pandas关于读写文件(大部分都是链接别人的文章)
一、关于pandas.read_csv()参数的理解
参考一
参考二
在read_csv()的过程中可以设置行索引。
【代码演示】:
import pandas as pd
col1=["a","b","c","d"]
col2=["一","二","三","四"]
col3=["","","",""]
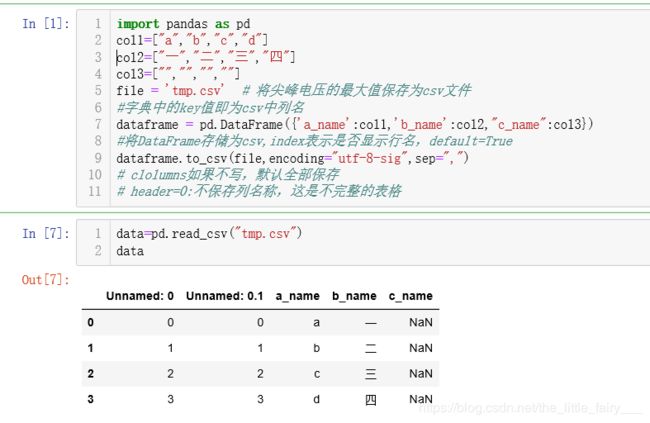
file = 'tmp.csv' # 将尖峰电压的最大值保存为csv文件
#字典中的key值即为csv中列名
dataframe = pd.DataFrame({'a_name':col1,'b_name':col2,"c_name":col3})
#将DataFrame存储为csv,index表示是否显示行名,default=True
dataframe.to_csv(file,encoding="utf-8-sig",sep=",")
# clolumns如果不写,默认全部保存
# header=0:不保存列名称,这是不完整的表格
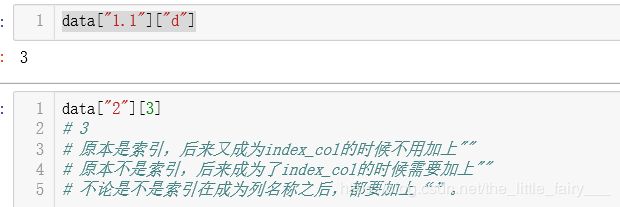
data=pd.read_csv("tmp.csv")
data

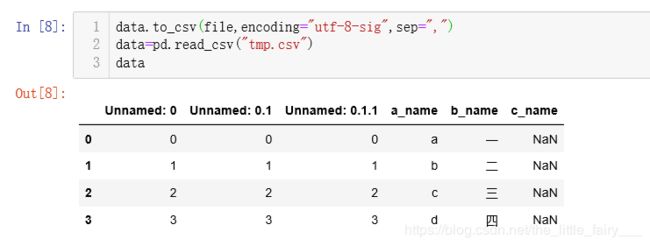
data.to_csv(file,encoding="utf-8-sig",sep=",")
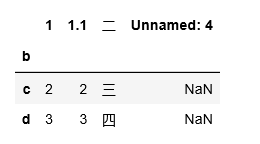
data=pd.read_csv("tmp.csv",index_col=2,header=2)
# 可以发现索引的条目变成了第二列
data
二、关于pandas.to_csv()参数的理解
参考
【相关程序】:
三、合并两个.csv文件
参考一
参考二
四、创建.csv文件
一、逐行写入:
注意writerow和writerows的区别
import csv
col=["a","b","c","d"]
row=["一","二","三","四"]
max_file = 'tmp.csv' # 将尖峰电压的最大值保存为csv文件
#python2可以用file替代open
with open(max_file,'w', encoding='utf-8-sig') as f:
writer = csv.writer(f)
#先写入columns_name
writer.writerow(col)
#写入多行用writerows
writer.writerows([[row_item] for row_item in row])
【解释】
如果不使用utf-8-sig会出现中文乱码的情况,只用utf-8不行
【效果】
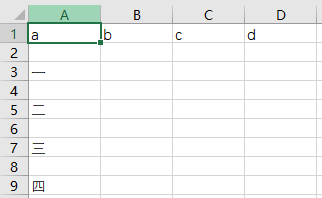
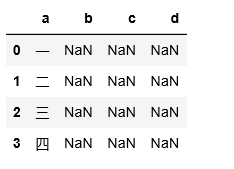
在jupyter 里面的展示效果
【如果希望在.csv文件里面没有中间的空行】
将with open(max_file,'w', encoding='utf-8-sig') as f: 更改成with open(max_file,'w',newline="", encoding='utf-8-sig') as f:
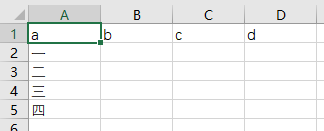
二、利用pandas包
import pandas as pd
col1=["a","b","c","d"]
col2=["一","二","三","四"]
file = 'tmp.csv' # 将尖峰电压的最大值保存为csv文件
#字典中的key值即为csv中列名
dataframe = pd.DataFrame({'a_name':col1,'b_name':col2})
#将DataFrame存储为csv,index表示是否显示行名,default=True
dataframe.to_csv(file,encoding="utf-8-sig",index=False,sep=',')
【效果】
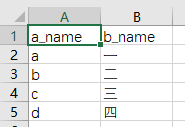
【注意不保留行索引】
如果没有加上index=“False”,会发现前面多了一行,创造了一行行索引
五、连接列表元素
a=["i","love","you!"]
