Faiss源码解析 - Index抽象类介绍(一)
本系列文章基于Faiss 1.5.3版本的代码进行分析。
相似性搜索介绍
Faiss是Facebook AI团队开源的针对聚类和相似性搜索库,为稠密向量提供高效相似度搜索和聚类,是目前比较成熟的近似近邻搜索库。以图片搜索为例,所谓相似度搜索,就是在给定的图片中,寻找出指定的图片最像的K张图片,本质上为KNN(K近邻)问题。
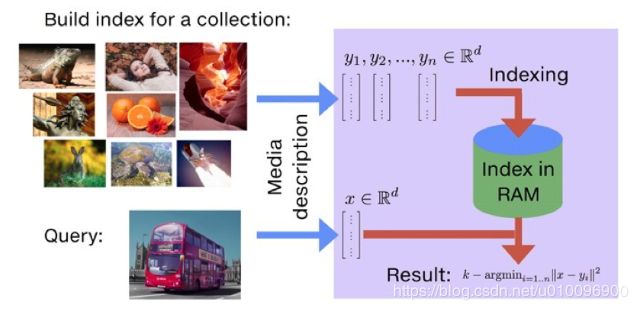
为了解决KNN问题,在工程上需要对现有图片库的特征向量进行存储。当用户指定检索图片后,需要知道如何从存储的图片库中找到最为相似的K张图片。Faiss为解决这种问题,除具备添加和搜索的功能外,还需要提供相应的修改和删除功能。从本质上将,Faiss属于向量(矢量)数据库。
Faiss的github首页上对相似性搜索做了一个简要的介绍,What is similarity search?。在这里把这部分内容摘抄过来,以对Faiss提供的功能有基本的了解:
Given a set of vectors x_i in dimension d, Faiss build a data structure from it. After the structure is constructed, when given a new vector x in dimension d it performs efficiently the operation:
i = argmin_i ||x - x_i||
where ||.|| is the Euclidean distance (L2).
If Faiss terms, the data structure is an index, an object that has an add method to add x_i vectors. Note that the x_i's are assumed to be fixed.
Computing the argmin is the search operation on the index.
This is all what Faiss is about. It can also:
1. return not just the nearest neighbor, but also the 2nd nearest, 3rd, ..., k-th nearest neighbor
2. search several vectors at a time rather than one (batch processing). For many index types, this is faster than searching one vector after another
3. trade precision for speed, ie. give an incorrect result 10% of the time with a method that's 10x faster or uses 10x less memory
4. perform maximum inner product search argmax_i instead of minimum Euclidean search.
5. return all elements that are within a given radius of the query point (range search)
相似性计算方式
既然Faiss是一种相似性搜索库,那就来看一下Faiss提供了哪些方式来衡量相似度度。在Faiss 1.5.0版本之前,仅支持常用的内积(归一化后与余弦等同)和欧式距离两种,新版本中支持了更多的计算方式,可供用户选择。
/// Some algorithms support both an inner product version and a L2 search version.
enum MetricType {
METRIC_INNER_PRODUCT = 0, ///< maximum inner product search
METRIC_L2 = 1, ///< squared L2 search
METRIC_L1, ///< L1 (aka cityblock)
METRIC_Linf, ///< infinity distance
METRIC_Lp, ///< L_p distance, p is given by metric_arg
/// some additional metrics defined in scipy.spatial.distance
METRIC_Canberra = 20,
METRIC_BrayCurtis,
METRIC_JensenShannon,
};
Index抽象类
对于传统数据库,时空的优化是永恒的主题,即在存储上如何以更少的空间来存储更多的信息,在搜索上如何以更快的速度来搜索出更准确的信息,如何减少搜索所需的时间?在数据库中比较常见的便是各种索引,把各种加速搜索算法功能或空间换时间的策略封装成各种索引,来满足各种不同的引用场景。Faiss作为向量(矢量)数据库,也需要考虑时空优化问题。本系列文章会对每种类型的向量搜索算法进行详尽的分析,本文先来分析Faiss基类的设计。
Faiss实现中有两个基础索引抽象类Index和IndexBinary,本文仅对Index基类进行介绍。Faiss作为向量数据库,需要提供向量的增删改查功能,那先来看一下向量参数如何传递的。
向量参数传递
在整个Faiss的实现中,向量参数的传递按照下面的方式进行:
* Throughout the library, vectors are provided as float * pointers.
* Most algorithms can be optimized when several vectors are processed
* (added/searched) together in a batch. In this case, they are passed
* in as a matrix. When n vectors of size d are provided as float * x,
* component j of vector i is
*
* x[ i * d + j ]
*
* where 0 <= i < n and 0 <= j < d. In other words, matrices are
* always compact. When specifying the size of the matrix, we call it
* an n*d matrix, which implies a row-major storage.
