hbase 的Rowkey设计方案
1.1 hbase的概述
HBase由于其存储和读写的高性能,在OLAP即时分析中越来越发挥重要的作用。作为Nosql数据库的一员,HBase查询只能通过其Rowkey来查询(Rowkey用来表示唯一一行记录),Rowkey设计的优劣直接影响读写性能。
由于HBase是通过Rowkey查询的,一般Rowkey上都会存一些比较关键的检索信息,我们需要提前想好数据具体需要如何查询,根据查询方式进行数据存储格式的设计,要避免做全表扫描,因为效率特别低。
此外易观方舟也使用HBase做用户画像的标签存储方案,存储每个app的用户的人口学属性和商业属性等标签信息。
HBase中设计有MemStore和BlockCache,分别对应列族/Store级别的写入缓存,和RegionServer级别的读取缓存。如果RowKey过长,缓存中存储数据的密度就会降低,影响数据落地或查询效率。
1.2 hbase的设计原则以及解决方法
1.3 预分区
1.3.1 什么是预分区
HBase表在刚刚被创建时,只有1个分区(region),当一个region过大(达到hbase.hregion.max.filesize属性中定义的阈值,默认10GB)时,
表将会进行split,分裂为2个分区。表在进行split的时候,会耗费大量的资源,频繁的分区对HBase的性能有巨大的影响。
HBase提供了预分区功能,即用户可以在创建表的时候对表按照一定的规则创建分区。
1.3.2 预分区的目的
减少由于region split带来的资源消耗。从而提高HBase的性能。
避免数据倾斜,热点等问题
- hbase的热点问题
1.4 hbase的热点
默认情况下,当我们通过hbaseAdmin指定TableDescriptor来创建一张表时,只有一个region正处于混沌时期,start-end key无边界,可谓海纳百川。所有的rowkey都写入到这个region里,然后数据越来越多,region的size越来越大时,大到一定的阀值,hbase就会将region一分为二,成为2个region,这个过程称为分裂(region-split)。
如果我们就这样默认建表,表里不断的put数据,更严重的是我们的rowkey还是顺序增大的,是比较可怕的。存在的缺点比较明显:
首先是热点写,我们总是会往最大的start-key所在的region写东西,因为我们的rowkey总是会比之前的大,并且hbase的是按升序方式排序的。所以写操作总是被定位到无上界的那个region中。
其次,由于写热点,我们总是往最大start-key的region写记录,之前分裂出来的region不会再被写数据,有点被打进冷宫的赶脚,它们都处于半满状态,这样的分布也是不利的。
如果在写频率高的场景下,数据增长快,split的次数也会增多,由于split是比较耗时耗资源的,所以我们并不希望这种事情经常发生。
1.5 hbase的热点的解决方法
预分区与随机散列二者结合起来,是比较完美的。
预分区一开始就预建好了一部分region,这些region都维护着自己的start-end keys,在配合上随机散列,写数据能均衡的命中这些预建的region,就能解决上面的那些缺点,大大提供性能。
https://www.cnblogs.com/cxzdy/p/5521308.html rowkey设计
https://blog.csdn.net/w1014074794/article/details/73140489 rowkey的设计
1.5.1 方法一:hash散列预分区
hash就是rowkey前面由一串随机字符串组成,随机字符串生成方式可以由SHA或者MD5方式生成,只要region所管理的start-end keys范围比较随机,那么就可以解决写热点问题。
1.rowkey的生成策略:
rowkey原本是自增长的long型,可以将rowkey转为hash再转为bytes,加上本身id转为bytes。rowkey=hash(id)+id;这样就生成随便的rowkey。
2.预分区:对于这种方式的rowkey设计,如何去进行预分区呢?
