Solr安装与IK Analyzer(中文分词器)
一、Solr简介
二、solr安装
三、solr基础
四、IK Analyzer(中文分词器)
一、Solr简介
Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr索引的实现方法很简单,用POST方法向 Solr服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET请求,然后对Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
在以前可能手机或者PC端访问商品的时候,我们服务器的时候我们是直接读取数据库。
而现在用solr我们不直接读取数据库,而是走solr服务器,但是solr服务器的数据(在服务器上存储的是document)是由数据库中加载的。但是不是实时的,我们通过跑定时任务增量或者全量将DB的数据加载到Solr中。

二、solr安装
solr 各种版本集合下载
http://archive.apache.org/dist/lucene/solr/
安装Solr与Tomcat集成:Linux环境CentOS6.5、Tomcat7.0、Solr5.3.2
安装步骤
1、解压tar -zxvf Solr5.3.2.
2 cd /usr/local/solr/solr-5.3.2/server/solr-webapp/webapp
3、拷贝 /usr/local/solr/solr-5.3.2/server/solr-webapp/webapp文件到tomcat的webapps中
cp -r /usr/local/solr/solr-5.3.2/server/solr-webapp/webapp/. /usr/local/tomcat/apache-tomcat-7.0.29/webapps/solr/
4、修改其文件: vim solr/WEB-INF/web.xml 找到nv-entry 内容,修改solr/home地址/usr/local/solr/solr-5.3.2/example/example-DIH/solr。保存并退出即可

5、拷贝相关拓展jar包到tomcat下
cd /usr/local/solr/solr-5.3.2/server/lib/ext && cp * /usr/local/tomcat/apache-tomcat-7.0.29/lib
6、启动tomcat即可 /usr/local/tomcat/apache-tomcat-7.0.29/bin/startup.sh
7、查看日志tail -500f /usr/local/tomcat/apache-tomcat-7.0.29/logs/catalina.out
8、打开浏览器访问
http://IP:8080/solr查看主页。说明solr服务器已经启动

在solr服务器上存储的是document,比如我们进入vim solr-5.3.2/example/example-DIH/solr/solr/conf/schema.xml
可以看到

在图中,我们看到了好多field,比如name等。solr默认提供了索引的字段。这些索引字段不需要我们自己建。在搜索的时候,我们可以指定字段name,我们可以通过java程序,将name的值放到solr服务器上面,我们搜索的时候,直接走solr服务器
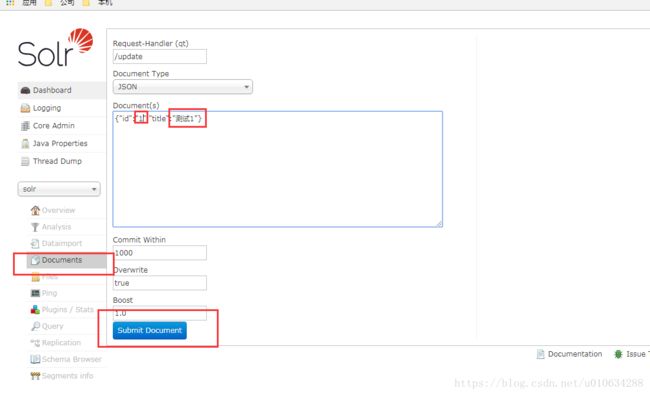
这里做一个小的实验,由于之前我们在tomcat的web.xml中配置了nv-entry的key,我在这里,随便选择一个改了下id和title进行测试
这里多添加几个
可以点击查询看到我们之前插入的文档
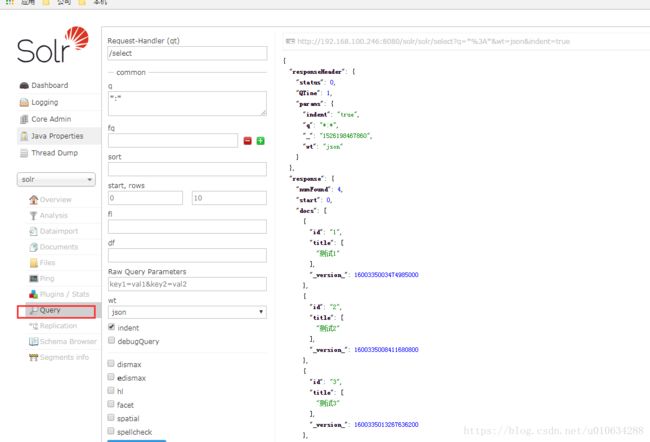
控制台还可以通过参数去过滤相关数据。具体可以自研究一下。
三、solr基础
1、信息源->本地(进行加工和处理)->建立索引库(信息集合,一组文件的集合)
2、搜索的时候从本地的(索引库)信息集合中搜索
3、文本在建立索引和搜索时,都会先进行分词(使用分词器)
4、索引的结构:
索引表(存放具体的词汇,哪些词汇再那些文档里存储,索引里存储的就是分词器分词之后的结果)
存放数据(文档信息集合)
5、用户搜索时:首先经过分词器进行分词,然后去索引表里查找对应的词汇(利用倒排序索引),再找到对应的文档集合
6、索引库位置(目录)
7、信息集合里的每一条数据都是一个文件(存储所有信息,他是一个Filed属性的集合)
8、store是否进行存储(可以不存储,也可以存储)
9、index是否进行存储(可以不索引,也可以索引,索引的话分为分词后索引,或者直接索引)
概括起来可以使用下面的图来表示

