Flink的local和standalone HA安装部署
文章目录
- 1、local模式
- 2、standalone cluster部署
- 3、standalone cluster HA部署
版本介绍:
centos 7.7
jdk 1.8.152
hadoop 2.7.1
zookeeper 3.4.10
flink 1.9.1
1、local模式
flink的local模式运行在单个jvm中。同时local方便快速测试。
安装方式:
需求:
- Java 1.8.x or higher,
- ssh
1、下载
2、解压
[root@hadoop01 local]# tar -zxvf /home/flink-1.9.1-bin-scala_2.11.tgz -C /usr/local/
[root@hadoop01 local]# cd ./flink-1.9.1/
3、配置环境变量
export FLINK_HOME=/usr/local/flink-1.9.1/
export PATH=$PATH:$JAVA_HOME/bin:$ZK_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$KAFKA_HOME/bin:$FLINK_HOME/bin:
4、刷新环境变量
[root@hadoop01 flink-1.9.1]# source /etc/profile
[root@hadoop01 flink-1.9.1]# which flink
5、启动测试
./bin/start-cluster.sh
6、测试:
jps

访问web地址:http://hadoop01:8081
启动流作业:
监控输入数据
[root@hadoop01 flink-1.9.1]# nc -l 9000
lorem ipsum
ipsum ipsum ipsum
bye
启动job
[root@hadoop01 flink-1.9.1]# ./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000

监控结果
[root@hadoop01 ~]# tail -f /usr/local/flink-1.9.1/log/flink-*-taskexecutor-*.out
lorem : 1
bye : 1
ipsum : 4
启动批次作业:
[root@hadoop01 flink-1.9.1]# flink run ./examples/batch/WordCount.jar --input /home/words --output /home/1907/out/00
Starting execution of program
Program execution finished
Job with JobID 8b258e1432dde89060c4acbac85f57d4 has finished.
Job Runtime: 3528 ms
web控制台如下图:
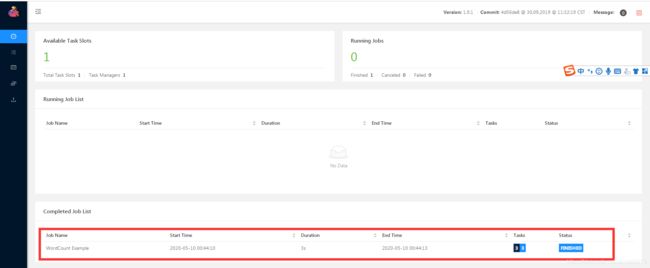
7、关闭local模式
./bin/stop-cluster.sh
2、standalone cluster部署
flink的集群也是主从架构。主是jobManager,从是taskManager。如下图来自于官网。
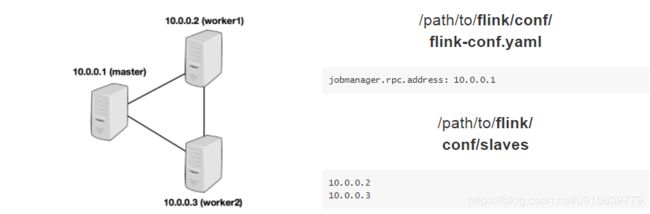
集群规划:
| ip | 服务 | 描述 |
|---|---|---|
| 192.168.216.111 | jobManager、taskManager | |
| 192.168.216.112 | taskManager | |
| 192.168.216.113 | taskManager |
1、下载
2、解压
[root@hadoop01 local]# tar -zxvf /home/flink-1.9.1-bin-scala_2.11.tgz -C /usr/local/
[root@hadoop01 local]# cd ./flink-1.9.1/
