Linux内核剖析 之 内核同步
主要内容
1、内核请求何时以交错(interleave)的方式执行以及交错程度如何。
2、内核所实现的基本同步机制。
3、通常情况下如何使用内核提供的同步机制。
内核如何为不同的请求服务
哪些服务?
====>>>
为了更好地理解内核是如何执行的,我们把内核看做必须满足两种请求的侍者:一种请求来自顾客,另一种请求来自数量有限的几个不同的老板。对于不同的请求,侍者采用如下的策略:
1、老板提出请求时,如果侍者空闲,则侍者开始为老板服务。
2、如果老板提出请求时侍者正在为顾客服务,那么侍者停止为顾客服务,开始为老板提供服务。
3、如果一个老板提出请求时侍者正在为另一个老板服务,那么侍者停止为第一个老板提供服务,而开始为第二个老板服务,服务完毕后再继续为第二个老板服务。
4、一个老板可能命令侍者停止正在为顾客提供的服务。侍者在完成对老板最近请求的服务之后,可能暂时不理会原来的顾客而去为新选中的顾客服务。
这里,将其对应到内核中的功能:
侍者提供的服务 <<<————>>> CPU处于内核态时所执行的代码和程序。如果CPU在用户态执行,则侍者被认为处于空闲状态。
老板的请求 <<<————>>> 中断。
顾客的请求 <<<————>>> 用户态进程发出的系统调用或异常。
====>>>
1、2、3对应于中断和异常处理程序的嵌套执行,4对应于内核抢占(kernel preemption)。
内核抢占与非内核抢占
简单定义,如果进程正执行内核函数时,即它在内核态运行时,允许发生内核切换(被替换的进程是正执行内核函数的进程),那么这个内核就是抢占的。
* 无论在抢占内核还是非抢占内核中,运行在内核态的进程都可以自动放弃CPU,例如,其可能的原因是,进程由于等待资源而不得不转入睡眠状态。我们把这种进程切换称为计划性进程切换。但是,抢占式内核在响应引起进程切换的异步事件(例如唤醒高优先权的中断处理程序)的方式与非抢占式内核是有着极大差别的,我们将这种进程切换称为强制性进程切换。
* 所有的进程切换都由宏(switch_to)来完成。在抢占式内核和非抢占式内核中,当进程执行完某些具有内核功能的线程,而且调度程序被调用后,就发生进程切换。不过,在非抢占内核中,当前进程是不可能被替换的,除非它打算切换到用户态。
Linux 2.6版本提出的可抢占式内核是指内核抢占,即当进程位于内核空间时,有一个更高优先级的任务出现时,如果当前内核允许抢占,则可以将当前任务挂起,执行优先级更高的进程。在2.5版本及之前,Linux内核是不可抢占的,高优先级的进程不能中止正在内核中运行的低优先级的进程而抢占CPU运行。进程一旦处于核心态(例如用户进程执行系统调用),则除非进程自愿放弃CPU,否则该进程将一直运行下去,直至完成或退出内核。与此相反,一个可抢占的Linux内核可以让Linux内核如同用户空间一样允许被抢占。当一个高优先级的进程到达时,不管当前进程处于用户态还是核心态,如果当前允许抢占,可抢占内核的Linux都会调度高优先级的进程运行。
现在,总结一下抢占式内核与非抢占式内核的特点与区别:
1、非抢占式内核
非抢占式内核是由任务主动放弃CPU的使用权。非抢占式调度法也称为合作型多任务,各个任务彼此共享一个CPU。异步事件由中断服务处理。中断服务可以使一个高优先级的任务由挂起状态转为就绪状态。但中断服务以后的控制权还是回到原来被中断了的那个任务,直到该任务主动放弃CPU的使用权时,那个高优先级的任务才能获得CPU的使用权。非抢占式内核如下图。
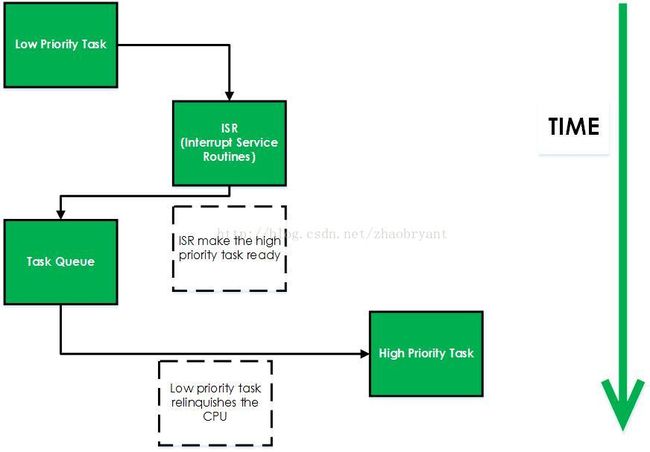
非抢占式内核的优点:
* 中断响应快(与抢占式内核相比);
* 允许使用不可重入函数;
* 几乎不需要使用信号量保护共享数据。运行的任务占有CPU,不必担心被其他任务抢占。
非抢占式内核的缺点:
* 任务相应时间慢。高优先级的任务已经进入就绪态,但还不能运行,要等到当前运行着的任务释放CPU后才能进行任务执行。
* 非抢占式内核的任务级响应时间是不确定的,最高优先级的任务获得CPU的控制权的时间,完全取决于已经运行进程何时释放CPU。
2、抢占式内核
使用抢占式内核可以保障系统响应时间。最高优先级的任务一旦就绪,总能得到CPU的使用权。当一个运行着的任务使一个比它优先级高的任务进入了就绪态,当前任务的CPU使用权就会被剥夺,或者说被挂起了,那个高优先级的任务便会立刻得到CPU的控制权。如果是中断服务子程序使一个高优先级的任务进入就绪状态,中断完成时,中断了的任务就会被挂起,优先级高的任务便开始控制CPU。抢占式内核如下图:

抢占式内核的优点:
* 使用抢占式内核,最高优先级的任务能够得到最快程度的相应,高优先级任务肯定能够获得CPU使用权。抢占式内核使得任务优先级相应时间机制得以最优化。
* 使内核可抢占的目的是减少用户态进程的分派延迟(dispatch latency),即从进程变为可执行状态到它实际开始运行之间的时间间隔。内核抢占对执行及时被调度的任务(如硬件控制器,环境监视器,电影播放器等)的进程确实是由好处的,因为它降低了这种进程被另一个运行在内核态的进程延迟的风险。
抢占式内核的缺点:
* 不能直接使用不可重入型函数。调用不可重入函数时,要满足互斥条件,可以使用互斥性信号量来实现。如果调用不可重入型函数时,对于低优先级的任务,其CPU使用权会被高优先级任务剥夺,不可重入型函数中的数据可能会被破坏。
3、内核态抢占的设计:
首先,需要做何种改进才能支持内核可抢占性呢?
只有当内核正在执行异常处理程序(尤其是系统调用),而且内核抢占没有被显式地禁用时,才可能抢占内核。此外,由从中断和异常中返回的知识,本地CPU必须打开本地中断,否则无法完成内核抢占。
另外,Linux2.6独具特色的允许用户在编译内核时通过设置选项来禁用或启用内核抢占,当然,通过内核内部,也可以显式地禁用内核抢占。那么,应该如何设置来禁止内核抢占呢?
由从中断和异常中返回可知,当被current_thread_info()宏所引用的thread_info描述符的preempt_count字段大于0时,就禁止内核抢占。
这样,我们可以通过控制以下三个不同情况来控制内核抢占禁用:a、内核正在执行中断服务例程;b、可延迟函数被禁止;c、通过把抢占计数器设置为正数而显式地禁用内核抢占。
关于preempt_count字段,有如下操作宏:
| 宏 | 说明 |
| preempt_count() | 在thread_info描述符中选择preempt_count字段 |
| preempt_disable() | 使抢占计数器的值加1 |
| preempt_enable_no_resched() | 使抢占计数器的值减1 |
| preempt_enable() | 使抢占计数器的值减1,并在 |
if (!current_thread_info->preempt_count && !irqs_disabled()){
current_thread_info->preempt_count = PREEMPT_ACTIVE;
schedule();
current_thread_info->preempt_count = 0;
}
其次,要满足什么条件时,其他的内核态任务才可以抢占已运行任务的内核态呢?
* 没有持有锁(lock)。锁用于保护临界区,不能被抢占。
* 内核态任务代码可重入(code reentrant)。
那么,如何判断当前上下文(context)(中断处理例程,系统调用,内核线程等)是没有持有锁的?
我们在前面已经提及过thread_info中的preempt_count可以通过设置正数来显式地禁用内核抢占。这里,通过控制此变量即可实现持有锁机制,preempt_count初始为0,当加锁时便执行加1操作,当解锁时便执行减1操作,由此可以实现控制内核抢占的目的。
另外,这里需要补充一些关于可重入函数的知识。
所谓可重入是指一个可以被多个任务调用的过程,任务在调用时不必担心数据是否会出错。不可重入函数在实时系统设计中被视为不安全函数。
若一个函数是可重入的,则该函数必须满足以下必要条件:
* 不能含有静态(全局)非常量数据。
* 不能返回静态(全局)非常量数据的地址。
* 只能处理由调用者提供的数据。
作为可重入函数的输入参数,只能由调用者提供,而且所提供的输入数据必须满足下面三点要求。
* 不能依赖于单实例模式资源的锁。
* 不能调用不可重入的函数。
* 在函数内部,尽量不能用 malloc 和 free 之类的方法进行内存分配和释放,如果使用,一般情况下会造成该函数的不可重入。
可重入函数主要用于多任务环境中。一个可重入的函数简单来说就是可以被中断的函数,也就是说,可以在这个函数执行的任何时刻中断它,转入OS调度下去执行另外一段代码,而返回控制时不会出现什么错误。
不可重入的函数由于使用了一些系统资源,比如全局变量区,中断向量表等,所以它如果被中断的话,可能会出现问题,这类函数是不能运行在多任务环境下的。
可重入函数也可以这样理解,重入即表示重复进入,首先它意味着这个函数可以被中断,其次意味着它除了使用自己栈上的变量以外不依赖于任何环境(包括 static),这样的函数就是purecode(纯代码)可重入,可以允许有该函数的多个副本在运行,由于它们使用的是分离的栈,所以不会互相干扰。
再则,我们来讨论一下关于内核态需要抢占的触发条件:
内核提供了一个need_resched标志(这个标志在任务结构thread_info中,其返回的是TIF_NEED_RESCHED)来表明是否需要重新执行调度。当执行调度程序时,内核抢占会根据内核抢占是否禁止来进行内核抢占操作。
在触发内核抢占及重新调度时,有以下几个重要的函数:
set_tsk_need_resched():设置指定进程中的need_resched标志;
clear_tsk_need_resched():清除指定进程中的need_resched标志;
need_resched():检查need_resched标志的值:如果被设置就返回真,否则返回假。
那么,何时触发重新调度呢?
* 时钟中断处理例程检查当前任务的时间片,当任务的时间片消耗完时,scheduler_tick()函数就会设置need_resched标志;
* 信号量、等待队列等机制唤醒时都是基于等待队列(waitqueue)的,而等待队列的唤醒函数为default_wake_function,其调用try_to_wake_up将被唤醒的任务更改为就绪状态并设置need_resched标志;
* 设置用户进程的nice值时,可能会使高优先级的任务进入就绪状态;
* 改变任务的优先级时,可能会使高优先级的任务进入就绪状态;
* 对CPU(SMP)进行负载均衡时,当前任务可能需要移动至另外一个CPU上运行。
另外,抢占发生的时机:
* 当一个中断处理例程退出,在返回到内核态时,此时隐式调用schedule()函数,当前任务没有主动放弃CPU使用权,而是被剥夺了CPU使用权。
* 当内核代码(程序)从不可抢占状态变为可抢占状态时(preemptible),也就是preempt_count从正数变为0时,此时同样隐式调用schedule()函数。
* 一个任务在内核态中,显式的调用schedule()函数,任务主动放弃CPU使用权。
* 一个任务在内核态中被阻塞,导致需要调用schedule()函数,任务主动放弃CPU使用权。
那些时候不允许内核抢占呢?
* 内核正在进行中断处理。在Linux内核中不能抢占中断(中断只能被其他中断中止和抢占,进程不能中止和抢占中断,内核抢占是被进程抢占和中止),在中断例程中不允许进行进程调度。进程调度函数schedule()会对此做出判断,如果是在中断中调用,会打印错误。
* 内核正在进行中断上下文的下半部处理时,硬件中断返回前会执行软中断,此时仍然处于中断上下文中,所以此时无法进行内核抢占。
* 内核的代码段正持有自旋锁(spinlock)、读写锁(writelock/readlock)时,内核代码段处于锁保护状态。此时,内核不能被抢占,否则由于抢占将导致其他CPU长期不能获得锁而出现死锁状态。
* 内核正在对每CPU私有的数据结构(Per-CPU data structures)进行操作。在SMP(对称多处理器)中,对于每CPU数据结构并未采用自旋锁进行保护,因为这些数据结构隐含地被保护了(不同的CPU上有不同的每CPU数据,其他CPU上运行的进程不能访问另一个CPU的每CPU数据)。在这种情况下,虽然并未采用锁机制,同样不能进行内核抢占,因为如果允许内核抢占,一个进程被抢占后重新调度,有可能调度到其他的CPU上去,这时定义的每CPU数据变量就会发生错位。因此,对于每CPU数据访问时,同样也无法进行内核抢占。
同步原语
如何避免由于对共享数据的不安全访问导致的数据崩溃?
内核使用的各种同步技术:
| 技术 | 说明 | 适用范围 |
| 每CPU变量 | 在CPU之间复制数据结构 | 所有CPU |
| 原子操作 | 对一个计数器原子地“读-修改-写”的指令 | 所有CPU |
| 内存屏障 | 避免指令重新排序 | 本地CPU或所有CPU |
| 自旋锁 | 加锁时忙等 | 所有CPU |
| 信号量 | 加锁时阻塞等待 | 所有CPU |
| 顺序锁 | 基于访问计数器的锁 | 所有CPU |
| 本地中断的禁止 | 禁止单个CPU上的中断处理 | 本地CPU |
| 本地软中断的禁止 | 禁止单个CPU上的可延迟函数处理 | 本地CPU |
| 读-复制-更新(RCU) | 通过指针而不是锁来访问共享数据结构 | 所有CPU |
每CPU变量
最好的同步技术是把设计不需要同步的临界资源放在首位,这是一种思维方法,因为每一种显式的同步原语都有不容忽视的性能开销。最简单也是最重要的同步技术包括把内核变量或数据结构声明为每CPU变量(per-cpu variable)。每CPU变量主要是数据结构的数组,系统的每个CPU对应数组的一个元素。
多核情况下,CPU是同时并发运行的,但是它们共同使用其他的硬件资源,因此我们需要解决多个CPU之间的同步问题。每CPU变量(per-cpu-variable)是内核中一种重要的同步机制。顾名思义,每CPU变量就是为每个CPU构造一个变量的副本,这样多个CPU相互操作各自的副本,互不干涉。比如我们标识当前进程的变量current_task就被声明为每CPU变量。
一个CPU不应该访问与其他CPU对应的数组元素,另外,它可以随意读或修改它自己的元素而不用担心出现竞争条件,因为它是唯一有资格这么做的CPU。但是,这也意味着每CPU变量基本上只能在特殊情况下使用,也就是当它确定在系统的CPU上的数据在逻辑上是独立的时候。
每CPU变量的特点:
1、用于多个CPU之间的同步,如果是单核结构,每CPU变量没有任何用处。
2、每CPU变量不能用于多个CPU相互协作的场景(每个CPU的副本都是独立的)。
3、每CPU变量不能解决由中断或延迟函数导致的同步问题。
4、访问每CPU变量的时候,一定要确保关闭内核抢占,否则一个进程被抢占后可能会更换CPU运行,这会导致每CPU变量的引用错误。
我们可以用数组来实现每CPU变量吗?比如,我们要保护变量var,我们可以声明int var[NR_CPUS],CPU num就访问var[num]不就可以了吗?