向量以float类型的指针来传递,大部分的算法实现都对批量添加或查询功能进行了优化。比如x为传递的向量指针,其指向的是一个d维,含有n个向量的矩阵,则第i个向量的第j维的值为x[ i * d + j ],是一个行优先矩阵存储方式。
Index抽象类定义
在Faiss的术语中,相关的数据结构就是一个索引Index。Faiss(包括C++和Python)提供了索引Index的实例。每个Index子类实现一个索引结构,以说明哪些向量可被加入和搜索。Index基类的相关的定义在Index.h/Index.cpp两个文件。
聚类模型训练接口
train()为模型训练函数,像暴力检索的IndexFlat系列子类并不需要训练聚类模型,因此该函数定义为虚函数,并提供了缺省的实现。该函数有2个输入参数,n代表向量的条数,x为浮点数指针,指向训练向量数组,长度为n * d,向量的参数传递方式前面已经介绍。函数接口定义及在虚基类中的缺省实现如下:
/** Perform training on a representative set of vectors
*
* @param n nb of training vectors
* @param x training vecors, size n * d
*/
virtual void train(idx_t n, const float* x);
void Index::train(idx_t /*n*/, const float* /*x*/) {
// does nothing by default
}
向量添加接口
Index虚基类中提供了两个add添加向量的接口:
- void add (idx_t n, const float *x) 分配的id为ntotal … ntotal + n - 1,这个接口是所有Index子类均需要提供的,这里将它定义为纯虚函数。
- void add_with_ids (idx_t n, const float * x, const idx_t *xids)指定了添加向量的id信息,这个功能并不是所有的Index子类都提供这个功能,Index抽象类提供了缺省实现:抛出FaissException异常。
/** Add n vectors of dimension d to the index.
*
* Vectors are implicitly assigned labels ntotal .. ntotal + n - 1
* This function slices the input vectors in chuncks smaller than
* blocksize_add and calls add_core.
* @param x input matrix, size n * d
*/
virtual void add (idx_t n, const float *x) = 0;
/** Same as add, but stores xids instead of sequential ids.
*
* The default implementation fails with an assertion, as it is
* not supported by all indexes.
*
* @param xids if non-null, ids to store for the vectors (size n)
*/
virtual void add_with_ids (idx_t n, const float * x, const idx_t *xids);
查询接口
Index虚基类中定义了3个查询接口,分别实现不同的功能:
- void search (idx_t n, const float *x, idx_t k, float *distances, idx_t *labels),它从库中查找与输入向量的最相近的k个向量,并输出与相似向量的距离与对应的ID标签信息。如果查询的KNN向量个数小于K,则相应的标签ID填充为-1。这个接口是所有Index子类都需要提供的,因此,在基类中定义为虚基类。
- void range_search (idx_t n, const float *x, float radius, RangeSearchResult *result) ,该接口限制了查询距离的大小,涉及RangeSearchResult参数,在支持该查询的Index子类时,再详细分析。
- void assign (idx_t n, const float * x, idx_t * labels, idx_t k = 1)函数实现功能与seach接口类似的功能,只是不返回具体的距离信息。
/** query n vectors of dimension d to the index.
*
* return at most k vectors. If there are not enough results for a
* query, the result array is padded with -1s.
*
* @param x input vectors to search, size n * d
* @param labels output labels of the NNs, size n*k
* @param distances output pairwise distances, size n*k
*/
virtual void search (idx_t n, const float *x, idx_t k,
float *distances, idx_t *labels) const = 0;
/** query n vectors of dimension d to the index.
*
* return all vectors with distance < radius. Note that many
* indexes do not implement the range_search (only the k-NN search
* is mandatory).
*
* @param x input vectors to search, size n * d
* @param radius search radius
* @param result result table
*/
virtual void range_search (idx_t n, const float *x, float radius,
RangeSearchResult *result) const;
/** return the indexes of the k vectors closest to the query x.
*
* This function is identical as search but only return labels of neighbors.
* @param x input vectors to search, size n * d
* @param labels output labels of the NNs, size n*k
*/
void assign (idx_t n, const float * x, idx_t * labels, idx_t k = 1);
接下来看一下assign()函数的具体实现,它仅仅是实现了对search()函数的封装:它申请了存储distance距离的存储空间,并交由ScopeDeleter来管理它。
void Index::assign (idx_t n, const float * x, idx_t * labels, idx_t k)
{
float * distances = new float[n * k];
ScopeDeleter del(distances);
search (n, x, k, distances, labels);
}
ScopeDeleter是模版类,用于管理由new申请的内存资源,在析构函数中进行释放,该模版类定义在FaissException.h文件中:
/** bare-bones unique_ptr
* this one deletes with delete [] */
template
struct ScopeDeleter {
const T * ptr;
explicit ScopeDeleter (const T* ptr = nullptr): ptr (ptr) {}
void release () {ptr = nullptr; }
void set (const T * ptr_in) { ptr = ptr_in; }
void swap (ScopeDeleter &other) {std::swap (ptr, other.ptr); }
~ScopeDeleter () {
delete [] ptr;
}
};
数据清空和删除接口
Index虚基类中提供了reset()接口,用于清空向量库中数据,本接口要求所有子类实现该功能,该接口被定义为纯虚接口。remove_ids()接口用于从向量库中删除指定标签label的向量,这个接口并不是所有Index索引类型都支持。
/// removes all elements from the database.