3、配置环境变量
export FLINK_HOME=/usr/local/flink-1.9.1/
export PATH=$PATH:$JAVA_HOME/bin:$ZK_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$KAFKA_HOME/bin:$FLINK_HOME/bin:
4、刷新环境变量
[root@hadoop01 flink-1.9.1]# source /etc/profile
[root@hadoop01 flink-1.9.1]# which flink
5、集群配置
配置三个配置文件
-rw-r--r--. 1 yarn games 10327 Jul 18 2019 flink-conf.yaml
-rw-r--r--. 1 yarn games 15 Jul 15 2019 masters
-rw-r--r--. 1 yarn games 10 Jul 15 2019 slaves
配置flink-conf.yaml:
#修改几个地方:
jobmanager.rpc.address: hadoop01
rest.port: 8081
rest.address: hadoop01
配置masters:
hadoop01:8081
配置slaves:
hadoop01
hadoop02
hadoop03
6、分发到别的服务器
[root@hadoop01 flink-1.9.1]# scp -r ../flink-1.9.1/ hadoop02:/usr/local/
[root@hadoop01 flink-1.9.1]# scp -r ../flink-1.9.1/ hadoop03:/usr/local/
并配置好其他服务器的环境变量。。。。。。
7、启动集群
[root@hadoop01 flink-1.9.1]# start-cluster.sh
[root@hadoop01 flink-1.9.1]# jps
2080 ResourceManager
1684 NameNode
5383 StandaloneSessionClusterEntrypoint
1803 DataNode
2187 NodeManager
5853 TaskManagerRunner
访问web:http://hadoop01:8081/#/overview
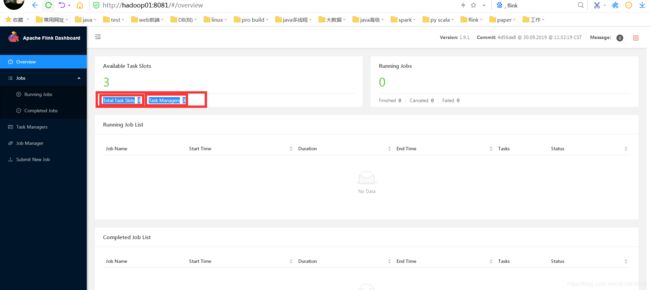
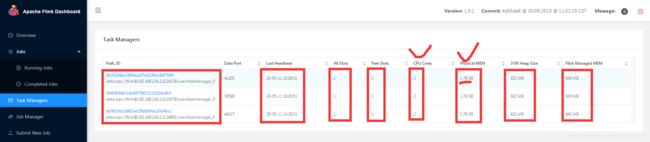
8、运行作业
[root@hadoop01 flink-1.9.1]# flink run ./examples/batch/WordCount.jar --input /home/words --output /home/1907/out/02
Starting execution of program
Program execution finished
Job with JobID dd30661b01cc6f663fe22dab7d7ef542 has finished.
Job Runtime: 6432 ms
查看结果:
[root@hadoop01 flink-1.9.1]# cat /home/1907/out/02
生产中:
1、jobmamager配置到单独服务器即可,,,本身使用不了多少内存。
2、taskmamager配置多台服务器,内存充足,能够满足业务即可。
3、standalone cluster HA部署
基于standalone cluster集群升级部署。
1、修改配置:flink-conf.yaml
high-availability: zookeeper
high-availability.zookeeper.quorum: hadoop01:2181,hadoop02:2181,hadoop03:2181
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /cluster_flink
