自然语言处理入门新手上路
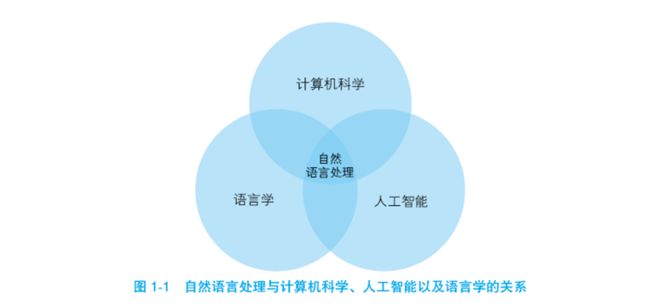
自然语言处理 (Natural Language Processing,NLP)是一门融合了计算机科学、人工智能以及语言学的交叉学科,它们的关系如图 1-1 所示。这门学科研究的是如何通过机器学习等技术,让计算机学会处理人类语言,乃至实现终极目标——理解人类语言或人工智能①。
事实上,自然语言处理这个术语并没有被广泛接受的定义②。注重语言学结构的学者喜欢使用 计算语言学 (Computational Linguistics,CL)这个表达,而强调最终目的的学者则更偏好 自然语言理解 (Natural Language Understanding,NLU)这个术语。由于 NLP 听上去含有更多工程意味,所以本书将一直使用该术语,而不去细究它们的异同。
如同其本身的复杂性一样,自然语言处理一直是一个艰深的课题。虽然语言只是人工智能的一部分(人工智能还包括计算机视觉等),但它非常独特。这个星球上有许多生物拥有超过人类的视觉系统,但只有人类才拥有这么高级的语言。自然语言处理的目标是让计算机处理或 “理解”自然语言,以完成有意义的任务,比如订机票、购物或同声传译等。完全理解和表达语言是极其困难的,完美的语言理解等价于实现人工智能。
在这一章中,我们将围绕自然语言处理的缩略图,了解一些基本概念。
① 著名的图灵测试就是根据机器是否能像人类一样理解语言来判断它是否具备人工智能。
② Smith N. A. Linguistic structure prediction[J]. Synthesis lectures on human language technologies, 2011, 4(2): 1-274.1.1 自然语言与编程语言
作为我们将要处理的对象,自然语言具备高度灵活的特点。我们太熟悉自己的语言,就像水对鱼来讲是透明的一样,我们很难体会到语言的复杂程度。不如拿自然语言与人工语言做一番比较,看看计算机理解我们的语言是多么困难。
1.1.1 词汇量
自然语言中的词汇比编程语言中的关键词丰富。在我们熟悉的编程语言中,能使用的关键词数量是有限且确定的。比如,C 语言一共有 32 个关键字,Java 语言则有 50 个。虽然我们可以自由地取变量名、函数名和类名,但这些名称在编译器看来只是区别符号,不含语义信息,也不影响程序的运行结果。但在自然语言中,我们可以使用的词汇量是无穷无尽的,几乎没有意义完全相同的词语。以汉语为例,由国家语言文字工作委员会发布的《现代汉语常用词表(草案)》一共收录了 56 008 个词条。除此之外,我们还可以随时创造各种类型的新词,而不仅限于名词。
1.1.2 结构化
自然语言是非结构化的,而编程语言是结构化的。所谓结构化,指的是信息具有明确的结构关系,比如编程语言中的类与成员、数据库中的表与字段,都可以通过明确的机制来读写。举个例子,我们来看看两种语言对同一事实的表述,一些面向对象的编程语言可以如此书写:
class Company(object):
def __init__(self, founder, logo) -> None:
self.founder = founder
self.logo = logo
apple = Company(founder=‘乔布斯’, logo=‘apple’)
于是,程序员可以通过 apple.founder和 apple.logo来获取苹果公司的创始人和标志。像这样,程序语言通过 class Company这个结构为信息提供了层次化的模板,而在自然语言中则不存在这样的显式结构。人类语言是线性的字符串,给定一句话“苹果的创始人是乔布斯,它的 logo 是苹果”,计算机需要分析出如下结论:
●这句汉语转换为单词序列后,应该是“苹果 的 创始人 是 乔布斯 , 它 的 logo 是 苹果”;
●第一个“苹果”指的是苹果公司,而第二个“苹果”指的是带缺口的苹果 logo ;
● “乔布斯”是一个人名;
● “它”指代的是苹果公司;
●苹果公司与乔布斯之间的关系是“的创始人是”,与带缺口的苹果 logo 之间的关系为“的logo 是”。
这些结论的得出分别涉及中文分词、命名实体识别、指代消解和关系抽取等自然语言处理任务。这些任务目前的准确率都达不到人类水平。可见,人类觉得很简单的一句话,要让计算机理解起来并不简单。
1.1.3 歧义性
自然语言含有大量歧义,这些歧义根据语境的不同而表现为特定的义项。比如汉语中的多义词,只有在特定的上下文中才能确定其含义,甚至存在故意利用无法确定的歧义营造幽默效果的用法。除了上文“苹果”的两种意思之外,“意思”这个词也有多种意义。比如,下面这则经典的笑话。
他说:“她这个人真有意思(funny)。”她说:“他这个人怪有意思的(funny)。”于是人们以为他们有了意思(wish),并让他向她意思意思(express)。他火了:“我根本没有那个意思(thought)!”她也生气了:“你们这么说是什么意思(intention)?”事后有人说:“真有意思(funny)。”也有人说:“真没意思(nonsense)。”(原文见《生活报》1994.11.13. 第六版)[吴尉天,1999]①
这个例子中特地用英文注解“意思”的不同义项,从侧面体现了处理中文比处理英文更难。
但在编程语言中,则不存在歧义性②。如果程序员无意中写了有歧义的代码,比如两个函数的签名一样,则会触发编译错误。
1.1.4 容错性
书刊中的语言即使经过编辑的多次校对,也仍然无法完全避免错误。而互联网上的文本则更加随性,错别字或病句、不规范的标点符号等随处可见。不过,哪怕一句话错得再离谱,人们还是可以猜出它想表达的意思。而在编程语言中,程序员必须保证拼写绝对正确、语法绝对规范,否则要么得到编译器无情的警告,要么造成潜在的 bug。
事实上,区别于规范的新闻领域,如何处理不规范的社交媒体文本也成为了一个新的课题。
① 摘自宗成庆《统计自然语言处理》。
② 编程语言被特意设计为无歧义的确定上下文无关文法,并且能在 O(n) 时间内分析完毕,其中 n 为文本长度。1.1.5 易变性
任何语言都是不断发展变化的,不同的是,编程语言的变化要缓慢温和得多,而自然语言则相对迅速嘈杂一些。
编程语言由某个个人或组织发明并且负责维护。以 C++ 为例,它的发明者是 Bjarne Stroustrup,它现在由 C++ 标准委员会维护。从 C++ 98 到 C++ 03,再到 C++ 11 和 C++ 14,语言标准的变化是以年为单位的迁越过程,且新版本大致做到了对旧版本的前向兼容,只有少数废弃掉的特性。