显然,每CPU变量的实现不会这么简单。理由:我们知道为了加快内存访问,处理器中设计了硬件高速缓存(也就是CPU的cache),每个处理器都会有一个硬件高速缓存。如果每CPU变量用数组来实现,那么任何一个CPU修改了其中的内容,都会导致其他CPU的高速缓存中对应的块失效,而频繁的失效会导致性能急剧的下降。因此,每CPU的数组元素在主存中被排列以使每个数据结构存放在硬件高速缓存的不同行,这样,对每CPU数组的并发访问不会导致高速缓存行的窃用和失效(这种操作会带来昂贵的系统开销)。
虽然每CPU变量为来自不同CPU的并发访问提供保护,但对来自异步函数(中断处理程序和可延迟函数)的访问不提供保护,在这种情况下需要另外的同步技术。
每CPU变量分为静态和动态两种,静态的每CPU变量使用DEFINE_PER_CPU声明,在编译的时候分配空间;而动态的使用alloc_percpu和free_percpu来分配回收存储空间。
每CPU变量的函数和宏:
每CPU变量的定义在include\linux\percpu.h以及include\asm-generic\percpu.h中。这些文件中定义了单核和多核情况下的每CPU变量的操作,这是为了代码的统一设计的,实际上只有在多核情况下(定义了CONFIG_SMP)每CPU变量才有意义。
常见的操作和含义如下:
| 函数名 | 说明 |
| DECLARE_PER_CPU(type, name) | 声明每CPU变量name,类型为type |
| DEFINE_PER_CPU(type, name) | 静态分配一个每CPU数组,数组名为name,类型为type |
| alloc_percpu(type) | 动态为type类型的每CPU变量分配空间,并返回它的地址 |
| free_percpu(pointer) | 释放为动态分配的每CPU变量的空间,pointer是起始地址 |
| per_cpu(name, cpu) | 获取编号cpu的处理器上面的变量name的副本 |
| get_cpu_var(name) | 获取本处理器上面的变量name的副本,该函数禁用内核抢占,主要由__get_cpu_var来完成具体的访问 |
| get_cpu_ptr(name) | 获取本处理器上面的变量name的副本的指针,该函数禁用内核抢占,主要由__get_cpu_var来完成具体的访问 |
| put_cpu_var(name) & put_cpu_ptr(name) | 表示每CPU变量的访问结束,启用内核抢占(不使用name) |
| __get_cpu_var(name) | 获取本处理器上面的变量name的副本,该函数不禁用内核抢占 |
原子操作
若干汇编语言指令具有“读-修改-写”类型——也就是说,它们访问存储器单元两次,第一次读原值,第二次写新值。
假定运行在两个CPU上的两个内核控制路径试图通过执行非原子操作来同时“读-修改-写”同一存储器单元,首先,两个CPU都试图读同一单元,但是存储器仲裁器(对访问RAM芯片的操作进行串行化的硬件电路)插手,只允许其中的一个访问而让另一个延迟,然而,当第一个读操作已经完成后,延迟的CPU从那个存储器单元正好读到同一个值(旧值)。然后,两个CPU都试图向那个存储器单元写一新值,总线存储器访问再一次被存储器仲裁器串行化,最终,两个写操作都成功。但是,全局的结果是不正确的,因为两个CPU写入同一(新)值。因此,两个交错的“读-修改-写”操作成了一个单独的操作。
避免由于“读-修改-写”指令引起的竞争条件的最容易的办法,就是确保这样的操作在芯片上是原子的。任何一个这样的操作都必须以单个指令执行,中间不能中断,且避免其他的CPU访问同一存储单元。这些很小的原子操作(atomic operations)可以建立在其他更灵活机制的基础之上以创建临界区。
原子操作可以保证指令以原子的方式执行,执行过程不被打断。它通过把读取和修改变量的行为包含在一个单步中执行,从而防止了竞争的发生,保证操作结果总是一致的。
例如:
int i=9;
线程1: i++;
===>>> i=9 OR i=8
线程2: i–-;
===>>> i=9 OR i=8
两个线程并发的执行,导致结果不确定性。原子操作的作用和信号量机制是一样,都是为了防止同时访问临界资源,保证结果的一致性。大多数硬件体系结构要么本来就支持简单的原子操作,要么就提供了锁内在总线的指令,例如x86平台上,就支持CPU锁总线操作,汇编指令前缀“LOCK”就可以将总线锁作,直到指令结束时锁打开;而有些硬件体系结构本身就不太支持原子操作,比如SPARC,但是Linux内核通过一些方法,做到了原子操作。
原子操作在Linux内核里分为原子整数操作和原子位操作,下面我们来看看这两个操作用法。
原子整数操作:
针对整数的原子操作只能对atomic_t类型的数据进行处理,之所以没有用C语言的int类型,主要有三个原因:
1、让原子函数只接受atomic_t类型的操作数,可以确保原子操作只与这种特殊类型数据一起使用,防止该类型数据不会传给其它非原子操作。
2、使用atomic_t类型确保编译器不对相应的值进行访问优化。
3、在不同体系结构上实现原子操作的时候,使用atomic_t可以屏蔽其间的差异。
在Linux内核中提供了一系统的原子整数操作函数。
| 原子整数操作 | 描述 |
| ATOMIC_INIT(int i) | 在声明一个atmoic_t变量时,将它初始化为i |
| int atmoic_read(atmoic_t *v) | 原子地读取整数变量v |
| void atmoic_set(atmoic_t *v, int i) | 原子地设置v值为i |
| void atmoic_add(atmoic_t *v, int i) | 原子地从v值加i |
| void atmoic_sub(atmoic_t *v, int i) | 原子地从v值减i |
| void atmoic_inc(atmoic_t *v) | 原子地从v值加1 |
| void atmoic_dec(atmoic_t *v) | 原子地从v值减1 |
| int atmoic_sub_and_test(int i,atmoic_t *v) | 原子地从v值减i,如果结果等于0返回真,否则返回假 |
| int atmoic_add_negative(int i,atmoic_t *v) | 原子地从v值减i,如果结果是负数返回真,否则返回假 |
| int atmoic_dec_and_test(atmoic_t *v) | 原子地给v减1,如果结果等于0返回真,否则返回假 |
| int atmoic_inc_and_test(atmoic_t *v) | 原子地给v加1,如果结果等于0返回真,否则返回假 |
原子操作最常见的用途就是实现计数器,使用复杂的锁机制来保护一个单纯的计数是很笨拙的,原子操作比起复杂的同步方法来说,给系统带来的开销小,对高速缓存行的影响也小。
原子位操作:
除了原子整数操作外,内核还提供了一组针对位这一级数据进行操作的函数,位操作函数是对普通的内在地址进行操作的,它的参数是一个指针和一个位号。由于是对普通的指针进程操作,所以没有像atomic_t这样的类型约束。
| 原子位操作 | 描述 |
| void set_bit(int nr, void *addr) | 原子地设置addr所指对象的第nr位 |
| void clear_bit(int nr, void *addr) | 原子地清空addr所指对象的第nr位 |
| void change_bit(int nr, void *addr) | 原子地翻转addr所指对象的第nr位 |
| int test_and_set_bit(int nr, void *addr) | 原子地设置addr所指对象的第nr位,并返回原先的值 |
| int test_and_clear_bit(int nr, void *addr) | 原子地清空addr所指对象的第nr位,并返回原先的值 |
| int test_and_change_bit(int nr, void *addr) | 原子地翻转addr所指对象的第nr位,并返回原先的值 |
| int test_bit(int nr, void *addr) | 原子地返回addr所指对象的第nr位 |
| void atomic_clear_mask(void *mask, void *addr) | 清零mask指定的*addr的所有位 |
| void atomic_set_mask(void *mask, void *addr) | 设置mask指定的*addr的所有位 |
优化和内存屏障
当使用优化的编译器是,指令并不会严格地按照它们在源代码中出现的顺序执行。例如,编译器可能重新安排汇编语言指令以使寄存器以最优的方式使用。此外,现代CPU通常并行地执行若干条指令,且可能重现安排内存访问,这种重新排序可能极大地加速程序的执行。
然而,当处理同步时,必须避免指令重新排序,如果放在同步原语之后的一条指令在同步原语本身之前执行,事情很快就会变得失控。事实上,所有的同步原语起优化和内存屏障的作用。
优化屏障(optimization barrier)原语保证编译程序不会混淆放在原语操作之前的汇编语言指令和放在原语操作之后的汇编语言指令,这些汇编语言指令在C中都由对应的语句。在Linux中,优化屏障就是barrier()宏。
内存屏障(memory barrier)原语确保,在原语之后的操作开始执行之前,原语之前的操作已经完成。因此,内存屏障类似于防火墙,让任何汇编语言指令都不能通过。
在《独辟蹊径品内核》一书中,如此定义内存屏障:为了防止编译器和硬件的不正确优化,使得对存储器的访问顺序(其实就是变量)和书写程序时的访问顺序不一致而提出的一种解决办法。 内存屏障不是一种错误的现象,而是一种对错误现象提出的一种解决方法。
前面概述了内存屏障,现在我们进行一些详细说明:
1、为什么会乱序执行?
现在的CPU一般采用流水线来执行指令。一个指令的执行被分划成:取指、译码、访存、执行、写回等若干个阶段。然后,多条指令可以同时存在于流水线中,同时被执行。
指令流水线并不是串行的,并不会因为一个耗时很长的指令在“执行”阶段呆很长时间,而导致后续的指令都卡在“执行”之前的阶段上。相反,流水线是并行的,多个指令可以同时处于同一个阶段,只要CPU内部相应的处理部件未被占满即可。比如说CPU有一个加法器和一个除法器,那么一条加法指令和一条除法指令就可能同时处于“执行”阶段,而两条加法指令在“执行”阶段就只能串行工作。
可见,相比于串行+阻塞的方式,流水线像这样并行的工作,效率是非常高的。
然而,这样一来,乱序可能就产生了。比如一条加法指令原本出现在一条除法指令的后面,但是由于除法的执行时间很长,在它执行完之前,加法可能先执行完了。再比如两条访存指令,可能由于第二条指令命中了cache而导致它先于第一条指令完成。
一般情况下,指令乱序并不是CPU在执行指令之前刻意去调整顺序。CPU总是顺序的去内存里面取指令,然后将其顺序的放入指令流水线。但是指令执行时的各种条件,指令与指令之间的相互影响,可能导致顺序放入流水线的指令,最终乱序执行完成。这就是所谓的“顺序流入,乱序流出”。
指令流水线除了在资源不足的情况下会阻塞之外(如前所述的一个加法器应付两条加法指令的情况),指令之间的相关性也是导致流水线阻塞的重要原因。
CPU的乱序执行并不是任意的乱序,而是以保证程序上下文因果关系为前提的。有了这个前提,CPU执行的正确性才有保证。比如:
a++;
b=f(a);
c--;
由于b=f(a)这条指令依赖于前一条指令a++的执行结果,所以b=f(a)将在“执行”阶段之前被阻塞,直到a++的执行结果被生成出来;而c--跟前面没有依赖,它可能在b=f(a)之前就能执行完。(注意,这里的f(a)并不代表一个以a为参数的函数调用,而是代表以a为操作数的指令。C语言的函数调用是需要若干条指令才能实现的,情况要更复杂些。)
像这样有依赖关系的指令如果挨得很近,后一条指令必定会因为等待前一条执行的结果,而在流水线中阻塞很久,占用流水线的资源。而编译器的乱序,作为编译优化的一种手段,则试图通过指令重排将这样的两条指令拉开一定的距离,以至于后一条指令进入CPU的时候,前一条指令结果已经得到了,那么也就不再需要阻塞等待了。比如将指令重排为:
a++;
c--;
b=f(a);
相比于CPU的乱序,编译器的乱序才是真正对指令顺序做了调整。但是编译器的乱序也必须保证程序上下文的因果关系不发生改变。
2、乱序的后果
乱序执行,有了“保证上下文因果关系”这一前提,一般情况下是不会有问题的。因此,在绝大多数情况下,我们写程序都不会去考虑乱序所带来的影响。
但是,有些程序逻辑,单纯从上下文是看不出它们的因果关系的。比如:
*addr=5;
val=*data;
从表面上看,addr和data是没有什么联系的,完全可以放心的去乱序执行。但是如果这是在某设备驱动程序中,这两个变量却可能对应到设备的地址端口和数据端口。并且,这个设备规定了,当你需要读写设备上的某个寄存器时,先将寄存器编号设置到地址端口,然后就可以通过对数据端口的读写而操作到对应的寄存器。那么,对前面那两条指令的乱序执行就可能造成错误。
对于这样的逻辑,我们姑且将其称作隐式的因果关系;而指令与指令之间直接的输入输出依赖,也姑且称作显式的因果关系。CPU或者编译器的乱序是以保持显式的因果关系不变为前提的,但是它们都无法识别隐式的因果关系。再举个例子:
Thread 1:
obj->data = 123;
obj->ready = 1;
当设置了data之后,记下标志,然后在另一个线程中可能执行:
Thread 2:
if (obj->ready)
do_something(obj->data);
虽然这个代码看上去有些别扭,但是似乎没错。不过,考虑到乱序,如果标志被置位先于data被设置,那么结果很可能就悲剧了(本来不会执行do_something函数,但是由于乱序导致执行了该函数)。因为从字面上看,前面的那两条指令其实并不存在显式的因果关系,乱序是有可能发生的。
总的来说,如果程序具有显式的因果关系的话,乱序一定会尊重这些关系;否则,乱序就可能打破程序原有的逻辑。这时候,就需要使用屏障来抑制乱序,以维持程序所期望的逻辑。
3、优化和内存屏障的作用
内存屏障主要有:读屏障、写屏障、通用屏障、优化屏障几种。