四、IK Analyzer(中文分词器)
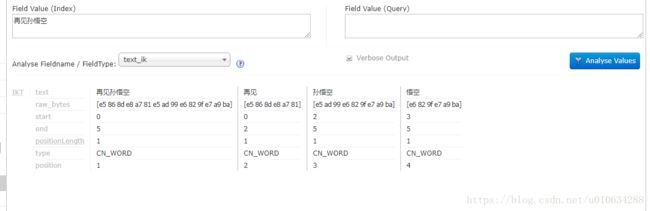
在管控台上,我使用一段文字进行了分词发现

这样,他就把每个字进行分词,这样效率就太低了。我们要求的是,最要能将句子分解成,码农、明天、要、上班、了。类似这样的索引。(PS:索引文件存放在/usr/local/solr/solr-5.3.2/example/example-DIH/solr/solr/data/index)

无论是Solr的还是Lucene的,都对中文分词不支持,所以我们一般索引中文的话需要使用IK中文分词器。
分词器下载地址https://github.com/EugenePig/ik-analyzer-solr5
下载完毕之后编译
JDK8
mvn clean install
JDK7
mvn clean -Djavac.src.version=1.7 -Djavac.target.version=1.7 install
得到ik-analyzer-solr5-5.x.jar
安装:把ik-analyzer-solr5-5.x.jar拷贝到Tomcat的Solr中的应用服务下:
我这里是/usr/local/tomcat/apache-tomcat-7.0.29/webapps/solr/WEB-INF/lib

创建文件夹:/usr/local/tomcat/apache-tomcat-7.0.29/webapps/solr/WEB-INF/classes
把IKAnalyzer.cfg.xml和stopword.dic,ext。dic拷贝到新创建的类目录下即可。

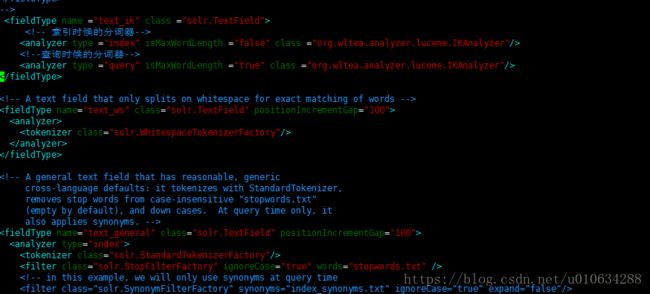
修改solr core的schema文件,默认是位置:
vim /usr/local/solr/solr-5.3.2/example/example-DIH/solr/solr/conf/schema.xml
添加如下配置:
最后启动tamcat
/usr/local/tomcat/apache-tomcat-7.0.29/bin/startup.sh
可以通过 tail -f /usr/local/tomcat/apache-tomcat-7.0.29/logs/catalina.out 查看日志

如果我想自定义一些词库,让IK分词器可以识别,那么就需要自定义扩展词库了。
操作步骤:
1、修改/usr/local/tomcat/apache-tomcat-7.0.29/webapps/solr/WEB-INF/classes的IKAnalyzer.cfg.xml

我们在ext.dic配置我们自己的扩展字典,

重新进行分词