TensorFlow 分布式(Distributed TensorFlow)
Distributed Tensorflow
基本概念
Tensorflow 集群
A TensorFlow “cluster” is a set of “tasks” that participate in the distributed execution of a TensorFlow graph. Each task is associated with a TensorFlow “server”, which contains a “master” that can be used
to create sessions, and a “worker” that executes operations in the graph.
从上面的定义可以看出,所谓的TensorFlow集群就是一组任务,每个任务就是一个服务。每个服务由两个部分组成,第一部分是master,用于创建session,第二部分是worker,用于执行具体的计算。
TensorFlow一般将任务分为两类job:一类叫参数服务器,parameter server,简称为ps,用于存储tf.Variable;一类就是普通任务,称为worker,用于执行具体的计算。
即:distributed tensorflow 包含两类job: ps server 和 worker server, 每类job 可以包含多个 task, 每个task 是1个server,而每个server 包含两部分: master 和 worker, master用于创建session, worker用于执行具体的计算。
首先来理解一下参数服务器的概念。
一般而言,机器学习的参数训练过程可以划分为两个类别:
第一类: 根据参数算算梯度。
第二类:根据梯度更新参数。
对于小规模训练,数据量不大,参数数量不多,一个CPU就足够了,两类任务都交给一个CPU来做。
对于普通的中等规模的训练,数据量比较大,参数数量不多,计算梯度的任务负荷较重,参数更新的任务负荷较轻,所以将第一类任务交给若干个CPU或GPU去做,第二类任务交给一个CPU即可。
对于超大规模的训练,数据量大、参数多,不仅计算梯度的任务要部署到多个CPU或GPU上,而且更新参数的任务也要部署到多个CPU。
如果计算量足够大,一台机器能搭载的CPU和GPU数量有限,就需要多台机器来进行计算能力的扩展了。参数服务器是一套分布式存储,用于保存参数,并提供参数更新的操作。
创建一个集群
一个tensorflow“集群”是一套“任务”,参加一个tensorflow图的分布式执行。每个任务都与一个tensorflow“服务器”相关,其中包含一个“master”,可以用来创建会话,和“worker”,执行操作的图。集群也可以分为一个或多个“作业”,其中每个作业包含一个或多个任务。
创建一个集群,你开始在每一tensorflow服务器集群的任务。每项任务通常运行在不同的机器上, 但是你可以运行多个任务在同一台机器上(例如,控制不同的GPU设备)。在每个任务中,做以下操作:
1.创建一个 tf.train.ClusterSpec t描述集群中的所有任务。对于每一个任务,这应该是相同的。
2.创建一个 tf.train.Server, 通过 tf.train.ClusterSpec 的构造函数,确定本地任务的工作名称和任务index。
创建一个 tf.train.ClusterSpec 描述集群
把列表传给 tf.train.ClusterSpec 的构造函数.例如:
在每个任务里,创建一个 tf.train.Server 的实例
一个tf.train.server对象包含一组本地设备,一组连接在tf.train.clusterspec其他任务, 和一个“会话”的目标,可以使用它们来执行分布式计算。 每个服务器都是一个特定的命名作业的成员,并在该作业中有一个任务索引。 服务器可以与集群中的任何其他服务器进行通信。
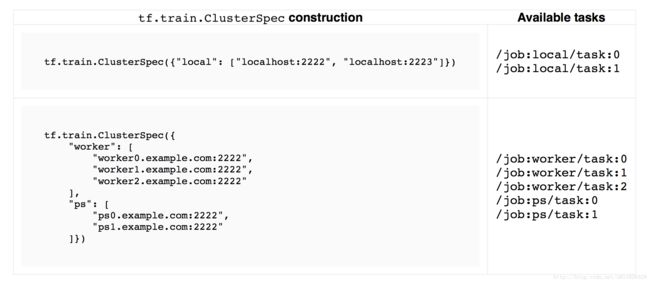
例如,有两个服务器在本地运行启动一个集群:localhost:2222,localhost:2223,在本地机器运行下面的两个不同进程的代码:
# In task 0:
cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]})
server = tf.train.Server(cluster, job_name="local", task_index=0) # In task 1:
cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]})
server = tf.train.Server(cluster, job_name="local", task_index=1) 注:手动指定这些集群规格可以是繁琐的,特别是对于大集群。
我们来看一下怎么创建一个TensorFlow集群。每个任务用一个ip:port表示。TensorFlow用tf.train.ClusterSpec表示一个集群信息,举例如下:
import tensorflow as tf
# Configuration of cluster
ps_hosts = [ "xx.xxx.xx.xxxx:oooo", "xx.xxx.xx.xxxx:oooo" ]
worker_hosts = [ "xx.xxx.xx.xxxx:oooo", "xx.xxx.xx.xxxx:oooo", "xx.xxx.xx.xxxx:oooo" ]