而自然语言不是由某个个人或组织发明或制定标准的。或者说,任何一门自然语言都是由全人类共同约定俗成的。虽然存在普通话、简体字等规范,但我们每个人都可以自由创造和传播新词汇和新用法,也在不停地赋予旧词汇以新含义,导致古代汉语和现代汉语相差巨大。此外,汉语不断吸收英语和日语等外语中的词汇,并且也在输出 niubility 等中式英语。这些变化是连续的,每时每刻都在进行,给自然语言处理带来了不小的挑战。这也是自然语言明明是人类发明的,却还要称作“自然”的原因。
1.1.6 简略性
由于说话速度和听话速度、书写速度和阅读速度的限制,人类语言往往简洁、干练。我们经常省略大量背景知识或常识,比如我们会对朋友说“老地方见”,而不必指出“老地方”在哪里。对于机构名称,我们经常使用简称,比如“工行”“地税局”,假定对方熟悉该简称。如果上文提出一个对象作为话题,则下文经常使用代词。在连续的新闻报道或者一本书的某一页中,并不需要重复前面的事实,而假定读者已经熟知。这些省略掉的常识,是交流双方共有而计算机不一定拥有的,这也给自然语言处理带来了障碍。
1.2 自然语言处理的层次
按照处理对象的颗粒度,自然语言处理大致可以分为图 1-2 所示的几个层次。
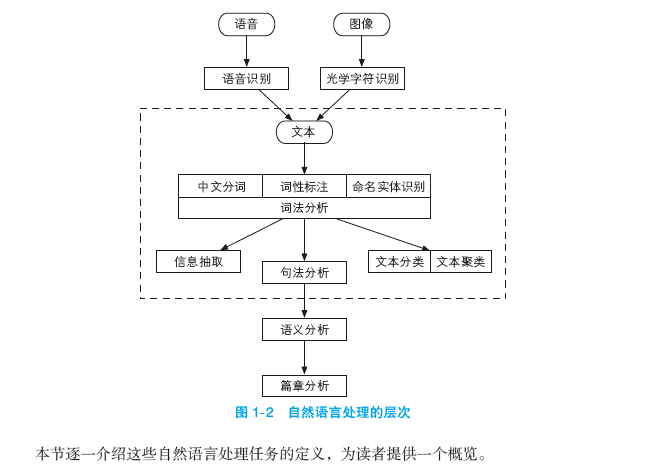
本节逐一介绍这些自然语言处理任务的定义,为读者提供一个概览。
1.2.1 语音、图像和文本
自然语言处理系统的输入源一共有 3 个,即语音、图像与文本。其中,语音和图像虽然正引起越来越大的关注,但受制于存储容量和传输速度,它们的信息总量还是没有文本多。另外,这两种形式一般经过识别后转化为文本,再进行接下来的处理,分别称为语音识别(Speech Recognition)和光学字符识别(Optical Character Recognition)。一旦转化为文本,就可以进行后续的 NLP 任务。所以,文本处理是重中之重。
1.2.2 中文分词、词性标注和命名实体识别
这 3 个任务都是围绕词语进行的分析,所以统称词法分析。词法分析的主要任务是将文本分隔为有意义的词语(中文分词),确定每个词语的类别和浅层的歧义消除(词性标注),并且识别出一些较长的专有名词(命名实体识别)。对中文而言,词法分析常常是后续高级任务的基础。在流水线式① 的系统中,如果词法分析出错,则会波及后续任务。所幸的是,中文词法分析已经比较成熟,基本达到了工业使用的水准。
① 指的是前一个系统的输出是后一个系统的输入,并且前一个系统不依赖于后续系统。作为一个初级且资源丰富的任务,词法分析将在本书后续章节中详细阐述。另外,由于这是读者接触的第一个 NLP 任务,它将引出许多有趣的模型、算法和思想。因此,词法分析不仅是自然语言处理的基础任务,它所属的章节也会成为读者知识体系的基础。
1.2.3 信息抽取
词法分析之后,文本已经呈现出部分结构化的趋势。至少,计算机看到的不再是一个超长的字符串,而是有意义的单词列表,并且每个单词还附有自己的词性以及其他标签。
根据这些单词与标签,我们可以抽取出一部分有用的信息,从简单的高频词到高级算法提取出的关键词,从公司名称到专业术语,其中词语级别的信息已经可以抽取不少。我们还可以根据词语之间的统计学信息抽取出关键短语乃至句子,更大颗粒度的文本对用户更加友好。
值得一提的是,一些信息抽取算法用到的统计量可以复用到其他任务中,会在相应章节中详细介绍。
1.2.4 文本分类与文本聚类
将文本拆分为一系列词语之后,我们还可以在文章级别做一系列分析。
有时我们想知道一段话是褒义还是贬义的,判断一封邮件是否是垃圾邮件,想把许多文档分门别类地整理一下,此时的 NLP 任务称作文本分类。
另一些时候,我们只想把相似的文本归档到一起,或者排除重复的文档,而不关心具体类别,此时进行的任务称作文本聚类。
这两类任务看上去挺相似,实际上分属两种截然不同的算法流派,我们会在单独的章节中分别讲解。
1.2.5 句法分析
词法分析只能得到零散的词汇信息,计算机不知道词语之间的关系。在一些问答系统中,需要得到句子的主谓宾结构。比如“查询刘医生主治的内科病人”这句话,用户真正想要查询的不是“刘医生”,也不是“内科”,而是“病人”。虽然这三个词语都是名词,甚至“刘医生” 离表示意图的动词“查询”最近,但只有“病人”才是“查询”的宾语。通过句法分析,可以得到如图 1-3 所示的语法信息。
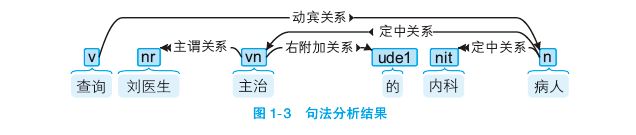
我们发现图 1-3 中果然有根长长的箭头将“查询”与“病人”联系起来,并且注明了它们之间的动宾关系。后续章节会详细介绍上面这种树形结构,以及句法分析器的实现方法。
不仅是问答系统或搜索引擎,句法分析还经常应用于基于短语的机器翻译,给译文的词语重新排序。比如,中文“我吃苹果”翻译为日文后则是“私は(我)林檎を(苹果)食べる(吃)”,两者词序不同,但句法结构一致。
1.2.6 语义分析与篇章分析
相较于句法分析,语义分析侧重语义而非语法。它包括词义消歧(确定一个词在语境中的含义,而不是简单的词性)、语义角色标注(标注句子中的谓语与其他成分的关系)乃至语义依存分析(分析句子中词语之间的语义关系)。
随着任务的递进,它们的难度也逐步上升,属于较为高级的课题。即便是最前沿的研究,也尚未达到能够实用的精确程度。另外,相应的研究资源比较稀缺,大众难以获取,所以本书不会涉及。
1.2.7 其他高级任务
除了上述“工具类”的任务外,还有许多综合性的任务,与终端应用级产品联系更紧密。比如:
● 自动问答,根据知识库或文本中的信息直接回答一个问题,比如微软的Cortana和苹果的Siri;
● 自动摘要,为一篇长文档生成简短的摘要;
● 机器翻译,将一句话从一种语言翻译到另一种语言。
注意,一般认为信息检索(Information Retrieve,IR)是区别于自然语言处理的独立学科。虽然两者具有密切的联系,但 IR 的目标是查询信息,而 NLP 的目标是理解语言。此外,IR 检索的未必是语言,还可以是以图搜图、听曲搜曲、商品搜索乃至任何信息的搜索。现实中还存在大量不需要理解语言即可完成检索任务的场景,比如 SQL 中的 LIKE。
本书作为入门读物,不会讨论这些高级任务,但了解自然语言处理的整个宏观图景有助于我们开拓视野,找准定位与方向。
1.3 自然语言处理的流派
上一节比较了自然语言与人工语言的异同,展示了自然语言处理的困难所在,介绍了一些常见的 NLP 任务。这一节简要介绍进行自然语言处理的几种不同手法。
1.3.1 基于规则的专家系统
规则,指的是由专家手工制定的确定性流程。小到程序员日常使用的正则表达式,大到飞机的自动驾驶仪①,都是固定的规则系统。
在自然语言处理的语境下,比较成功的案例有波特词干算法(Porter stemming algorithm),它由马丁•波特在 1980 年提出,广泛用于英文词干提取。该算法由多条规则构成,每个规则都是一系列固定的 if then条件分支。当词语满足条件则执行固定的工序,输出固定的结果。摘录其中一部分规则为例,收录于表 1-1 中。