2.1取样,先随机生成一定数量的rowkey,将取样数据按升序排序放到一个集合里。
2.2根据预分区的region个数,对整个集合平均分割,即是相关的splitkeys。
2.3 HBaseAdmin.createTable(HTableDescriptor tableDescriptor,byte[][] splitkeys)可以指定预分区的splitkey,即指定region间的rowkey临界值。
3. 以上就是按照hash方式,预建好分区,以后再插入数据的时候,也是按照此rowkeyGenerator的方式生成rowkey
public interface SplitKeysCalculator {
}
public interface RowKeyGenerator {
byte [] nextId();
}
public class HashRowKeyGenerator implements RowKeyGenerator {
private long currentId = 1;
private long currentTime = System.currentTimeMillis();
private Random random = new Random();
public byte[] nextId() {
try {
currentTime += random.nextInt(1000);
byte[] lowT = Bytes.copy(Bytes.toBytes(currentTime), 4, 4);
byte[] lowU = Bytes.copy(Bytes.toBytes(currentId), 4, 4);
return Bytes.add(MD5Hash.getMD5AsHex(Bytes.add(lowU, lowT)).substring(0, 8).getBytes(),
Bytes.toBytes(currentId));
} finally {
currentId++;
}
}
}
//
public class HashMethodCreatePartition implements SplitKeysCalculator {
//随机取机数目
private int baseRecord;
//rowkey生成器
private RowKeyGenerator rkGen;
//取样时,由取样数目及region数相除所得的数量.
private int splitKeysBase;
//splitkeys个数
private int splitKeysNumber;
//由抽样计算出来的splitkeys结果
private byte[][] splitKeys;
public HashMethodCreatePartition(int baseRecord, int prepareRegions) {
this.baseRecord = baseRecord;
//实例化rowkey生成器
rkGen = new HashRowKeyGenerator();
splitKeysNumber = prepareRegions - 1;
splitKeysBase = baseRecord / prepareRegions;
}
public byte[][] calcSplitKeys() {
splitKeys = new byte[splitKeysNumber][];
//使用treeset保存抽样数据,已排序过
TreeSet rows = new TreeSet(Bytes.BYTES_COMPARATOR);
for (int i = 0; i < baseRecord; i++) {
rows.add(rkGen.nextId());//关键步骤
}
int pointer = 0;
Iterator rowKeyIter = rows.iterator();
int index = 0;
while (rowKeyIter.hasNext()) {
byte[] tempRow = rowKeyIter.next();
rowKeyIter.remove();
if ((pointer != 0) && (pointer % splitKeysBase == 0)) {
if (index < splitKeysNumber) {
splitKeys[index] = tempRow;
index ++;
}
}
pointer ++;
}
rows.clear();
rows = null;
return splitKeys;
}
//测试类:
public class TestHashPartition {
private final static Logger log= Logger.getLogger(String.valueOf(TestHashPartition.class));
public static void main(String args[])throws Exception{
HashMethodCreatePartition worker = new HashMethodCreatePartition(1000000,10);
byte [][] splitKeys = worker.calcSplitKeys();
String tableName="hash_split_table";//用户画像hbase中的表
TableName tn=TableName.valueOf(Constants.HBASE_TABLE_NAME.value);
String familyArray[]={"mboth"};//定义列族
initUserTable(tableName,familyArray,true,splitKeys);
}
public static void initUserTable(String tableName,String familyArray[],boolean partionFlag,byte[][] splitKeys){
List list=new ArrayList();
try {
Admin hadmin = HbaseConnectionUtils.getInstance().getConnection().getAdmin();
TableName tm = TableName.valueOf(tableName);
if (!hadmin.tableExists(TableName.valueOf(tableName))) {
HTableDescriptor hTableDescriptor = new HTableDescriptor(tm);
for(String colFa:familyArray){
HColumnDescriptor family = new HColumnDescriptor(colFa);
family.setMaxVersions(1);
hTableDescriptor.addFamily(family);
}
if(partionFlag){
hadmin.createTable(hTableDescriptor, splitKeys);
}
else {
hadmin.createTable(hTableDescriptor);//不分区
}
hadmin.close();
}
else {
log.info("................新建表:"+tableName+"已存在..........................");
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
log.info("................................................create hbase table "+tableName+" successful..........");
}
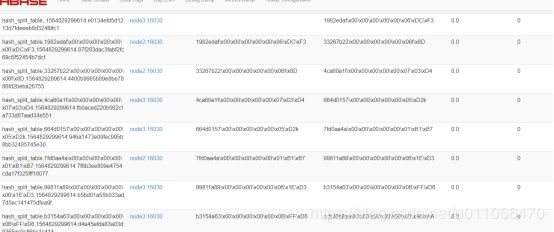
} #结果:
1.5.2 方法二:整数取模预分区
rowkey:将ID取模后,然后拼上ID整体作为rowkey,rowkey=(id)%regionNum +id;
分区:用长整数作为分区号,每个region管理着相应的区域数据,splitkeys也非常简单,直接是分区号即可。
public interface RowKeyGenerator {