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})上面的语句提供了一个TensorFlow集群信息,集群有两类任务,称为job,一个job是ps,一个job是worker;ps由2个任务组成,worker由3个任务组成。
定义完集群信息后,使用tf.train.Server创建每个任务:
tf.app.flags.DEFINE_string("job_name", "worker", "One of 'ps', 'worker'")
tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job")
FLAGS = tf.app.flags.FLAGS
def main(_):
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
server.join()
if __name__ == "__main__":
tf.app.run()对于本例而言,我们需要在ip:port对应的机器上运行每个任务,共需执行五次代码,生成五个任务。
python worker.py --job_name=ps --task_index=0
python worker.py --job_name=ps --task_index=1
python worker.py --job_name=worker --task_index=0
python worker.py --job_name=worker --task_index=1
python worker.py --job_name=worker --task_index=2我们找到集群的某一台机器,执行下面的代码:
# -*- coding=utf-8 -*-
import tensorflow as tf
import numpy as np
train_X = np.random.rand(100).astype(np.float32)
train_Y = train_X * 0.1 + 0.3
# 选择变量存储位置和op执行位置,这里全部放在worker的第1个task上
with tf.device("/job:worker/task:0"):
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
w = tf.Variable(0.0, name="weight")
b = tf.Variable(0.0, name="reminder")
y = w * X + b
loss = tf.reduce_mean(tf.square(y - Y))
init_op = tf.global_variables_initializer()
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
# 选择创建session使用的master
with tf.Session("grpc://xx.xxx.xx.xxxx:oooo") as sess:
sess.run(init_op)
for i in range(500):
sess.run(train_op, feed_dict={X: train_Y, Y: train_Y})
if i % 50 == 0:
print i, sess.run(w), sess.run(b)
print sess.run(w)
print sess.run(b)执行结果如下:
0 0.00245265 0.00697793
50 0.0752466 0.213145
100 0.0991397 0.279267
150 0.107308 0.30036
200 0.110421 0.306972
250 0.111907 0.308929
300 0.112869 0.309389
350 0.113663 0.309368
400 0.114402 0.309192
450 0.115123 0.308967
0.115824
0.30873其实ps和worker本质上是一个东西,就是名字不同,我们将上例中的with tf.device("/job:worker/task:0"):改为with tf.device("/job:ps/task:0"):,一样能够执行。之所以在创建集群时要分为两个类别的任务,是因为TensorFlow提供了一些工具函数,会根据名字不同赋予task不同的任务,ps的用于存储变量,worker的用于计算。
标注模型中的分布式设备
为了将某个操作放在某个特殊的处理过程上,在分布式环境下依然可以使用tf.device()函数,之前是用来指明是放在CPU还是GPU上的。譬如:
with tf.device("/job:ps/task:0"):
weights_1 = tf.Variable(...)
biases_1 = tf.Variable(...)
with tf.device("/job:ps/task:1"):
weights_2 = tf.Variable(...)
biases_2 = tf.Variable(...)
with tf.device("/job:worker/task:7"):
input, labels = ...
layer_1 = tf.nn.relu(tf.matmul(input, weights_1) + biases_1)
logits = tf.nn.relu(tf.matmul(layer_1, weights_2) + biases_2)
# ...
train_op = ...