以读屏障为例,它用于保证读操作有序。屏障之前的读操作一定会先于屏障之后的读操作完成,写操作不受影响,同属于屏障的某一侧的读操作也不受影响。类似的,写屏障用于限制写操作。而通用屏障则对读写操作都有作用。而优化屏障则用于限制编译器的指令重排,不区分读写。前三种屏障都隐含了优化屏障的功能。比如:
tmp = 2048;
*addr = 5;
mb();
val = *data;
有了内存屏障就了确保先设置地址端口,再读数据端口。而至于设置地址端口与tmp的赋值孰先孰后,屏障则不做干预。有了内存屏障,就可以在隐式因果关系的场景中,保证因果关系逻辑正确。
4、内存屏障原语
Linux使用六个内存屏障原语。这些原语也被当做优化屏障,因为我们必须保证编译器程序不在屏障前后移动汇编语言指令。
| 宏 | 说明 |
| mb() | 适用于MP和UP的内存屏障 |
| rmb() | 适用于MP和UP的读内存屏障 |
| wmb() | 适用于MP和UP的写内存屏障 |
| smp_mb() | 仅适用于MP的内存屏障 |
| smp_rmb() | 仅适用于MP的读内存屏障 |
| smp_wmb() | 仅适用于MP的写内存屏障 |
内存屏障既用于多处理器系统(MP),也用于单处理器系统(UP)。当内存屏障应该防止仅出现在多处理器系统上的竞争条件时,就使用smp_xxx()原语;在单处理器系统上,它们什么也不做。其他的内存屏障原语防止出现在单处理器和多处理器系统上的竞争条件。
内存屏障原语的实现依赖于系统地体系结构。
在80x86微处理器上,如果CPU支持lfence汇编语言指令,就把rmb()宏展开为 asm volatile("lfence"),否则就展开为 asm volatile("lock;addl $0, 0(%%esp)")。asm指令告诉编译器插入一些汇编语言指令并起优化屏障的作用。lock;addl $0, 0(%%esp)汇编指令把0加到栈顶的内存单元;这条指令本身没有什么价值,但是,lock前缀使得这条指令成为CPU的一个内存屏障。
而对于wmb()宏,其实现即为barrier()宏,这是因为Intel处理器不对写内存访问进行重新排序,因此,没有必要在代码中插入一条串行化汇编指令。不过,此宏禁止编译器重新组合指令。
5、多处理器系统情况
前面只是考虑了单处理器指令乱序的问题,而在多处理器下,除了每个处理器要独自面对上面讨论的问题之外,当多个处理器之间存在交互的时候,同样要面对乱序的问题。
一个处理器(记为a)对内存的写操作并不是直接就在内存上生效的,而是要先经过自身的cache。另一个处理器(记为b)如果要读取相应内存上的新值,先得等a的cache同步到内存,然后b的cache再从内存同步这个新值。而如果需要同步的值不止一个的话,就会存在顺序问题。举一个例子:
<CPU-a>: | <CPU-b>:
|
obj->data = 123; |
if
(
obj
->
ready
)
wmb(); |
do_something
(
obj
->
data
);
obj->ready = 1; |
前面也说过,必须要使用屏障来保证CPU-a不发生乱序,从而使得ready标记置位的时候,data一定是有效的。但是在多处理器情况下,这还不够。原因在于,data和ready标记的新值可能以相反的顺序更新到CPU-b上。
其实这种情况在大多数体系结构下并不会发生,不过内核文档memory-barriers.txt举了alpha机器的例子。alpha机器可能使用分列的cache结构,每个cache列可以并行工作,以提升效率。而每个cache列上面缓存的数据是互斥的(如果不互斥就还得解决cache列之间的一致性),于是就可能引发cache更新不同步的问题。
假设cache被分成两列,而CPU-a和CPU-b上的data和ready都分别被缓存在不同的cache列上。
首先是CPU-a更新了cache之后,会发送消息让其他CPU的cache来同步新的值,对于data和ready的更新消息是需要按顺序发出的。如果cache只有一列,那么指令执行的顺序就决定了操作cache的顺序,也就决定了cache更新消息发出的顺序。但是现在假设了有两个cache列,可 能由于缓存data的cache列比较繁忙而使得data的更新消息晚于ready发出,那么程序逻辑就没法保证了。不过好在SMP下的内存屏障在解决指令乱序问题之外,也将cache更新消息乱序的问题解决了。只要使用了屏障,就能保证屏障之前的cache更新消息先于屏障之后的消息被发出。
然后就是CPU-b的问题。在使用了屏障之后,CPU-a已经保证data的更新消息先发出了,那么CPU-b也会先收到data的更新消息。不过同样,CPU-b上缓存data的cache列可能比较繁忙,导致对data的更新晚于对ready的更新。这里同样会出问题。
所以,在这种情况下,CPU-b也得使用屏障。CPU-a上要使用写屏障,保证两个写操作不乱序,并且相应的两个cache更新消息不乱序。CPU-b上则需要使用读屏障,保证对两个cache单元的同步不乱序。可见,SMP下的内存屏障一定是需要配对使用的。
所以,上面的例子应该改写成:
<CPU-a>: | <CPU-b>:
|
obj->data = 123; | if (obj->ready){
wmb(); | rmb();
obj->ready = 1; | do_something(obj->data);
| }
CPU-b上使用的读屏障还有一种弱化版本,它不保证读操作的有序性,叫做数据依赖屏障。顾名思义,它是在具有数据依赖情况下使用的屏障,因为有数据依赖(也就是之前所说的显式的因果关系),所以CPU和编译器已经能够保证指令的顺序。
<CPU-a>: | <CPU-b>:
|
init(newval); | p = data;
<write barrier> | <data dependency barrier>
data = &newval; | val = *p;
这里的屏障就可以保证:如果data指向了newval,那么newval一定是初始化过的。
自旋锁
一种广泛应用的同步技术是加锁(locking)。当内核控制路径必须访问共享数据结构或进入临界区时,就需要为自己获取一把“锁”。由于锁机制保护的资源非常类似与限制于房间内的资源,当某人进入房间时,就把门锁上。如果内核控制路径希望访问资源,就试图获取钥匙“打开门”。当且仅当资源空闲时,它才能成功。然后,只要它还想使用这个资源,门就依然锁着。当内核控制路径释放锁时,门就打开,另一个内核控制路径就可以进入房间使用资源。
下图展现了锁的使用。

5个内核控制路径(P1, P2, P3, P4和P0)试图访问两个临界区(C1, C2)。内核控制路径P0正在C1中,而P2和P4正等待进入C1。同时,P1正在C2中,而P3正在等待进入C2。注意P0和P1可以并行运行。临界区C3的锁处于打开状态,因为没有内核控制路径需要进入C3。
自旋锁(spinlock)是用来在多处理器环境中工作的一种特殊的锁。如果内核控制路径(内核态进程)发现自旋锁“开着”,就获取锁并继续自己的执行。相反,如果内核控制路径发现锁由运行在另一个CPU上的内核控制路径“锁着”,就在周围“旋转”,反复执行一条紧凑的循环指令,直到锁被释放。
自旋锁的循环指令表示“忙等”。即使等待的内核控制路径无事可做(除了浪费时间),它也在CPU上保持运行。不过,自旋锁通常非常方便,因为很多内核资源只锁1毫秒的时间片段,所以说,释放CPU和随后又获得CPU都不会消耗很多时间。
一般来说,由自旋锁所保护的每个临界区都是禁止内核抢占的。在单处理器系统上,这种锁本身不起锁的作用,自旋锁原语仅仅是禁止或启用内核抢占。请注意,在自旋锁忙等期间,内核抢占还是有效的,因此,等待自旋锁释放的进程有可能被更高优先级的进程所替代。
下面,进行几个方面对自旋锁进行相关说明:
1、为什么使用自旋锁?
操作系统锁机制的基本原理,就是在某个锁操作过程中不能与其他锁操作交织执行,以免多个执行路径对内核中某些重要的数据及数据结构进行同时操作而造成系统混乱。在不同的系统环境中,根据系统特点和操作需要,锁机制可以用多种方式来实现。在Linux中,其系统内核的锁机制一般通过3种基本方式来实现,即原语、关中断和总线锁。在单CPU系统中,CPU 的读—修改—写原语可以保证是原子的,即执行过程过中不会被中断,所以CPU通过关中断的方式,从芯片级保证该操作所存取的数据不能被多个内核控制路径同时访问,避免交叉执行。然而,在对称多处理器 (SMP) 环境中,单CPU涉及读—修改—写原语不再是原子的,因为在某个CPU执行读—修改—写指令时有多次总线操作,其他CPU竞争总线,可导致对同一存储单元的读—写操作与其他CPU对这一存储单元交叉,这时我们就需要用一个称为自旋锁(spin lock)的原始对象为CPU 提供锁定总线的方法。
2、关于自旋锁的几个事实
自旋锁实际上是忙等锁,当锁不可用时,CPU一直循环执行“测试并设置(test-and-set)”,直到该锁可用而取得该锁,CPU在等待自旋锁时不做任何有用的工作,仅仅是等待。这说明只有在占用锁的时间极短的情况下,使用自旋锁是合理的,因为此时某个CPU可能正在等待这个自旋锁。当临界区较为短小时,如只是为了保证对数据修改的原子性,常用自旋锁;当临界区很大,或有共享设备的时候,需要较长时间占用锁,使用自旋锁就不是一个很好的选择,会降低CPU的效率。
自旋锁也存在死锁(deadlock)问题。引发这个问题最常见的情况是要求递归使用一个自旋锁,即如果一个已经拥有某个自旋锁的CPU希望第二次获得这个自旋锁,则该CPU将死锁。自旋锁没有与其关联的“使用计数器”或“所有者标识”;锁或者被占用或者空闲。如果你在锁被占用时获取它,你将等待到该锁被释放。如果碰巧你的CPU已经拥有了该锁,那么用于释放锁的代码将得不到运行,因为你使CPU永远处于“测试并设置”某个内存变量的自旋状态。另外,如果进程获得自旋锁之后再阻塞,也有可能导致死锁的发生。由于自旋锁造成的死锁,会使整个系统挂起,影响非常大。
自旋锁一定是由系统内核调用的。不可能在用户程序中由用户请求自旋锁。当一个用户进程拥有自旋锁期间,内核是把代码提升到管态的级别上运行。在内部,内核能获取自旋锁,但任何用户都做不到这一点。
3、Linux 自旋锁
在Linux中,每个自旋锁都用spinlock_t结构表示,其中包含两个字段:
slock:该字段表示自旋锁的状态:值为1时,表示未加锁状态,而任何负数和0都表示加锁状态。
break_lock:表示进程正在忙等自旋锁。
自旋锁宏:
| 宏 | 说明 |
| spin_lock_init() | 把自旋锁置为1(未锁) |
| spin_lock() | 循环,直到自旋锁变为1(未锁),然后,把自旋锁置为0(锁上) |
| spin_unlock() | 把自旋锁置为1(未锁) |
| spin_unlock_wait() | 等待,直到自旋锁变为1(未锁) |
| spin_is_lock() | 如果自旋锁被置为1(未锁),返回0;否则,返回1 |
| spin_trylock() | 把自旋锁置为0(锁上),如果原来锁的值为1,则返回1;否则,返回0 |
具有内核抢占的spin_lock宏
针对支持SMP系统的抢占式内核,该宏获取自旋锁的地址slp作为其参数,并执行下面的操作:
a、调用preempt_disable()以禁用内核抢占;
b、调用函数_raw_spin_trylock(),它对自旋锁的slock字段执行原子性的测试和设置操作。该函数首先执行等价于下面汇编语言片段的一些指令:
movb $0, %a1
xchgb %a1, slp->slock
汇编语言指令xchg原子性地交换8位寄存器%a1(存0)和slp->slock指示的内存单元中的内容。随后,如果存放在自旋锁中的旧值是正数,函数就返回1,否则返回0。
c、如果自旋锁中的旧值是正数,宏结束:内核控制路径已经获得自旋锁。
d、否则,内核控制路径无法获得自旋锁,因此,宏必须执行循环一直到在其他CPU上运行的内核控制路径释放自旋锁。调用preempt_enable()递减在第一步递增了的抢占计数器。如果在执行spin_lock宏之前内核抢占被启用,那么其他进程此时可以取代等待自旋锁的进程。
e、如果break_lock字段等于0,则把它设置为1。通过检测该字段,拥有锁并在其他CPU上运行的进程可以知道是否有其他进程在等待这个锁。如果进程持有某个自旋锁时间太长,它可以提前释放锁以使等待相同自旋锁的进程能够继续向前运行。
f、执行等待循环:
while (spin_is_locked(slp) && slp->break_lock)
cpu_relax();
宏cpu_relax()简化为一条pause汇编语言指令。
g、跳转到a步骤,再次试图获取自旋锁。
非抢占式内核中的spin_lock宏
如果在内核编译时没有选择内核抢占选项,spin_lock宏就与前面描述的spin_lock宏有着很大的区别。在这种情况下,宏生成一个汇编语言程序片段,本质上等价于下面紧凑的忙等待:
1: lock; decb slp->slock (递减slp->slock, 判断其是否为正数)
jns 3f (f表示向前的,它在程序后面出现)
2: pause
cmpb $0, slp->slock (判断slp->slock是否为0)
jle 2b (b表示向后的,前跳回标签2代码)
jmp lb (前跳回标签1代码)
3:
JNS(jump if not sign),汇编语言中的条件转移指令 。结果为正则转移。
JLE(或JNG)(jump if less or equal or not greater),汇编语言中的条件转移指令。小于或等于,或者不大于则转移。
汇编语言指令decb递减自旋锁的值,该指令是原子的,因为它带有lock字节前缀。随后检测符号标志,如果它被清零,说明自旋锁被设置为1(未锁),因此,从标记3处继续正常执行。否则,在标签2处执行紧凑循环直到自旋锁出现正值。然后,从标签1处开始重新执行,因为不检查其他的处理器是否抢占了锁就继续执行是不安全的。
spin_unlock宏
spin_unlock宏释放以前获得的自旋锁,它本质上执行了下面的汇编语言指令:
movb $1, slp->slock (slock赋值为1,标为未锁)
读/写自旋锁
我们从如下几个点进行讨论:
1、什么是读写自旋锁?