专家系统要求设计者对所处理的问题具备深入的理解,并且尽量以人力全面考虑所有可能的情况。它最大的弱点是难以拓展。当规则数量增加或者多个专家维护同一个系统时,就容易出现冲突。比如表 1-1 这个仅有 3 条规则的简单系统,规则 1 和规则 2 其实有冲突,类似 feed这样的单词会同时满足这两个规则的条件,从而引起矛盾。此时,专家系统通常依靠规则的优先级来解决。比如定义规则 1 优先于规则 2,当满足规则 1 的条件时,则忽略其他规则。几十条规则尚可接受,随着规则数量与团队人数的增加,需要考虑的兼容问题也越来越多、越来越复杂,系统维护成本也越来越高,无法拓展。
大多数语言现象比英文词干复杂得多,我们已经在上文了解了不少。这些语言现象没有必然遵循的规则,也在时刻变化,使得规则系统显得僵硬、死板与不稳定。
① 区别于汽车的无人驾驶技术,飞机的自动驾驶系统只能处理预定情况,在异常情况下会报警或切换到手动驾驶。
② 下面的例子中,feed 为特殊情况,不是过去式,不执行替换。bled 是 bleed 的过去式,不应执行“去 ed”。sing 不是现在进行时,不应执行“去 ing”。1.3.2 基于统计的学习方法
为了降低对专家的依赖,自适应灵活的语言问题,人们使用统计方法让计算机自动学习语言。所谓“统计”,指的是在语料库上进行的统计。所谓语料库,指的是人工标注的结构化文本,我们会在接下来的小节中详细阐述。
由于自然语言灵活多变,即便是语言学专家,也无法总结出完整的规则。哪怕真的存在完美的规则集,也难以随着语言的不停发展而逐步升级。由于无法用程序语言描述自然语言,所以聪明的人们决定以举例子的方式让机器自动学习这些规律。然后机器将这些规律应用到新的、未知的例子上去。在自然语言处理的语境下,“举例子”就是“制作语料库”。
统计学习方法其实是机器学习的别称,而机器学习则是当代实现人工智能的主流途径。机器学习在自然语言处理中的重要性非常之大,可以说自然语言处理只是机器学习的一种应用。此处我们仅仅用“举例学习”来简单理解,后续章节将浓墨重彩地系统学习。
1.3.3 历史
既然自然语言处理是机器学习的应用层,那么如同人工智能的历史一样,自然语言处理也经历了从逻辑规则到统计模型的发展之路。图 1-4 列出了历史上几个重要的时间段。
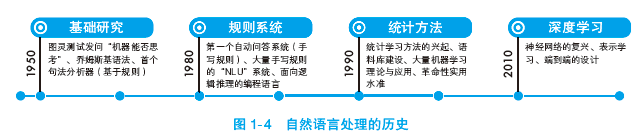
20 世纪 50 年代是人工智能与自然语言处理的萌芽期,出现了许多奠基性的工作。其中最具代表性的是数学家阿兰•图灵在论文 Computing Machinery and Intelligence 提出的人工智能的充分条件——图灵测试,以及语言学家乔姆斯基的《句法结构》——认为句子是按某种与语境无关的普遍语法规则生成的。有趣的是,先驱们的早期估计或理论都过于乐观。图灵曾预言在2014 年一台 1 GB 内存的计算机就能以 70% 的概率在 5 分钟内不被识破机器的身份,然而这个乐观的预言截至今日也没有实现。而乔姆斯基的“普遍语法”则因为对语义的忽视而备受争议,并在后续理论中做了相应修正。无论是人工智能还是自然语言处理,都是任重道远的课题。
20 世纪 80 年代之前的主流方法都是规则系统,由专家手工编写领域相关的规则集。那时候计算机和计算机语言刚刚发明,从事编程的都是精英学者。他们雄心勃勃,认为只要通过编程就能赋予计算机智能。代表性工作有 MIT AI 实验室的 BASEBALL 以及 Sun 公司(2009 年被甲骨文公司收购)的 LUNAR,分别专门回答北美棒球赛事的问题和阿波罗探月带回来的岩石样本问题。这一时期还有很多类似的问答系统,都是主要依赖手写规则的专家系统。以BASEBALL 为例,其中的词性标注模块是这样判断 score 的词性的:“如果句子中不含其他动词,则 score 是一个动词,否则是名词。”接着该系统依靠词性上的规则合并名词短语、介词短语以及副词短语。语法模块则根据“若最后一个动词是主要动词并位于 to be 之后”之类的规则判断被动句、主语和谓语。然后该系统利用词典上的规则来将这些信息转化为“属性名 = 属性值”或“属性名 = ?”的键值对,用来表示知识库中的文档以及问句。最后利用类似“若除了问号之外所有属性名都匹配,则输出该文档中问句所求的属性”的规则匹配问句与答案。如此僵硬严格的规则导致该系统只能处理固定的问句,无法处理与或非逻辑、比较级与时间段。于是,这些规则系统被称为“玩具”。为了方便表述这样的规则逻辑,1972 年人们还特意发明了 Prolog(Programming in Logic)语言来构建知识库以及专家系统。
20 世纪 80 年代之后,统计模型给人工智能和自然语言处理领域带来了革命性的进展——人们开始标注语料库用于开发和测试 NLP 模块:1988 年隐马尔可夫模型被用于词性标注,1990年 IBM 公布了第一个统计机器翻译系统,1995 年出现第一个健壮的句法分析器(基于统计)。为了追求更高的准确率,人们继续标注更大的语料库(TREC 问答语料库、CoNLL 命名实体识别、语义角色标注与依存句法语料库)。而更大的语料库与硬件的发展又吸引人们应用更复杂的模型。到了 2000 年,大量机器学习模型被广泛使用,比如感知机和条件随机场。人们不再依赖死板的规则系统,而是期望机器自动学习语言规律。要提高系统的准确率,要么换用更高级的模型,要么多标注一些语料。从此 NLP 系统可以健壮地拓展,而不再依赖专家们手写的规则。但专家们依然有用武之地,根据语言学知识为统计模型设计特征模板(将语料表示为方便计算机理解的形式)成为立竿见影的方法,这道工序被称为“特征工程”。2010 年基于 SVM 的Turbo 依存句法分析器在英语宾州树库(Penn Treebank)上取得了 92.3% 的准确率①,是当时最先进的系统。本书将着重介绍一些实用的统计模型及实现,它们并非高不可攀的技术,完全可以实现,且在普通的硬件资源下运行起来。
2010 年之后语料库规模、硬件计算力都得到了很大提升,为神经网络的复兴创造了条件。但随着标注数据的增加,传统模型的准确率提升越来越不明显,人们需要更复杂的模型,于是深层的神经网络重新回归研究者的视野。神经网络依然是统计模型的一种,其理论奠基于 20世纪 50 年代左右。 1951 年,Marvin Lee Minsky 设计了首台模拟神经网络的机器。1958 年, Rosenblatt 首次提出能够模拟人类感知能力的神经网络模型——著名的感知机。1989 年,Yann LeCun 在贝尔实验室利用美国邮政数据集训练了首个深度卷积神经网络,用于识别手写数字。只不过限于计算力和数据量,神经网络一直到 2010 年前后才被广泛应用,并被冠以“深度学习”的新术语,以区别于之前的浅层模型。深度学习的魅力在于,它不再依赖专家制定特征模板,而能够自动学习原始数据的抽象表示,所以它主要用于表示学习。作为入门书,我们仅仅在最后一章介绍一些概念与应用,作为衔接传统方法与深度学习的桥梁。
① 准确来讲,是斯坦福标准下忽略标点符号的 Unlabeled Attachment Score,将会在第12 章中详细介绍。1.3.4 规则与统计
纯粹的规则系统已经日渐式微,除了一些简单的任务外,专家系统已经落伍了。20 世纪 70年代,美国工程院院士贾里尼克在 IBM 实验室开发语音识别系统时,曾经评论道:“我每开除一名语言学家,我的语音识别系统的准确率就提高一点。”① 这句广为流传的快人快语未免有些刻薄,但公正地讲,随着机器学习的日渐成熟,领域专家的作用越来越小了。
实际工程中,语言学知识的作用有两方面:一是帮助我们设计更简洁、高效的特征模板,二是在语料库建设中发挥作用。事实上,实际运行的系统在预处理和后处理的部分依然会用到一些手写规则。当然,也存在一些特殊案例更方便用规则特殊处理。
本书尊重工程实践,以统计为主、规则为辅的方式介绍实用型 NLP 系统的搭建。
1.3.5 传统方法与深度学习
虽然深度学习在计算机视觉领域取得了耀眼的成绩,但在自然语言处理领域中的基础任务上发力并不大。这个结论或许有点意外,作为数据科学从业者,用数据说明问题最合适。表 1-2收录了《华尔街日报》语料库上的词性标注任务的前沿准确率。