with tf.Session("grpc://worker7:2222") as sess:
for _ in range(10000):
sess.run(train_op)在上面的例子中,Variables在job ps的两个task上被创建,然后计算密集型的部分创建在job work上。TensorFlow会自动地在不同的job之间传输数据。(从job到work是前向传递,而从worker到ps是梯度应用)。另外,tensorflow 提供了tf.train.replica_device_setter函数,帮我们自动执行分配。
# 通过tf.train.replica_device_setter函数来指定执行每一个运算的设备
# tf.train.replica_device_setter函数会自动将所有的参数分配到参数服务器上,
# 而计算分配到当前的计算服务器上
# Between-graph replication
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):术语
Cluster
一个TensorFlow集群会包含一个或者多个TensorFlow的服务端,被切分为一系列命名的job,而每个job又会负责一系列的tasks。一个集群一般会专注于一个相对高层的目标,譬如用多台机器并行地训练一个神经网络。
Job
一个job会包含一系列的致力于某个相同目标的task。譬如,一个叫ps(意思是参数服务)的job会用于处理存储与更新Variables相关的工作。而一个叫worker的job会用于承载那些用于计算密集型的无状态节点。一般来说一个job中的tasks会运行在不同的机器中。
Task
一个Task一般会关联到某个单一的TensorFlow服务端的处理过程,属于一个特定的job并且在该job的任务列表中有个唯一的索引。
TensorFlow server
用于运行grpc_tensorflow_server的处理过程,是一个集群中的一员,并且向外暴露了一个Master Service与一个Worker Service。
Master service
Master Service是一个RPC服务用于与一系列远端的分布式设备进行交互。Master Service实现了tensorflow::Session 接口, 并且用来协调多个worker service。
Worker service
一个执行部分TensorFlow图部分内容的RPC服务。
Client
一个典型的客户端一般会构建一个TensorFlow的图并且使用tensorflow::Session来完成与集群的交互。客户端一般会用Python或者C++编写,一般来说一个客户端可以同时与多个服务端进行交互,并且一个服务端也可以同时服务于多个客户端。
总的来说: 举一个例子
下面的代码展示了分布式训练程序的框架 实现了between-graph replication和asynchronous training。它包括参数服务器和worker任务的代码。
import tensorflow as tf
# Flags for defining the tf.train.ClusterSpec
tf.app.flags.DEFINE_string("ps_hosts", "",
"Comma-separated list of hostname:port pairs")
tf.app.flags.DEFINE_string("worker_hosts", "",
"Comma-separated list of hostname:port pairs")
# Flags for defining the tf.train.Server
tf.app.flags.DEFINE_string("job_name", "", "One of 'ps', 'worker'")
tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job")
FLAGS = tf.app.flags.FLAGS
def main(_):
ps_hosts = FLAGS.ps_hosts.split(",")
worker_hosts = FLAGS.worker_hosts.split(",")
# Create a cluster from the parameter server and worker hosts.
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
# Create and start a server for the local task.
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
if FLAGS.job_name == "ps":
server.join()
elif FLAGS.job_name == "worker":
# Assigns ops to the local worker by default.
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):
# Build model...
loss = ...
global_step = tf.Variable(0)
train_op = tf.train.AdagradOptimizer(0.01).minimize(
loss, global_step=global_step)
saver = tf.train.Saver()
summary_op = tf.merge_all_summaries()
init_op = tf.initialize_all_variables()
# Create a "supervisor", which oversees the training process.
sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0),
logdir="/tmp/train_logs",
init_op=init_op,
summary_op=summary_op,
saver=saver,
global_step=global_step,
save_model_secs=600)
# The supervisor takes care of session initialization, restoring from
# a checkpoint, and closing when done or an error occurs.
with sv.managed_session(server.target) as sess:
# Loop until the supervisor shuts down or 1000000 steps have completed.
step = 0
while not sv.should_stop() and step < 1000000:
# Run a training step asynchronously.
# See `tf.train.SyncReplicasOptimizer` for additional details on how to
# perform *synchronous* training.
_, step = sess.run([train_op, global_step])
# Ask for all the services to stop.
sv.stop()
if __name__ == "__main__":
tf.app.run()代码说明
ClusterSpec的定义,需要把你要跑这个任务所有的ps和worker的节点的ip和端口信息都包含进去,所有的节点都要执行这段代码,大家就互相知道了,这个集群里都有哪些成员,不同成员的类型是什么,是ps节点还是worker节点
tf.train.Server定义开始,每个节点就不一样了。根据执行的命令参数不同,决定了这个任务是哪个任务。如果任务名字是ps的话,程序就join到这里,作为参数更新的服务,等待其他worker节点给他提交参数更新的数据。如果是worker任务,就继续执行后面的计算任务。
replica_device_setter,根据TensorFlow的文档对这个的解释,在这个with语句之下定义的参数,会自动分配到参数服务器上去定义,如果有多个参数服务器,就轮流循环分配。
Supervisor,类似于一个监督者,因为分布式了,很多机器都在运行,像参数初始化、保存模型、写summary,这个supervisor帮你一起弄起来了,就不用自己手动去做这些事情了,而且在分布式的环境下涉及到各种参数的共享,其中的过程自己手工写也不好写,于是TensorFlow就给大家包装好这么一个东西。这里的参数is_chief比较重要。
is_chief: If True, create a chief supervisor in charge of initializing and restoring the model. If False, create a supervisor that relies on a chief supervisor for inits and restore. 在所有的计算节点里还是有一个主节点的,这个主节点来负责初始化参数,模型的保存,summary的保存。logdir就是保存和装载模型的路径。不过这个似乎启动后会去这个logdir的目录去看有没有checkpoint的文件,有的话就自动装载了,没用就用init_op指定的初始化参数,好像没有参数指定不让它自动load的
主worker节点负责模型参数初始化等工作,在这个过程中,其他worker节点等待主节点完成初始化工作,等主节点初始化完成后,就可以跑数据了。
- 这里的global_step的值,是可以所有计算节点共享的,在执行optimizer的minimize的时候,会自动+1, 虽有可以通过这个可以知道所有的计算节点一共计算了多少步了。
同步更新与异步更新
CPU负责梯度平均、参数更新,不同GPU训练模型副本(model replica)。基于训练样例子集训练,模型有独立性。
步骤:
不同GPU分别定义模型网络结构。
单个GPU从数据管道读取不同数据块,前向传播,计算损失,计算当前变量梯度。
所有GPU输出梯度数据转移到CPU,梯度求平均操作,模型变量更新。重复,直到模型变量收敛。
数据并行,提高SGD效率。SGD mini-batch样本,切成多份,模型复制多份,在多个模型上同时计算。多个模型计算速度不一致,CPU更新变量有同步、异步两个方案。
分布式随机梯度下降法,模型参数分布式存储在不同参数服务上,工作节点并行训练数据,和参数服务器通信获取模型参数。
同步随机梯度下降法(Sync-SGD,同步更新、同步训练)
步骤 训练时,每个节点上工作任务读入共享参数,执行并行梯度计算,同步需要等待所有工作节点把局部梯度处好,将所有共享参数合并、累加,再一次性更新到模型参数,下一批次,所有工作节点用模型更新后参数训练。
即:各 worker 计算出各自部分的梯度;当每个 worker 梯度计算完成后,收集到一起算出总梯度,然后在求总梯度平均值,用梯度平均值去更新参数。同步更新模式下,每次都要等各 worker 的梯度计算完后才能进行参数更新操作,处理速度取决于计算梯度最慢的那个 worker,其他 worker 存在大量的等待时间浪费;
优势 每个训练批次考虑所有工作节点训练情部,损失下降稳定。
劣势 性能瓶颈在最慢工作节点。异楹设备,工作节点性能不同,劣势明显
异步随机梯度下降法(Async-SGD,异步更新、异步训练)
步骤 每个工作节点任务独立计算局部梯度,异步更新到模型参数,不需执行协调、等待操作。
即: 异步更新模式下,所有 worker 只需要算自己的梯度,根据自己的梯度更新参数,不同 worker 之间不存在通信和等待。
优势 性能不存在瓶颈。
劣势 每个工作节点计算梯度值发磅回参数服务器有参数更新冲突,影响算法收剑速度,损失下降过程抖动较大。
同步更新、异步更新实现区别于更新参数服务器参数策略。
数据量小,各节点计算能力较均衡,用同步模型。
数据量大,各机器计算性能参差不齐,用异步模式。
带备份的Sync-SGD(Sync-SDG with backup)
论文: 《Revisiting Distributed Synchronous SGD》
增加工作节点,解决部分工作节点计算慢问题。工作节点总数n+n*5%,n为集群工作节点数。异步更新设定接受到n个工作节点参数直接更新参数服务器模型参数,进入下一批次模型训练。计算较慢节点训练参数直接丢弃。
图内模式与图间模式(数据并行)
同步更新、异步更新有图内模式(in-graph pattern)和图间模式(between-graph pattern),独立于图内(in-graph)、图间(between-graph)概念。
in-graph和between-graph模式都支持同步更新和异步更新。
图内复制(in-grasph replication)
所有操作(operation)在同一个图中,用一个客户端来生成图,把所有操作分配到集群所有参数服务器和工作节点上。图内复制和单机多卡类似,扩展到多机多卡,数据分发还是在客户端一个节点上。
即:in-graph模式下数据分发在一个节点上。这种方式配置简单,其他结算节点只需join操作,暴露一个网络接口,等在那里接受任务就好。但坏处就是训练数据的分发在一个节点上,要把训练数据分到不同的机器上,严重影响了并发的训练速度。
优势,计算节点只需要调用join()函数等待任务,客户端随时提交数据就可以训练。
劣势,训练数据分发在一个节点上,要分发给不同工作节点,严重影响并发训练速度。
图间复制(between-graph replication)
每一个工作节点创建一个图,训练参数保存在参数服务器,数据不分发,各个工作节点独立计算,计算完成把要更新参数告诉参数服务器,参数服务器更新参数。