自旋锁(Spinlock)是一种常用的互斥(Mutual Exclusion)同步原语(Synchronization Primitive),试图进入临界区(Critical Section)的线程使用忙等待(Busy Waiting)的方式检测锁的状态,若锁未被持有则尝试获取。这种忙等待的做法无谓地消耗了处理器资源,因此只适用于临界区非常短小的代码片段,例如Linux内核的中断处理函数。
由于互斥的特点,使用自旋锁的代码毫无线程并发性可言,多处理器系统的性能受到限制。通过观察线程(内核控制路径)在临界区的访问行为,我们发现有些线程只是简单地读取信息,并不修改任何东西,那么允许它们同时进入临界区不会有任何危险,反而能大大提高系统的并发性。这种将线程区分为读者和写者、多个读者允许同时访问共享资源、申请线程在等待期内依然使用忙等待方式的锁,我们称之为读写自旋锁(Reader-Writer Spinlock)。
读写自旋锁同样是在保护SMP体系下的共享数据结构而引入的,它的引入是为了增加内核的并发能力。只要内核控制路径没有对数据结构进行修改,读/写自旋锁就允许多个内核控制路径同时读同一数据结构。如果一个内核控制路径想对这个结构进行写操作,那么它必须首先获取读/写锁的写锁,写锁授权独占访问这个资源。这样设计的目的,即允许对数据结构并发读可以提高系统性能。
下图显示有两个受读写自旋锁保护的临界区。内核控制路径R0和R1正在同时读取C1中的数据结构,而W0正在等待获取写锁。内核控制路径W1正对C2中的数据进行写操作,而R2和W1分别等待获取读锁和写锁。
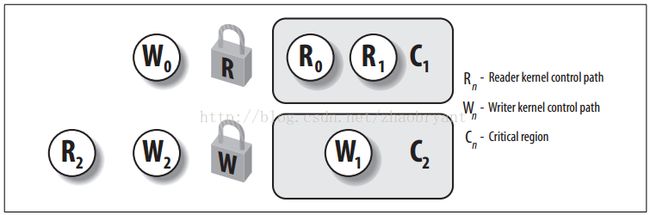
每个读/写自旋锁都是一个rwlock_t结构:
typedef struct {
raw_rwlock_t raw_lock;
#if defined(CONFIG_PREEMPT) && defined(CONFIG_SMP)
unsigned int break_lock;
#endif
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} rwlock_t;
typedef struct {
volatile unsigned int lock;
} raw_rwlock_t;
其lock字段(raw_lock)是一个32位的字段,分为两个不同的部分:
a、24位计数器,表示对受保护的数据结构并发地进行读操作的内核控制路径的数目。这个计数器的二进制补码存放在这个字段的0~23位。(为什么不保存尽心写操作的内核控制路径呢?原因在于:最多只能有一个写者访问受保护的数据结构,只存在0与1两种情况。lock字段完全可以实现,见下文。)
b、“未锁”标志字段,当没有内核控制路径在读或写时设置该位(为1),否则清0。这个“未锁”标志存放在lock字段的第24位。
注意,如果自旋锁为空(设置了“未锁”标志且无读者),那么lock字段的值为0x01000000;如果写者已经获得自旋锁(“未锁”标志清0且无读者),那么lock字段的值为0x00000000;如果一个、两个或多个进程因为读获取了自旋锁,那么,lock字段的值为Ox00ffffff,Ox00fffffe等(“未锁”标志清0表示写锁定,不允许写该数据结构的进程,读者个数的二进制补码在0~23位上;如果全为0,则表示有一个写进程在操作此数据结构)。
与spinlock_t结构一样,rwlock_t结构也包括break_lock字段。
rwlock_init()宏把读/写自旋锁的lock字段初始化为0x01000000(“未锁”),把break_lock初始化为0,算法类似spin_lock_init。
2、读写自旋锁的属性
上面提及的共享资源可以是简单的单一变量或多个变量,也可以是像文件这样的复杂数据结构。为了防止错误地使用读写自旋锁而引发的bug,我们假定每个共享资源关联一把唯一的读写自旋锁,线程只允许按照类似大象装冰箱的方式访问共享资源:
申请锁 ==>> 获得锁后,读写共享资源 ==>> 释放锁。
对于线程(内核控制路径)的执行,我们假设:
a、系统存在一个全局时钟,我们讨论的时间是离散的,不是连续的、数学意义上的时间。
b、任意时刻,系统中活跃线程的总数目是有限的。
c、线程的执行不会因为调度、缺页异常等原因无限期地被延迟。理论上,线程的执行可以被系统无限期地延迟,因此任何互斥算法都有死锁的危险。我们希望排除系统的干扰,集中关注算法及具体实现本身。
d、线程对共享资源的访问在有限步骤内结束。
e、当线程释放锁时,我们希望:线程在有限步骤内释放锁。
因为每个程序步骤花费有限时间,所以如果满足上述 5 个条件,那么:获得锁的线程必然在有限时间内将锁释放掉。
我们说某个读写自旋锁算法是正确的,是指该锁满足如下三个属性:
a、互斥。任意时刻读者和写者不能同时访问共享资源(即获得锁);任意时刻只能有至多一个写者访问共享资源。
b、读者并发。在满足“互斥”的前提下,多个读者可以同时访问共享资源。
c、无死锁(Freedom from Deadlock)。如果线程A试图获取锁,那么某个线程必将获得锁,这个线程可能是A自己;如果线程A试图但是却永远没有获得锁,那么某个或某些线程必定无限次地获得锁。
读写自旋锁主要用于比较短小的代码片段,线程等待期间不应该进入睡眠状态,因为睡眠 / 唤醒操作相当耗时,大大延长了获得锁的等待时间,所以我们要求:
d. 忙等待。申请锁的线程必须不断地查询是否发生退出等待的事件,不能进入睡眠状态。这个要求只是描述线程执行锁申请操作未成功时的行为,并不涉及锁自身的正确性。
“无死锁”属性告诉我们,从全局来看一定会有申请线程获得锁,但对于某个或某些申请线程而言,它们可能永远无法获得锁,这种现象称为饥饿(Starvation)。一种原因源于计算机体系结构的特点:例如在使用基于单一共享变量的读写自旋锁的多核系统中,如果锁的持有者A所处的处理器和等待者B所处的处理器相邻(也许还能共享二级缓存),B更容易获知锁被释放,增大获得锁的几率,而距离较远的处理器上的线程则难与之PK,导致饥饿的发生。还有一种原因源于设计策略,即读写自旋锁刻意偏好某类角色的线程。
为了提高并发性,读写自旋锁可以选择偏好读者,即读者能够优先获得锁:
a、读者优先(Reader Preference)。如果锁被读者持有,那么新来的读者可以立即获得锁,无需忙等待。至于当锁被“写者持有”或“未被持有”时,新来的读者是否可以“阻塞”到正在等待的写者之前,依赖于具体实现。
如果读者持续不断地到来,等待的写者很可能永远无法获得锁,导致饥饿。在现实中,写者的数目一般较读者少许多,而且到来的频率很低,因此读写自旋锁可以选择偏好写者来有效地缓解饥饿现象:
b、写者优先(Writer Preference)。写者必须在后到的读者 / 写者之前获得锁。因为在写者之前到来的等待线程数目是有限的,所以可以保证写者的等待时间有个合理的上界。但是多个读者之间获得锁的顺序不确定,且先到的读者不一定能在后到的写者之前获得锁。可见,如果写者持续到来,读者仍然可能产生饥饿。
为了彻底消除饥饿现象,完美的读写自旋锁还需满足下面任一属性:
c、无饥饿(Freedom from Starvation)。如果线程A试图获取锁,那么A必定能在有限时间内获得锁。当然,这个“有限时间”也许相当漫长。
d、公平(Fairness)。我们把“锁申请”操作的执行分为两个阶段:准备阶段(Doorway Section),能在有限程序步骤结束;等待阶段(Waiting Section),也许永远无法结束等待阶段一旦结束,线程即获得读写自旋锁。如果线程A和B同时申请锁,但是A的等待阶段完成于B之前,那么公平读写自旋锁保证A在B之前获得锁。如果A和B的等待阶段在时间上有重叠,那么它们获得锁的顺序是不确定的。
“公平”意味着申请锁的线程必定在有限时间内获得锁。若不然,假设A申请一个公平读写自旋锁但是永远不能获得,那么在A之后完成准备阶段的线程显然也永远不能获得锁。而在A之前或“重叠”地完成等待阶段的申请线程数目是 有限的,可见必然发生了“死锁”,矛盾。同时这也说明释放锁的时间也是有限的。使用公平读写自旋锁杜绝了饥饿现象的发生,如果假定线程访问共享资源和释放锁的时间有一个合理的上界,那么锁申请线程的等待时间只与前面等待的线程数目有关,不依赖其它因素。
P.S. 我们也可以自己去进行相关算法的设计与实现,比如说从博弈论和统计学的方向来思考(如利用概率进行读写者优先权分配等)。
3、以自动机的观点看读写自旋锁
前面关于读写自旋锁的定义和描述虽然通俗易懂,但是并不精确,很多细节比较含糊。例如,读者和写者这种角色到底是什么含义?“先来”,“后到”,“新来”以及“同时到来”如何界定?申请和释放锁的过程到底是怎样的?
现在,我们集中精力思考一下读写自旋锁到底是什么东西?读写自旋锁其实就是一个有限状态自动机(Finite State Machine)。自动机模型是一种强大的武器,可以帮助我们精确描述和理解各种算法。在给出严格定义之前,我们先规范一下上节中出现的各种概念:
a、首先,我们把读写自旋锁看成一个独立的串行系统,线程对锁函数的调用本质上是向其独立地提交操作(Operation)。操作必须是基本的,语义清晰的。所谓“基本”,是指任一种类操作的执行效果都不能由其它一种或多种操作的执行累积而成。
b、读写自旋锁的函数调用的全过程现在可以建模为:
线程提交了一个操作,然后等待读写自旋锁在某个时刻选择并执行该操作。我们举个读者申请锁的例子来具体说明。前面提到申请锁分成两个阶段,其中准备阶段我们认为线程向读写自旋锁提交了一个“读者申请”的操作。读者在等待阶段不停地测试锁的最新状态,其实就是在等待读写自旋锁的选择。最终读者在被许可的情况下“原子地”更新锁的状态,从而获得锁,说明读写自旋锁在某个合适的时刻选择并执行了该“读者申请”的操作。一旦某个操作被选中,它将不受干扰地在有限时间内成功完成并且在执行过程中读写自旋锁不能选择其它的操作。读者可能会有些奇怪,直观上锁的释放操作似乎是立即执行,难道也需要“等待”么?为了保证锁状态的一致性(Consistency),某些实现的释放函数使用了忙等待方式(参见本文的第一个实现),亦或由于调度、处理器相对速度等原因,总之锁的释放操作同样有一个不确定的等待执行的延时,因此可以和其它操作统一到相同的执行模型中。在操作成功提交至执行完毕这段时间内,线程不能睡眠。
c、某个线程对锁的一次使用既可以用读者身份申请,也可以用写者身份申请,但是不能以两种身份同时申请。可见“角色”实质上是线程分别提交了“读者申请”或“写者申请”的操作,而不能提交类似“读者写者同时申请”的操作。
d、读者 / 写者可以不停地到来 / 离去,这意味着线程能够持续地向读写自旋锁提交各种操作,但是每次只能提交一个。只有当上次提交的操作被执行后,线程才被允许提交新操作。读写自旋锁有能力知道某个操作是哪个线程提交的。
e、线程对锁的使用必须采用前面提及的规范化流程,这是指线程必须提交配对的“申请”/“释放”操作,即“申请”操作成功执行后,线程应当在有限时间内提交相应的“释放”操作,且在此之前不准提交其它操作。
f、关于读者 / 写者先来后到的顺序问题,我们转换成确定操作的提交顺序。我们认为操作的提交效果是“瞬间”产生的,即使多个线程在所谓的“同一时刻”提交操作,这些操作彼此之间也有严格的先后顺序,不存在两个或多个操作是“同时”提交成功的。在现实中,提交显然是需要一定时间的,不同线程的提交过程可能在时间上重叠,但是我们认为总可以按照一种策略规定它们的提交顺序,虽然这可能影响锁的实际执行过程,但并不影响正确性;对于同一线程提交的各个操作,它们彼此之间显然有着严格的时序关系,当然能够确定提交顺序。在此,我们彻底取消同时性的概念。
令 A(t) 为在时间段 (0, t] 内所有提交的操作构成的集合,A(t) 中的任两个操作 o1和 o2,要么 o1在 o2之前提交,要么 o1在 o2之后提交,这种提交顺序是一种全序关系(Total Order)。
读写自旋锁的形式化定义是一个 6 元组(Q,O,T,S,q0,qf),其中:
Q = {q0,q1,…,qn},是一个有限集合,称为状态集。状态 qi描述了读写自旋锁在某时刻t0所处于的一种真实状况。
O = {o0,o1,…,om},是一个有限集合,称为操作种类集。
T:Q x O -> Q 是转移函数。T 是一个偏函数(Partial Function),即 T 的定义域是 Q x O 的子集。如果 T 在 (q, o) 有定义,即存在 q’ = T(q, o),我们称状态 q 允许操作 o,在状态 q 可以执行操作 o,成功完成后读写自旋锁转换到状态 q ’;反之,如果 T 在 (q, o) 没有定义,我们称状态 q 不允许操作 o,说明在状态 q 不能执行操作 o,例如在锁被写者持有时,不能选择 “读者申请获取锁”的操作。
S 是选择函数,从已提交但未执行的操作实例集合中选择一个让读写自旋锁执行,后文详细讨论。由于任意时刻活跃线程的总数目是有限的,这个集合必然是有限集,因此我们认为 S 的每一次选择能在有限步骤内结束。
q0是初始状态。
qf是结束状态,对于任一种操作 o,T 在 (qf, o) 无定义。也就是说到达该状态后,读写自旋锁不再执行任何操作。
我们先画出与定义等价的状态图,然后描述 6 元组具体是什么。
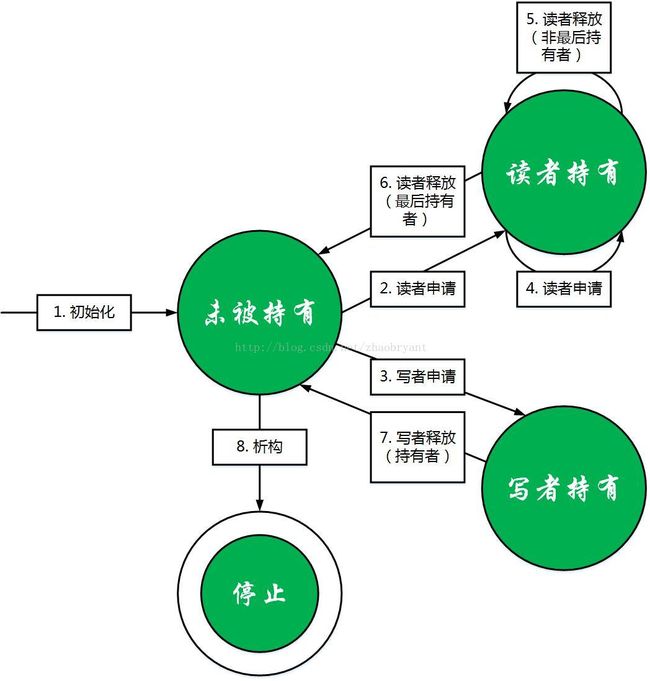
a、状态图中的每个圆圈代表一个状态。状态集合Q至少应该有3个状态:“未被持有”,“读者持有”和“写者持有”。因为可能执行“析构”操作,所以还需要增加一个结束状态“停止”。除此之外不需要新的状态。
b、有向边上的文字代表了一种操作。读写自旋锁需要 6 种操作: “初始化”、“析构”、“读者申请”、 “读者释放”、 “写者申请”和“写者释放”。操作后面括号内的文字,例如“最后持有者”,只是辅助理解,并不表示一种新的操作。
c、有向边及其上的操作定义了转移函数。如果一条有向边从状态q指向q’,且标注的操作是 o,那么表明状态q允许操作o,且 q’ = T(q, o)。
d、初始状态是“未被持有”。
e、结束状态是“停止”,双圆圈表示,该状态不射出任何有向边,表明此后锁停止执行任何操作。
结合状态图,我们描述读写自旋锁的工作原理:
a、我们规定在时刻 0 执行全局唯一一次的“初始化”操作,将锁置为初始状态“未被持有”,图中即为那条没有起点、标注“初始化“操作的有向边。如果决定停止使用读写自旋锁,则执行全局唯一一次的“析构”操作,将锁置为结束状态“停止”。
b、读写自旋锁可以被看成一个从初始状态“未被持有”开始依次“吃”操作、不断转换状态的串行机器。令 W(t) 为时间段 (0, t] 内已提交但未执行的操作构成的集合,W(t) 是所有提交的操作集合 A(t) 的子集。在时刻t,如果锁准备执行新的操作,假设当前处于状态q,W(t)不是空集且存在状态q允许的操作,那么读写自旋锁使用选择函数S在W(t)集合中选出一个来执行,执行完成后将自身状态置为 q’ = T(q, o)。
c、我们称序列 < qI1,oI1,qI2,oI2,…,oIn,qI(n+1)> 是读写自旋锁在 t 时刻的执行序列,如果:
①. oIk是操作,1 <= k <= (n + 1) 且 oI1,oI2,…,oIn属于集合 A(t)。
②. qIk是状态,1 <= k <= (n + 1)。
③. 读写自旋锁在 t 时刻的状态是 qI(n+1)。
④. qI1= q0。
⑤. T 在 (qIk, oIk) 有定义,且 qI(k+1)= T(qIk, oIk)(1 <= k <= n)。
c、假如执行序列的最后一个状态 qI(n+1)不是结束状态 qf,且在时刻 t0,W(t0) 为空或者 qI(n+1)不允许 W(t0) 中的任一个操作 o,我们称读写自旋锁在时刻t0处于潜在死锁状态。这并不表明读写自旋锁真的死锁了,因为随后线程可以提交新的操作,使其继续工作下去。例如 qI(n+1)是“写者持有”状态,而 W(t0) 中全是“读者申请”的操作。但是我们知道锁的持有者一会定在 t0之后的有限时间内提交“写者释放”操作,届时读写自旋锁可以选择执行它,将状态置为“未被持有”,而现存的“读者申请”的操作随后也可被执行了。
