Spark集群安装部署
1.安装包下载
scala-2.10.5.tgz
spark-1.3.0-bin-hadoop2.4
2.安装Scala(Master节点)
2.1 解压文件
tar -zxvf scala-2.10.5.tgz
2.2 配置环境变量
#vi/etc/profile
#SCALA VARIABLES START
export SCALA_HOME=/home/was/scala-2.10.5
export PATH=$PATH:$SCALA_HOME/bin
#SCALA VARIABLES END
$ source /etc/profile
$ scala -version
Scala code runner version 2.10.5 -- Copyright 2002-2013, LAMP/EPFL
2.3验证Scala
$ scala
Welcome to Scala version 2.10.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_51).
Type in expressions to have them evaluated.
Type :help for more information.
scala> 9*9
res0: Int = 81
3. 安装Spark
Master、Slave1、Slave2 这三台机器上均需要安装 Spark。
首先在 Master 上安装 Spark,具体步骤如下
第一步:把 Master 上的 Spark 解压:我们直接解压到当前目录下:
[root@Master was]#tar -zxvf spark-1.3.0-bin-hadoop2.4.tar
第二步:配置环境变量
进入配置文件
使用 vim 打开 spark-env.sh:
在配置文件中加入“SPARK_HOME”并把 spark 的 bin 目录加到 PATH 中:

配置后保存退出,然后使配置生效:
第三步:配置 Spark
进入 Spark 的 conf 目录:

把 spark-env.sh.template 拷贝到 spark-env.sh:
使用 vim 打开 spark-env.sh:
在配置文件中添加如下配置信息:
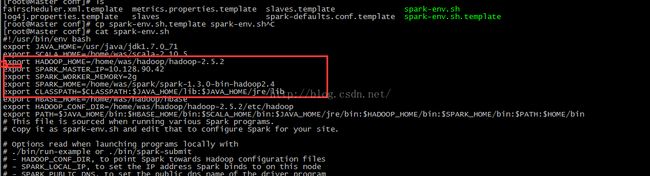
其中:
JAVA_HOME:指定的是 Java 的安装目录;
SCALA_HOME:指定的是 Scala 的安装目录;
SPARK_MASTER_IP:指定的是 Spark 集群的 Master 节点的 IP 地址;
SPARK_WORKER_MEMOERY:指定的 Worker 节点能够最大分配给 Excutors 的内存大小,
因为我们的三台机器配置都是 2g,为了最充分的使用内存,这里设置为了 2g;
HADOOP_CONF_DIR:指定的是我们原来的 Hadoop 集群的配置文件的目录;
保存退出。
接下来配置 Spark 的 conf 下的 slaves 文件,把 Worker 节点都添加进去:

可以看出我们把三台机器都设置为了 Worker 节点,也就是我们的主节点即是 Master 又是
Worker 节点。
保存退出。
上述就是 Master 上的 Spark 的安装。
第四步:Slave1 和 Slave2 采用和 Master 完全一样的 Spark 安装配置,在此不再赘述。
第四步启动spark集群
在 Hadoop 集群成功启动的基础上,启动 Spark 集群需要使用 Spark 的 sbin 目录下
“start-all.sh”:
读者必须注意的是此时必须写成“ ./start-all.sh”来表明是当前目录下的“ start-all.sh”,
因为我们在配置 Hadoop 的 bin 目录中也有一个“start-all.sh”文件!
此时使用 jps 发现我们在主节点正如预期一样出现了“Master”和“Worker”两个新进程!
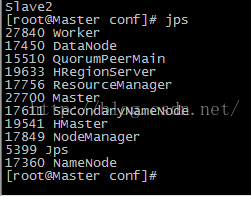
此时的 Slave1 和 Slave2 会出现新的进程“Worker”:
此时,我们可以进入 Spark 集群的 Web 页面,访问“http://Master:8080”: 如下所示:
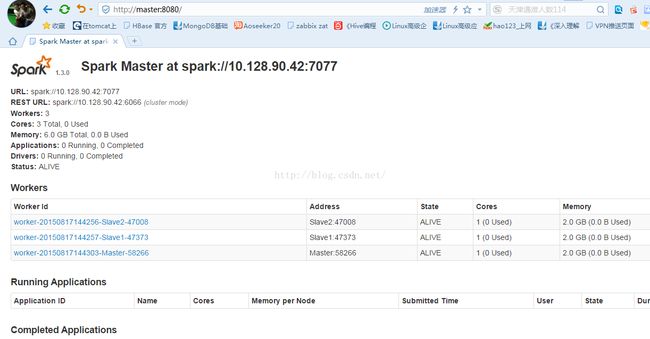
从页面上我们可以看到我们有三个 Worker 节点及这三个节点的信息。
此时,我们进入 Spark 的 bin 目录,使用“spark-shell”控制台:
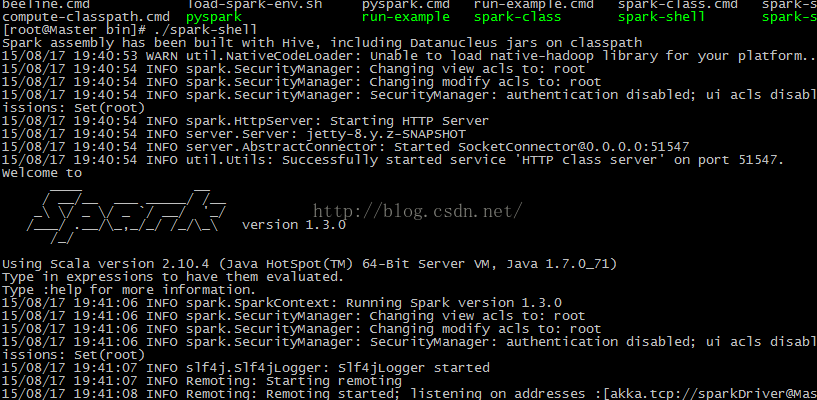

此 时 我 们 进 入 了 Spark 的 shell 世 界 , 根 据 输 出 的 提 示 信 息 , 我 们 可 以 通 过
“http://Master:4040” 从 Web 的角度看一下 SparkUI 的情况,如下图所示:
至此,我们 的 Spark 集群搭建成功