virtual void reset() = 0;
/** removes IDs from the index. Not supported by all
* indexes. Returns the number of elements removed.
*/
virtual size_t remove_ids (const IDSelector & sel);
接下来分析一下remove_ids()接口参数IDSelector的实现。IDSelector是一个虚基类,用于指定要删除的向量标签ID,有2个子类:IDSelectorRange用于表示标签范围为[imin, imax],IDSelectorBatch用一个集合来存储标签信息,它使用的std::unordered_set
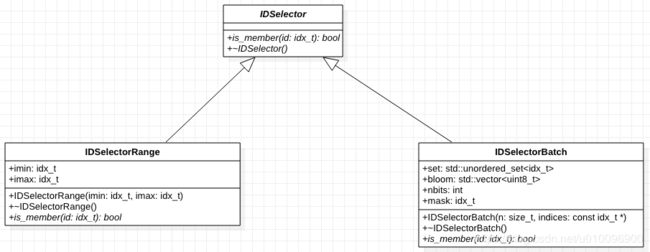
IDSelector虚基类和子类IDSelectorRange比较简单,不再阐述,其定义和实现如下:
/** Encapsulates a set of ids to remove. */
struct IDSelector {
typedef Index::idx_t idx_t;
virtual bool is_member (idx_t id) const = 0;
virtual ~IDSelector() {}
};
/** remove ids between [imni, imax) */
struct IDSelectorRange: IDSelector {
idx_t imin, imax;
IDSelectorRange (idx_t imin, idx_t imax);
bool is_member(idx_t id) const override;
~IDSelectorRange() override {}
};
/***********************************************************************
* IDSelectorRange
***********************************************************************/
IDSelectorRange::IDSelectorRange (idx_t imin, idx_t imax):
imin (imin), imax (imax)
{
}
bool IDSelectorRange::is_member (idx_t id) const
{
return id >= imin && id < imax;
}
重点看一下IDSelectorBatch实现。IDSelectorBatch用于从一个ID集合中批量删除向量。使用std::unordered_set
/** Remove ids from a set. Repetitions of ids in the indices set
* passed to the constructor does not hurt performance. The hash
* function used for the bloom filter and GCC's implementation of
* unordered_set are just the least significant bits of the id. This
* works fine for random ids or ids in sequences but will produce many
* hash collisions if lsb's are always the same */
struct IDSelectorBatch: IDSelector {
std::unordered_set set;
typedef unsigned char uint8_t;
std::vector bloom; // assumes low bits of id are a good hash value
int nbits;
idx_t mask;
IDSelectorBatch (size_t n, const idx_t *indices);
bool is_member(idx_t id) const override;
~IDSelectorBatch() override {}
};
IDSelectorBatch构造函数中在set中插入标签ID,并构建布隆过滤器。
/***********************************************************************
* IDSelectorBatch
***********************************************************************/
IDSelectorBatch::IDSelectorBatch (size_t n, const idx_t *indices)
{
//根据n计算需要比特位数,nbits = log2(n),这里通过位移来计算
nbits = 0;
while (n > (1L << nbits)) nbits++;
nbits += 5;
// for n = 1M, nbits = 25 is optimal, see P56659518
mask = (1L << nbits) - 1; // 设置mask值,布隆过滤器计算使用
bloom.resize (1UL << (nbits - 3), 0); //调整布隆过滤器空间大小,并初始化位0
for (long i = 0; i < n; i++) {
Index::idx_t id = indices[i];
set.insert(id); //插入set集合
id &= mask;
bloom[id >> 3] |= 1 << (id & 7); //hash计算,并设置布隆过滤器相应的比特位
}
}
bool IDSelectorBatch::is_member (idx_t i) const
{
long im = i & mask;
if(!(bloom[im>>3] & (1 << (im & 7)))) { //先根据布隆过滤器查看相应标签ID是否存在,不存在直接返回,否则从set查找。
return 0;
}
return set.count(i);
}
为了方便理上面的代码,简要介绍一下布隆过滤器。布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
重新构建存储向量
后续文章将陆续降到索引Index各种子类的实现,如IndexFlatL2和IndexIVFFlat都存储了完整的向量。为了扩展到非常大的数据集,Faiss提供了一些变体,它们根据乘积量化器(Product Quantizer, PQ)压缩存储的矢量,并进行有损压缩。矢量仍然存储在Voronoi单元中,但是它们的大小减小到可配置的字节数m(d必须是m的倍数)。压缩基于乘积量化器,其可以被视为额外的量化水平,其应用于要编码的矢量的子矢量。在这种情况下,由于矢量未精确存储,因此搜索方法返回的距离也是近似值。
在讲到相关的实现,还会仔细讲解PQ的相关原理。下面的这些接口,都和乘积量化PQ有关。
/** Reconstruct a stored vector (or an approximation if lossy coding)
*
* this function may not be defined for some indexes
* @param key id of the vector to reconstruct
* @param recons reconstucted vector (size d)
*/
virtual void reconstruct (idx_t key, float * recons) const;
/** Reconstruct vectors i0 to i0 + ni - 1
*
* this function may not be defined for some indexes
* @param recons reconstucted vector (size ni * d)
*/
virtual void reconstruct_n (idx_t i0, idx_t ni, float *recons) const;
/** Similar to search, but also reconstructs the stored vectors (or an
* approximation in the case of lossy coding) for the search results.