即: between-graph模式下,训练的参数保存在参数服务器,数据不用分发,数据分片的保存在各个计算节点,各个计算节点自己算自己的,算完后把要更新的参数告诉参数服务器,参数服务器更新参数。这种模式的优点是不用进行训练数据的分发,尤其数据量在TB级的时候,节省了大量的时间,所以大数据深度学习推荐使用between-graph模式。
优势,不需要数据分发,各个工作节点都创建图和读取数据训练。
劣势,工作节点既是图创建者又是计算任务执行者,某个工作节点宕机影响集群工作。大数据相关深度学习推荐使用图间模式。
模型并行
论文: 《TensorFlow:Large-Scale Machine Learning on Heterogeneous Distributed Systems》
切分模型,模型不同部分执行在不同设备上,一个批次样本可以在不同设备同时执行。TensorFlow尽量让相邻计算在同一台设备上完成节省网络开销。
模型并行、数据并行,TensorFlow中,计算可以分离,参数可以分离。可以在每个设备上分配计算节点,让对应参数也在该设备上,计算参数放一起。

分布式训练案例
import tensorflow as tf
import numpy as np
# Configuration of cluster
ps_hosts = [ "xx.xxx.xx.xxxx:oooo", "xx.xxx.xx.xxxx:oooo" ]
worker_hosts = [ "xx.xxx.xx.xxxx:oooo", "xx.xxx.xx.xxxx:oooo", "xx.xxx.xx.xxxx:oooo" ]
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job")
FLAGS = tf.app.flags.FLAGS
def main(_):
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):
x_data = tf.placeholder(tf.float32, [100])
y_data = tf.placeholder(tf.float32, [100])
W = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
loss = tf.reduce_mean(tf.square(y - y_data))
global_step = tf.Variable(0, name="global_step", trainable=False)
optimizer = tf.train.GradientDescentOptimizer(0.1)
train_op = optimizer.minimize(loss, global_step=global_step)
tf.summary.scalar('cost', loss)
summary_op = tf.summary.merge_all()
init_op = tf.global_variables_initializer()
# The StopAtStepHook handles stopping after running given steps.
hooks = [ tf.train.StopAtStepHook(last_step=1000000)]
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf.train.MonitoredTrainingSession(master="grpc://" + worker_hosts[FLAGS.task_index],
is_chief=(FLAGS.task_index==0), # 我们制定task_index为0的任务为主任务,用于负责变量初始化、做checkpoint、保存summary和复原
checkpoint_dir="/tmp/tf_train_logs",
save_checkpoint_secs=None,
hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# Run a training step asynchronously.
# See `tf.train.SyncReplicasOptimizer` for additional details on how to
# perform *synchronous* training.
# mon_sess.run handles AbortedError in case of preempted PS.
train_x = np.random.rand(100).astype(np.float32)
train_y = train_x * 0.1 + 0.3
_, step, loss_v, weight, biase = mon_sess.run([train_op, global_step, loss, W, b], feed_dict={x_data: train_x, y_data: train_y})
if step % 100 == 0:
print "step: %d, weight: %f, biase: %f, loss: %f" %(step, weight, biase, loss_v)
print "Optimization finished."
if __name__ == "__main__":
tf.app.run()代码中,tf.train.replica_device_setter()会根据job名,将with内的Variable op放到ps tasks,将其他计算op放到worker tasks。默认分配策略是轮询。
在属于集群的一台机器中执行上面的代码,屏幕会开始输出每轮迭代的训练参数和损失
python train.py --task_index=0在另一台机器上执行下面你的代码,再启动一个任务,会看到屏幕开始输出每轮迭代的训练参数和损失,注意,step不再是从0开始,而是在启动时刻上一个启动任务的step后继续。此时观察两个任务,会发现他们同时在对同一参数进行更新。
python train.py --task_index=21. tf.train.Supervisor
example.py
# -*- coding:utf-8 -*-
'''
Distributed Tensorflow 1.2.0 example of using data parallelism and share model parameters.
Trains a simple sigmoid neural network on mnist for 20 epochs on three machines using one parameter server.
Change the hardcoded host urls below with your own hosts.