d、如果存在t0 > 0,且对于任意 t >= t0,读写自旋锁在时刻t都处于潜在死锁状态,我们称读写自旋锁从时刻t0开始“死锁”。
以下是状态图正确性的证明概要:
a、互斥。从图可知,状态“读者持有”只能转换到自身和“未被持有”,不能转换到“写者持有”,同时状态“写者持有”只能转换到“未被持有”,不能转换到“读者持有”,所以锁一旦被持有,另一种角色的线程只有等到“未被持有”的状态才有机会获得锁,因此读者和写者不可能同时获得锁。状态“写者持有”不允许“写者申请”操作,故而任何时刻只有至多一个写者获得锁。
b、读者并发。状态“读者持有”允许“读者申请”操作,因此可以有多个读者同时持有锁。
c、无死锁。证明关于线程执行的 3 个假设。反证法,假设对任意t >= t0,锁在时刻t都处于潜在死锁状态。令q为t0时刻锁的状态,分 3 种情况讨论:
“未被持有”。如果线程A在 t1 > t0 的时刻提交“读者申请”或“写者申请”的操作,那么锁在t1时刻并不处于潜在死锁状态。
“读者持有”。持有者必须在某个 t1 > t0 的时刻提交“读者释放”的操作,那么锁在t1时刻并不处于潜在死锁状态。
“写者持有”。持有者必须在某个 t1 > t0 的时刻提交“写者释放”的操作,那么锁在t1时刻并不处于潜在死锁状态。
从线程 A 申请锁的角度来看,由状态图知对于任意时刻 t0,不论锁在 t0的状态如何,总存在 t1> t0,锁在时刻 t1必定处于“未被持有”的状态,那么在时刻 t1允许锁申请操作,不是 A 就是别的线程获得锁。如果 A 永远不能获得锁,说明锁一旦处于“未被持有”的状态,就选择了别的线程提交的锁申请操作,那么某个或某些线程必然无限次地获得锁。
上面提到读写自旋锁有一种选择未执行的操作的能力,即选择函数 S,正是这个函数的差异,导致锁展现不同属性:
a、读者优先。在任意时刻 t,如果锁处于状态“读者持有”,S 以大于 0 的概率选择一个尚未执行的“读者申请”操作。这意味着:首先,即使有先提交但尚未执行的“写者申请”操作,“读者申请”操作可以被优先执行;其次,没有刻意规定如何选“读者申请”操作,因此多个“读者申请”操作间的执行顺序是不确定的;最后,不排除连续选择“读者释放”操作,使得锁状态迅速变为“未被持有”,只不过这种几率很小。
b、写者优先。在任意时刻 t,如果 o1是尚未执行的“写者申请”操作,o2是尚未执行的“读者申请”或“写者申请”操作,且 o1在 o2之前提交,那么 S 保证一定在 o2之前选择 o1。
c、无饥饿。如果线程提交了操作 o,那么 S 必定在有限时间内选择 o。即存在时刻 t,读写自旋锁在 t 的执行序列 < qI1,oI1,qI2,oI2,…,oIn,qI(n+1)> 满足 o = oIn。狭义上, o 限定为“读者申请”或“写者申请”操作。
d、公平。如果操作 o1在 o2之前提交,那么 S 保证一定在在 o2之前选择执行 o1。狭义上,o1和 o2限定为“读者申请”或“写者申请”操作。
4、读写自旋锁的实现细节
上文阐述的自动机模型是个抽象的机器,用于帮助我们理解读写自旋锁的工作原理,但是忽略了很多实现的关键细节:
a、操作的执行者。如果按照前面的描述,为读写自旋锁创建专门的操作执行线程,那么锁的实际性能将会比较低下,因此我们要求申请线程自己执行提交的操作。
b、操作类别的区分。可以提供多个调用接口来区分不同种类的操作,避免使用额外变量存放类别信息。
c、确定操作的提交顺序,即线程的到来的先后关系。写者优先和公平读写自旋锁需要这个信息。可以有 3 种方法:
①、假定系统有一个非常精确的实时时钟,线程到来的时刻用于确定顺序。但是寻找直接后继者比较困难,因为事先无法预知线程到来的精确时间。
②、参考银行的做法,即每个到来的线程领取一张号码牌,号码的大小决定先后关系。
③、将线程组织成一个先进先出(FIFO)的队列,具体实现可以使用单向链表,双向链表等。
d、在状态 q,确定操作(线程)是否被允许执行。这有 2 个条件:首先 q 必须允许该操作;其次对于写者优先和公平读写自旋锁,不存在先提交但尚未执行的写者(读者 / 写者)申请操作。可以有 3 种方法:
①、不停地主动查询这 2 个条件。
②、被动等待前一个执行线程通知。
③、主动/被动相结合。
e、选择执行的线程。在状态 q,如果存在多个被允许执行的线程,那么它们必须达成一致(Consensus),保证只有一个线程执行成功,否则会破坏锁状态的一致性。有 2 种简单方法:
①、互斥执行。原子指令(总线级别的互斥),或使用锁(高级互斥原语)。
②、投机执行。线程不管三七二十一先执行再说,然后检查是否成功。如果不成功,可能需要执行回滚操作。
f、因为多个读者可以同时持有锁,那么读者释放锁时,有可能需要知道自己是不是最后一个持有者(例如通知后面的写者)。一个简单的方法是用共享计数器保存当前持有锁的读者数目。如果我们对具体数目并不关心,只是想知道计数器是大于 0 还是等于 0,那么用一种称为“非零指示器”(Non-Zero Indicator)的数据结构效果更好。还可以使用双向链表等特殊数据结构。
5、为读获取和释放一个锁
read_lock宏,作用于读/写自旋锁的地址*lock,与前面所描述的spin_lock宏非常相似。如果编译内核时选择了内核抢占选项,read_lock宏执行与spin_lock()非常相似的操作,只有一点不同:该宏执行_raw_read_trylock( )函数以在第2步有效地获取读/写自旋锁。
void __lockfunc _read_lock(rwlock_t *lock)
{
preempt_disable();
rwlock_acquire_read(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, _raw_read_trylock, _raw_read_lock);
}
在没有定义调试自旋锁操作时rwlock_acquire_read为空函数,我们不去管它。所以_read_lock的实务函数是_raw_read_trylock:
# define _raw_read_trylock(rwlock) __raw_read_trylock(&(rwlock)->raw_lock)
static inline int __raw_read_trylock(raw_rwlock_t *lock)
{
atomic_t *count = (atomic_t *)lock;
atomic_dec(count);
if (atomic_read(count) >= 0)
return 1;
atomic_inc(count);
return 0;
}
读/写锁计数器lock字段是通过原子操作来访问的。注意,尽管如此,但整个函数对计数器的操作并不是原子性的,利用原子操作主要目的是禁止内核抢占。例如,在用if语句完成对计数器值的测试之后并返回1之前,计数器的值可能发生变化。不过,函数能够正常工作:实际上,只有在递减之前计数器的值不为0或负数的情况下,函数才返回1,因为计数器等于0x01000000表示没有任何进程占用锁,等于Ox00ffffff表示有一个读者,等于0x00000000表示有一个写者(因为只可能有一个写者)。
如果编译内核时没有选择内核抢占选项,read_lock宏产生下面的汇编语言代码:
movl $rwlp->lock,%eax
lock; subl $1,(%eax)
jns 1f
call _ _read_lock_failed
1:
这里,__read_lock_failed()是下列汇编语言函数:
_ _read_lock_failed:
lock; incl (%eax)
1: pause
cmpl $1,(%eax)
js 1b
lock; decl (%eax)
js _ _read_lock_failed
ret
read_lock宏原子地把自旋锁的值减1,由此增加读者的个数。如果递减操作产生一个非负值,就获得自旋锁;否则就算作失败。我们看到lock字段的值由Ox00ffffff到0x00000000要减多少次才可能出现负值,所以几乎很难出现调用__read_lock_failed()函数的情况。该函数原子地增加lock字段以取消由read_lock宏执行的递减操作,然后循环,直到lock字段变为正数(大于或等于0)。接下来,__read_lock_failed()又试图获取自旋锁(正好在cmpl指令之后,另一个内核控制路径可能为写获取自旋锁)。
释放读自旋锁是相当简单的,因为read_unlock宏只需要使用汇编语言指令简单地增加lock字段的计数器:
lock; incl rwlp->lock
以减少读者的计数,然后调用preempt_enable()重新启用内核抢占。
6、为写获取或释放一个锁
write_lock宏实现的方式与spin_lock()和read_lock()相似。例如,如果支持内核抢占,则该函数禁用内核抢占并通过调用_raw_write_trylock()立即获得锁。如果该函数返回0,说明锁已经被占用,因此,该宏像前面博文描述的那样重新启用内核抢占并开始忙等待循环。
#define write_lock(lock) _write_lock(lock)
void __lockfunc _write_lock(rwlock_t *lock)
{
preempt_disable();
rwlock_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, _raw_write_trylock, _raw_write_lock);
}
_raw_write_trylock()函数描述如下:
int
_raw_write_trylock
(
rwlock_t
*
lock
)
{
atomic_t *count = (atomic_t *)lock->lock;
if (atomic_sub_and_test(0x01000000, count))
return 1;
atomic_add(0x01000000, count);
return 0;
}
static __inline__ int atomic_sub_and_test(int i, atomic_t *v)
{
unsigned char c;
__asm__ __volatile__(
LOCK "subl %2,%0; sete %1"
:"=m" (v->counter), "=qm" (c)
:"ir" (i), "m" (v->counter) : "memory");
return c;
}
函数_raw_write_trylock()调用tomic_sub_and_test(0x01000000, count)从读/写自旋锁lock->lock的值中减去0x01000000,从而清除未上锁标志(看见没有?正好是第24位)。如果减操作产生0值(没有读者),则获取锁并返回1;否则,函数原子地在自旋锁的值上加0x01000000,以取消减操作。
释放写锁同样非常简单,因为write_unlock宏只需使用汇编语言指令:
lock; addl $0x01000000,rwlp
把lock字段中的“未锁”标识置位,然后再调用preempt_enable()。
参考:
http://www.ibm.com/developerworks/cn/linux/l-cn-rwspinlock1/#ibm-pcon
http://www.ibm.com/developerworks/cn/linux/l-cn-rwspinlock2/index.html
http://www.ibm.com/developerworks/cn/linux/l-cn-rwspinlock3/index.html
顺序锁
当使用读写自旋锁时,内核控制路径发出的执行read_lock或write_lock操作的请求具有相同的优先级:读者必须等待,直到写操作完成。同样的,写者也必须等待,直到读操作完成。
Linux2.6中引入了顺序锁(seqlock),它与读写自旋锁非常相似,只是它为写者赋予了更高的优先级:事实上,即使在读者正在读的时候也允许写者继续运行。这种策略的好处是写者永远不会等待(除非另一个写者正在写),缺点就是有些时候读者不得不反复多次读相同的数据直到它获得有效的副本。
顺序锁是对读写锁的一种优化,对于顺序锁,读者绝不会被写者阻塞,也就说,读者可以在写者对被顺序锁保护的共享资源进行写操作时仍然可以继续读,而不必等待写者完成写操作,写者也不需要等待所有读者完成读操作才去进行写操作。但是,写者与写者之间仍然是互斥的,即如果有写者在进行写操作,其他写者必须自旋在那里,直到写者释放了顺序锁。
这种锁有一个限制,它必须要求被保护的共享资源不含有指针,因为写者可能使得指针失效,但读者如果正要访问该指针,将导致致命错误。
如果读者在读操作期间,写者已经发生了写操作,那么,读者必须重新读取数据,以便确保得到的数据是完整的。
这种锁对于读写同时进行的概率比较小的情况,性能是非常好的,而且它允许读写同时进行,因而更大地提高了并发性。
顺序锁的结构如下:
typedef struct{
unsigned int sequence;
spinlock_t lock;
} seqlock_t;
其中包含一个类型为spinlock_t的lock字段和一个整型的sequence字段,第二个字段是一个顺序计数器。每个读者都必须在读数据前后两次读顺序计数器,并检查两次读到的数据是否相同,如果不相同,说明新的写者已经开始写并增加了顺序计数器,因此暗示读者刚读到的数据是无效的。
注意,并不是每一种资源都可以使用顺序锁来保护,一般来说,必须满足下述条件时才能使用顺序锁:
* 被保护的数据结构不包括被写者修改和被读者间接引用的指针(否则,写者可能在读者访问时修改指针而不被发现);
* 读者的临界区代码没有副作用(否则,多个读者的操作会与单独的读操作有着不同的结果)。
顺序锁的API如下:
void write_seqlock(seqlock_t *sl);
写者在访问被顺序锁s1保护的共享资源前需要调用该函数来获得顺序锁s1。它实际功能上等同于spin_lock,只是增加了一个对顺序锁顺序号的加1操作,以便读者能够检查出是否在读期间有写者访问过。
void write_sequnlock(seqlock_t *sl);
写者在访问完被顺序锁s1保护的共享资源后需要调用该函数来释放顺序锁s1。它实际功能上等同于spin_unlock,只是增加了一个对顺序锁顺序号的加1操作,以便读者能够检查出是否在读期间有写者访问过。
写者使用顺序锁的模式如下:
write_seqlock(&seqlock_a);
//写操作代码块
…
write_sequnlock(&seqlock_a);
因此,对写者而言,它的使用与spinlock相同。
int write_tryseqlock(seqlock_t *sl);
写者在访问被顺序锁s1保护的共享资源前也可以调用该函数来获得顺序锁s1。它实际功能上等同于spin_trylock,只是如果成功获得锁后,该函数增加了一个对顺序锁顺序号的加1操作,以便读者能够检查出是否在读期间有写者访问过。
unsigned read_seqbegin(const seqlock_t *sl);
读者在对被顺序锁s1保护的共享资源进行访问前需要调用该函数。读者实际没有任何得到锁和释放锁的开销,该函数只是返回顺序锁s1的当前顺序号。
int read_seqretry(const seqlock_t *sl, unsigned iv);
读者在访问完被顺序锁s1保护的共享资源后需要调用该函数来检查,在读访问期间是否有写者访问了该共享资源,如果是,读者就需要重新进行读操作,否则,读者成功完成了读操作。
因此,读者使用顺序锁的模式如下:
do {
seqnum = read_seqbegin(&seqlock_a);
//读操作代码块
...
