stagefright之MPEG4Extractor(二)(stts,stsc,stco)
上一篇,我们讲了,Track是这样一个结构体:
struct Track { Track *next; spmeta; uint32_t timescale; sp sampleTable; bool includes_expensive_metadata; bool skipTrack; }; spmeta主要用来存一些影片宽高,编码,时间长度等等一些,信息。 从这篇开始,我们着重讲spsampleTable,这个成员是用来描述MP4的sample(也就是其他容器里的frame)的组织形式。 我们都看过胶片电影,都是一帧一帧的播放的,一秒钟放24帧画面,就可以展现连贯的动画。而针对数字媒体时代,我们需要解决的问题是如何在文件中找到我们指定的帧来播放,对mp4,就是要找到指定的sample.在文件中的偏移位置,sample的大小。
//Time-to-Sample Atoms - STTS
该box可以使我们通过时间来计算对应的sampleIndex,所以叫time to sample:
更详细的物理结构(举例):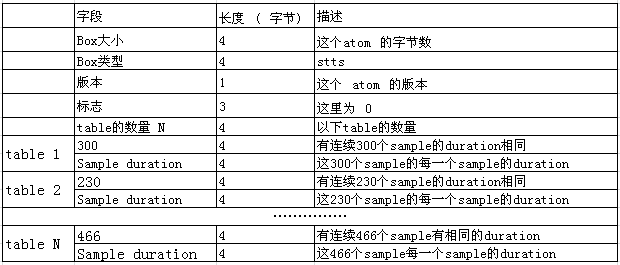
以上table将每一个sample的duration都描述出来了,那么请思考,如果给一个具体时间,例如第25秒,要查出第25秒是第几个sample.我们将以上duration从第一个sample到N个sample 的duration求和,如果和大于25秒(严格说是25*timescale),那么N-1就是第25秒所在的sample Index.通过这个sampleIndex,我们后面再通过一系列运算,就可以得到这个sample的实际媒体数据在文件中的偏移位置offset,从而可以读出了给解码器解码。//Mpeg4Extractor代码case FOURCC('s', 't', 't', 's'): { //这里的data_offset是box size和box type后第一个字节为基准的,也就每个box的offset+8 status_t err = mLastTrack->sampleTable->setTimeToSampleParams( data_offset, chunk_data_size); if (err != OK) { return err; } *offset += chunk_size; break; } .............................. status_t SampleTable::setTimeToSampleParams( off64_t data_offset, size_t data_size) { if (mTimeToSample != NULL || data_size < 8) { return ERROR_MALFORMED; } uint8_t header[8]; if (mDataSource->readAt( data_offset, header, sizeof(header)) < (ssize_t)sizeof(header)) { return ERROR_IO; } if (U32_AT(header) != 0) { // Expected version = 0, flags = 0. return ERROR_MALFORMED; } mTimeToSampleCount = U32_AT(&header[4]);//获取table的数量 //为什么要乘以2?看上面表格,因为每一个table包含两个元素啊,sample duration和相同duration的sample数量 mTimeToSample = new uint32_t[mTimeToSampleCount * 2]; size_t size = sizeof(uint32_t) * mTimeToSampleCount * 2; //一次性将所有table读进数组,偶数下标放 sample duration,奇数下标放有相同duration的sample数量 if (mDataSource->readAt( data_offset + 8, mTimeToSample, size) < (ssize_t)size) { return ERROR_IO; } for (uint32_t i = 0; i < mTimeToSampleCount * 2; ++i) { mTimeToSample[i] = ntohl(mTimeToSample[i]); } return OK; }
Sample-to-Chunk Atoms - STSC
mp4里的多个sample组合成chunk,前面我们通过STTS(time to sample),通过time 来算出对应的sample Index;这里,我们通过STSC(sample to chunk)这个box,通过 sample Index 来算出对应的chunk index,后面我们还有一个STCO(chunk to offset),我们再通过chunk index可以得到每一个chunk在文件中的偏移量offset,从而找到媒体数据,所以打通了由time找到sample数据这条通路,这才是最终目的。STSC box就是用来描述由sample组成的chunk的。可能你现在还不知道为什么要组成chunk,有什么好处,等下你看完就知道了。先来抽象描述一下这个box的结构:
下面是关于Entry更具体的物理结构如下:sample组成chunk,而具有相同sample数量的chunk组成Entry.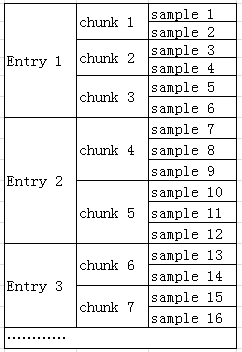
关于上表所写的First Chunk,比如Entry 1, First Chunk是1,Entry 2,First Chunk 是4,Entry3,First Chunk是6.因为该box里只提供First Chunk 和 Samples per chunk,我们我们无法直接知道每个Entry有多少个Chunk和sample.例如,我们可以用Entry 2的First Chunk减去Entry 1的 FirstChunk,即可得到Entry 1有多少个Chunk了。知道多少Chunk,然后乘以samplePerChunk就知道多少sample.