*
* If there are not enough results for a query, the resulting arrays
* is padded with -1s.
*
* @param recons reconstructed vectors size (n, k, d)
**/
virtual void search_and_reconstruct (idx_t n, const float *x, idx_t k,
float *distances, idx_t *labels,
float *recons) const;
/** Computes a residual vector after indexing encoding.
*
* The residual vector is the difference between a vector and the
* reconstruction that can be decoded from its representation in
* the index. The residual can be used for multiple-stage indexing
* methods, like IndexIVF's methods.
*
* @param x input vector, size d
* @param residual output residual vector, size d
* @param key encoded index, as returned by search and assign
*/
void compute_residual (const float * x, float * residual, idx_t key) const;
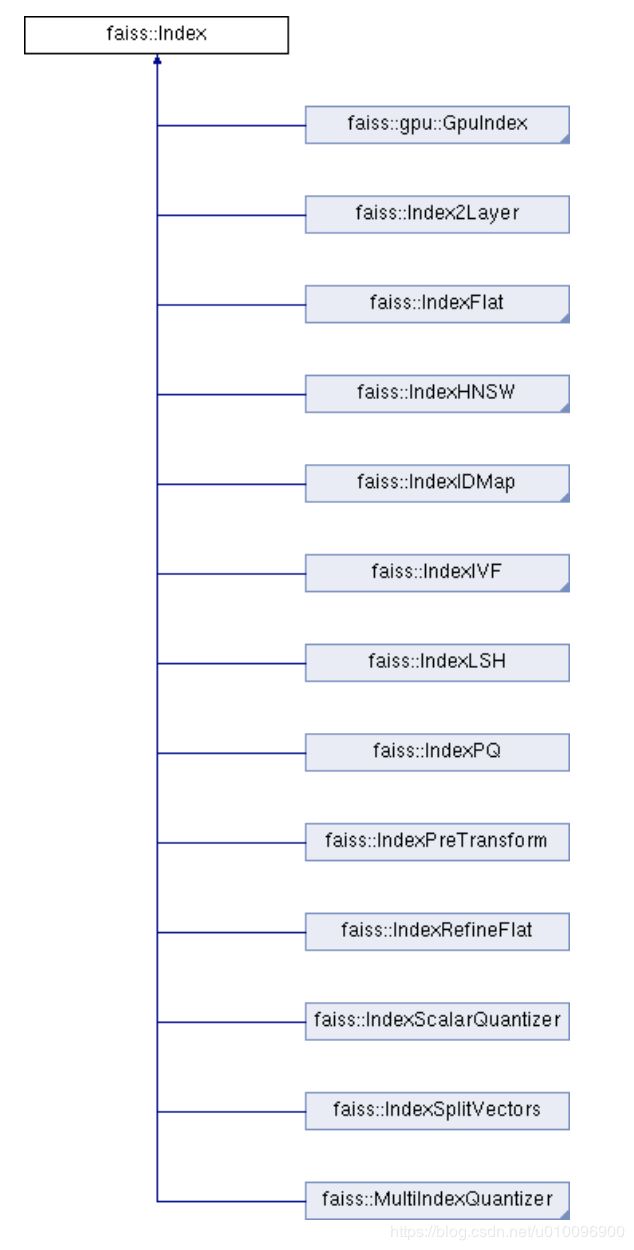
Index虚基类子类
后面的系列文章会详细分析Index子类的实现,这里先将继承自Index的子类在下图中列出。
参考资料
- Faiss:Facebook 开源的相似性搜索类库
- 布隆过滤器
- Low Memory Footprint