} while (read_seqretry(&seqlock_a, seqnum));
write_seqlock_irqsave(lock, flags)
写者也可以用该宏来获得顺序锁lock,与write_seqlock不同的是,该宏同时还把标志寄存器的值保存到变量flags中,并且失效了本地中断。
write_seqlock_irq(lock)
写者也可以用该宏来获得顺序锁lock,与write_seqlock不同的是,该宏同时还失效了本地中断。与write_seqlock_irqsave不同的是,该宏不保存标志寄存器。
write_seqlock_bh(lock)
写者也可以用该宏来获得顺序锁lock,与write_seqlock不同的是,该宏同时还失效了本地软中断。
write_sequnlock_irqrestore(lock, flags)
写者也可以用该宏来释放顺序锁lock,与write_sequnlock不同的是,该宏同时还把标志寄存器的值恢复为变量flags的值。它必须与write_seqlock_irqsave配对使用。
write_sequnlock_irq(lock)
写者也可以用该宏来释放顺序锁lock,与write_sequnlock不同的是,该宏同时还使能本地中断。它必须与write_seqlock_irq配对使用。
write_sequnlock_bh(lock)
写者也可以用该宏来释放顺序锁lock,与write_sequnlock不同的是,该宏同时还使能本地软中断。它必须与write_seqlock_bh配对使用。
read_seqbegin_irqsave(lock, flags)
读者在对被顺序锁lock保护的共享资源进行访问前也可以使用该宏来获得顺序锁lock的当前顺序号,与read_seqbegin不同的是,它同时还把标志寄存器的值保存到变量flags中,并且失效了本地中断。注意,它必须与read_seqretry_irqrestore配对使用。
read_seqretry_irqrestore(lock, iv, flags)
读者在访问完被顺序锁lock保护的共享资源进行访问后也可以使用该宏来检查,在读访问期间是否有写者访问了该共享资源,如果是,读者就需要重新进行读操作,否则,读者成功完成了读操作。它与read_seqretry不同的是,该宏同时还把标志寄存器的值恢复为变量flags的值。注意,它必须与read_seqbegin_irqsave配对使用。
因此,读者使用顺序锁的模式也可以为:
do {
seqnum = read_seqbegin_irqsave(&seqlock_a, flags);
//读操作代码块
...
} while (read_seqretry_irqrestore(&seqlock_a, seqnum, flags));
读者和写者所使用的API的几个版本应该如何使用与自旋锁的类似。
如果写者在操作被顺序锁保护的共享资源时已经保持了互斥锁保护对共享数据的写操作,即写者与写者之间已经是互斥的,但读者仍然可以与写者同时访问,那么这种情况仅需要使用顺序计数(seqcount),而不必要spinlock。
顺序计数的API如下:
unsigned read_seqcount_begin(const seqcount_t *s);
读者在对被顺序计数保护的共享资源进行读访问前需要使用该函数来获得当前的顺序号。
int read_seqcount_retry(const seqcount_t *s, unsigned iv);
读者在访问完被顺序计数s保护的共享资源后需要调用该函数来检查,在读访问期间是否有写者访问了该共享资源,如果是,读者就需要重新进行读操作,否则,读者成功完成了读操作。
因此,读者使用顺序计数的模式如下:
do {
seqnum = read_seqbegin_count(&seqcount_a);
//读操作代码块
...
} while (read_seqretry(&seqcount_a, seqnum));
void write_seqcount_begin(seqcount_t *s);
写者在访问被顺序计数保护的共享资源前需要调用该函数来对顺序计数的顺序号加1,以便读者能够检查出是否在读期间有写者访问过。
void write_seqcount_end(seqcount_t *s);
写者在访问完被顺序计数保护的共享资源后需要调用该函数来对顺序计数的顺序号加1,以便读者能够检查出是否在读期间有写者访问过。
写者使用顺序计数的模式为:
write_seqcount_begin(&seqcount_a);
//写操作代码块
…
write_seqcount_end(&seqcount_a);
需要特别提醒,顺序计数的使用必须非常谨慎,只有确定在访问共享数据时已经保持了互斥锁才可以使用。
读-拷贝-更新(RCU)
读-拷贝-更新(RCU)是为了保护在多数情况下被多个CPU读的数据结构而设计的另一种同步技术。RCU允许多个读者和写者并发执行(相对于只允许一个写者执行的顺序锁有了改进)。而且,RCU是不是用锁的,就是说,它不使用被所有CPU共享的锁或计数器,在这一点上与读写自旋锁和顺序锁相比,RCU具有更大的优势。
RCU是如何不使用共享数据结构而实现多个CPU同步呢?其关键思想如下所示:
* RCU只保护被动态分配并通过指针引用的数据结构;
* 在被RCU保护的临界区中,任何内核控制路径都不能睡眠。
当内核控制路径要读取被RCU保护的数据结构时,执行宏rcu_read_lock(),它等同于preempt_disable()。接下来,读者间接引用该数据结构所对应的内存单元并开始读这个数据结构。读者在完成对数据结构的读操作之前,是不能睡眠的。用等同于preempt_enable()的宏rcu_read_unlock()标记临界区的结束。
由于读者几乎不做任何事情来防止竞争条件的出现,所以写者不得不做得更多一些。事实上,当写者要更新数据结构是,它间接引用指针并生成整个数据结构的副本。接下来,写者修改这个副本。由于修改指针值的操作是一个原子操作,所以旧副本和新副本对每个读者和写者是可见的,在数据结构中不会出现数据崩溃。尽管如此,还需要内存屏障来保证:只有在数据结构被修改之后,已更新的指针对其他CPU才是可见的。如果把自旋锁与RCU结合起来以禁止写者的并发执行,就隐含地引入了这样的内存屏障。
然而,使用RCU的真正困难在于:写者修改指针时不能立即释放数据结构的旧副本。实际上,写者开始修改时,正在访问数据结构的读者可能还在读旧副本。只有在CPU上的所有读者都执行完宏rcu_read_unlock()之后,才可以释放旧副本。内核要求每个潜在的读者在下面的操作之前执行rcu_read_unlock()宏:
* CPU执行进程切换;
* CPU开始在用户态执行;
* CPU执行空循环。
对于上述每种情况,我们说CPU已经过了静止状态(quiescent state)。
写者调用call_rcu()来释放数据结构的旧副本。该函数把回调函数和其参数的地址存放在rcu_head描述符中,然后把描述符插入回调函数的每个CPU链表中。内核没经过一个时钟滴答就周期性的检查本地CPU是否经过了一个静止状态。如果所有CPU都经过了静止状态,本地tasklet就执行链表中的所有回调函数。
RCU是Linux 2.6中新加的功能,常用在网络层和虚拟文件系统中。
信号量
信号量,从本质上说,它实现了一个加锁原语,即让等待者睡眠,直到等待的资源变为空闲。
实际上,Linux提供两种信号量:
* 内核信号量,由内核控制路径使用。
* System V IPC信号量,由用户态进程使用。
内核信号量类似于自旋锁,因为当锁关闭着时,它不允许内核控制路径继续进行。然而,当内核控制路径试图获取内核信号量所保护的忙资源时,相应的进程被挂起。只有在资源被释放时,相应的进程才再次变为可运行的。因此,只有可以睡眠的函数才能获取信号量:中断处理程序和可延迟函数都不能使用内核信号量。
信号量由结构semaphore描述,它基于自旋锁改进而成,其包括一个自旋锁、信号量计数器和一个等待队列。用户程序只能调用信号量API函数,而不能直接访问semaphore结构。其结构定义如下(include/asm-i386/semaphore.h)
struct semaphore {
atomic_t count;
int sleepers;
wait_queue_head_t wait;
};
struct semaphore{
spinlock_t lock;
unsigned int count;
struct list_head wait_list;
};
在这里,我们主要关注linux 2.6版本中的信号量机制。
现对linux 2.6版本中的信号量结构体字段进行详细说明:
## count字段:存放atomic_t类型的一个值,如果该值大于0,那么资源就是空闲的,也就是说,该资源现在可以使用。相反,如果count等于0,那么信号量是忙的,但没有进程等待这个被保护的资源。最后,如果count为负数,那么资源是不可用的,并至少一个进程在等待该资源。
## wait字段:存放等待队列链表的地址,当前等待资源的所有睡眠进程都放在这个链表中。当然,如果count大于或等于0,等待队列就为空。
注:wait_queue_head_t结构体:
struct __wait_queue_head {
wq_lock_t lock;
struct list_head task_list;
#if WAITQUEUE_DEBUG
long __magic;
long __creator;
#endif
};
typedef struct __wait_queue_head wait_queue_head_t;
## sleepers字段:存放一个标志,表示是否有一些进程在信号量上睡眠。
在具体的操作中,信号量提供了许多的API供程序调用:
可以用init_MUTEX()和init_MUTEX_LOCKED()函数来初始化互斥访问所需的信号量:这两个函数分别把count字段设置成1(互斥资源访问的资源空闲)和0(对信号量进行初始化的进程当前互斥访问的资源忙)。
static inline void sema_init (struct semaphore *sem, int val)
{
/*
* *sem = (struct semaphore)__SEMAPHORE_INITIALIZER((*sem),val);
*
* i'd rather use the more flexible initialization above, but sadly
* GCC 2.7.2.3 emits a bogus warning. EGCS doesn't. Oh well.
*/
atomic_set(&sem->count, val);
sem->sleepers = 0;
init_waitqueue_head(&sem->wait);
}
static inline void init_MUTEX (struct semaphore *sem)
{
sema_init(sem, 1);
}
static inline void init_MUTEX_LOCKED (struct semaphore *sem)
{
sema_init(sem, 0);
}
宏DECLARE_MUTEX和DECLARE_MUTEX_LOCKED完成同上的同样的功能,但它们也静态分配semaphore结构的变量。当然,也可以把信号量中的count字段初始化为任意的正整数n,在这种情况下,最多有n个进程可以并发地访问这个资源。
#define __SEMAPHORE_INITIALIZER(name, n) \
{ \
.count = ATOMIC_INIT(n), \
.sleepers = 0, \
.wait = __WAIT_QUEUE_HEAD_INITIALIZER((name).wait) \
}
#define __MUTEX_INITIALIZER(name) \
__SEMAPHORE_INITIALIZER(name,1)
#define __DECLARE_SEMAPHORE_GENERIC(name,count) \
struct semaphore name = __SEMAPHORE_INITIALIZER(name,count)
#define DECLARE_MUTEX(name) __DECLARE_SEMAPHORE_GENERIC(name,1)
#define DECLARE_MUTEX_LOCKED(name) __DECLARE_SEMAPHORE_GENERIC(name,0)
&*& 获取和释放信号量
获取信号量函数:static inline void down(struct semaphore * sem);
释放信号量函数:static inline void up(struct semaphore * sem);
首先,从如何释放信号量开始讨论,up()函数本质上等价于下面的汇编语言片段:
movl $sem->count, %ecx
lock; incl (%ecx)
jg lf # 大于0跳转至1标记处
lea %ecx, %eax # lea(Load effect address): 取有效地址,也就是取偏移地址---- lea 目的 源:即将源中的地址传给目的.
pushl %edx # 保存现场
pushl %ecx
call __up # 队列释放(唤醒队列中的睡眠进程)
popl %ecx
popl %edx
1:
fastcall void __up(struct semaphore *sem)
{
wake_up(&sem->wait);
}
up()函数增加*sem信号量count字段的值,然后,检查它的值是否大于0。count的增加及其后所测试的标志的设置都必须原子地执行;否则,另一个内核控制路径有可能同时访问这个字段的值,这会导致灾难性的后果。如果count大于0,说明没有进程在等待队列上睡眠,因此,就什么事都不做。否则,调用__up()函数以唤醒一个睡眠进程。
相反,当进程希望获取内核信号量锁时,就调用down()函数。down()的实现相当棘手,但本质上等价于下面代码:
down:
movl $sem->count, %ecx
lock; decl (%ecx)
jns 1f #JNS(jump if not sign),汇编语言中的条件转移指令.结果为正则转移.
lea %ecx, %eax
pushl %edx
pushl %ecx
call __down
popl %ecx
popl %edx
1:
fastcall void __sched __down(struct semaphore * sem)
{
struct task_struct *tsk = current;
DECLARE_WAITQUEUE(wait, tsk);
unsigned long flags;
tsk->state = TASK_UNINTERRUPTIBLE;
spin_lock_irqsave(&sem->wait.lock, flags);
add_wait_queue_exclusive_locked(&sem->wait, &wait);
sem->sleepers++;
for (;;) {
int sleepers = sem->sleepers;
/*
* Add "everybody else" into it. They aren't
* playing, because we own the spinlock in
* the wait_queue_head.