理解了这些后,试想,如果告诉一个sample index,比如第12个sample,能计算出这个sample位于第几个chunk吗?这个算法应该不难实现。我们来看MPEG4Extractor的代码,
case FOURCC('s', 't', 's', 'c'): { status_t err = mLastTrack->sampleTable->setSampleToChunkParams( data_offset, chunk_data_size); if (err != OK) { return err; } *offset += chunk_size; break; } .......................... status_t SampleTable::setSampleToChunkParams( off64_t data_offset, size_t data_size) { if (mSampleToChunkOffset >= 0) { return ERROR_MALFORMED; } mSampleToChunkOffset = data_offset; if (data_size < 8) { return ERROR_MALFORMED; } uint8_t header[8]; if (mDataSource->readAt( data_offset, header, sizeof(header)) < (ssize_t)sizeof(header)) { return ERROR_IO; } if (U32_AT(header) != 0) { // Expected version = 0, flags = 0. return ERROR_MALFORMED; } mNumSampleToChunkOffsets = U32_AT(&header[4]);//Entry的数量 if (data_size < 8 + mNumSampleToChunkOffsets * 12) { return ERROR_MALFORMED; } mSampleToChunkEntries = new SampleToChunkEntry[mNumSampleToChunkOffsets]; for (uint32_t i = 0; i < mNumSampleToChunkOffsets; ++i) { uint8_t buffer[12]; if (mDataSource->readAt( mSampleToChunkOffset + 8 + i * 12, buffer, sizeof(buffer)) != (ssize_t)sizeof(buffer)) { return ERROR_IO; } CHECK(U32_AT(buffer) >= 1); // chunk index is 1 based in the spec. // We want the chunk index to be 0-based. mSampleToChunkEntries[i].startChunk = U32_AT(buffer) - 1; mSampleToChunkEntries[i].samplesPerChunk = U32_AT(&buffer[4]); mSampleToChunkEntries[i].chunkDesc = U32_AT(&buffer[8]); } return OK; }
可以看出,Google将STST这个box的相关信息放在mSampleToChunkEntries这个结构体数组里。好,到这里为止,我们已经建立了从 time--->sampleIndex--------->chunkIndex 这条通道了。下面这个box,就要建立chunkIndex----->ChunkOffset的通道。
Chunk Offset Atoms - STCOSTCO其实最简单了,主要是通过Chunk index来获取该Chunk的offset.
MPEG4Extractor代码
case FOURCC('s', 't', 'c', 'o'): case FOURCC('c', 'o', '6', '4'): { status_t err = mLastTrack->sampleTable->setChunkOffsetParams( chunk_type, data_offset, chunk_data_size); if (err != OK) { return err; } *offset += chunk_size; break; } .................................. status_t SampleTable::setChunkOffsetParams( uint32_t type, off64_t data_offset, size_t data_size) { if (mChunkOffsetOffset >= 0) { return ERROR_MALFORMED; } CHECK(type == kChunkOffsetType32 || type == kChunkOffsetType64); mChunkOffsetOffset = data_offset; mChunkOffsetType = type; if (data_size < 8) { return ERROR_MALFORMED; } uint8_t header[8]; if (mDataSource->readAt( data_offset, header, sizeof(header)) < (ssize_t)sizeof(header)) { return ERROR_IO; } if (U32_AT(header) != 0) { // Expected version = 0, flags = 0. return ERROR_MALFORMED; } mNumChunkOffsets = U32_AT(&header[4]); if (mChunkOffsetType == kChunkOffsetType32) { if (data_size < 8 + mNumChunkOffsets * 4) { return ERROR_MALFORMED; } } else { if (data_size < 8 + mNumChunkOffsets * 8) { return ERROR_MALFORMED; } } return OK; }
setChunkOffsetParams也没有太多可讲的.主要是获取到这个STCO box的mChunkOffsetOffset ,也就是加上box size和box type后的offset.我们来看看,如果通过chunkIndex来获取chunk offsetstatus_t SampleIterator::getChunkOffset(uint32_t chunk, off64_t *offset) { *offset = 0; if (chunk >= mTable->mNumChunkOffsets) { return ERROR_OUT_OF_RANGE; } if (mTable->mChunkOffsetType == SampleTable::kChunkOffsetType32) { uint32_t offset32; //mChunkOffsetOffset为上面表格中“版本”这个字段算,加8,就移动到Chunk 1 offset,每个offset大小为4,所以乘以4; if (mTable->mDataSource->readAt( mTable->mChunkOffsetOffset + 8 + 4 * chunk, &offset32, sizeof(offset32)) < (ssize_t)sizeof(offset32)) { return ERROR_IO; } *offset = ntohl(offset32); } else { CHECK_EQ(mTable->mChunkOffsetType, SampleTable::kChunkOffsetType64); uint64_t offset64; if (mTable->mDataSource->readAt( mTable->mChunkOffsetOffset + 8 + 8 * chunk, &offset64, sizeof(offset64)) < (ssize_t)sizeof(offset64)) { return ERROR_IO; } *offset = ntoh64(offset64); } return OK; }