① 原话是“Every time I fire a linguist, the performance of the speech recognizer goes up”。
② “作者姓 ( 年份 )”是一种常见的论文引用格式,可通过该信息(必要时加入主题关键词)搜索到论文。截止 2015 年,除了 Bi-LSTM-CRF 以外,其他系统都是传统模型,最高准确率为 97.36%,而 Bi-LSTM-CRF 深度学习模型为 97.55%,仅仅提高了 0.19%。2016 年,传统系统 NLP4J 通过使用额外数据与动态特征提取算法,准确率可以达到 97.64%。
类似的情形也在句法分析任务上重演,以斯坦福标准下宾州树库的准确率为例,如表 1-3所示。
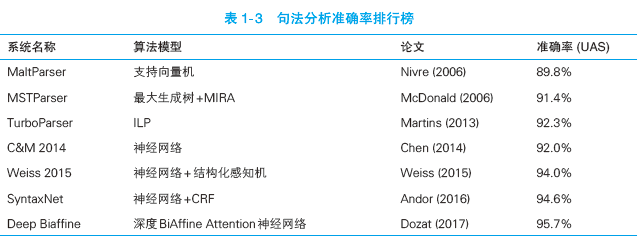
2014 年首个神经网络驱动的句法分析器还不如传统系统 TurboParser 准确,经过几年的发展准确率终于达到 95.7%,比传统算法提高 3.4%。这个成绩在学术界是非常显著的,但在实际使用中并不明显。
另一方面,深度学习涉及大量矩阵运算,需要特殊计算硬件(GPU、TPU 等)的加速。目前,一台入门级塔式服务器的价格在 3000 元左右,一台虚拟服务器每月仅需 50 元左右,但仅一块入门级计算显卡就需要 5000 元。从性价比来看,反而是传统的机器学习方法更适合中小企业。
此外,从传统方法到深度学习的迁移不可能一蹴而就。两者是基础和进阶的关系,许多基础知识和基本概念用传统方法讲解会更简单、易懂,它们也会在深度学习中反复用到(比如 CRF与神经网络的结合)。无论是传统模型还是神经网络,它们都属于机器学习的范畴。掌握传统方法,不仅可以解决计算资源受限时的工程问题,还可以为将来挑战深度学习打下坚实的基础。
1.4 机器学习
在前面的小节中,我们邂逅了一些机器学习的术语。按照递归学习的思路,现在我们来递归了解一下机器学习的基本概念。
本书虽然主要面向自然语言处理,不会专门设立章节详谈机器学习,但仍然会在合适的时候介绍引擎盖下的机器学习算法。机器学习是自然语言处理的基石,一些基本概念依然需要预先掌握。熟练掌握这些术语,还方便我们与其他人流畅交流。
1.4.1 什么是机器学习
人工智能领域的先驱 Arthur Samuel 在 1959 年给出的机器学习定义是:不直接编程却能赋予计算机提高能力的方法。
聪明的读者或许都曾经思考过,计算机是否只能执行人类设计好的步骤?机器学习给了这个问题积极的答复,机器可以通过学习提高自身能力,而不需要程序员硬编码该项能力。美国工程院院士 Tom Mitchell 给过一个更明确的定义,机器学习指的是计算机通过某项任务的经验数据提高了在该项任务上的能力。
简而言之,机器学习是让机器学会算法的算法。这个说法有些绕口,不如拿我们熟悉的数据库做类比:数据库中的“元数据”指的是描述数据的数据(表名、字段等),而其中的一行则是普通数据。类比过来,机器学习算法则可以称作“元算法”,它指导机器自动学习出另一个算法,这个算法被用来解决实际问题。为了避免混淆,人们通常称被学习的算法为模型。
1.4.2 模型
模型是对现实问题的数学抽象,由一个假设函数以及一系列参数构成。举个简单的例子,我们要预测中国人名对应的性别。假设中国人名由函数 f x()输出的符号决定,负数表示女性,非负数表示男性。
我们选取的 f x()的定义如下:
![]()
其中, w 和 b 是函数的参数,而 x 是函数的自变量。那么,模型指的就是包括参数在内的整个函数。不过模型并不包括具体的自变量 x ,因为自变量是由用户输入的。自变量 x 是一个特征向量,用来表示一个对象的特征。
读者可以将式 (1.1) 理解为初中的直线方程,也可以理解为高中的平面方程,或者高维空间中的超平面方程。总之,不必担心问题的抽象性,我们将在第 5 章中用代码完整地实现这个案例。
1.4.3 特征
特征指的是事物的特点转化的数值,比如牛的特征是 4 条腿、0 双翅膀,而鸟的特征是 2条腿、1 双翅膀。那么在性别识别问题中,中国人名的特征是什么呢?
首先,对于一个中国人名,姓氏与性别无关,真正起作用的是名字。而计算机不知道哪部分是姓,哪部分是名。姓氏属于无用的特征,不应被提取。另外,有一些特殊的字(壮、雁、健、强)是男性常用的,而另一些(丽、燕、冰、雪)则是女性常用的,还有一些(文、海、宝、玉)则是男女通用的。让我们把人名表示为计算机可以理解的形式,一个名字是否含有这些字就成了最容易想到的特征。在专家系统中,我们显式编程:

如果有人叫“沈雁冰”① 怎么办?“雁”听上去像男性,而“冰”听上去像女性,而这个名字其实是男性用的。看来,每个字与男女的相关程度是不一样的,“雁”与男性的相关程度似乎大于“冰”与女性的相关程度。这个冲突似乎可以通过“优先级”解决,不过这种机械的工作交给机器好了。在机器学习中,“优先级”可以看作特征权重或模型参数。我们只需要定义一系列特征,让算法根据数据自动决定它们的权重就行了。为了方便计算机处理,我们将它们表示为数值类型的特征,这个过程称为特征提取。以“沈雁冰”的特征提取为例,如表 1-4 所示。

特征的数量是因问题而定的,2 个特征显然不足以推断名字的性别,我们可以增加到 4 个,如表 1-5 所示。
① 作家茅盾原名沈德鸿,字雁冰,以字行于世,因此“沈雁冰”同样为人熟知。
有时候,我们还可以将位置信息也加入特征中,比如“是否以雪字结尾”。我们还可以组合两个特征得到新的特征,比如“是否以雪字结尾并且倒数第二个字是吹”,这样就可以让“西门吹雪”这个特殊名字得到特殊处理,而不至于同“小雪”“陆雪琪”混为一谈。
工程上,我们并不需要逐个字地写特征,而是定义一套模板来提取特征。比如姓名为 name的话,则定义特征模板为 name[1] + name[2]之类,只要我们遍历一些姓名,则 name[1] + name[2]可能组合而成的特征就基本覆盖了。这种自动提取特征的模板称作特征模板。
如何挑选特征,如何设计特征模板,这称作特征工程。特征越多,参数就越多;参数越多,模型就越复杂。模型的复杂程度应当与数据集匹配,按照递归学习的思路,数据集的概念将在下一节中介绍。
1.4.4 数据集
如何让机器自动学习,以得到模型的参数呢?首先得有一本习题集。有许多问题无法直接编写算法(规则)解决(比如人名性别识别,我们说不清楚什么样的名字是男性),所以我们准备了大量例子(人名 x 及其对应的性别 y)作为习题集,希望机器自动从习题集中学习中国人名的规律。其中,“例子”一般称作样本。
这本习题集在机器学习领域称作数据集,在自然语言处理领域称作语料库,会在 1.5 节详细介绍。数据集的种类非常多,根据任务的不同而不同。表 1-6 收录了一些常用的数据集。

在使用数据集时,我们不光要考虑它的规模、标注质量,还必须考虑它的授权。大部分数据集都不可商用,许多冷门领域的数据集也比较匮乏,此时我们可以考虑自行标注。
1.4.5 监督学习
如果这本习题集附带标准答案 y ,则此时的学习算法称作监督学习。监督学习算法让机器先做一遍题,然后与标准答案作比较,最后根据误差纠正模型的错误。大多数情况下,学习一遍误差还不够小,需要反复学习、反复调整。此时的算法是一种迭代式的算法,每一遍学习都称作一次迭代。监督学习在日语中被称作“教師あり学習”,意思是“有老师的学习”。通过提供标准答案,人类指出了模型的错误,充当了老师的角色。