*/
if (!atomic_add_negative(sleepers - 1, &sem->count))
// atomic_add_negative(i,v):把i加到*v,如果结果为负,返回1,如果结果为0或正数,返回0.
// 同时注意该函数会将sleepers-1加到sem->count并保存该值至sem->count,这就会有这样一个细节:
// 如果有睡眠进程,sleepers=1, sleepers++;=>>2, 这样sleepers-1+sem->count就相当于恢复了前面的sem->count
// (注意刚开始时由汇编语言导致sem->count--,现在通过+1即保证了count的取值范围即为1/0/-1).
{
sem->sleepers = 0;
break;
}
sem->sleepers = 1; /* us - see -1 above */
spin_unlock_irqrestore(&sem->wait.lock, flags);
schedule();
spin_lock_irqsave(&sem->wait.lock, flags);
tsk->state = TASK_UNINTERRUPTIBLE;
}
remove_wait_queue_locked(&sem->wait, &wait);
wake_up_locked(&sem->wait);
spin_unlock_irqrestore(&sem->wait.lock, flags);
tsk->state = TASK_RUNNING;
}
down()函数减少*sem信号量的count字段的值,然后检查该值是否为负。该值的减少和检查过程都必须是原子的。如果count大于等于0,当前进程获得资源并继续正常执行。否则,count为负,当前进程必须挂起。把一些寄存器的内容保存在栈中,然后调用__down()。
从本质上说,__down()函数把当前进程的状态从TASK_RUNNING变为TASK_UNINTERRUPTIBLE,并把进程放在信号量的等待队列。该函数在访问信号量结构的字段之前,要获得用来保护信号量等待队列的sem->wait.lock自旋锁,并禁止本地中断。通常当插入和删除元素时,等待队列函数根据需要获取和释放等待队列的自旋锁。函数__down()也用等待队列自旋锁来保护信号量数据结构的其他字段,以使在其他CPU上运行的进程不能读或修改这些字段。最后,__down()使用等待队列函数的"lock"版本,它假设在调用等待队列函数之前已经获得了自旋锁。
__down()函数的主要任务是挂起当前进程,直到信号量被释放。然而,要实现这种想法并不容易。为了更容易地理解代码,要牢记如果没有进程在信号量等待队列上睡眠,则信号量sleepers字段通常被置为0,否则被置为1。
考虑以下几种典型的情况:
* MUTEX信号量打开(count=1,sleepers=0)
down宏仅仅把count字段置为0,并跳到主程序的下一条指令;因此,__down()函数根本不执行。
* MUTEX信号量关闭,没有睡眠进程(count=0,sleepers=0)
down宏减count并将count字段置为-1 且sleepers字段置为0来调用__down()函数。在循环体的每次循环中,该函数检查count字段是否为负。
# 如果count字段为负,__down()就调用schedule()挂起当前进程。count字段仍然设置为-1,而sleepers字段置为1,。随后,进程在这个循环内核恢复自己的运行并又进行测试。
# 如果count字段不为负,则把sleepers置为0,并从循环退出。__down()试图唤醒信号量等待队列中的另一个进程,并终止保持的信号量。在退出时,count字段和sleepers字段都置为0,这表示信号量关闭且没有进程等待信号量。
* MUTEX信号量关闭,有其他睡眠进程(count=-1,sleepers=1)
down宏减count并将count字段置为-2且sleepers字段置为1来调用__down()函数。该函数暂时把sleepers置为2,然后通过把sleepers - 1 加到count来取消down宏执行的减操作。同时,该函数检查count是否依然为负。
# 如果count字段为负,__down()函数把sleepers重新设置为1,并调用schedule()函数挂起当前进程。count字段还是置为-1,而sleepers字段置为1.
# 如果count字段不为负,__down()函数吧sleepers置为0,试图唤醒信号量等待队列上的另一个进程,并退出持有的信号量。在退出时,count字段置为0且sleepers字段置为0。
其他函数:
down_trylock()函数:适用于异步处理程序。该函数和down()函数除了对资源繁忙情况的处理有所不同之外,其他都是相同的。在资源繁忙时,该函数会立即返回,而不是让进程去睡眠。
down_interruptible函数:该函数广泛使用在设备驱动程序中,因为如果进程接收了一个信号但在信号量上被阻塞,就允许进程放弃“down”操作。
另外,因为进程通常发现信号量处于打开状态,因此,就可以优化信号量函数。尤其是,如果信号量等待队列为空,up()函数就不执行跳转指令。同样,如果信号量是打开的,down()函数就不执行跳转指令。信号量实现的复杂性是由于极力在执行流的主分支上避免费时的指令而造成的。
读写信号量
读写信号量类似于前面的“读写自旋锁”,但不同的是:在信号量再次变为打开之前,等待进程挂起而不是自旋。很多内核控制路径为读可以并发地获取读写信号量,但是,任何写者内核控制路径必须有对被保护资源的互斥访问。因此,只有在没有内核控制路径为读访问或写访问持有信号量时,才可以为写获取信号量。读写信号量可以提高内核中的并发度,并改善了整个系统的性能。
内核以严格的FIFO顺序处理等待读写信号量的所有进程。如果读者或写者进程发现信号量关闭,这些进程就被插入到信号量等待队列链表的末尾。当信号量被释放时,就检查处于等待队列链表第一个位置的进程。第一个进程常被唤醒。如果是一个写者进程,等待队列上其他的进程就继续睡眠。如果是一个读者进程,那么紧跟第一个进程的其他所有读者进程也被唤醒并获得锁。不过,在写者进程之后排队的读者进程继续睡眠。
每个读写信号量都是由rw_semaphore结构描述的,它包含下列字段:
/*
* the semaphore definition
*/
struct rw_semaphore {
signed long count;
#define RWSEM_UNLOCKED_VALUE 0x00000000
#define RWSEM_ACTIVE_BIAS 0x00000001
#define RWSEM_ACTIVE_MASK 0x0000ffff
#define RWSEM_WAITING_BIAS (-0x00010000)
#define RWSEM_ACTIVE_READ_BIAS RWSEM_ACTIVE_BIAS
#define RWSEM_ACTIVE_WRITE_BIAS (RWSEM_WAITING_BIAS + RWSEM_ACTIVE_BIAS)
spinlock_t wait_lock;
struct list_head wait_list;
#if RWSEM_DEBUG
int debug;
#endif
};
## count字段:存放两个16位计数器。其中,最高16位计数器以二进制补码形式存放非等待写者进程的总数(0或1)和等待的写内核控制路径数。最低16位计数器存放非等待的读者和写者进程的总数。
## wait_list字段:指向等待进程的链表。链表中的每个元素都是一个rwsem_waiter结构,该结构包含一个指针和一个标志,指针指向睡眠进程的描述符,标志表示进程是为读需要信号量还是为写需要信号量。
## wait_lock字段:一个自旋锁,用于保护等待队列链表和rw_semaphore结构本身。
init_rwsem()函数初始化rw_semaphore结构,即把count字段置为0,wait_lock自旋锁置为未锁,而把wait_list置为空链表。
down_read()和down_write()函数分别为读或写获取信号量。同样,up_read()和up_write()函数为读或写释放以前获取的读写信号量。down_read_trylock()和down_write_trylock()函数分别类似于down_read()和down_write()函数,但是,在信号量忙的情况下,它们不阻塞进程。最后,函数downgrade_write()自动把写锁转换成读锁。
对于前面提及的5个函数,其实现思想同信号量有着相同的设计思想。
禁止本地中断
确保一组内核语句被当做一个临界区处理的主要机制之一就是中断禁止。即使当硬件设备产生了一个IRQ信号时,中断禁止也让内核控制路径继续执行。因此,这就提供了一种有效的方式,确保中断处理程序访问的数据结构也受到保护。然而,禁止本地中断并不保护运行在另一个CPU上的中断处理程序对数据结构的并发访问,因此,在多处理器系统上,禁止本地中断通常与自旋锁结合使用。
宏local_irq_disable()使用cli汇编语言指令关闭本地CPU上的中断,宏local_irq_enable()函数使用sti汇编语言指令打开被关闭的中断。汇编语言指令cli和sti分别清除和设置eflags控制寄存器的IF标志。如果eflags寄存器的IF标志被清零,宏irqs_disabled()产生等于1的值;如果IF标志被设置,该宏也产生为1的值。
保存和恢复eflags的内容是分别通过宏local_irq_save()和local_irq_restore()宏来实现的。local_irq_save宏把eflags寄存器的内容拷贝到一个局部变量中,随后用cli汇编语言指令把IF标志清零。在临界区的末尾,宏local_irq_restore恢复eflags原来的内容。因此,只有在这个控制路径发出cli汇编指令之前,中断被激活的情况下,中断才处于打开状态。
/* interrupt control.. */
#define local_save_flags(x) do { typecheck(unsigned long,x); __asm__ __volatile__("pushfl ; popl %0":"=g" (x): /* no input */); } while (0)
#define local_irq_restore(x) do { typecheck(unsigned long,x); __asm__ __volatile__("pushl %0 ; popfl": /* no output */ :"g" (x):"memory", "cc"); } while (0)
#define local_irq_disable() __asm__ __volatile__("cli": : :"memory")
#define local_irq_enable() __asm__ __volatile__("sti": : :"memory")
/* For spinlocks etc */
#define local_irq_save(x) __asm__ __volatile__("pushfl ; popl %0 ; cli":"=g" (x): /* no input */ :"memory")
禁止和激活可延迟函数
可延迟函数可能在不可预知的时间执行(实际上是在硬件中断程序结束时)。因此,必须保护可延迟函数访问的数据结构使其避免竞争条件。
我们前面在”中断处理”提到,在由内核执行的几个任务之间有些不是紧急的的;在必要情况下它们可以延迟一段时间。一个中断处理程序的几个中断服务例程之间是串行执行的,并且通常在一个中断的处理程序结束前,不应该再次出现此中断。相反,可延迟函数可以在开中断的情况下执行。把可延迟函数从中断处理程序中抽出来有助于使内核保持较短的响应时间。这对于那些期望它们的中断能在几毫秒内得到处理的”急迫”应用来说是非常重要的。
Linux2.6是通过两种非紧迫、可中断内核函数来实现这种机制的:可延迟函数和工作队列。
软中断和tasklet有密切的关系,tasklet是在软中断之上实现。事实上,出现在内核代码中的术语”软中断”常常表示可延迟函数的所有种类。另外一种被广泛使用的术语是”中断上下文”:表示内核当前正执行一个中断处理程序或一个可延迟函数。
软中断的分配是静态的,而tasklet的分配和初始化可以在运行是进行。软中断可以并发地运行在多个CPU上。因此,软中断是可重入函数而且必须明确地使用自旋锁保护其数据结构。tasklet不必担心这些问题,因为内核对tasklet的执行了更加严格的控制。相同类型的tasklet总是被串行地执行,换句话说就是:不能在两个CPU上同时运行相同类型的tasklet。但是,类型不同的tasklet可以在几个CPU上并发执行。tasklet的串行化使tasklet函数不必是可重入的,因此简化了设备驱动程序开发者的工作。
可延迟函数实现见实时测量一节。
一般而言,在可延迟函数上可以执行四种操作:
初始化
定义一个新的可延迟函数,这个操作通常在内核自身初始化或加载模块时进行。
激活
标记一个可延迟函数为”挂起”,激活可以在任何时候进行。
屏蔽
有选择地屏蔽一个可延迟函数,这样,即使它被激活,内核也不执行它。禁止可延迟函数有时是必要的。
执行
执行一个挂起的可延迟函数和同类型的其它所有挂起的可延迟函数,执行是在特定的时间进行的。
激活和执行总是捆绑在一起,由给定CPU激活的一个可延迟函数必须在同一个CPU上执行。把可延迟函数绑定在激活CPU上从理论上说可以充分利用CPU的硬件高速缓存。毕竟,可以想象,激活的内核线程访问的一些数据结构,可延迟函数也可能会使用。然后,当可延迟函数运行时,因为它的执行可以延迟一段时间,因此相关高速缓存行很可能就不再在高速缓存中了。此外,把一个函数绑定在一个CPU上总是有潜在”危险的”操作,因为一个CPU可能忙死而其它CPU又无所事事。
禁止可延迟函数在一个CPU上执行的一种简单方式就是禁止在那个CPU上的中断。因为没有中断处理程序被激活,因此,软中断操作就不能异步地开始。
然而,内核有时需要只禁止可延迟函数而不禁止中断。通过操纵当前thread_info描述符preempt_count字段中存放的软中断计数器,可以在本地CPU上激活或禁止可延迟函数。如果软中断计数器是正数,do_softirq()函数就不会执行软中断,而且,因为tasklet在软中断之前被执行,把这个计数器设置为大于0的值,由此禁止了在给定CPU上的所有可延迟函数和软中断的执行。
宏local_bh_disable()给本地CPU的软中断计数器加1,而函数local_bh_enable()从本地CPU的软中断计数器中减掉1。内核因此能使用几个嵌套的local_bh_disable调用,只有宏local_bh_enable与第一个local_bh_disable调用相匹配,可延迟函数才再次被激活。
递减软中断计数器后,local_bh_enable()执行两个重要的操作以有助于保证适时地执行长时间等待的线程:
1、检查本地CPU的preempt_count字段中硬中断计数器和软中断计数器,如果这两个计数器的值都等于0而且有挂起的软中断要执行,就调用do_softirq()来激活这些软中断。