Run like this:
pc-01$ python example.py --job_name="ps" --task_index=0
pc-02$ python example.py --job_name="worker" --task_index=0
pc-03$ python example.py --job_name="worker" --task_index=1
pc-04$ python example.py --job_name="worker" --task_index=2
More details here: ischlag.github.io
'''
from __future__ import print_function
import tensorflow as tf
import sys
import time
# cluster specification
parameter_servers = ["10.130.0.85:2222"]
workers = ["10.130.0.83:2222",
"10.130.0.75:2222"]
cluster = tf.train.ClusterSpec({"ps": parameter_servers, "worker": workers})
# input flags
tf.app.flags.DEFINE_string("job_name", "", "Either 'ps' or 'worker'")
tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job")
FLAGS = tf.app.flags.FLAGS
# start a server for a specific task
server = tf.train.Server(
cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
# config
batch_size = 100
learning_rate = 0.0005
training_epochs = 20
logs_path = "/tmp/mnist/1"
# load mnist data set
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
if FLAGS.job_name == "ps":
server.join()
elif FLAGS.job_name == "worker":
# 通过tf.train.replica_device_setter函数来指定执行每一个运算的设备
# tf.train.replica_device_setter函数会自动将所有的参数分配到参数服务器上,而
# 计算分配到当前的计算服务器上
# Between-graph replication
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):
# count the number of updates
global_step = tf.get_variable(
'global_step',
[],
initializer=tf.constant_initializer(0),
trainable=False)
# input images
with tf.name_scope('input'):
# None -> batch size can be any size, 784 -> flattened mnist image
x = tf.placeholder(tf.float32, shape=[None, 784], name="x-input")
# target 10 output classes
y_ = tf.placeholder(tf.float32, shape=[None, 10], name="y-input")
# model parameters will change during training so we use tf.Variable
tf.set_random_seed(1)
with tf.name_scope("weights"):
W1 = tf.Variable(tf.random_normal([784, 100]))
W2 = tf.Variable(tf.random_normal([100, 10]))
# bias
with tf.name_scope("biases"):
b1 = tf.Variable(tf.zeros([100]))
b2 = tf.Variable(tf.zeros([10]))
# implement model
with tf.name_scope("softmax"):
# y is our prediction
z2 = tf.add(tf.matmul(x, W1), b1)
a2 = tf.nn.sigmoid(z2)
z3 = tf.add(tf.matmul(a2, W2), b2)
y = tf.nn.softmax(z3)
# specify cost function
with tf.name_scope('cross_entropy'):
# this is our cost
cross_entropy = tf.reduce_mean(
-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
# specify optimizer
with tf.name_scope('train'):
# optimizer is an "operation" which we can execute in a session
grad_op = tf.train.GradientDescentOptimizer(learning_rate)
'''
rep_op = tf.train.SyncReplicasOptimizer(
grad_op,
replicas_to_aggregate=len(workers),
replica_id=FLAGS.task_index,
total_num_replicas=len(workers),
use_locking=True)
train_op = rep_op.minimize(cross_entropy, global_step=global_step)
'''
train_op = grad_op.minimize(cross_entropy, global_step=global_step)
'''
init_token_op = rep_op.get_init_tokens_op()
chief_queue_runner = rep_op.get_chief_queue_runner()
'''
with tf.name_scope('Accuracy'):
# accuracy
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# create a summary for our cost and accuracy
tf.summary.scalar("cost", cross_entropy)
tf.summary.scalar("accuracy", accuracy)
# merge all summaries into a single "operation" which we can execute in a session
summary_op = tf.summary.merge_all()
# 定义用于保存模型的saver
saver = tf.train.Saver()
# init parms
init_op = tf.global_variables_initializer()
print("Variables initialized ...")
sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0), # 定义当前计算服务器是否为主计算服务器,只用主计算服务器会保存模型以及输出日志
logdir="/tmp/train_logs", # 指定保存模型和输出日志的地址
global_step=global_step, # 指定当前迭代的轮数,这个会用于生成保存模型文件的文件名
init_op=init_op, # 指定初始化操作
summary_op=summary_op, # 指定日志生成操作
saver=saver, # 指定用于保存模型的saver
save_model_secs=60, # 指定保存模型的时间间隔
save_summaries_secs=60 # 指定日志输出的时间间隔
)
begin_time = time.time()