这种在有标签的数据集上迭代学习的过程称为训练,训练用到的数据集称作训练集。训练的结果是一系列参数(特征权重)或模型。利用模型,我们可以为任意一个姓名计算一个值,如果非负则给出男性的结论,否则给出女性的结论。这个过程称为预测。
总结一下,监督学习的流程如图 1-5 所示。
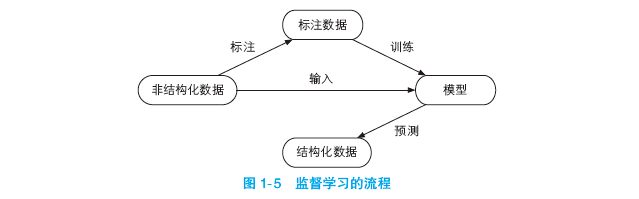
在性别识别的例子中:
● 非结构化数据是许多个类似“沈雁冰”“丁玲”的人名;
● 经过人工标注后得到含有许多个类似“沈雁冰=男”“丁玲=女”样本的标注数据集;
● 然后通过训练算法得到一个模型;
● 最后利用这个模型,我们可以预测任何名字(如“陆雪琪”)的性别。
待预测的名字不一定出现在数据集中,但只要样本数量充足且男女均衡、特征模板设计得当、算法实现正确,我们依然可以预期一个较高的准确率。
另外,图 1-5 中的标注数据其实也是结构化数据。但由于它含有人工标注的成本,有时被称作“黄金数据”(gold data),与模型预测的、有一定误差的结果还是有很大区别的。
本书将从第 3 章开始详细介绍一些 NLP 中实用的监督学习方法。
1.4.6 无监督学习
如果我们只给机器做题,却不告诉它参考答案,机器仍然可以学到知识吗?
可以,此时的学习称作无监督学习,而不含标准答案的习题集被称作无标注(unlabeled)的数据集。无监督学习在日语中被称作“教師なし学習”,意为“没有老师的学习”。没有老师的指导,机器只能说发现样本之间的联系,而无法学习样本与答案之间的关联。
无监督学习一般用于聚类和降维,两者都不需要标注数据。
聚类已经在 1.2 节中介绍过了,我们不再赘述。在性别识别的例子中,如果我们选择将一系列人名聚成 2 个簇的话,“周树人”“周立人”很可能在一个簇里面,“陆雪琪”和“曹雪芹” 在另一个簇里面。这是由样本之间的相似性和簇的颗粒度决定的,但我们并不知道哪个簇代表男性哪个簇代表女性,它们也未必能通过肉眼区分。
降维指的是将样本点从高维空间变换到低维空间的过程。机器学习中的高维数据比比皆是,比如在性别识别的例子中,以常用汉字为特征的话,特征数量轻易就突破了 2000。如果样本具有 n 个特征,则样本对应着 n +1 维空间中的一个点,多出来的维度是给假设函数的因变量用的。如果我们想要让这些样本点可视化,则必须将其降维到二维或三维空间。有一些降维算法的中心思想是,降维后尽量不损失信息,或者说让样本在低维空间中每个维度上的方差都尽量大。试想一下这样的极端案例:平地上竖直地插着一些等长的钢管,将这些钢管的顶端降维到二维平面上,就是拔掉钢管后留下来的孔洞。垂直维度上钢管长度都是一样的,没有有用信息,于是被舍弃掉了。
有一些无监督方法也可以用来驱动中文分词、词性标注、句法分析等任务。由于互联网上存储了丰富的非结构化数据,所以无监督学习十分诱人。然而无监督学习时,模型与用户之间没有发生任何信息交换,这种缺乏监督信号的学习导致模型无法捕捉用户的标准,最终预测的结果往往与用户心目中的理想答案相去甚远。目前,无监督学习的 NLP 任务的准确率总比监督学习低十几个到几十个百分点,无法达到生产要求。
本书将在第 10 章详细介绍聚类算法的原理和实现。
1.4.7 其他类型的机器学习算法
如果我们训练多个模型,然后对同一个实例执行预测,会得到多个结果。如果这些结果多数一致,则可以将该实例和结果放到一起作为新的训练样本,用来扩充训练集。这样的算法①被称为半监督学习。由于半监督学习可以综合利用标注数据和丰富的未标注数据,所以正在成为热门的研究课题。
现实世界中的事物之间往往有很长的因果链:我们要正确地执行一系列彼此关联的决策,才能得到最终的成果。这类问题往往需要一边预测,一边根据环境的反馈规划下次决策。这类算法被称为强化学习。强化学习在一些涉及人机交互的问题上成果斐然,比如自动驾驶、电子竞技和问答系统。
本书作为入门读物,不会深入这些前沿课题。但了解这些分支的存在,有助于构建完整的知识体系。
① 称作启发式半监督学习,是所有半监督学习方法中最容易理解的一种。1.5 语料库
语料库作为自然语言处理领域中的数据集,是我们教机器理解语言不可或缺的习题集。在这一节中,我们来了解一下中文处理中的常见语料库,以及语料库建设的话题。
1.5.1 中文分词语料库
中文分词语料库指的是,由人工正确切分后的句子集合。
以著名的 1998 年《人民日报》语料库为例,该语料库由北京大学计算语言学研究所联合富士通研究开发中心有限公司,在人民日报社新闻信息中心的许可下,从 1999 年 4 月起到 2002年 4 月底,共同标注完成。语料规模达到 2600 万汉字,市售为 1998 年上半年的语料部分(约1300 万字=约 730 万词)。
在 2005 年的第二届国际中文分词比赛中,曾经公开过约 1 个月份的语料。其中的一句样例为:
先有通货膨胀干扰,后有通货紧缩叫板。
从这句简单的标注语料中,无须语言学知识,我们也能发现一个问题:为何“通货膨胀”是一个词,而“通货 紧缩”却分为两个词呢?这涉及语料标注规范和标注员内部一致性的问题。我们将在后续章节中详细介绍这些话题,现在只需留个印象:语料规范很难制定,规范很难执行。
事实上,中文分词语料库虽然总量不多,但派别却不少。我们将在第 3 章中了解这些语料的授权、下载与使用。
1.5.2 词性标注语料库
它指的是切分并为每个词语指定一个词性的语料。总之,我们要教机器干什么,我们就得给机器示范什么。依然以《人民日报》语料库为例,1998 年的《人民日报》一共含有 43 种词性,这个集合称作词性标注集。这份语料库中的一句样例为:
迈向/v 充满/v 希望/n 的/u 新/a 世纪/n ——/w 一九九八年/t 新年/t 讲话/n (/w 附/v 图片/n 1/m 张/q )/w这里每个单词后面用斜杠隔开的就是词性标签,关于每种词性的意思将会在第 7 章详细介绍。这句话中值得注意的是,“希望”的词性是“名词”(n)。在另一些句子中,“希望”还可以作为动词。
1.5.3 命名实体识别语料库
这种语料库人工标注了文本内部制作者关心的实体名词以及实体类别。比如《人民日报》语料库中一共含有人名、地名和机构名 3 种命名实体:
萨哈夫/nr 说/v ,/w 伊拉克/ns 将/d 同/p [联合国/nt 销毁/v 伊拉克/ns 大规模/b 杀伤性/n 武器/n 特别/a 委员会/n] /nt 继续/v 保持/v 合作/v 。/w这个句子中的加粗词语分别是人名、地名和机构名。中括号括起来的是复合词,我们可以观察到:有时候机构名和地名复合起来会构成更长的机构名,这种构词法上的嵌套现象增加了命名实体识别的难度。
命名实体类型有什么取决于语料库制作者关心什么。在本书第 8 章中,我们将演示如何标注一份语料库用来实现对战斗机名称的识别。
1.5.4 句法分析语料库
汉语中常用的句法分析语料库有 CTB(Chinese Treebank,中文树库),这份语料库的建设工作始于 1998 年,历经宾夕法尼亚大学、科罗拉多大学和布兰迪斯大学的贡献,一直在发布多个改进版本。以 CTB 8.0 版为例,一共含有来自新闻、广播和互联网的 3007 篇文章,共计 71 369个句子、1 620 561 个单词和 2 589 848 个字符。每个句子都经过了分词、词性标注和句法标注。其中一个句子可视化后如图 1-6 所示。
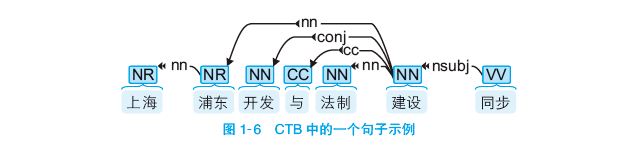
图 1-6 中,中文单词上面的英文标签表示词性,而箭头表示有语法联系的两个单词,具体是何种联系由箭头上的标签表示。关于句法分析语料库的可视化和利用,将会在第 12 章中介绍。
1.5.5 文本分类语料库
它指的是人工标注了所属分类的文章构成的语料库。相较于上面介绍的 4 种语料库,文本分类语料库的数据量明显要大很多。以著名的搜狗文本分类语料库为例,一共包含汽车、财经、 IT、健康、体育、旅游、教育、招聘、文化、军事 10 个类别,每个类别下含有 8000 篇新闻,每篇新闻大约数百字。
另外,一些新闻网站上的栏目经过了编辑的手工整理,相互之间的区分度较高,也可作为文本分类语料库使用。情感分类语料库则是文本分类语料库的一个子集,无非是类别限定为 “正面”“负面”等而已。
如果这些语料库中的类目、规模不满足实际需求,我们还可以按需自行标注。标注的过程实际上就是把许多文档整理后放到不同的文件夹中。
1.5.6 语料库建设
语料库建设指的是构建一份语料库的过程,分为规范制定、人员培训与人工标注这 3 个阶段。
规范制定指的是由语言学专家分析并制定一套标注规范,这份规范包括标注集定义、样例和实施方法。在中文分词和词性标注领域,比较著名的规范有北京大学计算语言学研究所发布的《现代汉语语料库加工规范——词语切分与词性标注》和中国国家标准化管理委员会发布的《信息处理用现代汉语词类标记规范》。
人员培训指的是对标注员的培训。由于人力资源的限制,制定规范与执行规范的未必是同一批人。大型语料库往往需要多人协同标注,这些标注员对规范的理解必须达到一致,否则会导致标注员内部冲突,影响语料库的质量。
针对不同类型的任务,人们开发出许多标注软件,其中比较成熟的一款是 brat(brat rapid annotation tool) ①,它支持词性标注、命名实体识别和句法分析等任务。brat 是典型的 B/S 架构,服务端用 Python 编写,客户端运行于浏览器。相较于其他标注软件,brat 最大的亮点是多人协同标注功能。此外,拖曳式的操作体验也为 brat 增色不少。
① 详见 http://brat.nlplab.org/。1.6 开源工具
目前开源界贡献了许多优秀的 NLP 工具,它们为我们提供了多种选择,比如教学常用的NLTK(Natural Language Toolkit)、斯坦福大学开发的 CoreNLP,以及国内哈工大开发的 LTP (Language Technology Platform)、我开发的 HanLP(Han Language Processing)。
1.6.1 主流 NLP 工具比较
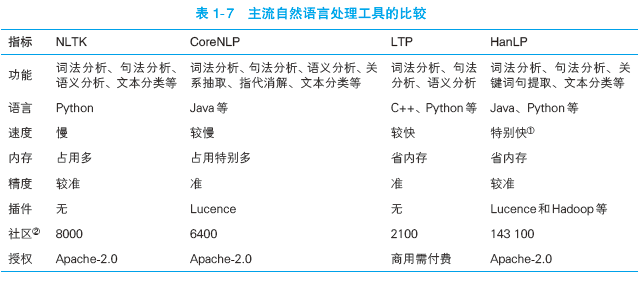
选择一个工具包,我们需要考虑的问题有:功能、精度、运行效率、内存效率、可拓展性、商业授权和社区活跃程度。表 1-7 比较了 4 款主流的开源 NLP 工具包。
关于这些开源工具的发展速度,根据 GitHub 上 Star 数量的趋势,HanLP 是发展最迅猛的,如图 1-7 所示。
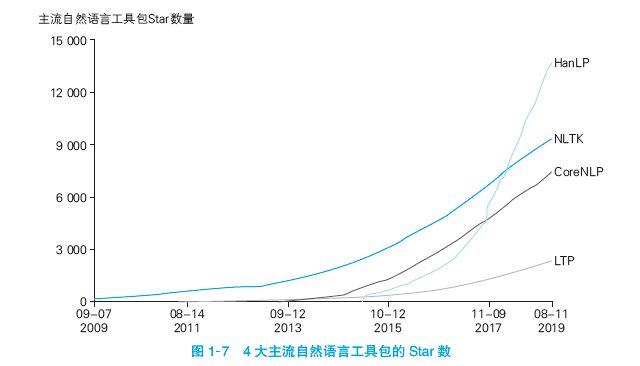
① 关于 HanLP 与 LTP 的具体性能对比,请参考 @zongwu233 的第三方开源评测:https://github.com/zongwu233/ HanLPvsLTP。关于 HanLP 与包括结巴、IK、Stanford、Ansj、word 在内的其他 Java 开源分词器的性能对比,可参考阿里巴巴架构师杨尚川的第三方开源评测:https://github.com/ysc/cws_evaluation。我不保证第三方开源评测的准确与公正,更不采信任何闭源评测。本书将在相关章节中详细介绍如何规范地评估常见 NLP 任务的精度。
② 截至 2019 年 8 月份在 GitHub 上的 Star 数量。
另外,我也研究过其他开源项目的原理,借鉴了其中优秀的设计。但毕竟还是自己写的代码讲得最清楚,所以综合以上各种考虑,最后选取了 HanLP 作为本书的实现。
1.6.2 Python 接口
得益于 Python 简洁的设计,使用这门动态语言调用 HanLP 会省下不少时间。无论用户是否常用 Python,都推荐一试。
HanLP 的 Python 接口由 pyhanlp 包提供,其安装只需一句命令:
$ pip install pyhanlp这个包依赖 Java 和 JPype。Windows 用户如果遇到如下错误:
building '_jpype' extension
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual
C++ Build Tools": http://visualstudio.microsoft.com/visual-cpp-build-tools/既可以按提示安装 Visual C++,也可以安装更轻量级的 Miniconda。Miniconda 是 Python 语言的开源发行版,提供更方便的包管理。安装时请勾选如图 1-8 所示的两个复选框。
然后执行如下命令:
$ conda install -c conda-forge jpype1
$ pip install pyhanlp如果遇到 Java 相关的问题:
jpype._jvmfinder.JVMNotFoundException: No JVM shared library file (jvm.dll) found. Try setting up the JAVA_HOME environment variable properly.请安装 Java 运行环境①。HanLP 主项目采用 Java 开发,所以需要 JDK 或 JRE。如果发生其他错误,欢迎前往项目讨论区② 汇报问题。
一切顺利的话,在命令行中键入如下命令,可以验证安装结果:

如果 Linux 用户遇到权限问题,则需要执行 sudo hanlp。因为在第一次运行时,pyhanlp 会自动下载 HanLP 的 jar 包(包含许多算法)和数据包(包含许多模型)到 pyhanlp 的系统路径。
通过命令行,我们可以在不写代码的前提下轻松调用 HanLP 提供的常见功能。
① 官网(http://www.oracle.com/technetwork/java/javase/downloads/index.html)推荐选择 JDK 8 以上版本。
② 详见 https://github.com/hankcs/HanLP/issues,我大约每周末回复一次。
使用命令 hanlp segment进入交互分词模式;输入一个句子并回车,HanLP 会输出分词结果:
$ hanlp segment
商品和服务
商品/n 和/cc 服务/vn
当下雨天地面积水分外严重
当/p 下雨天/n 地面/n 积水/n 分外/d 严重/a王总和小丽结婚了
王总/nr 和/cc 小丽/nr 结婚/vi 了/ule在 Linux 下还可以重定向字符串作为输入:
$ hanlp segment <<< '欢迎新老师生前来就餐'
欢迎/v 新/a 老/a 师生/n 前来/vi 就餐/vi注意 Windows 不支持字符串的 <<< 定向,只能手动输入。
这里默认执行了词性标注,我们可以禁用它:
$ hanlp segment --no-tag <<< ' 欢迎新老师生前来就餐'
欢迎 新 老 师生 前来 就餐任何平台都支持重定向文件输入 / 输出,比如我们将一本小说存储为 input.txt :
$ head input.txt
第一章 隐忧
张小凡看着前方那个中年文士,也就是当今正道的心腹大患“鬼王”,脑海中一片混乱。
这些日子以来,他在深心处不时对自己往日的信仰有小小的疑惑,其实都根源于当日空桑山下茶摊里的一番对话。如今,又见故人,这份心情当真复杂,几乎让他一时间忘了此时此地的处境。
不过就算他忘了,旁边的人可不会忘。
小周伸手擦去了嘴边的鲜血,勉强站了起来,低声对张小凡、田灵儿二人道:“此人道行太高,不可力敌,我来拖住他,你们二人快走!”
说罢,他伸手一招,倒插在岩壁中到现在兀自在轻微振动的“七星剑”,似受他召唤,“铮”的一声破壁而出,飞回到他手上。
鬼王看了看小周,点了点头,脸上依然带着一丝微笑,道:“以你的道行,看来青云门门下年轻弟子一辈里,要以你为首。
想不到青云门除了这个张小凡,居然还有你这样的人才,不错,不错!”
张小凡吓了一跳,却发觉师姐田灵儿与那小周的眼光都瞄了过来,一时脸上有些发热,却不知道该说什么才好。通过重定向,只需一条命令就可以给小说分词:
$ hanlp segment < input.txt > output.txt -a crf --no-tag此处通过 -a参数指定分词算法为 CRF。关于该算法,我们会在第 6 章中详细介绍。现在,我们先来感性观察一下 CRF 分词的效果:
$ head output.txt
第一 章 隐忧
张小凡 看着 前方 那个 中年 文士 , 也 就是 当今 正道 的 心腹大患 “ 鬼王 ” , 脑海中 一片 混乱。这些 日子 以来 , 他 在 深心 处 不时 对 自己 往日 的 信仰 有 小小 的 疑惑 , 其实 都 根源 于 当日 空桑山 下 茶摊 里 的 一番 对话 。
如今 , 又 见 故人 , 这 份 心情 当真 复杂 , 几乎 让 他 一 时间 忘 了 此时此地 的 处境 。不过 就算 他 忘 了 , 旁边 的 人 可 不会 忘 。
小周 伸手 擦去 了 嘴边 的 鲜血 , 勉强 站 了 起来 , 低声 对 张小凡 、 田灵儿 二 人 道 :
“ 此人 道行 太 高 , 不可力敌 , 我 来 拖住 他 , 你们 二 人 快走 !”
说罢 , 他 伸手 一 招 , 倒 插 在 岩壁 中 到 现在 兀自 在 轻微 振动 的 “ 七星剑 ” , 似 受 他 召唤 , “ 铮 ” 的 一 声 破壁 而 出 , 飞 回到 他 手上 。
鬼王 看 了 看 小周 , 点 了 点头 , 脸上 依然 带 着 一 丝 微笑 , 道 : “ 以 你 的 道行 , 看来 青云门 门下 年轻 弟子 一 辈 里 , 要以 你 为首 。
想不到 青云门 除了 这个 张小凡 , 居然 还有 你 这样 的 人才 , 不错 , 不错 ! ”
张小凡 吓了一跳 , 却 发觉 师姐 田灵儿 与 那 小周 的 眼光 都 瞄 了 过来 , 一时 脸上 有些 发热 , 却 不 知道 该 说 什么 才 好 。效果似乎还行,“鬼王”“空桑山”“七星剑”“青云门”等词语都正确切分出来了。但仍然有不尽如人意的地方。比如“此时此地”“吓了一跳”为什么被当作一个词?这些分词标准是由分词器作者定的吗?这些问题我们将会在后续章节中逐个讨论。
句法分析功能也是一样的道理,一句命令即可:

这些命令还支持许多其他参数,这可以通过 --help参数来查看最新的帮助手册:

在初步体验 HanLP 后,来看看如何在 Python 中调用 HanLP 的常用接口。这里给出一个大而不全的例子:

HanLP 的常用功能可以通过工具类 HanLP来调用,而不需要创建实例。对于其他更全面的功能介绍,可参考 GitHub 上的 demos 目录:https://github.com/hankcs/pyhanlp/tree/master/tests/demos。
1.6.3 Java 接口
Java 用户可以通过 Maven 方便地引入 HanLP 库,只需在项目的 pom.xml 中添加如下依赖项即可:

此外,可以访问发布页https://github.com/hankcs/HanLP/releases 获取其最新的版本号。
然后就可以用一句话调用HanLP 了:
System.out.println(HanLP.segment("你好,欢迎使用HanLP汉语处理包!"));常用的 API 依然封装在工具类 HanLP中,你可通过 https://github.com/hankcs/HanLP 了解接口的用法。当然,你也可以随着本书的讲解,逐步熟悉这些功能。
HanLP 的数据与程序是分离的。为了减小 jar 包的体积,portable 版只含有少量数据。对于一些高级功能(CRF 分词、句法分析等),则需要下载额外的数据包,并通过配置文件将数据包的位置告诉给 HanLP。
如果读者安装过 pyhanlp 的话,则数据包和配置文件已经安装就绪。我们可以通过如下命令获取它们的路径:

最后一行 hanlp.properties 就是所需的配置文件,我们只需将它复制到项目的资源目录src/main/resources 即可(没有该目录的话,手动创建一个)。此时 HanLP 就会从 /usr/local/lib/python3.6/site-packages/pyhanlp/static 加载 data,也就是说与 pyhanlp 共用同一套数据包。
如果读者没有安装过 pyhanlp,或者希望使用独立的 data,也并不困难。只需访问项目主页https://github.com/hankcs/HanLP,下载 data.zip 并将其解压到一个目录,比如 D:/hanlp。然后下载并解压 hanlp-1.7.5-release.zip,将得到的 hanlp.properties 中的第一行 root 设为 data 文件夹的父目录:
root=D:/hanlp注意 Windows 用户请注意,路径分隔符统一使用斜杠“/”。Windows 默认的“\”与绝大多数编程语言的转义符冲突,比如“D:\nlp”中的“\n”实际上会被Java 和Python 理解为换行符,引发问题。
最后,将 hanlp.properties 移动到项目的 resources 目录中即可。
由于本书将深入讲解 HanLP 的内部实现,所以还推荐读者去 GitHub 上创建分支(fork)并克隆(clone)一份源码。版本库中的文件结构如下:

限于文件体积,版本库中依然不含完整的 model 文件夹,需要用户下载数据包和配置文件。下载方式有自动与手动两种,本书 Java 配套代码在运行时会自动下载并解压,另外用户也可以自行下载解压。按照前面提到的方法,创建 resources 目录并将 hanlp.properties 放入其中。然后将下载到的 data/model 放入版本库的相应目录即可。完成后的路径示意图如下:

接下来,我们就可以运行本书配套的代码了(配套代码位于 src/test/java/com/hankcs/book)。现在我们来运行一个 Hello Word(详见 ch01/HelloWord.java):
HanLP.Config.enableDebug(); // 为了避免你等得无聊,开启调试模式说点什么
System.out.println(HanLP.segment("王国维和服务员"));运行一下,会得到类似如下的输出:

相较于上一个例子,它们有以下两个区别。
● 我们打开了调试模式,此时会将运行过程的中间结果输出到控制台。
● 我们运行的是GitHub仓库版,该版本中的词典和模型都是文本形式。HanLP中的词典一般有文本和二进制两种形式,它们的关系类似于源码和程序。当二进制不存在时,HanLP会加载文本词典并自动缓存为同名的二进制。二进制的加载比文本要快很多,通常是5 倍的加速比。比如在上面的例子中,加载文本花了341 ms,但再次运行时加载相应的二进制只花了64 ms。通过缓存机制和内部重写的IO 接口,HanLP 可以将系统的冷启动控制在几百毫秒内。这为程序员反复调试提供了极大的便利。
再来看看调试输出,里面分为两个过程:粗分过程和细分过程。粗分过程的结果是 [王国 /n, 维和 /vn, 服务员 /nnt],这显然是不合理① 的,这个句子不应该这样理解。于是在细分过程中,算法进行了人名识别,召回了“王国维”这个词语。接着算法觉得 [王国维 /nr, 和 /cc, 服务员 /nnt]通顺多了,于是将其作为最终结果。
算法内部还有许多细节,但我们已经有了趁手的武器。具体武器的基本骨架、锻造过程和使用场景,将以递归的形式逐步讲解。
1.7 总结
本章给出了人工智能、机器学习与自然语言处理的宏观缩略图与发展时间线。机器学习是人工智能的子集,而自然语言处理则是人工智能与语言学、计算机科学的交集。这个交集虽然小,它的难度却很大。为了实现理解自然语言这个宏伟目标,人们尝试了规则系统,并最终发展到基于大规模语料库的统计学习系统。
在接下来的章节中,就让我们按照这种由易到难的发展规律去解决第一个 NLP 问题——中文分词。我们将先从规则系统入手,介绍一些快而不准的算法,然后逐步进化到更加准确的统计模型。
① 称其“不合理”而非“不正确”的原因是,我们无法排除在某个奇幻世界里存在一个特立独行的王国,里面养着一只维和部队,部队的成员却不是战士而是服务员。但这种可能性非常低,几乎不可能发生。
本文摘自《自然语言处理入门》