2、检查本地CPU的TIF_NEED_RESCHED标志是否被设置,如果是,说明进程切换请求是挂起的,因此调用preempt_schedule()函数。
对内核数据结构的同步访问
在前文,我们详细介绍了内核所提供的几种同步原语以保护共享数据结构避免竞争条件。系统性能可能随所选择的同步原语种类的不同而有很大变化。通常情况下,内核开发者采用下述由经验得到的法则:把系统中的并发度保持在尽可能高的程度。
系统中的并发度取决于两个主要因素:
* 同时运转的I/O设备数;
* 进行有效工作的CPU数。
为了使I/O吞吐量最大化,应该使中断禁止保持在很短的时间。当中断被禁止时,由I/O设备产生的IRQ被PIC暂时忽略,因此,就没有新的活动在这种设备上开始。
为了有效地利用CPU,应该尽可能避免使用基于自旋锁的同步原语。当一个CPU执行紧指令循环等待自旋锁打开时,是在浪费宝贵的机器周期。同时,由于自旋锁对硬件高速缓存的影响而使其对系统的整体性能产生不利影响。
在下列两个例子所展示的情况下,即可以保持较高的并发度,同时也能够达到同步:
* 共享的数据结构是一个单独的整数值,可以把它声明为atomic_t类型并使用原子操作对其更新。原子操作比自旋锁和中断禁止操作都快,只有在几个内核控制路径同时访问这个数据结构时速度才会慢下来。
* 把一个元素插入到共享链表的操作绝不是原子的,因为这至少涉及两个指针赋值。不过,内核有时并不用锁或禁止中断就可以执行这种插入操作。考虑这样一种情况,系统调用服务例程把新元素插入到一个简单链表中,而中断处理程序或可延迟函数异步地查看该链表。
在C语言中,插入是通过下面的指针赋值来实现的:
new->next = list_element->next;
list_element->next = new;
在汇编语言中,插入简化为两个连续的原子指令。第一条指令建立new元素的next指针,但不修改链表。因此,如果中断处理程序在第一条指令和第二条指令执行的中间查看这个链表,看到的就是没有新元素的链表。如果该处理程序在第二条指令执行之后查看链表,就会看到有新元素的链表。关键是,在任一种情况下,链表都是一致的且处于未损坏状态。然而,只有在中断处理程序不修改链表的情况下才能确保这种完整性。如果修改了链表,那么在new元素内刚刚设置的next指针就可能变为无效。
然而,上面的两个赋值操作的顺序不能被编译器或CPU控制器改变,所以可以添加内存屏障来实现写顺序控制:
new->next = list_element->next;
wmb();
list_element->next = new;
在自旋锁、信号量及中断禁止之间选择
前面我们介绍了两个例子,这两个例子实现了高并发高同步,但是,实际遇到的问题往往复杂许多,这个时候,我们就必须使用信号量、自旋锁、中断禁止和软中断禁止来实现并发同步。一般来说,同步原语的选择取决于访问数据结构的内核控制路径的种类。
| 访问数据结构的内核控制路径 | 单处理器保护 | 多处理器进一步保护 |
| 异常 | 信号量 | 无 |
| 中断 | 本地中断禁止 | 自旋锁 |
| 可延迟函数 | 无 | 无或自旋锁(见下表) |
| 异常与中断 | 本地中断禁止 | 自旋锁 |
| 异常与可延迟函数 | 本地软中断禁止 | 自旋锁 |
| 中断与可延迟函数 | 本地中断禁止 | 自旋锁 |
| 异常、中断与可延迟函数 | 本地中断禁止 | 自旋锁 |
1、保护异常所访问的数据结构
当一个数据结构仅由异常处理程序访问时,竞争条件通常是易于理解也易于避免的。最常见的产生同步问题的异常就是系统调用服务例程。在这种情况下,CPU运行在内核态而为用户态程序提供服务。因此,仅由异常访问的数据结构通常表示一种资源,可以分配给一个或多个进程。
竞争条件可以通过信号量避免,因为信号量原语允许进程睡眠到资源变为可用。注意,信号量工作方式在单处理器系统和多处理器系统上完全相同。
内核抢占不会引起太大的问题。如果一个拥有信号量的进程是可以被抢占的,运行在同一个CPU上的新进程就可能试图获得这个信号量。在这种情况下,让新进程处于睡眠状态,而且原来拥有信号量的进程最终会释放信号量。只有在访问每CPU变量的情况下,必须显式地禁用内核抢占。
2、保护中断所访问的数据结构
假定一个数据结构仅被中断处理程序的“上半部”访问,那么,每个中断处理程序都相对自己串行地执行,也就是说,中断服务例程本身不能同时多次运行,因此,访问数据结构就无需任何同步原语。
但是,如果多个中断处理程序访问一个数据结构,情况就有所不同了。一个处理程序可以中断另一个处理程序,不同的中断处理程序可以在多处理器系统上同时运行。没有同步,共享的数据结构就很容易被破坏。
在单处理器系统上,必须通过在中断处理程序的所有临界区上禁止中断来避免竞争条件。只能用这种方式进行同步,因为其他的同步原语都不能完成这件事。信号量能够阻塞进程,因此,不能用在中断处理程序上。另一方面,自旋锁可能使系统冻结:如果访问数据结构的处理程序被中断,它就不能释放锁,因此,新的中断处理程序在自旋锁的紧循环上保持等待。
在多处理器系统上,其要求更加苛刻。不能简单地通过禁止本地中断来避免竞争条件。事实上,即使在一个CPU上禁止了中断,中断处理程序还可以在其他CPU上执行。避免竞争条件的最简单的方法是禁止本地中断,并获取保护数据结构的自旋锁或读写自旋锁。注意,这些附加的自旋锁不能冻结系统,因为即使中断处理程序发现锁关闭,在另一个CPU上拥有锁的中断处理程序最终也会释放这个锁。
Linux使用了几个宏,把本地中断禁止与激活同自旋锁结合起来。


3、保护由可延迟函数访问的数据结构
只被可延迟函数访问的数据结构的保护主要取决于可延迟函数的种类。
在单处理器系统上,不存在竞争条件,这是因为可延迟函数的执行总是在一个CPU上串行执行,也就是说,一个可延迟函数不会被另一个可延迟函数中断。因此,不需要同步原语。
在多处理器系统上,几个可延迟函数的并发运行导致了竞争的存在。
表:在SMP上可延迟函数访问的数据结构所需的保护
| 访问数据结构的可延迟函数 | 保护 |
| 软中断 | 自旋锁 |
| 一个tasklet | 无 |
| 多个tasklet | 自旋锁 |
由软中断访问的数据结构必须受到保护,通常使用自旋锁进行保护,因为一个软中断可以在两个或多个CPU上并发运行。相反,仅由一个tasklet访问的数据结构不需要保护,因为同种tasklet不能并发运行,但是,如果数据结构被几种tasklet访问,那么,就必须对数据结构进行保护。
为什么要使用软中断?
软中断作为下半部机制的代表,是随着SMP(share memory processor)的出现应运而生的,它也是tasklet实现的基础(tasklet实际上只是在软中断的基础上添加了一定的机制)。它的特性包括:
a)产生后并不是马上可以执行,必须要等待内核的调度才能执行。软中断不能被自己打断,只能被硬件中断打断(上半部)。
b)可以并发运行在多个CPU上(即使同一类型的也可以)。所以软中断必须设计为可重入的函数(允许多个CPU同时操作),因此也需要使用自旋锁来保护其数据结构。
为什么要使用tasklet?(tasklet和软中断的区别)
由于软中断必须使用可重入函数,这就导致设计上的复杂度变高,作为设备驱动程序的开发者来说,增加了负担。而如果某种应用并不需要在多个CPU上并行执行,那么软中断其实是没有必要的。因此诞生了弥补以上两个要求的tasklet。它具有以下特性:
a)一种特定类型的tasklet只能运行在一个CPU上,不能并行,只能串行执行。
b)多个不同类型的tasklet可以并行在多个CPU上。
c)软中断是静态分配的,在内核编译好之后,就不能改变。但tasklet就灵活许多,可以在运行时改变(比如添加模块时)。
tasklet是在两种软中断类型的基础上实现的,因此如果不需要软中断的并行特性,tasklet就是最好的选择。
4、保护由异常和中断访问的数据结构
对于由异常处理程序(如系统调用服务例程)和中断处理程序访问的数据结构,通常采用如下策略:
在单处理器系统上,竞争条件的防止是相当简单的,因为中断处理程序不是可重入的且不能被异常中断。只要内核以本地中断禁止访问数据结构,内核在访问数据结构的过程中就不会被中断。不过,如果数据结构正好是被一种中断处理程序访问,那么,中断处理程序不用禁止本地中断就可以自由访问数据结构。
在多处理器系统上,必须关注异常和中断在其他CPU上的并发执行。本地中断禁止外还必须外加自旋锁,强制并发的内核控制路径进行等待,直到访问数据结构的处理程序完成自己的工作。
有时,用信号量代替自旋锁可能更好。因为中断处理程序不能被挂起,它们必须用紧循环和down_trylock()函数获得信号量;对于中断处理程序来说,信号量起的作用本质上与自旋锁一样。另一方面,系统调用服务例程可以在信号量忙是挂起调用进程。
5、保护由异常和可延迟函数访问的数据结构
异常和可延迟函数都访问的数据结构与异常和中断访问的数据结构处理方式类似。事实上,可延迟函数本质上是由中断的出现激活的,而可延迟函数执行时不可能产生异常。因此,把本地中断禁止与自旋锁结合起来就可以了。
异常处理程序可以调用local_bh_disable()宏简单地禁止可延迟函数,而不禁止本地中断。仅禁止可延迟函数比禁止中断更可取,因为中断还可以继续在CPU上得到服务。在每个CPU上可延迟函数的执行被串行化,不存在竞争条件。
同样,在多处理器系统上,要用自旋锁确保在任何时候只有一个内核控制路径访问数据结构。
6、保护由中断和可延迟函数访问的数据结构
这种情况类似于中断和异常处理程序访问的数据结构。当可延迟函数运行时可能产生中断,但是,可延迟函数不能阻止中断处理程序。因此,必须通过在可延迟函数执行期间禁用本地中断来避免竞争条件。不过,中断处理程序可以随意访问被可延迟函数访问的数据结构而不用关中断,前提是没有其他的中断处理程序访问这个数据结构。
在多处理器系统上,还是需要自旋锁禁止对多个CPU上数据结构的并发访问。
7、保护由异常、中断和可延迟函数访问的数据结构
类似前面的情况,禁止本地中断和获取自旋锁几乎总是避免竞争条件所必需的。但是,没有必要显式地禁止可延迟函数,因为当中断处理程序终止执行时,可延迟函数才能被实质激活,因此,禁止本地中断就可以了。
避免竞争条件的实例
人们总是期望内核开发者确定和解决由内核控制路径的交错执行所引起的同步问题。但是,避免竞争条件是一项艰巨的任务,因为这需要对内核的各个成分如何相互作用有一个清楚的理解。
引用计数器
引用计数器广泛地用在内核中以避免由于资源的并发分配和释放而产生的竞争条件。引用计数器(reference counter)只不过是一个atomic_t计数器,与特定的资源,如内存页、模块或文件相关。当内核控制路径开始使用资源时就原子地减少计数器的值,当内核控制路径使用完资源时就原子地增加计数器的值。当引用计数器变为0时,说明该资源未被使用,如有必要,就释放该资源。
大内核锁
大内核锁(Big Kernel Lock)也叫全局内核锁或BKL。其用一个kernel_sem的信号量来实现,但是,其比简单的信号量要复杂一些。
每个进程描述符都含有lock_depth字段,这个字段允许同一进程几次获取大内核锁。因此,对大内核锁两次连续的请求不挂起处理器(相对于普通自旋锁)。如果进程未获得过锁,则这个字段的值为-1;否则,这个字段的值加1,表示已经请求了多少次锁。lock_depth字段对中断处理程序、异常处理程序及可延迟函数获取大内核锁都是至关重要的。如果没有这个字段,那么,在当前进程已经拥有大内核锁的请况下,任何试图获得这个锁的异步函数都可能产生死锁。
lock_kernel()和unlock_kernel()内核函数用来获得和释放大内核锁。
lock_kernel()等价于:
depth = current->lock_depth + 1;
if(depth == 0)
down(&kernel_sem);
current->lock_depth = depth;
unlock_kernel()等价于:
if(--current->lock_depth < 0)
up(&kernel_sem);
BKL(大内核锁)是一个全局自旋锁,使用它主要是为了方便实现从Linux最初的SMP过度到细粒度加锁机制。
BKL的特性:
* 持有BKL的任务仍然可以睡眠 。因为当任务无法调度时,所加的锁会自动被抛弃;当任务被调度时,锁又会被重新获得。当然,并不是说,当任务持有BKL时,睡眠是安全的,紧急是可以这样做,因为睡眠不会造成任务死锁。
* BKL是一种递归锁。一个进程可以多次请求一个锁,并不会像自旋锁那么产生死锁。
* BKL可以在进程上下文中。
* BKL是有害的。
在内核中不鼓励使用BKL。一个执行线程可以递归的请求锁lock_kernel(),但是释放锁时也必须调用同样次数的unlock_kernel()操作,在最后一个解锁操作完成之后,锁才会被释放。
内存描述符读写信号量
mm_struct类型的每个内存描述符在mmap_sem字段中都包含了自己的信号量。由于几个轻量级进程之间可以共享一个内存描述符,因此,信号量保护这个描述符以避免可能产生的竞争条件。
例如,让我们假设内核必须为某个进程创建或扩展一个内存区。为了做到这一点,内核调用do_mmap()函数分配一个新的vm_area_struct数据结构。在分配的过程中,如果没有可用的空闲内存,而共享同一内存描述符的另一个进程可能在运行,那么当前进程可能被挂起。如果没有信号量,那么需要访问内存描述符的第二个进程的任何操作都可能会导致严重的数据崩溃。
这种信号量是作为读写信号量来实现的,因为一些内核函数,如缺页异常处理程序只需要描述内存描述符。
slab高速缓存链表的信号量
slab高速缓存描述符链表是通过cache_chain_sem信号量保护的,这个信号量允许互斥地访问和修改链表。
当kmem_cache_create()在链表中增加一个新元素,而kmem_cache_shrink()和kmem_cache_reap()顺序地扫描整个链表时,可能产生竞争条件。然而,在处理中断时,这些函数从不被调用,在访问链表时它们也从不阻塞。由于内核是支持抢占的,因此这种信号量在多处理器系统和单处理器系统中都会起作用。
索引节点的信号量
Linux把磁盘文件的信息存放在一种叫做索引节点(inode)的内存对象中。相应的数据结构也包括自己的信号量,存放在l_sem字段中。
在文件系统的处理过程中会出现很多竞争条件。实际上,磁盘上的每个文件都是所有用户共有的资源,因为所有进程可能会存取文件的内容、修改文件名或文件位置、删除或复制文件等。例如,让我们假设一个进程在显示某个目录所包含的文件。由于每个磁盘操作都可能会阻塞,因此即使在单处理器系统中,当第一个进程正在执行显示操作的过程中,其他进程也可能存取同一目录并修改它的内容。或者,两个不同的进程可能同时修改同一目录。所有这些竞争条件都可以通过用索引节点信号量保护目录文件来避免。
只要一个程序使用了两个或多个信号量,就存在死锁的可能,因为两个不同的控制路径可能互相死等着释放信号量。一般来说,Linux在信号量请求上很少会发生死锁问题,因为每个内核控制路径通常一次只需要获得一个信号量。然而,在有些情况下,内核必须获得两个或多个信号量锁。索引节点信号量倾向于这种情况,例如,在rename()系统调用的服务例程中就会发生上述情况。在这种情况下,操作涉及两个不同的索引节点,因此,必须采用两个信号量。为了避免这样的死锁,信号量的请求按预先确定的地址顺序进行。