢铁公司和神户钢铁公司利用基于数据挖掘技术的ISPA系统,研究分析产品性能规律和进行质量控制,取得了显著效果。通用电器公司(GE)与法国飞机发动机制造公司(sNEcMA),利用数据挖掘技术研制了CASSIOP.EE质量控制系统,被三家欧洲航空公司用于诊断和预测渡音737的故障,带来了可观的经济效益。该系统于1996年获欧洲一等创造性应用奖。
享有盛誉的市场研究公司,如美国的A.C.一Nielson和Information Resources,欧洲的GFK和ln.fratest Burk等纷纷开始使用数据挖掘工具来应付迅速增长的销售和市场信息数据。商家的激烈竞争导致了市场快速饱和,产品的迅速更新,使得经营者对市场信息的需求格外强烈利用数据挖掘技术所形成的市场预测能力和服务,使这些市场研究公司取得了巨大收益。
英国广播公司(BBC)也应用数据挖掘技术来预测电视收视率,以便合理安排电视节目时刻表。信用卡公司Alllelicall KxT,ress自采用数据挖掘技术后,信用卡使用率增加了10% 一15%。AT&T公司赁借数据挖掘技术技术侦探国际电话欺诈行为,可以尽快发现国际电话使用中的不正常现象。
中国的公安部门也在研究利用KDD技术总结各类案件的共性和发生规律,从而在宏观上制定最有效的社会治安综合治理的方案和措施;在微观上指出犯罪人的特点,划定罪犯的范围,为侦破工作提供方向。
2 OpenMiner数据挖掘引擎的架构
2.1 大体框架
在开发教务管理决策支持系统过程中,我们自主开发了一个Java平台的通用数据挖掘引擎OpenMiner。OpenMiner是一个独立于教务管理数据库和教务管理决策支持Web平台的数据挖掘服务提供者。OpenMiner作为一个OLAP的服务进程,主要是进行的是海量数据分析运算,运行于数据库后台服务器平台。因为OpenMiner服务程序需要和数据库系统进行大规模的数据交换操作,所以OpenMiner最好的情况是运行于数据库服务器,通过IPC(进程间通信)或者Windows的Pipe(管道)来与数据库交互,效率是要高于基于TCP网络的连接。
OpenMiner
数据挖掘引引擎在整个教务决策支持系统中处于最核心的地位。教务决策支持系统的Web服务程序根据用户的可视化操作以及教务数据库具体的部署,构造相应的基于XML的数据挖掘原语,通过TCP网络连接,发送数据挖掘原语至OpenMiner服务进程,OpenMiner在接收到挖掘原语后,解释其挖掘原语的意义,执行相关的数据挖掘任务,最后将挖掘完成的结果再次通过TCP网络连接返回给Web服务程序。

图2.1 OpenMiner在决策支持系统的结构图
OpenMiner
是分成了关联规则挖掘,分类规则挖掘和聚类分析三大模块。本人做的主要是OpenMiner的关联规则挖掘以及OpenMiner系统架构部分。
OpenMiner
挖掘引擎是一个基于数据挖掘模型Model的数据分析引擎。通过定义挖掘模型Model,将数据挖掘的任务分成模型的定义,模型的训练和模型的使用。挖掘引擎所做的工作以及前台用户的交流,也始终围绕挖掘模型而展开。前台用户操作挖掘引擎使用的数据挖掘原语分成模型定义原语,模型训练原语和模型使用原语。

图2.2 OpenMiner挖掘任务的三个部分
2.2 连接配置
2.2.1 与数据库的连接配置
OpenMiner
在安装完成后,需要将数据库的连接信息,URL,用户名,密码等,填写于OpenMiner 的数据库配置文件dbserver.xml。这些信息是在安装部署OpenMiner数据挖掘服务的时候所完成的工作,出于安全考虑,这些信息是不通过前段Web Server来传递进来的。
下面是一个dbserver.xml的例子:
其中的url就是我在测试连接局域网内的192.168.0.7的一个Oracle服务器地址。由于dbserver.xml配置文件存放于后台服务器,再出于简单方便考虑,后面的username,password都还是明文保存。
2.2.2 与Web Server的连接配置
OpenMiner
对于挖掘服务使用者提供有自己的一个权限的管理,通过property.xml来配置主要的Web Server前台连接。
下面是property.xml的例子:
property
根元素的port属性定义了OpenMiner服务监听的TCP端口号。
其中,定义了一个名字和密码都叫test的客户端帐号,max属性定义了该帐号的最大的连接线程个数为5。同时,这个test用户对应的使用的数据库帐号为TL。前面的dbserver.xml中已经定义了用户名为TL的数据库帐号。那么OpenMiner将使用的TL这个数据库帐号进行内部的挖掘任务。至于TL这个帐号到底能够访问哪个数据库,访问数据库内的哪个表,就由dbserver.xml和数据库来决定了。
2.3 线程对象池
为了提高效率和稳定性,连接池和线程池技术已经普遍使用于多线程数据库服务程序中
[14,15]
。OpenMiner在主要做的是一种OLAP数据分析服务,连接池与线程池的实现比较简单。一个非并行的数据挖掘分析服务只需要一个线程和一个数据库连接。

图2.3 线程对象池
图中,每个线程对象都是一个MinerThread对象,MinerThread对象继承于Java Thread线程对象。每个MinerThread拥有一个Connection数据库连接。所以,当线程对象存活的时候,Connection就始终存活。
OpenMiner
的线程对象管理模块统一对每个线程以及其数据库连接进行创建,管理和销毁。Miner挖掘服务并不需要自己创建关闭线程和创建关闭数据库连接。OpenMiner服务运行中一旦监听到由客户端的请求,会根据请求的类型信息,来分配一个“空闲”状态的线程对象来进行数据挖掘服务。当数据挖掘服务完成后,OpenMiner线程对象管理模块收回其分配的线程对象,并且置于“空闲”状态。
2.4 挖掘算法模块
上一节已经提到过,OpenMiner中,一个MinerThread就是一个挖掘服务的实例。MinerThread对象一旦接收到“命令”后,从“空闲”状态转向“工作”,就会根据具体的挖掘原语来调用相关的挖掘算法模块来执行数据挖掘任务。
OpenMiner
内部提供了关联,分类,聚类各种不同的挖掘算法模块,我们会其后的开发过程中逐步增加完善。
Miner
是所有挖掘算法模块的抽象父类,里面定义所有挖掘算法模块的公共接口函数,不同的算法模块都要求实现其基本接口。
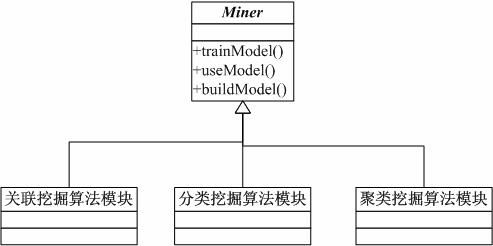
图2.4 算法模块之间的继承关系