high-availability.storageDir: hdfs://hadoop01:9000/flink/recovery
2、修改配置:masters
hadoop01:8081
hadoop02:8081
3、启动集群
启动顺序:先启动zk和hdfs、再启动flink。
拷贝hdfs的依赖包:
[root@hadoop01 ~]# cp /home/flink-shaded-hadoop-2-uber-2.7.5-10.0.jar /usr/local/flink-1.9.1/lib/
[root@hadoop01 ~]# scp /home/flink-shaded-hadoop-2-uber-2.7.5-10.0.jar hadoop02:/usr/local/flink-1.9.1/lib/
[root@hadoop01 ~]# scp /home/flink-shaded-hadoop-2-uber-2.7.5-10.0.jar hadoop03:/usr/local/flink-1.9.1/lib/
启动集群:
[root@hadoop01 ~]# start-cluster.sh
4、测试提交作业:
![]()
[root@hadoop01 ~]# flink run /usr/local/flink-1.9.1/examples/batch/WordCount.jar --input /home/words --output /home/out/fl00
结果:
[root@hadoop01 ~]# cat /home/out/fl00
1813 4
gp1813 3
hello 2
hi 1
5、并测试HA的切换:
通过log查看leader还是standby状态:
hadoop01的日志
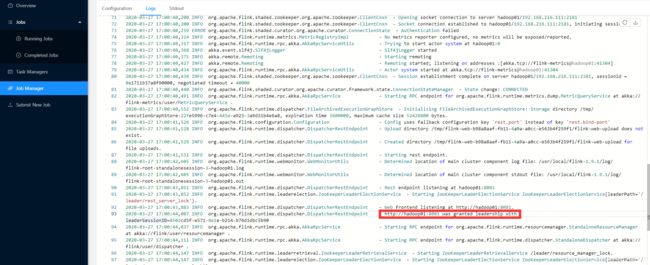
由上可以看出hadoop01是leader。也就是active状态。
hadoop02的日志
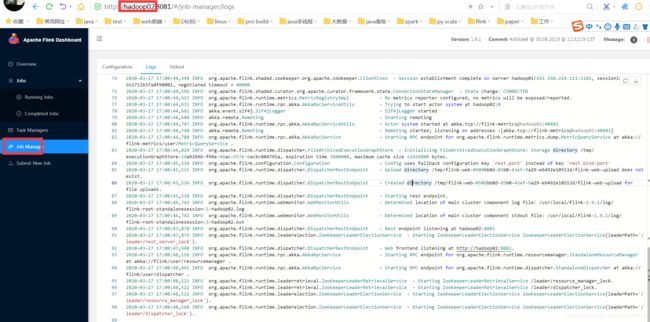
hadoop02的日志没有leadership标识,也就是为standby状态。
手动杀死hadoop01激活状态的jobmanager:
[root@hadoop01 ~]# jps
3840 TaskManagerRunner
2454 NodeManager
1959 NameNode
3385 StandaloneSessionClusterEntrypoint
1802 QuorumPeerMain
4026 Jps
2092 DataNode
2350 ResourceManager
[root@hadoop01 ~]# kill -9 3385 ##或者使用jobmanager.sh stop
再次查看hadoop02的log:
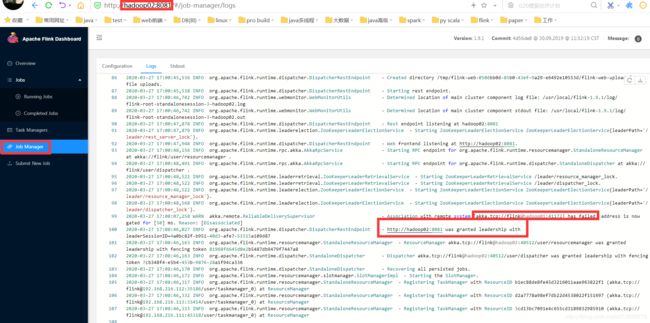
显示hadoop02为leader状态。
测试web是否能提交并运行作业:
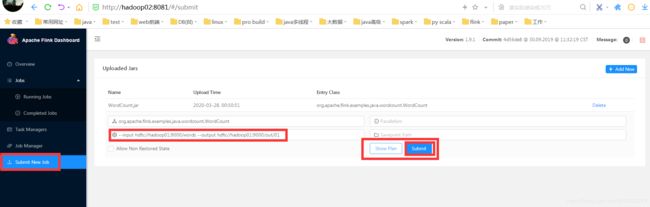
结果查看:
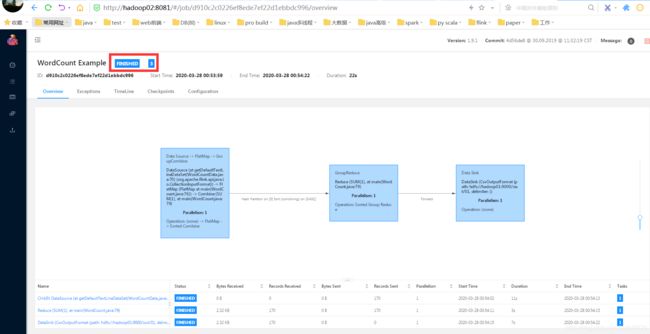
6、重启hadoop01的jobmanager:
[root@hadoop01 flink-1.9.1]# jobmanager.sh start
Starting standalonesession daemon on host hadoop01.
[root@hadoop01 flink-1.9.1]# jps
3840 TaskManagerRunner
5408 StandaloneSessionClusterEntrypoint
查看hadoop01的日志状态:
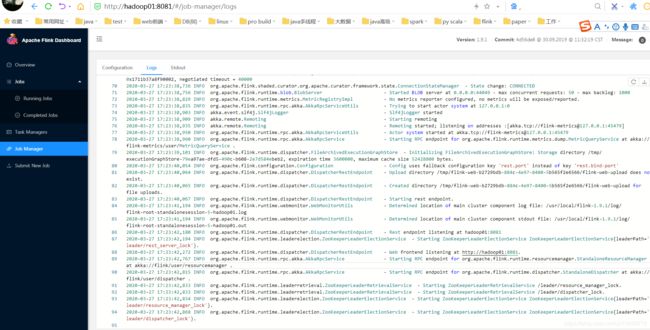
没有那个授权leader信息,代表就是一个standby状态咯。
HA的正常切换功能就可以咯。
到此为之,我们的local模式、standalone cluster和standalone cluster HA部署完成。