frequency = 100
# 通过设置log_device_placement选项来记录operations 和 Tensor 被指派到哪个设备上运行
# 为了避免手动指定的设备不存在这种情况, 你可以在创建的 session 里把参数 allow_soft_placement
# 设置为 True, 这样 tensorFlow 会自动选择一个存在并且支持的设备来运行 operation.
# device_filters:硬件过滤器,如果被设置的话,会话会忽略掉所有不匹配过滤器的硬件。
config = tf.ConfigProto(
allow_soft_placement=True,
log_device_placement=False,
device_filters=["/job:ps", "/job:worker/task:%d" % FLAGS.task_index]
)
with sv.prepare_or_wait_for_session(server.target, config=config) as sess:
'''
# is chief
if FLAGS.task_index == 0:
sv.start_queue_runners(sess, [chief_queue_runner])
sess.run(init_token_op)
'''
# create log writer object (this will log on every machine)
writer = tf.summary.FileWriter(logs_path, graph=tf.get_default_graph())
# perform training cycles
start_time = time.time()
for epoch in range(training_epochs):
# number of batches in one epoch
batch_count = int(mnist.train.num_examples / batch_size)
count = 0
for i in range(batch_count):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# perform the operations we defined earlier on batch
_, cost, summary, step = sess.run(
[train_op, cross_entropy, summary_op, global_step],
feed_dict={x: batch_x, y_: batch_y})
writer.add_summary(summary, step)
count += 1
if count % frequency == 0 or i + 1 == batch_count:
elapsed_time = time.time() - start_time
start_time = time.time()
print("Step: %d," % (step + 1),
" Epoch: %2d," % (epoch + 1),
" Batch: %3d of %3d," % (i + 1, batch_count),
" Cost: %.4f," % cost,
" AvgTime: %3.2fms" % float(elapsed_time * 1000 / frequency))
count = 0
print("Test-Accuracy: %2.2f" % sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
print("Total Time: %3.2fs" % float(time.time() - begin_time))
print("Final Cost: %.4f" % cost)
sv.stop()
print("done")2. MonitoredTrainingSession
trainer.py
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
FLAGS = None
# 定义一个函数,用于初始化所有的权值 W
def weight_variable(shape):
init = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(init)
# 定义一个函数,用于初始化所有的偏置项 b
def bias_variable(shape):
init = tf.constant(0.1, shape=shape)
return tf.Variable(init)
# 定义一个函数,用于构建卷积层
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding="SAME")
# 定义一个函数,用于构建池化层
def max_pool(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
def main(_):
ps_hosts = FLAGS.ps_hosts.split(",")
worker_hosts = FLAGS.worker_hosts.split(",")
# Create a cluster from the parameter server and worker hosts.
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
# Create and start a server for the local task.
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index,
start=True)
# # 参数服务器只需要管理TensorFlow中的变量,不需要执行训练的过程。
# server.join()会一直停在这条语句上
if FLAGS.job_name == "ps":
server.join()
elif FLAGS.job_name == "worker":
# Import data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# 通过tf.train.replica_device_setter函数来指定执行每一个运算的设备
# tf.train.replica_device_setter函数会自动将所有的参数分配到参数服务器上,而
# 计算分配到当前的计算服务器上
# tf.train.replica_device_setter()会根据job名,将with内的Variable op放到ps tasks,
# 将其他计算op放到worker tasks。默认分配策略是轮询。
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):
# 训练集的Image
x = tf.placeholder(tf.float32, [None, 784])
# 训练集的Label
y_actual = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
# 重构 input,因为卷积层和池化层要求x为 1行4列的矩阵,而输入input为1行2列
# [训练集数量, 图像高, 图像宽, 通道数量]
x_image = tf.reshape(x, [-1, 28, 28, 1])
# 构建网络
# 第一层卷积, [卷积核高, 卷积核宽, 输入通道数, 输出通道数]
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # 第一个卷积层
h_pool1 = max_pool(h_conv1) # 第一个池化层,[-1, 14, 14, 32]
# 第二层卷积
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) # 第二层卷积层
h_pool2 = max_pool(h_conv2) # 第二层池化层,[-1, 7, 7, 64]
# 第一层全连接层
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64]) # reshape成向量
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) # 全连接层
# dropout
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) # dropout
# 第二层全连接,分类 softmax
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_predict = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) # softmax, [-1, 10]
# 最优化求解
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_actual * tf.log(y_predict), 1)) # 交叉熵,没有平均值
global_step = tf.train.get_or_create_global_step()
optimizer = tf.train.GradientDescentOptimizer(FLAGS.learning_rate)
train_op = optimizer.minimize(cross_entropy, global_step=global_step)
cross_prediction = tf.equal(tf.argmax(y_predict, 1), tf.argmax(y_actual, 1))
accuracy = tf.reduce_mean(tf.cast(cross_prediction, tf.float32)) # 精度计算
# tensorboard
tf.summary.scalar('cost', cross_entropy)
tf.summary.scalar("accuracy", accuracy)
summary_op = tf.summary.merge_all()
# The StopAtStepHook handles stopping after running given steps.
hooks = [tf.train.StopAtStepHook(last_step=400)]
# # 通过设置log_device_placement选项来记录operations 和 Tensor 被指派到哪个设备上运行
## 为了避免手动指定的设备不存在这种情况, 你可以在创建的 session 里把参数 allow_soft_placement
## 设置为 True, 这样 tensorFlow 会自动选择一个存在并且支持的设备来运行 operation.
## device_filters:硬件过滤器,如果被设置的话,会话会忽略掉所有不匹配过滤器的硬件。
# config = tf.ConfigProto(
# allow_soft_placement=True,
# log_device_placement=False,
# device_filters=["/job:ps", "/job:worker/task:%d" % FLAGS.task_index]
# )
# 通过设置log_device_placement选项来记录operations 和 Tensor 被指派到哪个设备上运行
config = tf.ConfigProto(
allow_soft_placement=True,
log_device_placement=False,
device_filters=["/job:ps", "/job:worker/task:%d" % FLAGS.task_index]
)
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
# master="grpc://" + worker_hosts[FLAGS.task_index]
# if_chief: 制定task_index为0的任务为主任务,用于负责变量初始化、做checkpoint、保存summary和复原
# 定义计算服务器需要运行的操作。在所有的计算服务器中有一个是主计算服务器。
# 它除了负责计算反向传播的结果,它还负责输出日志和保存模型
with tf.train.MonitoredTrainingSession(master=server.target,
config=config,
is_chief=(FLAGS.task_index == 0),
hooks=hooks,
checkpoint_dir=FLAGS.checkpoint_dir) as mon_sess:
while not mon_sess.should_stop():
# Run a training step asynchronously.
# See `tf.train.SyncReplicasOptimizer` for additional details on how to
# perform *synchronous* training.
# mon_sess.run handles AbortedError in case of preempted PS.
batch_x, batch_y = mnist.train.next_batch(64)
step, _ = mon_sess.run([global_step, train_op], feed_dict={
x: batch_x,
y_actual: batch_y,
keep_prob: 0.8})
if step > 0 and step % 10 == 0:
loss, acc = mon_sess.run([cross_entropy, accuracy], feed_dict={
x: batch_x,
y_actual: batch_y,
keep_prob: 1.0})
print("step: %d, loss: %f, acc: %f" % (step, loss, acc))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.register("type", "bool", lambda v: v.lower() == "true")
# Flags for defining the tf.train.ClusterSpec
parser.add_argument(
"--ps_hosts",
type=str,
default="",
help="Comma-separated list of hostname:port pairs"
)
parser.add_argument(
"--worker_hosts",
type=str,
default="",
help="Comma-separated list of hostname:port pairs"
)
parser.add_argument(
"--job_name",
type=str,
default="",
help="One of 'ps', 'worker'"
)
# Flags for defining the tf.train.Server
parser.add_argument(
"--task_index",
type=int,
default=0,
help="Index of task within the job"
)
parser.add_argument(
"--checkpoint_dir",
type=str,
default=None,
help="path to a directory where to restore variables."
)
parser.add_argument(
"--learning_rate",
type=float,
default=0.001,
help="learning rate"
)
FLAGS, _ = parser.parse_known_args()
tf.app.run(main=main)command:
python trainer.py \
--ps_hosts=192.168.0.203:2222 \
--worker_hosts=192.168.0.205:2222,192.168.0.206:2222 \
--job_name=ps \
--task_index=0
python trainer.py \
--ps_hosts=192.168.0.203:2222 \
--worker_hosts=192.168.0.205:2222,192.168.0.206:2222 \
--job_name=worker \
--task_index=0
python trainer.py \
--ps_hosts=192.168.0.203:2222 \
--worker_hosts=192.168.0.205:2222,192.168.0.206:2222 \
--job_name=worker --task_index=13. Estimator API
cluster = {'ps': ['10.134.96.44:2222', '10.134.96.184:2222'],
'worker': ['10.134.96.37:2222', '10.134.96.145:2222']}
os.environ['TF_CONFIG'] = json.dumps(
{'cluster': cluster,
'task': {'type': 'worker', 'index': 0}})思考
分布式TensorFlow与Spark对比:
- 分布式的级别不同:TensorFlow的Tensor、Variable和Op不是分布式的,分布式执行的是subgraph. Spark的op和变量都是构建在RDD上,RDD本身是分布式的。
- 异步训练:TensorFlow支持同步和异步的分布式训练;Spark原生的API只支持同步训练
- 分布式存储:Spark在底层封装好了worker和分布式数据之间的关系;TensorFlow需要自行维护。
- Parameter Server:TensorFlow支持,Spark暂不支持。
- TF分布式部署起来还是比较繁琐的,需要定义好每个任务的ip:port,手工启动每个task,不提供一个界面可以对集群进行维护。