MPI 集合通信例子
Message-Passing-Interface:
是用于在分布式内存环境中为并行计算机编写可移植的代码。
我们有时候会使用mpi_send(mpi_recv)来进行点对点通信,从而实现从一个节点发送数据给另一个节点的功能。但是,有时候,我们需要从一个节点往其他所有节点都要发送东西,这个时候就会用到集合通信。
使用MPI_Bcast进行广播

从图中可以看出,MPI_Bcast会给所有节点发送相同的数据。
MPI_Bcast(
void* data,
int count,
MPI_Datatype datatype,
int root,
MPI_Comm communicator)第一个参数data就是所要发送的数据,这个数据包含count个 datatype类型,root是指广播的节点,communicator是指通信子。
使用MPI_Scatter
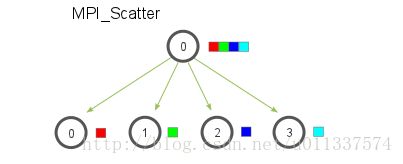
和MPI_Bcast不同的是,MPI_scatter发送不同的数据给不同的节点。
MPI_Scatter(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)第一个参数send_data是指root节点要发送的数据,然后要发送send_count个send_datatype类型的数据给每个节点。如果send_count是1,send_datatype是MPI_INT,root为0,那么就是0号节点拿到数组的第一个元素,1号节点拿到数组的第二个元素,以此类推。如果send_count是2,那就是0号几点拿到第一个和第二个元素,二号节点拿到第三个和第四个元素,以此类推。
recv_data,就是每个节点接收数据的缓冲区,每个节点要收到recv_count个recv_datatype的元素。
使用MPI_Gather
MPI_Gather是和MPI_Scatter相反的过程。

MPI_Gather(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)对于MPI_Gather来说,只有root节点需要有一个有效的接收缓冲区,其他的节点可以将recv_data设置为NULL。主要一点是,recv_count是每个节点要接收的元素数量。
例子
这个例子就是将一个结构体使用MPI_Bcast发送到其他的节点,然后使用MPI_Gather再从其它节点收回来。
#include 结果:

值得注意的是,这个在广播到其他节点的时候,先发送了一个长度过去,告诉接受的节点要接收多少数据,如果发送的长度是个固定值的话,这个地方可以省略,如果不是固定值的话,可以这么做。
示例代码下载