byte [] nextId();
}
public interface SplitKeysCalculator {
}
public class ModPartitionRowKeyManager implements RowKeyGenerator, SplitKeysCalculator {
public static final int DEFAULT_PARTITION_AMOUNT = 20;
private long currentId = 1;
private int partition = DEFAULT_PARTITION_AMOUNT;
public void setPartition(int partition) {
this.partition = partition;
}
public byte[] nextId() {
try {
long partitionId = currentId % partition;
return Bytes.add(Bytes.toBytes(partitionId+""),
Bytes.toBytes(currentId+""));
} finally {
currentId++;
}
}
public byte[][] calcSplitKeys() {
byte[][] splitKeys = new byte[partition - 1][];
for(int i = 1; i < partition ; i ++) {
splitKeys[i-1] = Bytes.toBytes((long)i);
}
return splitKeys;
}
}
//测试
public class TestMod {
private final static Logger log= Logger.getLogger(String.valueOf(TestMod.class));
public static void main(String args[])throws Exception{
ModPartitionRowKeyManager rkManager = new ModPartitionRowKeyManager();
//只预建10个分区
rkManager.setPartition(10);
byte [][] splitKeys = rkManager.calcSplitKeys();
String tableName="hash_split_table2";//用户画像hbase中的表
TableName tn=TableName.valueOf(Constants.HBASE_TABLE_NAME.value);
String familyArray[]={"mboth2"};//定义列族
initUserTable(tableName,familyArray,true,splitKeys);
//插入1亿条记录,看数据分布
List listp = new ArrayList();
for(int i = 0; i < 10000; i ++) {
Put put = new Put(rkManager.nextId());
put.addColumn("mboth2".getBytes(), "email".getBytes(), Bytes.toBytes("[email protected]"));
listp.add(put);
}
HbaseConnectionUtils.getInstance().getTable("hash_split_table2").put(listp);
}
public static void initUserTable(String tableName,String familyArray[],boolean partionFlag,byte[][] splitKeys){
List list=new ArrayList();
try {
Admin hadmin = HbaseConnectionUtils.getInstance().getConnection().getAdmin();
TableName tm = TableName.valueOf(tableName);
if (!hadmin.tableExists(TableName.valueOf(tableName))) {
HTableDescriptor hTableDescriptor = new HTableDescriptor(tm);
for(String colFa:familyArray){
HColumnDescriptor family = new HColumnDescriptor(colFa);
family.setMaxVersions(1);
hTableDescriptor.addFamily(family);
}
if(partionFlag){
hadmin.createTable(hTableDescriptor, splitKeys);
}
else {
hadmin.createTable(hTableDescriptor);//不分区
}
hadmin.close();
}
else {
log.info("................新建表:"+tableName+"已存在..........................");
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
log.info("................................................create hbase table "+tableName+" successful..........");
}
} #结果:

1.5.3 方法三:url进行md5后预分区
Rowkey的生成策略为=url的md5值;
Rowkey=md5(url)
/**
* 当list的size小于baseReocrd,分区为n,最终的结果可能要小于n
* 如list的size为6,baseReord=100,分区20,理论每个分区5个,所以最终结果为2个分区
所以要尽量设置baseReocrd,regionNum,要合理
#代码:
public class CreateHbaseTable {
private final static Logger log= Logger.getLogger(String.valueOf(HbaseUtil.class));
public static void main(String args[]){
String tableName="hash_split_table3";//用户画像hbase中的表hash_split_table3 hb_user_profile_t
TableName tn=TableName.valueOf(Constants.HBASE_TABLE_NAME.value);
String familyArray[]={"user"};//定义列族
initUserTable(tableName,familyArray,true);
Table table= HbaseConnectionUtils.getInstance().getTable("hash_split_table3");
putTable(table, familyArray);
}
/**
* 当list的size小于baseReocrd,分区n,最终的结果可能要小于n
* 如list的size为6,baseReord=100,分区20,理论每个分区5个,所以最终结果为2个分区
* @param tableName
* @param familyArray
* @param partionFlag
*/
public static void initUserTable(String tableName,String familyArray[],boolean partionFlag){
List
list.add("http://guangzhou.anjuke.com/community/view/756975");
list.add("http://chengdu.anjuke.com/community/view/141695");
list.add("http://beijing.anjuke.com/community/view/80542");
