【S2第二学期-使用JSP/Servlet技术开发新闻发布系统】全书知识点总结
使用JSP/Servlet技术开发新闻发布系统
第一章 动态网页开发基础
1. 动态网页的优势:
a) 交互性– 响应客户端的请求并回发
b) 自动更新– 自动生成的HTML代码而无须依次手动编写
c) 随机性– 不同客户访问同一网站时会产生不同的效果
2. 动态网页与静态网页不能相互替代;
3. 两种架构模式的应用程序:
a) C/S架构:
Client/Server(客户端/服务器)应用程序,本地安装的软件通过Internet进行通信,应用系统在客户机上;
安全性:安全性较高,适用于对于安全性较高的场合。
b) B/S架构:
(Browser/Server)应用程序,系统界面由浏览器展示,应用系统在应用服务器上;
安全性:较C/S架构的应用程序较低,适用于对于安全性不高的场合。
4. B/S架构的工作原理:

5. URL全称为“统一资源定位符”。
6. URL的组成:URL由协议、服务器域名或IP地址、端口号、路径组成。
7. 压缩版的Tomcat修改端口号的方法:
在Tomcat安装目录/conf目录下的server.xml下,修改
8. Tomcat的目录结构:

当运行Tomcat时,总是先加载运行classes文件夹内的文件在去加载lib目录下的类。
9. 配置某个项目的起始页的方法:项目目录/WEB-INF的web.xml文件中修改/增加
10. 何为JSP?
JSP就是在HTML中嵌入Java脚本语言;
11. JSP的执行过程:

执行过程详解:
当用户点击操作了JSP页面时,等于向服务器发出了请求,这时Web容器接收到请求后,首先对JSP页面进行转换,转换为Java代码;
之后对Java源码进行编译,编译成.class字节码文件;
这时,容器会执行已经翻译好的class文件,在内部执行,并将结果转换为HTML代码返回到客户端予以显示。
12. JSP页面的组成:
静态内容、指令、表达式、小脚本、声明、标准动作和注释等。
JSP的注释在客户机查看源码时无法看到,而普通的HTML注释依旧可以看到;
Page指令用于导入java包,且多个属性之间使用逗号隔开;
小脚本指在HTML页面中嵌入的<% %>间的代码片段;
表达式指对数据的表示,语法为:<%=Java表达式 %>
13. Tomcat部署、运行项目的注意事项:
a) 项目名绝对不能含有中文;
b) 若项目在系统盘,则需要给此项目的所有关联文件夹都设置权限为EveryOne或当前登入的系统账户;
第二章 JSP数据交互(一)
1. JSP的内置对象对照表
| JSP内置对象的常用方法及其说明 |
||
| 内置对象 |
方法名称 |
方法说明 |
| request |
String getParameter(String name) |
根据表单名称获取数据 |
|
|
String[] getParameterValues(String name) |
获取一组相同名称的控件数据 |
|
|
void setCharacterEncoding(String CharSet) |
设置请求的编码方式 |
|
|
RequestDispatcher getRequestDispatcher(String path) |
可以使用forward转发请求 |
| response |
void AddCookie(Cookie cookie) |
在客户端添加Cookie |
|
|
void setContentType(String type) |
设置HTTP的内容类型 |
|
|
void setCharacterEncoding(String CharSet) |
设置响应的编码方式 |
|
|
void sendRedirect(String location) |
重定向URL路径 |
| session |
void setAttribute(String Key,Object Value) |
以K-V的形式保存到session中 |
|
|
Object getAttribute(String Key) |
通过Key获取session保存的对象 |
|
|
void removeAttribute(String Key) |
从session删除制定Key的session对象 |
|
|
void invalidate() |
手动设置session失效 |
|
|
String getId() |
获取session Id |
| application |
void setAttribute(String Key,Object Value) |
以K-V的形式保存到application中 |
|
|
Object getAttribute(String Key) |
通过Key获取application保存的对象 |
|
|
String RealPath(String path) |
返回相对路径的真实路径 |
| out |
String print()/println() |
向HTML页面输出文本信息 |
2. Request对象用于处理客户端请求的数据
例:String[] channels = request.getParameterValues("channel");//提交页面有共同name为“channel”的元素radiobutton
//取值时使用增强型for循环便利数组集合即可取出
if(channels != null) {
for (String channel : channels) {
out.print(channel+" ");
}
}
3. 两种设置中文字符集编码的方式:
a) 方式一:在项目Java代码中设置:【推荐使用】
request.setCharacterEncoding("UTF-8");
b) 方式二:设置Tomcat安装目录/conf/下的server.xml文件的
增加URIEncoding属性,值为“UTF-8”。
4. Response对象用于响应客户的请求并向客户端输出信息。
工作原理:

5. 转发与重定向的区别:
| 转发与重定向 |
|||||
| 名称 |
JSP对应对象 |
方法 |
功能 |
过程 |
作用场合 |
| 转发 |
request |
getRequestDispatcher.().forward(request,response) |
页面跳转,并转发两个对象(客户端URL不变) |
等同于同一个请求,对象信息保留 |
服务器端 |
| 重定向 |
response |
sendRedirect() |
单纯的页面跳转(客户端URL改变) |
等于两次请求,对象信息丢失 |
客户端 |
6. Session用于保存用户来访时的每一次会话,作用域在服务器端。
当用户打开浏览器访问网站时,session即建立,当关闭浏览器即结束会话。
若Internet Explorer浏览器正在访问session,但此时又开了一个InternetExplorer浏览器,则此时两个浏览器间的session id则是一样的;
若Internet Explorer浏览器正在访问session,但此时又开了一个GoogleChrome浏览器,则此时两个浏览器间的session id则是不同的;
若360浏览器正在访问session,但此时将内核由Chrome内核切换到IE内核,则此时两个浏览器间的sessionid则是一样的;
最后总结:session的每次会话过程是基于浏览器种类的。
7. Session的失效有三种情况:
情况一:浏览操作结束,浏览器关闭后session对象自动销毁;
情况二:手动调用方法实现session失效(常用于网站用户的“注销”功能)。
手动设置失效即调用session的setMaxInactiveInterval([生效秒数,超过此秒数后session对象失效])手动设置失效时间;另一种方法是在项目的WEB-INF/web.xml中加入以下标签:
第二章 JSP数据交互(二)
1. Application对象相当于系统的“全局变量”,且在一个服务器上的一个Web应用只有一个application对象,这样可以使所有用户的数据共享。
此前的session可看作是“私有变量”,而application则可看作是“公有变量”。
使用application对象统计网站的访问人数:
<%
Integer count = (Integer)application.getAttribute("count");
if (count != null) {
count += 1;
} else {
count = 1;
}
application.setAttribute("count",count);
%>
<%
Integer i = (Integer)application.getAttribute("count");
out.print("统计访问量:目前有"+ i + "个人访问过本网站。");
%>
2. 对象的作用域
分为四种作用域:
Page作用域、request作用域、session作用域和application作用域。
Page作用域仅对当前页面有效,转发或重定向到其他页面时page对象失效;
Request作用域在页面间转发时有效;
session作用域在一次会话期间有效;
application作用域面向整个Web应用程序,只要服务器不关闭则一直生效,当服务器重启或关闭时application对象销毁。
3. Cookie
Cookie就是在客户端以字符串保存的文件。
4. Cookie的操作
a) 写入Cookie:
Response.addCookie(new Cookie);
例:
response.addCookie(new Cookie("username","Jack"));
response.addCookie(newCookie("password", "123456"));
b) 读取Cookie:
读取时返回的是Cookie的对象数组,是以K-V的形式保存的。
例:
Cookie[]cookies = request.getCookies();
String user = "";
String pwd = "";
if (cookies != null) {
for (int i = 0; i< cookies.length; i++) {
if(cookies[i].getName().equals("username")) {
user= cookies[i].getValue();
} else if(cookies[i].getName().equals("password")) {
pwd= cookies[i].getValue();
}
}
}
5. Cookie的有效期:
调用Cookie对象的setMaxAge([设置有效时间,单位为秒])。
6. Cookie与session的对比:
| Cookie与session的比较 |
||
| Cookie |
session |
|
| 作用位置 |
客户端 |
服务器端 |
| 值的类型 |
String |
Object |
| 持久性 |
长期保存 |
会话结束即销毁 |
| 适于保存的信息 |
非重要信息 |
较重要信息 |
7. JDBC访问数据库的步骤:
加载JDBC驱动;
与数据库建立连接;
发送SQL语句;
处理返回结果;
关闭各种连接,释放所用的资源。
注意:Object…params表示params这个参数的数组长度是可变的,称为“可变长参数”。此形参的位置可以穿入若干个实参。
三元运算符:
语法:
[布尔类型的表达式]?[结果为true时的值]:[结果为false时的值]
8. JavaBean
何为JavaBean?
JavaBean其实就是一种编程思想,本质是一个Java类,并不是一个组件。目的就是封装数据和封装业务,可跨平台重用,提高安全性,提高编码效率。
特点:
属性私有;
访问属性的getter和setter方法公有。
9. 补充:
a) Application内置对象的getRealpath()方法返回相对路径的真实物理路径。
第五章 使用分层实现业务处理
1. JNDI
Java Naming and Directory Interface(Java命名与目录接口),用于查找、访问各种资源的接口。
2. JNDI的配置
修改位于Tomcat安装目录/conf/context.xml文件,在
参数解释:
Name表示环境名称,对应于java:comp/env/的名称;
Value表示要返回的参数值;
3. JNDI的使用:
Contextctx = new InitialContext(); //使用上下文接口实例化一个初始化上下文对象
//调用上下文对象的lookup()方法按照指定的名称检索对象,并将其转换为String类型的数据进行输出
String testjndi = (String)ctx.lookup("java:comp/env/tjndi");
out.print("JNDI:" +testjndi);
注意:对象名必须以“java:comp/env/”开头,后面跟在context.xml文件中配置的环境名称。
4. JNDI与application对象的对比:
| JNDI与application的对比 |
||
|
|
JNDI |
application内置对象 |
| 可见性 |
服务器上的所有Web应用 |
服务器上的某一个Web应用 |
5. 数据库连接池
作用是分配、管理和释放数据库连接。
工作原理:
初始化阶段:
创建一定数量的数据库连接并放入连接池的空闲池中,且无论是否在用或不在用,数量都会创建为这么多;
使用阶段:
使用时,系统进入空闲池中检查还有没有空闲连接,有则分配后进入使用;否则再去检查是否达到了最大连接数,没有达到则会创建一个数据库连接以供使用,若达到了最大连接数就需等待了,如果超时则返回null值。当达到数据库连接池所能提供的最大连接数量时,若在向连接池请求连接,则将加入等待。
6. 使用数据库连接池与JNDI获得数据库连接,访问数据库:
a) 数据源的配置:
首先配置Tomcat安装目录/conf/context.xml的
之后配置Tomcat安装目录/conf/context.xml的< Resource>标签,内容如下:
含义解释:
Name表示Resource的名字;
Auth表示由谁来管理Resource(Container表示由容器创建和管理;Application表示由Web应用创建和管理);
Type表示Resource所用到的类名;
maxActive表示在使用的最大数据库活动连接数;
maxIdle表示连接池处于空闲的最大数据库连接数量(0表示数量随意,不受限);
maxWait表示连接池处于空闲的最长时间(单位:毫秒;1表示一直在等待)
username表示数据库的有效用户名
password表示数据库的有效登录密码
driverClassName表示要用到的Java驱动类
url表示数据库的连接字符串
b) 项目中web.xml的配置:
在
// description标签表示对此数据源的描述
// res-ref-name标签表示引用Resource的名字,对应于context.xml中
// res-type表示引用Resource的类名
// res-auth表示由谁来创建和管理Resource,对应于context.xml中
7. 三层架构
a) 层层间的关系:

表示层依赖业务逻辑层,业务逻辑层依赖数据访问层;
上一层依赖下一层,且不跨层调用;
下一层不依赖上一层。
8. 三层架构开发的优势:
a) 职责划分清晰;
b) 无损替换;
c) 复用代码;
d) 高内聚,低耦合。
9. 补充:
a) Application对象仅用于一个Web应用中访问,因为毕竟application对象是存储在内存中的,想要在一个项目中跨项目访问另一个项目的application对象是访问不到的,因为各个项目之间是相互独立的;
b) JNDI通过名称将资源与服务进行关联,类似于Map集合的K-V存储形式;
c) JNDI与ASP.NET中的Web.config的
d) 数据源(DataSource)负责创建和管理数据库连接,而Tomcat则会从上下文(Context)中取出某一个连接放入连接池中以供应用程序所使用;
e) 数据库连接是由Tomcat容器管理的;
f) 获取DataSource(数据源)对象的过程:

第六章 JSP开发业务应用
1. 分页
a) 原理:
每次翻页时只从数据库中检索出本页要显示的数据而不是全部查询出来。
b) 实现:
i. 确定每页要显示几条数据;
ii. 计算出总共要显示多少页;
iii. 编写SQL语句
packagecom.Entity;
importjava.util.List;
/**
* 分页类
*
* @author Cortana for ThinkPad
*
*/
public classSplitPage {
/**
* 总共要显示多少页
*/
private int totalPageCount = 1;
/**
* 每页显示多少条数据
*/
private int pageSize = 0;
/**
* 全部的数据数量
*/
private int totalCount = 0;
/**
* 当前为第几页
*/
private int currPageNo = 1;
List
public int getTotalCount() {
return totalCount;
}
//设置全部的数据条数
public void setTotalCount(inttotalCount) {
if (totalCount > 0) {
this.totalCount =totalCount;
//总页数的计算方法:
若总记录数除以每页显示的固定数据量可以除尽,则要显示的全部页数就是它俩的商,因为能除尽代表每页显示固定的数据条数正好可以在当前显示的总页数内容得下;
若总记录数除以每页显示的固定数据量除不尽,则要显示的全部页数就是它俩的商+1,因为能除不尽代表每页显示固定的数据条数不足以在当前显示的总页数内全部显示,还需要再额外加1页才能全部显示完
totalPageCount =this.totalCount % pageSize == 0 ? (this.totalCount / pageSize)
:this.totalCount / pageSize + 1;
}
}
public int getTotalPageCount() {
return totalPageCount;
}
public void setTotalPageCount(inttotalPageCount) {
this.totalPageCount =totalPageCount;
}
public int getPageSize() {
return pageSize;
}
public void setPageSize(int pageSize) {
if (pageSize > 0) {
this.pageSize =pageSize;
}
}
public int getCurrPageNo() {
if (totalPageCount == 0) {
return 0;
}
return currPageNo;
}
public void setCurrPageNo(intcurrPageNo) {
if (this.currPageNo > 0) {
this.currPageNo =currPageNo;
}
}
public List
return newsList;
}
public voidsetNewsList(List
this.newsList = newsList;
}
}
c) 理解分页SQL语句:
select top 3 * from NewsList where ArticleId not in
(select top ((1-1)*3) ArticleId from NewsList)
解释:
外层查询:在NewsList表中查询所有结果的前三列;
内层子查询:在NewsList表中查询出前0个文章编号的数据;
那么此时,按照当前语句来讲,子查询应无返回结果,外层查询查询到了前三条数据,那么not in中又没有数据,所以第一次等于子查询没有实际用处,即正常显示前三条数据,结果如下:
分段查询:
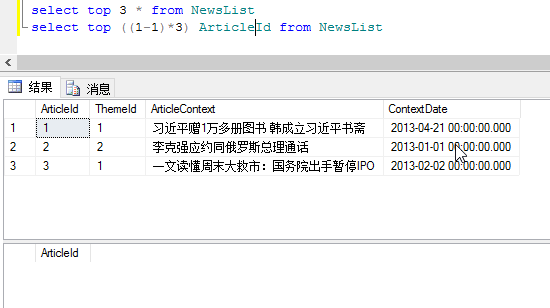
合并查询:

第二次查询:
那么此时,按照当前语句来讲,子查询应无返回结果,外层查询查询到了前三条数据,那么not in中又没有数据,所以第一次等于子查询没有实际用处,即正常显示前三条数据,结果如下:
分段查询:

可能会问为什么第二次查询的时候,分开查询怎么新闻的序号都是1、2、3而第一条SQL语句的查询结果不是6条呢?不应该是查询出前6条然后1、2、3条除外才对吗?就像下图:

此时要注意了,因为语句中使用not in进行条件约束,当首先执行子查询select top ((2-1)*3) ArticleId from NewsList时,查询出的结果为1、2、3,再执行外层的查询时,就会将1、2、3这三条数据过滤掉,从而就会查询出后三条数据来,一定要理解SQL语句的执行顺序,线执行子查询,根据子查询的条件在执行外层查询时就会根据关键字进行过滤。
分页SQL语句示意:

2. 使用Commons-FileUpload组件实现文件上传
a) 组件:
commons-fileupload-1.2.1.jar – 用于客户端向服务器发送文件数据
commons-io-1.3.2.jar – 用于服务器写入客户端上传过来的文件数据
b) 表单的属性设置:
设置