" ".join(a)
【输出】:
![]()
六、python获取当前路径的问题
import os,sys
if __name__=="__main__":
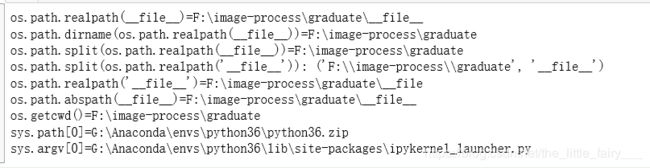
print ("os.path.realpath(__file__)=%s" % os.path.realpath('__file__'))
print ("os.path.dirname(os.path.realpath(__file__))=%s" % os.path.dirname(os.path.realpath('__file__')))
# 获取当前文件的目录
print ("os.path.split(os.path.realpath(__file__))=%s" % os.path.split(os.path.realpath('__file__'))[0])
# 得到一个列表,分别是目录以及文件名
print("os.path.split(os.path.realpath('__file__')):",os.path.split(os.path.realpath('__file__')))
print("os.path.realpath('__file__')=%s"%os.path.realpath("__file"))
# 获取file的完整路径
print ("os.path.abspath(__file__)=%s" % os.path.abspath('__file__'))
print ("os.getcwd()=%s" % os.getcwd())
print ("sys.path[0]=%s" % sys.path[0])
print ("sys.argv[0]=%s" % sys.argv[0])
【输出】:
七、使用glob.glob()
参考文档
八、获取当前文件夹下的文件信息
参考文档
九、python文件中几种读写方式(w,r,)的区别
1、r表示只读,r+读写,都不创建;
2、w新建只写,w+新建读写,两者都会将内容清零。以w方式打开不能读出。
3、w+与r+区别:
r+:可读可写,若文件不存在,报错;w+: 可读可写,若文件不存在,创建
4、r+与a+区别:
fd = open("1.txt",'w+')
fd.write('123')
fd = open("1.txt",'r+')
fd.write('456')
fd = open("1.txt",'a+')
fd.write("789")
fd.close()
结果:456789
这个文件必须得注意关闭,关闭之后再打开才会出现456789,否则只有456
说明r+进行了覆盖写。
5、以a,a+的方式打开文件,附加方式打开
a:附加写方式打开,不可读;
a+: 附加读写方式打开
w和a是不可以读的方式。
若不存在会创建新文件的打开方式:a,a+,w,w+
6、
fd=open(r'2.txt','a+')
fd.write('123')
fd.read()
输出:“”空的结果
7、
fd=open(r'2.txt','a+')
fd.seek(0)
fd.read()
输出:“123”
8、
fd=open(r'2.txt','w+') #清空内容,重新写入
fd.write('456')
fd.flush()#确定写入,此时文件内容为“456”
fd.read()
#因为指针仍然在|最后
#也就是123EOF
输出:“”结果是空的
9、
解决方案一、调用close后重新打开,指针位于开头。(r,r+,a+,U都可以,注意不要用w,w+,a打开)
fd.close()
fd=open(r'f:\mypython\test.py','a+')
fd.read()
# '456'
fd.close()
fd=open(r'f:\mypython\test.py','r+')
fd.read()
# '456'
fd=open(r'f:\mypython\test.py','r')
fd.read()
# '456'
fd.close()
fd=open(r'f:\mypython\test.py','U')
fd.read()
# '456'
10、解决方案二、调用seek指向开头
fd=open(r'f:\mypython\test.py','w+')
fd.write('456')
fd.seek(0)
fd.read()
# '456'
11、seek函数
seek(offset[, whence]) ,offset是相对于某个位置的偏移量。位置由whence决定,默认whence=0,从开头起;whence=1,从当前位置算起;whence=2相对于文件末尾移动,通常offset取负值。
12、记得close()关闭
当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。所以,还是用with语句来得保险:
with open('/Users/michael/test.txt', 'w') as f:
f.write('Hello, world!')
13、关于file.flush的理解:
一般的文件流操作都包含缓冲机制,write方法并不直接将数据写入文件,而是先写入内存中特定的缓冲区。
flush方法是用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区。
正常情况下缓冲区满时,操作系统会自动将缓冲数据写入到文件中。
至于close方法,原理是内部先调用flush方法来刷新缓冲区,再执行关闭操作,这样即使缓冲区数据未满也能保证数据的完整性。
如果进程意外退出或正常退出时而未执行文件的close方法,缓冲区中的内容将会丢失。
参考
?、遇到的问题——SettingWithCopyWarning
https://www.jianshu.com/p/72274ccb647a
十一、python在.csv文件中写入中文字符
参考
【关键代码】:
#!python3
#coding:utf8
import csv
data = [[u'American',u'美国人'],
[u'Chinese',u'中国人']]
with open('results.csv','w',newline='',encoding='utf-8-sig') as f:
w = csv.writer(f)
w.writerows(data)