list.add("http://guangzhou.anjuke.com/community/view/111235");
list.add("http://lijingfu.fang.com");
list.add("http://tianjin.anjuke.com/community/view/202811");
try {
Admin hadmin = HbaseConnectionUtils.getInstance().getConnection().getAdmin();
TableName tm = TableName.valueOf(tableName);
if (!hadmin.tableExists(TableName.valueOf(tableName))) {
HTableDescriptor hTableDescriptor = new HTableDescriptor(tm);
for(String colFa:familyArray){
HColumnDescriptor family = new HColumnDescriptor(colFa);
family.setMaxVersions(1);
hTableDescriptor.addFamily(family);
}
if(partionFlag){
hadmin.createTable(hTableDescriptor,HbaseUtil.calcSplitKeys(list,100,20));
}
else {
hadmin.createTable(hTableDescriptor);//不分区
}
hadmin.close();
}
else {
log.info("................新建表:"+tableName+"已存在..........................");
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
log.info("................................................create hbase table "+tableName+" successful..........");
}
public static void putTable(Table hTable, String familyArray[]) {
List
List
dataList.add("http://guangzhou.anjuke.com/community/view/112825");
dataList.add("http://lijingfu.fang.com/sdfsd/234");
for (String key:dataList) {
String rowKey= HbaseUtil.createMd5(key);
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(familyArray[0].getBytes(), "email".getBytes(),
Bytes.toBytes("ddd"));
listp.add(put);
}
try {
hTable.put(listp);
} catch (IOException e) {
e.printStackTrace();
}
listp.clear();
log.info("添加数据成功..........................");
}
}
#splitkeys
/**
* 预分区,根据预分区的region个数,对整个集合平均分割,即是相关的splitkeys。
* @param rkGen
* @param baseRecord
* @param prepareRegions
* @return
*/
public static byte[][] calcSplitKeys(List
int splitKeysNumber = prepareRegions - 1;
int splitKeysBase = baseRecord / prepareRegions;
byte[][] splitKeys = new byte[splitKeysNumber][];
TreeSet<byte[]> rows = new TreeSet<byte[]>(Bytes.BYTES_COMPARATOR);
for (String rk : rkGen) {
rows.add(createMd5(rk).getBytes());
}
int pointer = 0;
Iterator<byte[]> rowKeyIter = rows.iterator();
int index = 0;
while (rowKeyIter.hasNext()) {
byte[] tempRow = rowKeyIter.next();
if ((pointer != 0) && (pointer % splitKeysBase == 0)) {
if (index < splitKeysNumber) {
splitKeys[index] = tempRow;
index ++;
}
}
rowKeyIter.remove();
pointer ++;
}
rows.clear();
rows = null;
//防止分区多,数据少,有些分区没有数据
byte[][] splitKeysRegion = new byte[index][];
for(int m=0;m
byte[] tempRow=splitKeys[m];
if(tempRow==null){
continue;
}
splitKeysRegion[m]=tempRow;
}
return splitKeysRegion;
}
/**
* md5随机散列,通过SHA或者md5生成随机散列的字符串。
* @param plainText
* @return
*/
public static String createMd5(String plainText) {
byte[] secretBytes = null;
try {
secretBytes = MessageDigest.getInstance("md5").digest(
plainText.getBytes());
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("没有md5这个算法!");
}
String md5code = new BigInteger(1, secretBytes).toString(16);// 16进制数字
// 如果生成数字未满32位,需要前面补0
for (int i = 0; i < 32 - md5code.length(); i++) {
md5code = "0" + md5code;
}
return md5code;
}
#结果:


1.6 通过rowkey查看所属的region
public static void getRegionInfo(){
RegionLocator r= null;
try {
r = connection.getRegionLocator(TableName.valueOf("hash_split_table3"));
HRegionLocation location = r.getRegionLocation(Bytes.toBytes("00582ad1ea63c52490c1c8fd135b67"));
HRegionInfo rg = location.getRegionInfo();
String regionname = Bytes.toString(rg.getRegionName());
String strkey = Bytes.toString(rg.getStartKey());
String endkey = Bytes.toString(rg.getEndKey());
System.out.println(regionname);
System.out.println("START:"+strkey);
System.out.println("END:"+endkey);
} catch (IOException e) {
e.printStackTrace();
}
}
#结果:
