Accumulo入门手册
1。介绍
Apache Accumulo的是一个高度可扩展的结构化存储,基于谷歌的BigTable。Accumulo是用Java编写的,并在Hadoop分布式文件系统 (HDFS),这是流行的Apache Hadoop项目的一部分工作。Accumulo支持高效存储和检索的结构化数据,包括查询范围,并提供支持使用Accumulo表作为输入和输出的 MapReduce作业。
Accumulo设有自动负载平衡和分区,数据压缩和细粒度的安全标签。
2。Accumulo设计
2.1。数据模型
Accumulo提供了丰富的数据模型不是简单的键 - 值存储,但不是完全的关系数据库。数据表示为键 - 值对,其中键和值是由以下元素:
| Key |
Value |
|
| Row ID |
Column |
Timestamp |
| Family |
Qualifier |
Visibility |
键和值的所有元素都表示为字节数组时间戳,这是一个长期的除外。Accumulo各种键的元素和字典升序排列。时间戳以递减顺序排序,首先出现在一个连续的扫描,以便以后的版本相同的密钥。表由一组排序键 - 值对。
2.2。体系结构
accumulo是一个分布式数据存储和检索系统,因此由一些建筑元件,其中一些许多单独服务器上运行的。大部分的工作确实涉及Accumulo保持一定性能的数据,如组织,可用性和完整性,在许多商品级机。
2.3。组件
一个实例的Accumulo包括的许多TabletServers,一个垃圾收集过程中,一台主服务器和多个客户端。
2.3.1。tablet服务器
TabletServer 管理一些子集的所有片(分区表)。这包括接收从客户端中写道,坚持预写日志,写入新的键值对排序在内存中,定期冲洗排序键 - 值对HDFS中的新文件,并响应来自客户端的读取,形成一个合并排序查看所有键和值从创建和排序的内存中存储的所有文件。
TabletServers执行恢复以前的服务器失败,重新应用发现任何写在预写日志平板平板。
2.3.2。垃圾收集器
Accumulo进程将共享存储在HDFS中的文件。每隔一段时间,垃圾收集器将确定不再需要任何进程的文件,并删除它们。
2.3.3。master
是 负责检测和响应TabletServer失败的Accumulo master。它试图以平衡负载分配药片仔细和指导TabletServers的卸载片,必要时跨TabletServer的。master确保所有分片 被分配到每一个TabletServer,并处理表的创建,修改和删除请求从客户。master也协调启动,正常关机和恢复的变化的预写日志tablet 服务器时失败。
可能会运行多个master。master将选举一个作为master,其他作为备份。
2.3.4。客户
Accumulo包括链接到每一个应用程序的客户端库。客户端库包含逻辑寻找管理某个特定的平板电脑,服务器和通信与TabletServers写入和检索键 - 值对。
2.4。数据管理
Accumulo 存储表中的数据,这是划分成片。片分区行边界,这样一个特定的行的所有列和值一起被发现在同一片剂。主片分配到一个TabletServer的时间。这使 行级交易采取不使用分布式锁或其他一些复杂的同步机制。随着客户的插入和查询数据,机器从集群中添加和删除,主迁移片来保证他们就仍然可以采集和查询负载 平衡群集。
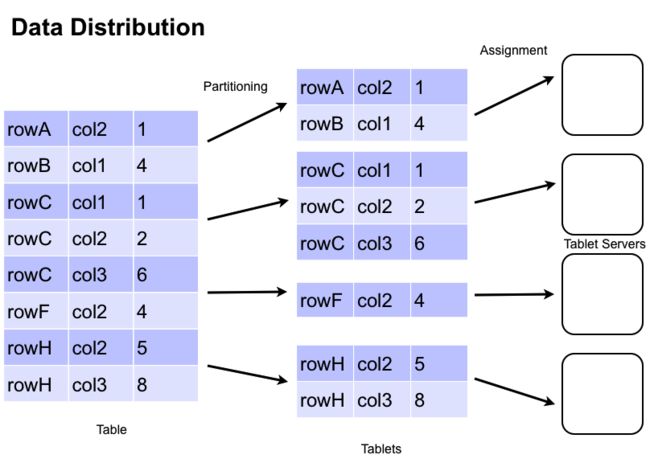
2.5。tablet服务
写 在TabletServer到达时,它被写入到一个预写日志,然后插入称为MemTable中一个排序的数据结构在内存中。当MemTable对达到一定 规模的TabletServer写道排序键 - 值对在HDFS中的文件被称为索引顺序访问方法(ISAM)文件。这个过程被称为一个小压实。然后创建一个新的MemTable中预写日志记录和压实的事 实。
当 一个请求读取数据在TabletServer到达的,TabletServer确实二进制搜索以及整个MemTable中每个ISAM文件在内存中的相关 指标,找到相关的值。如果客户端执行扫描,几个键 - 值对返回给客户端为了从MemTable中ISAM文件集进行合并排序,因为他们是阅读。
2.6。压实
为了管理文件,每片的数量,定期TabletServer的执行主要压实tablet内的文件,其中一些ISAM文件合并成一个文件。最终将被删除以前的文件,由垃圾收集器。这也提供了一个机会,用来彻底删除键 - 值对省略键 - 值对创建新的文件时,删除条目抑制。
2.7。拆分
当 创建一个表,它有一个平板电脑。随着表的增长,其最初的平板电脑最终分裂成两片。它可能是这些药片将迁移到另一台平板电脑服务器。如上表持续增长,及其片 剂将继续分裂和迁移。的决定是基于自动分割片剂的片剂的大小的文件。片剂分割的大小阈值配置的每个表。除了自动分裂,用户可以手动添加的分割点,用来从表 中创建新的片剂。手动分裂一个新表可以并行的读取和写入操作提供更好的初始性能,而无需等待自动分割。
当数据从表中删除,平板电脑可能会萎缩。随着时间的推移,这可能会导致空或小片。为了处理这个问题,片剂合并被引入在1.4 Accumulo。这在后面更详细讨论。
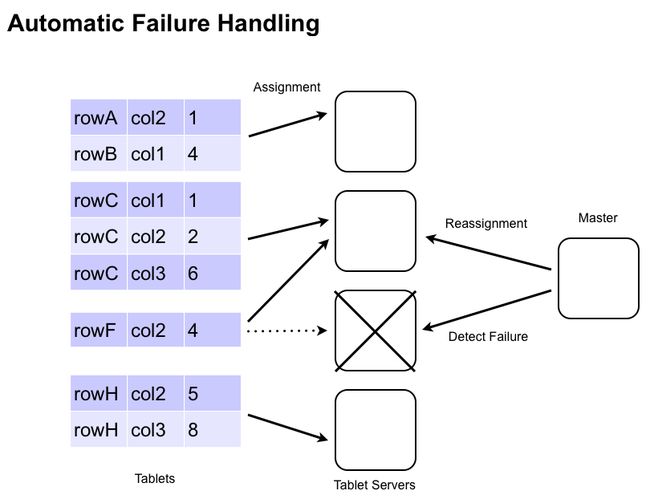
2.8。容错
如果TabletServer失败,法师检测,并自动从故障服务器分配到其他服务器重新分配片。任何键 - 值对,在内存中的时间TabletServer失败自动重新应用预写式日志,以防止丢失任何数据。
法师将协调预写日志复制到HDFS,以便提供给所有tablet服务器日志。为了使回收效率,更新在日志分组的平板电脑。注定的牌位,他们现在被分配给从排序的日志,可以快速申请TabletServers突变。
TabletServer故障都注意到法师的监控页面,通过http://master-address:50095/monitor访问的 。
3。Accumulo shell
Accumulo提供了一个简单的shell,可以用来检查表的内容和配置设置,插入/更新/删除值,更改配置设置。
外壳可以开始下面的命令:
$ACCUMULO_HOME/bin/accumulo shell -u [username]shell会提示输入相应的密码到指定的用户名,然后显示以下提示:
Shell - Apache Accumulo Interactive Shell
-
- version 1.5
- instance name: myinstance
- instance id: 00000000-0000-0000-0000-000000000000
-
- type 'help' for a list of available commands
-3.1。基本管理
Accumulo shell可以用来创建和删除表,以及配置表和实例的具体选项。
root@myinstance> tables
!METADATAroot@myinstance> createtable mytableroot@myinstance mytable>root@myinstance mytable> tables
!METADATA
mytableroot@myinstance mytable> createtable testtableroot@myinstance testtable>root@myinstance testtable> deletetable testtableroot@myinstance>壳牌也可以用来插入更新和扫描表。这是非常有用的检查表。root@myinstance mytable> scanroot@myinstance mytable> insert row1 colf colq value1
insert successfulroot@myinstance mytable> scan
row1 colf:colq [] value1括号内的数值“[]”的知名度标签。由于没有被使用,这是该行空。您可以使用“-ST”扫描到细胞内,也看到时间戳选项。
3.2。表维护
compact命令指示Accumulo安排巩固和删除哪些文件项被删除的表压实。
root@myinstance mytable> compact -t mytable
07 16:13:53,201 [shell.Shell] INFO : Compaction of table mytable
scheduled for 20100707161353EDT该flush命令指示Accumulo写当前内存中的所有条目,对于一个给定的表到磁盘。
root@myinstance mytable> flush -t mytable
07 16:14:19,351 [shell.Shell] INFO : Flush of table mytable
initiated...3.3。用户管理
shell可用于添加,删除,并授予用户特权。
root@myinstance mytable> createuser bob
Enter new password for 'bob': *********
Please confirm new password for 'bob': *********root@myinstance mytable> authenticate bob
Enter current password for 'bob': *********
Validroot@myinstance mytable> grant System.CREATE_TABLE -s -u bobroot@myinstance mytable> user bob
Enter current password for 'bob': *********bob@myinstance mytable> userpermissions
System permissions: System.CREATE_TABLE
Table permissions (!METADATA): Table.READ
Table permissions (mytable): NONEbob@myinstance mytable> createtable bobstable
bob@myinstance bobstable>bob@myinstance bobstable> user root
Enter current password for 'root': *********root@myinstance bobstable> revoke System.CREATE_TABLE -s -u bob
4。写作Accumulo客户端
4.1。运行客户端代码
有多种方式运行的Java代码使用Accumulo的。下面列出的不同的方式来执行客户端代码。
-
使用Java可执行文件
-
使用accumulo脚本
-
使用该工具的脚本
为 了运行客户端代码编写对Accumulo运行,您将需要包括罐子Accumulo取决于你的classpath。Accumulo客户端的代码依赖于 Hadoop和饲养员。对于Hadoop的Hadoop的核心罐子,在Hadoop的lib目录下的所有的罐子,conf目录到classpath中。饲 养员3.3,你只需要添加饲养员罐,也不是什么在饲养员的lib目录。您可以运行下面的命令上的配置Accumulo系统,看看有什么使用它的类路径。
$ACCUMULO_HOME/bin/accumulo classpath运行你的代码的另一种选择是把一个jar文件 $ ACCUMULO_HOME / lib / ext目录。这样做后,你可以使用accumulo的脚本来执行你的代码。例如,如果你创建一个jar含有类com.foo.Client,放置在lib / ext目录,那么你可以使用命令 $ ACCUMULO_HOME / bin中/ accumulo com.foo.Client的执行代码。
如果你正在写的地图减少,访问Accumulo,那么你可以使用的bin / tool.sh的脚本来运行这些作业的工作。查看地图减少的例子。
4.2。连
所有客户端必须先识别Accumulo例如,他们将进行通信。做到这一点的代码如下:
String instanceName = "myinstance";String zooServers = "zooserver-one,zooserver-two"Instance inst = new ZooKeeperInstance(instanceName, zooServers);Connector conn = inst.getConnector("user", "passwd");4.3。写入数据
通过创建对象代表所有更改的列单排突变数据写入到Accumulo的。这些变化是由原子在TabletServer。客户端,然后将它提交给适当的TabletServers到BatchWriter突变。
突变可以创建这样的:
Text rowID = new Text("row1");Text colFam = new Text("myColFam");Text colQual = new Text("myColQual");ColumnVisibility colVis = new ColumnVisibility("public");long timestamp = System.currentTimeMillis();Value value = new Value("myValue".getBytes());Mutation mutation = new Mutation(rowID);
mutation.put(colFam, colQual, colVis, timestamp, value);4.3.1。BatchWriter
高度优化的BatchWriter送突变的多个TabletServers和自动批次突变摊销网络开销相同TabletServer注定。必须小心避免的任何传递给BatchWriter对象改变的内容,因为它保持内存中的对象,而配料。
添加到BatchWriter突变是这样的:
long memBuf = 1000000L; // bytes to store before sending a batchlong timeout = 1000L; // milliseconds to wait before sendingint numThreads = 10;BatchWriter writer =
conn.createBatchWriter("table", memBuf, timeout, numThreads)
writer.add(mutation);
writer.close();一个例子可以发现在使用批处理写 accumulo/docs/examples/README.batch
4.4。读取数据
Accumulo优化,快速检索与给定键关联的值,并有效返回连续键及其关联值范围。
4.4.1。扫描器
检索数据,客户端使用扫描仪,它的作用像一个迭代器键和值。扫描仪可以被配置在特定的键来启动和停止,并返回可用的列的一个子集。
// specify which visibilities we are allowed to seeAuthorizations auths = new Authorizations("public");Scanner scan =
conn.createScanner("table", auths);
scan.setRange(new Range("harry","john"));
scan.fetchFamily("attributes");for(Entry entry : scan) { String row = entry.getKey().getRow(); Value value = entry.getValue();
} 4.4.2。隔离式扫描仪
Accumulo支持能力提出了一个孤立的观点的行扫描时。有三种可能的方式,行可能会改变accumulo:
-
一个突变应用于一个表
-
或大或小的压实的一部分执行的迭代器
-
批量导入新文件
隔 离担保,所有这些操作的行上所做的更改或无被看见。使用IsolatedScanner孤立的观点的一个accumulo表取得。当使用常规的扫描仪,它 是可以看到一排的非孤立的观点。例如,如果一个突变修改分三路,它可能是你只会看到两个修改。对于隔离扫描仪要么全部三个的变化被视为或无。
该IsolatedScanner缓冲行客户端上的,所以不会大排平板服务器崩溃。默认情况下,行缓存在内存中,但用户可以方便地提供自己的缓冲区,如果他们想缓冲到磁盘时行大。
举一个例子,看看
examples/simple/src/main/java/org/apache/accumulo/examples/simple/isolation/InterferenceTest.java
4.4.3。BatchScanner
对于某些类型的访问,它是更有效的同时检索几个范围。出现这种情况,当访问一组不连续的行,其ID已检索,例如从二级索引。
类 似该BatchScanner配置到扫描器,它可以被配置为检索可用的列的一个子集,但是,而不是通过一个单一的范围,BatchScanners接受一 组范围。重要的是要注意,键由BatchScanner返回键以排序的顺序,因为流式传输是从多个TabletServers平行。
ArrayList ranges = new ArrayList();// populate list of ranges ...BatchScanner bscan =
conn.createBatchScanner("table", auths, 10);
bscan.setRanges(ranges);
bscan.fetchFamily("attributes");for(Entry entry : scan)
System.out.println(entry.getValue()); 一个例子可以发现在accumulo/docs/examples/README.batch
4.5。代理
代理API允许Java以外的语言与Accumulo互动。在代码库中提供代理服务器和一个客户端可以进一步产生。
4.5.1。Prequisites
代理服务器可以住在任何节点上的基本客户端API将工作。这意味着它必须是能够沟通的法师,饲养员,NameNode的数据节点。代理客户端只需要与代理服务器进行通信的能力。
4.5.2。组态
代理服务器的配置选项里面住的属性文件。最起码,你需要提供以下属性:
protocolFactory=org.apache.thrift.protocol.TCompactProtocol$Factory
tokenClass=org.apache.accumulo.core.client.security.tokens.PasswordToken
port=42424
instance=test
zookeepers=localhost:2181在你的发行版,你可以找到一个示例配置文件:
$ACCUMULO_HOME/proxy/proxy.properties这个配置文件示例演示备份代理服务器由MockAccumulo或MiniAccumuloCluster的的abilty。
4.5.3。运行代理服务器
控股配置属性文件创建后,代理服务器就可以开始在Accumulo分布(假设你的属性文件被命名为config.properties中)使用以下命令:
$ACCUMULO_HOME/bin/accumulo proxy -p config.properties4.5.4。创建一个代理客户端
除了安装旧货编译的,你还需要生成客户端代码,语言旧货安装特定语言的库。通常情况下,您的操作系统的软件包管理器就能自动安装这些你在预期的位置,如目录/ usr / lib中/蟒蛇/节俭的site-packages /。
你可以找到节俭文件生成客户端:
$ACCUMULO_HOME/proxy/proxy.thrift生成客户端后,在上述的配置属性指定的端口将被用来连接到服务器。
4.5.5。使用代理客户端
下面的例子已经写在Java和方法签名可能旧货编译器生成客户端时指定的语言不同而略有差别。在初始化一个连接到代理服务器(Apache旧货的文件连接到旧货服务的例子),代理客户机上的方法将可用。要做的第一件事就是登录:
Map password = new HashMap<String,String>();
password.put("password", "secret");ByteBuffer token = client.login("root", password);登录后,返回的令牌将被使用到客户端的后续调用。让我们创建一个表,添加一些数据,表扫描,并删除它。
首先,创建一个表。
client.createTable(token, "myTable", true, TimeType.MILLIS);接下来,添加一些数据:
// first, create a writer on the serverString writer = client.createWriter(token, "myTable", new WriterOptions());// build column updatesMap cells> cellsToUpdate = //...// send updates to the serverclient.updateAndFlush(writer, "myTable", cellsToUpdate);
client.closeWriter(writer);扫描数据和批处理的服务器上返回的结果:
String scanner = client.createScanner(token, "myTable", new ScanOptions());ScanResult results = client.nextK(scanner, 100);for(KeyValue keyValue : results.getResultsIterator()) { // do something with results}
client.closeScanner(scanner);5。客户开发
通常情况下,Accumulo包含许多移动部件。即使是一个单机版的Hadoop的Accumulo需要,动物园管理员,Accumulo高手,tablet服务器等,如果你想写单元测试使用Accumulo的,你需要大量的基础设施到位之前,你的测试可以运行。
5.1。模拟Accumulo
模拟Accumulo用品大部分的客户端API模拟实现。它目前不强制用户,登录权限,等它支持迭代器和组合。请注意,MockAccumulo保存在内存中的所有数据,并不会保留任何数据或设置运行之间。
在正常情况下与Accumulo客户端的交互看起来像这样:
Instance instance = new ZooKeeperInstance(...);Connector conn = instance.getConnector(user, passwordToken);要与MockAccumulo互动时,只需更换ZooKeeperInstance与MockInstance:
Instance instance = new MockInstance();事实上,你可以使用选项-假的Accumulo壳与MockAccumulo:
$ ./bin/accumulo shell --fake -u root -p ''
Shell - Apache Accumulo Interactive Shell
-
- version: 1.5
- instance name: fake
- instance id: mock-instance-id
-
- type 'help' for a list of available commands
-
root@fake> createtable test
root@fake test> insert row1 cf cq value
root@fake test> insert row2 cf cq value2
root@fake test> insert row3 cf cq value3
root@fake test> scan
row1 cf:cq [] value
row2 cf:cq [] value2
row3 cf:cq [] value3
root@fake test> scan -b row2 -e row2
row2 cf:cq [] value2
root@fake test>当测试的Map Reduce作业,你还可以设置的的AccumuloInputFormat和AccumuloOutputFormat类的模拟Accumulo:
AccumuloInputFormat.setMockInstance(job, "mockInstance");
AccumuloOutputFormat.setMockInstance(job, "mockInstance");5.2。mini Accumulo集群
虽 然模拟Accumulo的进行单元测试的客户端API提供了一个轻量级的实施,往往是必要写更现实的终端到终端的整合利用整个生态系统的测试。的迷你 Accumulo集群配置和启动饲养员,初始化Accumulo,并开始主以及一些平板电脑服务器,使这成为可能。它的运行对本地文件系统,而不必启动 HDFS。
启动它,你将需要作为参数提供一个空的目录和根密码:
File tempDirectory = // JUnit and Guava supply mechanisms for creating temp directoriesMiniAccumuloCluster accumulo = new MiniAccumuloCluster(tempDirectory, "password");
accumulo.start();一旦我们有我们的小集群运行,我们将要与客户端API Accumulo:
Instance instance = new ZooKeeperInstance(accumulo.getInstanceName(), accumulo.getZooKeepers());Connector conn = instance.getConnector("root", new PasswordToken("password"));完成后,我们的开发代码,我们想关闭我们MiniAccumuloCluster:
accumulo.stop()// delete your temporary folder6。表配置
Accumulo表中有几个选项来改变默认行为,Accumulo以及存储的数据的基础上提高性能,可以配置。这些措施包括地方团体,约束,盛开的过滤器,迭代器和块缓存。
6.1。地址组
Accumulo套柱家庭支持存储在磁盘上分开,以允许客户端有效地扫描是经常一起使用,以避免扫描列家庭不要求列。地址组设置后,会自动利用扫描仪和BatchScanner操作时,他们的fetchColumnFamilies()方法用于。
默认情况下,表放置到同一个“默认”本地组的所有列家庭。随时可以配置其他地方团体通过shell或编程方式如下:
6.1.1。通过shell的管理地址组
usage: setgroups <group>=<col fam>{,<col fam>}{ <group>=<col fam>{,<col fam>}}
[-?] -t <table>user@myinstance mytable> setgroups group_one=colf1,colf2 -t mytableuser@myinstance mytable> getgroups -t mytable
6.1.2。通过客户端API地址组管理
Connector conn;HashMap<String,Set> localityGroups = new HashMap<String, Set>();HashSet metadataColumns = new HashSet();
metadataColumns.add(new Text("domain"));
metadataColumns.add(new Text("link"));HashSet contentColumns = new HashSet();
contentColumns.add(new Text("body"));
contentColumns.add(new Text("images"));
localityGroups.put("metadata", metadataColumns);
localityGroups.put("content", contentColumns);
conn.tableOperations().setLocalityGroups("mytable", localityGroups);// existing locality groups can be obtained as followsMap> groups =
conn.tableOperations().getLocalityGroups("mytable"); 列的家庭地址组的分配可以在任何时间改变。的物理移动到他们的新地址组的列家庭主要通过定期压实过程,发生在后台持续发生。主要压实,也可如期通过shell立即生效:
user@myinstance mytable> compact -t mytable6.2。约束
Accumulo支持突变在插入时的约束。这可以被用来根据用户定义的策略禁止某些插入。不限突变不符合要求的约束被拒绝,并且发送回客户端。
约束可以通过设置表属性如下:
user@myinstance mytable> constraint -t mytable -a com.test.ExampleConstraint com.test.AnotherConstraint
user@myinstance mytable> constraint -l
com.test.ExampleConstraint=1
com.test.AnotherConstraint=2目前,有没有通用的约束与Accumulo分布。新的约束条件,可以创建通过编写Java类实现org.apache.accumulo.core.constraints.Constraint接口的。
要部署一个新的约束,创建一个jar文件包含的类实施新的约束,并将其放置在lib目录的Accumulo安装。可以添加新的约束罐到Accumulo,不重新启动的情况下启动,但现有的约束类的任何改变需要重新启动Accumulo。
约束的一个例子可以发现在 accumulo/docs/examples/README.constraints相应的代码,根据 accumulo/examples/simple/main/java/accumulo/examples/simple/constraints。
6.3。Bloom过滤器
突变被应用到一个Accumulo表,每片创建几个文件。如果盛开的过滤器被启用,Accumulo将创建并加载到内存中的一个小的数据结构,以确定文件是否包含给定键在打开文件之前。这可以大大加快查找。
为了使盛开的过滤器,壳牌输入以下命令:
user@myinstance> config -t mytable -s table.bloom.enabled=true广泛使用bloom过滤器的例子可以发现在accumulo/docs/examples/README.bloom.。
6.4。迭代器
迭代器提供了一个模块化的机制,用于将要执行的TabletServers功能进行扫描,或者数据压缩。这使用户能够有效地总结,筛选和汇总数据。事实上,内置的单元级别的安全功能和列取使用迭代器来实现。一些有用的迭代器中所提供与Accumulo和中可以找到的 org.apache.accumulo.core.iterators.user包。在每一种情况下,任何自定义的迭代器必须包括在Accumulo classpath中,通常包括一个罐子在$ ACCUMULO_HOME / lib中或 $ ACCUMULO_HOME / lib / ext目录,虽然VFS类加载器允许类路径操纵利用的各种计划,包括网址和HDFS的URI 。
6.4.1。shell设置迭代
迭代器可以配置的桌子上扫描,小型压实和/或主要压实范围。如果迭代实现的OptionDescriber接口,的setiter命令可用于交互的方式提示用户提供值给予必要的选项。
usage: setiter [-?] -ageoff | -agg | -class | - regex |
-reqvis | -vers [-majc] [-minc] [-n ] -p
[-scan] [-t ]
user@myinstance mytable> setiter -t mytable -scan -p 15 -n myiter -class com.company.MyIterator
config命令可以随时用于手动配置了Iterator不实施的OptionDescriber接口的情况下,这是非常有用的迭代器。
config -t mytable -s table.iterator.{scan|minc|majc}.myiter=15,com.company.MyIterator
config -t mytable -s table.iteartor.{scan|minc|majc}.myiter.opt.myoptionname=myoptionvalue
6.4.2。设置迭代编程方式
scanner.addIterator(new IteratorSetting( 15, // priority
"myiter", // name this iterator
"com.company.MyIterator" // class name));
一些迭代器从客户端代码需要额外的参数,如下面的例子:
IteratorSetting iter = new IteratorSetting(...);
iter.addOption("myoptionname", "myoptionvalue");
scanner.addIterator(iter)
表支持独立的迭代器设置被应用在扫描时轻微压实后,而主要压实。对于大多数用途,表格将具有相同的所有三个迭代器设置,以避免不一致的结果。
6.4.3。版本迭代器和时间戳
Accumulo 提供版本的数据管理能力,通过使用时间戳内的关键。由客户端创建的关键,如果没有指定一个时间戳,然后系统将设置时间戳为当前时间。两个键具有相同的 ROWID列,但不同的时间戳被认为是两个版本的相同的密钥。如果两个插入相同的ROWID,列和时间戳制成accumulo的,则行为是不确定性。
时间戳以递减顺序排序,最新的数据是第一位的。accumulo可以配置为返回前k个版本,或版本高于给定的日期。默认是返回一个最新版本。
是可以改变的通过改变VersioningIterator选项如下的表的版本政策:
user@myinstance mytable> config -t mytable -s table.iterator.scan.vers.opt.maxVersions=3
user@myinstance mytable> config -t mytable -s table.iterator.minc.vers.opt.maxVersions=3
user@myinstance mytable> config -t mytable -s table.iterator.majc.vers.opt.maxVersions=3
创建表时,默认情况下,它的配置,使用VersioningIterator和保持一个版本。可以创建一个表不VersioningIterator NDI选项在shell。的Java API还具有以下的方法
connector.tableOperations.create(String tableName, boolean limitVersion)
逻辑时间
Accumulo 1.2引入逻辑时间的概念。这确保由accumulo设置时间戳永远向前。这将有助于避免出现问题由TabletServers引起不同的时间设置。每片 计数器时间邮票每一个突变的基础上给出了独特的一。当使用时间以毫秒为单位,如果两件事情同一毫秒内到达,然后都收到相同的时间戳。当使用时间(以毫秒为 单位),将accumulo设定的时间始终前进,永不后退。
表可以配置为使用逻辑在创建时的时间戳如下:
user@myinstance> createtable -tl logical
删除
删除特殊键accumulo得到沿将所有其他数据排序。当删除键被插入时,accumulo将不显示任何有时间戳小于或等于删除键。在主要压实,年纪比任何键删除键被省略创建的新文件,并省略键作为正规的垃圾收集过程的一部分从磁盘上删除。
6.4.4。过滤器
键 -值对的一组扫描时,它是通过一个过滤器的使用,可以将任意的过滤策略。过滤器是只返回键-值对满足过滤逻辑的迭代器类型。Accumulo有几个内置的 过滤器,可以配置任何表:ColumnAgeOff AgeOff,时间戳,NoVis,和正则表达式。可以添加更多通过编写一个Java类扩展 org.apache.accumulo.core.iterators.Filter类。
该AgeOff过滤器可以被配置为删除的数据比目标日期或一个固定的时间量从本。下面的例子设置一个表中删除插入超过30秒前的一切:
user@myinstance> createtable filtertest
user@myinstance filtertest> setiter -t filtertest -scan -minc -majc -p 10 -n myfilter -ageoff
AgeOffFilter removes entries with timestamps more than milliseconds old
----------> set org.apache.accumulo.core.iterators.user.AgeOffFilter parameter
negate, default false keeps k/v that pass accept method, true rejects k/v
that pass accept method:
----------> set org.apache.accumulo.core.iterators.user.AgeOffFilter parameter
ttl, time to live (milliseconds): 3000
----------> set org.apache.accumulo.core.iterators.user.AgeOffFilter parameter
currentTime, if set, use the given value as the absolute time in milliseconds
as the current time of day:
user@myinstance filtertest>
user@myinstance filtertest> scan
user@myinstance filtertest> insert foo a b c
user@myinstance filtertest> scan
foo a:b [] c
user@myinstance filtertest> sleep 4
user@myinstance filtertest> scan
user@myinstance filtertest>
看到一个表的迭代器设置,使用方法:
user@example filtertest> config -t filtertest -f iterator
---------+---------------------------------------------+------------------
SCOPE | NAME | VALUE
---------+---------------------------------------------+------------------
table | table.iterator.majc.myfilter .............. | 10,org.apache.accumulo.core.iterators.user.AgeOffFilter
table | table.iterator.majc.myfilter.opt.ttl ...... | 3000
table | table.iterator.majc.vers .................. | 20,org.apache.accumulo.core.iterators.VersioningIterator
table | table.iterator.majc.vers.opt.maxVersions .. | 1
table | table.iterator.minc.myfilter .............. | 10,org.apache.accumulo.core.iterators.user.AgeOffFilter
table | table.iterator.minc.myfilter.opt.ttl ...... | 3000
table | table.iterator.minc.vers .................. | 20,org.apache.accumulo.core.iterators.VersioningIterator
table | table.iterator.minc.vers.opt.maxVersions .. | 1
table | table.iterator.scan.myfilter .............. | 10,org.apache.accumulo.core.iterators.user.AgeOffFilter
table | table.iterator.scan.myfilter.opt.ttl ...... | 3000
table | table.iterator.scan.vers .................. | 20,org.apache.accumulo.core.iterators.VersioningIterator
table | table.iterator.scan.vers.opt.maxVersions .. | 1
---------+---------------------------------------------+------------------
6.4.5。Combiners
Accumulo允许合路器上配置表和列家庭。合当它应用于跨股份ROWID列家庭和列预选赛任何键关联的值。这是类似MapReduce的减少步骤,应用一些函数与特定键相关联的所有的值。
例如,如果一个加法组合器被配置在桌子上,以下的突变,插入
Row Family Qualifier Timestamp Value
rowID1 colfA colqA 20100101 1
rowID1 colfA colqA 20100102 1
该表将反映只有一个总价值:
rowID1 colfA colqA - 2
合路器可以使用一个表的setiter在shell命令启用。下面就是一个例子。
root@a14 perDayCounts> setiter -t perDayCounts -p 10 -scan -minc -majc -n daycount -class org.apache.accumulo.core.iterators.user.SummingCombiner
TypedValueCombiner can interpret Values as a variety of number encodings
(VLong, Long, or String) before combining
----------> set SummingCombiner parameter columns,
[:[:|LONG| STRING>: STRING
root@a14 perDayCounts> insert foo day 20080101 1
root@a14 perDayCounts> insert foo day 20080101 1
root@a14 perDayCounts> insert foo day 20080103 1
root@a14 perDayCounts> insert bar day 20080101 1
root@a14 perDayCounts> insert bar day 20080101 1
root@a14 perDayCounts> scan
bar day:20080101 [] 2
foo day:20080101 [] 2
foo day:20080103 [] 1
Accumulo包括一些有用的组合器开箱。要找到这些看看在org.apache.accumulo.core.iterators.user包。
可以添加额外的合路,通过创建一个Java类,延长 org.apache.accumulo.core.iterators.Combiner的加入一罐含有该类到Accumulo的lib / ext目录。
一个合成器的一个例子,可以发现
accumulo/examples/simple/main/java/org/apache/accumulo/examples/simple/combiner/StatsCombiner.java
6.5。块缓存
为 了增加吞吐量的常用访问的条目,,采用了Accumulo块缓存。此块缓存缓冲区内存中的数据,因此,它并没有被读出的磁盘。的RFile格式 Accumulo喜欢的组合索引块和数据块,索引块是用来寻找相应的数据块。典型的查询Accumulo结果在多个索引块的二进制搜索,然后通过线性扫描 的一个或多个数据块。
块缓存可配置每一个表的基础上,在平板电脑上的服务器共享一个单一的资源池和所有药片托管。要配置tablet服务器的块高速缓存的大小,设置以下属性:
tserver.cache.data.size:指定的高速缓存文件的数据块的大小。
tserver.cache.index.size:指定文件索引的缓存的大小。
要启用的块缓存表,设置以下属性:
table.cache.block.enable:确定是否启用文件(数据)块缓存。
table.cache.index.enable:确定是否启用索引缓存。
块缓存可以有一个显着的效果,对缓解热点问题,以及减少查询延迟。它是默认启用的元数据表。
6.6。压实
当 数据被写入到Accumulo缓存在内存中。缓冲在存储器中的数据最终被写入到HDFS上每片为基础。文件也可以直接向片批量导入。tablet服务器在 后台运行多个文件合并成一个主要的压实。tablet服务器来决定哪片紧凑,平板电脑内的文件压缩。作出这一决定是使用压缩率,这是每一个表的基础上进行 配置。要配置这个比例修改下列属性:
table.compaction.major.ratio
增加这一比例将导致更多的文件每片和压实工作。更多文件每片意味着更高的查询延迟。因此,调整这个比例是一个权衡之间采集和查询性能。缺省值为3的比例。
的比率的工作方式是,一组文件被压缩到一个文件中,如果组中的文件的大小的总和是大于集合中的最大文件的大小的比值乘以。如果这是不是真正的平板电脑中的所有文件集,最大的文件被删除考虑,剩余的文件被认为是压实。这是重复,直到压实被触发或有考虑留下任何文件。
tablet服务器用来运行主要压实的后台线程的数量是可配置的。要配置此修改以下属性:
tserver.compaction.major.concurrent.max
此外,tablet服务器使用小型压实的线程数是可配置的。要配置此修改以下属性:
tserver.compaction.minor.concurrent.max
正在运行和排队的主要和次要的压实的数字可见的Accumulo显示器页面。这可以让你看到,如果压实备份和上面的设置都需要调整。调整时可用的线程数,压实,考虑如地图和减少节点上运行的内核和其它任务的数量。
重 大压实如果没有跟上,那么的文件每片数将增长到一个点查询性能开始受到影响。来处理这种情况的一种方法是,以增加压缩比。例如,如果压缩比被设置为1,则 每一个新的文件中添加一个平板轻微压实立即队列主要压实片剂。因此,如果平板电脑拥有一个200M的文件和小型压实写入一个1M的文件,那么主要的压实试 图合并200M和1M的文件。如果平板电脑服务器有很多片剂试图做这样的事情,那么主要的压实将备份和文件每片的数量将开始增长,假设数据被连续写入。增 加压实比例将缓解备份通过降低主要压实工作需要做。
另一个选项来处理每片种植的文件太大调整以下属性:
table.file.max
当 平板电脑达到这个数字刷新其内存中的数据保存到磁盘文件和需要,它会选择做一个合并轻微压实。合并轻微压实,将平板电脑的最小文件合并轻微压缩时间在内存 中的数据。因此,文件的数量不会超过这个限制增长。这将使小压实需要更长的时间,这将导致摄取性能下降。这可能会导致摄取放慢主要压实,直到有足够的时间 赶上。当调整此属性,也考虑调整压缩率。理想的情况下,合并轻微的压实永远需要发生重大压实会跟上。配置文件最大和压实比只合并发生轻微压实和主要压实从 未发生,这是可能的。只因为这样做合并小压实导致O(Ñ 2)要做的工作,这应该被避免。主要压实完成的工作量是ø(N *日志ŗ(N)),其中 ŗ是压缩率。
一 个表可以手动进行压实。要启动一个小的压实,使用flush在shell命令。要发起一个重大的压实,使用外壳紧凑命令。紧凑的命令将压缩到一个文件中的 一个表中的所有片。即使同一个文件的平板电脑将被压缩。一个主要压实过滤器被配置为一个表的情况下,这是有用的。以1.4的压缩能力的范围内的一个表 中的溶液。要使用此功能指定启动停止紧凑命令行。这将只压缩片重叠在给定的行范围。
6.7。预拆分表
将平衡Accumulo跨服务器和分发表。表之前,变大时,它会保持在单个服务器上作为一个单一的片剂。这限制了在该数据可以被添加或查询的单个节点的速度的速度。为了提高性能,当一个表是新的,还是小的,你可以添加分割点,产生新的平板电脑。
在shell:
root@myinstance> createtable newTable
root@myinstance> addsplits -t newTable g n t
这将创建一个新的表4粒。该表将被分割的字母“G”,“N”,“T”,这将很好地工作,如果该行数据与小写字母字符开始。如果你的行数据包括二进制信息或数字信息,或者如果行信息的分布是不平坦的,那么你会选择不同的分割点。现在采集和查询可以进行4个节点可以提高性能。
6.8。合并片
随 着时间的推移,一个表可以得到非常大,如此之大,它有数百成千上万的分割点。一旦有足够的片蔓延在整个集群中的一个表,额外的分裂可能不会提高性能,可能 会造成不必要的簿记。数据的分布可能会随时间而改变。例如,如果行数据包含了最新的信息和数据的不断增加和删除,以维持目前的信息的一个窗口,为老年人行 的药片可能是空的。
accumulo支持片剂合并,它可以被用来减少分割点的数目。下面的命令将所有行合并从“A”到“Z”成一个单一的平板电脑:
root@myinstance> merge -t myTable -s A -e Z
如果一个合并的结果产生一个大于配置的分割大小的片剂,片剂可能会被分割由数位板服务器。肯定会增加平板电脑大小的任何合并前,如果我们的目标是有较大的药片:
root@myinstance> config -t myTable -s table.split.threshold=2G
为了合并小药片,你可以问accumulo合并部分小于给定大小的表。
root@myinstance> merge -t myTable -s 100M
缺省情况下,小片将不会被合并到已经大于给定大小的片剂。这可以离开孤立的小药片。要强制合并成较大的片小药片使用“ - {} - force”选项:
root@myinstance> merge -t myTable -s 100M --force
合并分片上一节的时间。如果你的表中包含许多部分小分割点,或正在试图改变分割整个表的大小,这将是更快地分割点设置和合并整个表:
root@myinstance> config -t myTable -s table.split.threshold=256M
root@myinstance> merge -t myTable
6.9。删除范围
考虑索引方案使用最新的信息在每一行。例如“20110823-15:20:25.013的可能会对指定的日期和时间的行。在某些情况下,我们可能会喜欢这个日期的基础上删除行说,删除所有的数据比当年旧。Accumulo支持删除操作,有效地消除两行之间的数据。例如:
root@myinstance> deleterange -t myTable -s 2010 -e 2011
这将删除所有以“2010”开始的行,它会停在“2011”开始的任何行。您可以删除任何数据,2011年之前:
root@myinstance> deleterange -t myTable -e 2011 --force
外壳不会允许你删除一个无限的范围内(不启动),除非你提供的“ - {} - force”选项。
范围的删除是通过使用在给定的开始/结束位置的分割,而且会影响在表中的分割的数目。
6.10。克隆表
可 以创建一个新的表指向现有的表的数据。这是一个非常快的元数据操作,实际上没有数据复制。克隆表和源表可以改变独立后的克隆操作。这个功能的一个用例的测 试。例如,测试一个新的过滤迭代器,克隆表,添加过滤器的克隆,并迫使主要压实。要执行测试数据较少,克隆一个表,然后使用删除范围,有效地去除很多从克 隆的数据。另一个用例生成一个快照,防范人为错误。要创建一个快照,克隆一个表,然后禁止克隆的写权限。
克隆操作将指向源表的文件。这就是为什么flush选项默认情况下,在shell中存在并已启用。如果冲洗选项未启用,那么任何数据源表目前已在内存不存在克隆。
克隆表复制源表中的配置。然而,源表中的权限不会被复制到克隆。创建克隆后,只有用户创建克隆可以读取和写入。
在以下示例中,我们可以看到,克隆操作之后插入的数据是不可见的克隆。
root@a14> createtable people
root@a14 people> insert 890435 name last Doe
root@a14 people> insert 890435 name first John
root@a14 people> clonetable people test
root@a14 people> insert 890436 name first Jane
root@a14 people> insert 890436 name last Doe
root@a14 people> scan
890435 name:first [] John
890435 name:last [] Doe
890436 name:first [] Jane
890436 name:last [] Doe
root@a14 people> table test
root@a14 test> scan
890435 name:first [] John
890435 name:last [] Doe
root@a14 test>
du 命令在shell中显示一个表被使用在HDFS多少空间。此命令也可以显示在HDFS中有多少空间重叠的两个克隆表。在下面的例子都显示表CI是使用 428M。CI是克隆CIC和du表明这两个表共享428M。经过三个条目插入CIC和其满脸通红,都显示了这两个表仍然共享428M,但中投公司本身有 226个字节。最后,表CIC被压实,然后杜表明,每个表使用428M。
root@a14> du ci
428,482,573 [ci]
root@a14> clonetable ci cic
root@a14> du ci cic
428,482,573 [ci, cic]
root@a14> table cic
root@a14 cic> insert r1 cf1 cq1 v1
root@a14 cic> insert r1 cf1 cq2 v2
root@a14 cic> insert r1 cf1 cq3 v3
root@a14 cic> flush -t cic -w
27 15:00:13,908 [shell.Shell] INFO : Flush of table cic completed.
root@a14 cic> du ci cic
428,482,573 [ci, cic]
226 [cic]
root@a14 cic> compact -t cic -w
27 15:00:35,871 [shell.Shell] INFO : Compacting table ...
27 15:03:03,303 [shell.Shell] INFO : Compaction of table cic completed for given range
root@a14 cic> du ci cic
428,482,573 [ci]
428,482,612 [cic]
root@a14 cic>
6.11。表导出
Accumulo 支持导出表的表复制到另一个集群的目的。导出和导入表保留表配置,分裂,和逻辑的时间。表导出,然后复制通过的hadoop distcp命令。要导出表,它必须是离线和保持脱机而discp运行的。它需要保持脱机状态的原因是为了防止文件被删除。表可以克隆和克隆脱机序,以避 免失去对表的访问。参见DOCS /例子/ README.export一个例子。
7。表设计
7.1。基本表
行 ID进行排序由于Accumulo表,每个表都可以被认为是被索引的行ID。行ID进行查找,可以快速执行,做一个二进制搜索,第一个冲过片,然后在平板 电脑。客户应小心选择行ID,以支持其所需的应用程序。一个简单的规则是选择行ID为每个实体的唯一标识符来存储和分配所有其他属性进行跟踪,根据此行的 ID列。例如,如果我们有一个逗号分隔的文件中的下列数据:
userid,age,address,account-balance
我们可能会选择此数据存储使用的的ROWID,其余列家庭中的数据的userid:
Mutation m = new Mutation(new Text(userid));
m.put(new Text("age"), age);
m.put(new Text("address"), address);
m.put(new Text("balance"), account_balance);
writer.add(m);作家。(米);
通过指定的用户ID作为扫描仪的范围和获取特定的列,然后我们就可以检索任何一个特定的用户ID列:
Range r = new Range(userid, userid); // single rowScanner s = conn.createScanner("userdata", auths);
s.setRange(r);
s.fetchColumnFamily(new Text("age"));for(Entry entry : s)
System.out.println(entry.getValue().toString());
7.2。ROWID设计
通常,它是必要的,以便有预期的访问模式最适合的方式,是命令行变换ROWID。一个很好的例子,这是互联网域名的组成部分,以相同的父域组行的顺序颠倒过来:
com.google.code
com.google.labs
com.google.mail
com.yahoo.mail
com.yahoo.research
有些数据可能会导致在创造非常大的行 - 行有许多列。在这种情况下,表设计可能要拆分这些行更好的负载平衡,同时保持他们在一起排序的扫描目的。这可以通过在该行的末尾附加一个随机的子串:
com.google.code_00
com.google.code_01
com.google.code_02
com.google.labs_00
com.google.mail_00
com.google.mail_01
它也可以通过添加一个字符串表示的一段时间,如一周或一个月的日期:
com.google.code_201003
com.google.code_201004
com.google.code_201005
com.google.labs_201003
com.google.mail_201003
com.google.mail_201004
追加日期提供了一个给定的日期范围限制扫描的附加功能。
7.3。索引
为 了支持通过查找一个实体的多个属性,额外的索引可以建。然而,因为Accumulo表可以支持任意数量的列不事先指定的一个附加指标往往会在主表中的记录 足以支持查找。在这里,该指数已为ROWID值或期限从主表,列的家庭都是一样的,预选赛的索引表列包含从主表的ROWID。
RowID
Column Family
Column Qualifier
Value
Term
Field Name
MainRowID
注:我们存储的rowid列预选赛,而不是价值,这样我们就可以有一个以上的ROWID与一个特定的期限内的指数相关。如果我们存储这个值,我们只能看到一个值出现自Accumulo默认配置为返回一个最新的值与键关联的那些行。
然后,可以通过先扫描索引表出现需要的值在指定的列,返回一个列表,从主表行ID查找。这些可以被用于检索每个匹配的记录,在他们的全部,或列的一个子集,从主表。
支 持高效查找多个从同一个表的rowid中,Accumulo客户端库提供一个BatchScanner。用户可以指定一组范围,在多个线程执行的查找到多 个服务器,并返回一个Iterator所有检索的行BatchScanner。返回的行排序顺序,不作为的情况下,基本的扫描仪接口。
// first we scan the index for IDs of rows matching our queryText term = new Text("mySearchTerm");HashSet matchingRows = new HashSet();Scanner indexScanner = createScanner("index", auths);
indexScanner.setRange(new Range(term, term));// we retrieve the matching rowIDs and create a set of rangesfor(Entry entry : indexScanner)
matchingRows.add(new Text(entry.getKey().getColumnQualifier()));// now we pass the set of rowIDs to the batch scanner to retrieve themBatchScanner bscan = conn.createBatchScanner("table", auths, 10);
bscan.setRanges(matchingRows);
bscan.fetchFamily("attributes");for(Entry entry : scan)
System.out.println(entry.getValue());
动 态模式的Accumulo能力的优点之一是,不同的字段可以采集到同一物理表。但是,它可能有必要建立不同的索引表,如果不同的条款必须进行格式化, 以保持适当的排序顺序。例如,实数必须比自己平时的符号不同的格式,以正确排序。在这些情况下,通常独特的数据类型的每一个索引就足够了。
7.4。实体属性和图形表
Accumulo是理想的存储实体及其属性的属性,特别是稀疏。它往往是一起加入多个数据集,在同一表常见的实体。这可以允许的代表性的曲线图,其中包括节点,它们的属性,并且它连接到其他节点。
存储个别事件,而非实体的属性或图形表存储聚合信息的事件中所涉及的实体和实体之间的关系。单一事件时,不是非常有用,当随意一个不断更新的聚合,这通常是可取的。
实体 - 属性或图形表的物理架构如下:
RowID
Column Family
Column Qualifier
Value
EntityID
Attribute Name
Attribute Value
Weight
EntityID
Edge Type
Related EntityID
Weight
例如,要跟踪员工,经理和产品以下实体属性表可以使用。注意所用的权并不总是必要的,被设置为0时,不使用。
RowID
Column Family
Column Qualifier
Value
E001
name
bob
0
E001
department
sales
0
E001
hire_date
20030102
0
E001
units_sold
P001
780
E002
name
george
0
E002
department
sales
0
E002
manager_of
E001
0
E002
manager_of
E003
0
E003
name
harry
0
E003
department
accounts_recv
0
E003
hire_date
20000405
0
E003
units_sold
P002
566
E003
units_sold
P001
232
P001
product_name
nike_airs
0
P001
product_type
shoe
0
P001
in_stock
germany
900
P001
in_stock
brazil
200
P002
product_name
basic_jacket
0
P002
product_type
clothing
0
P002
in_stock
usa
3454
P002
in_stock
germany
700
为了有效更新的边权重,合计迭代器可以配置相同的密钥应用的所有突变添加值。这些类型的表可以很容易地创建从原始事件,个别事件的实体,属性和关系通过简单的提取和插入钥匙进入Accumulo各计数1。聚合迭代会照顾保持边缘权重。
7.5。文件分区索引
用一个简单的索引如上所述运作良好时,寻找匹配的记录一组给定的标准之一。同时符合多个条件的记录,如寻找文件包含所有的话时,当寻找'和'白'和'家',有几个问题。
首先是必须被发送到客户端,这会导致网络流量的特定匹配的搜索条件中的任一项,该组的所有记录。第二个问题是客户端是负责执行的交集上套的记录返回,以消除所有,但所有搜索条件匹配的记录。内存的客户端可能会在此操作过程中很容易被淹没。
由于这些原因,Accumulo包括支持的方案被称为分片索引,这些组操作可以被执行上面的TabletServers决定哪些记录包括在结果集中的,可以在不产生网络流量。
这是通过分割记录成箱,每个驻留在至多一个TabletServer上,然后创建一个索引,每个记录在每个垃圾桶如下:
RowID
Column Family
Column Qualifier
Value
BinID
Term
DocID
Weight
由 用户定义的摄取应用映射到文件或记录。存储BinID的ROWID,我们确保特定斌的所有信息都包含在一个单一的平板电脑,并托管在一个单一的 TabletServer以来从未分裂Accumulo行跨片。存储列家庭服务条款,使在这个垃圾桶的所有文件包含给定的长期快速查找。
最 后,我们进行交集操作,通过一个特殊的迭代器称为相交迭代TabletServer。由于文件分割成许多垃圾桶,搜索所有文件必须搜索每一个垃圾桶。我们 可以使用BatchScanner,并行扫描所有的垃圾桶。相交迭代器应该启用一个BatchScanner在用户查询代码如下:
Text[] terms = {new Text("the"), new Text("white"), new Text("house")};BatchScanner bs = conn.createBatchScanner(table, auths, 20);IteratorSetting iter = new IteratorSetting(20, "ii", IntersectingIterator.class);
IntersectingIterator.setColumnFamilies(iter, terms);
bs.addScanIterator(iter);
bs.setRanges(Collections.singleton(new Range()));for(Entry entry : bs) {
System.out.println(" " + entry.getKey().getColumnQualifier());
}
此 代码有效的BatchScanner扫描一个表的所有平板电脑,寻找符合所有条款的文件。因为所有的平板电脑正在扫描的每个查询,每个查询比其他的 Accumulo扫描,这通常涉及少数TabletServers更加昂贵。这减少了支持的并发查询数量和被称为'掉队'的问题,其中每一个查询运行慢最 慢的服务器参与。
当然,快速的服务器将其结果返回给客户端,它可以显示给用户,而他们等待的结果到达其余立即。如果结果是无序的,这是一个相当有效的到达第一的成绩不如其他任何用户。
8。高速摄取
accumulo经常被用来作为一个更大的数据处理和存储系统的一部分。涉及Accumulo,摄取和查询组件的并行系统性能发挥到极致的设计应提供足够的并行和并发性,以避免产生瓶颈,为用户和其他系统写入和读取Accumulo。有几种方法,以实现高接收性能。
8.1。预拆分新表
新表包括默认情况下,一个单一的平板电脑。由于基因突变,表的增长和分裂成平衡由主跨TabletServers的多个片。这意味着总的摄取率将被限制在更少的服务器为群集内的,直到表中已经到了有是在每个TabletServer片其中。
预分割表,确保有尽可能多片随意摄取前开始利用一切可能的并行集群硬件。表可以随时拆分使用shell:
user@myinstance mytable> addsplits -sf /local_splitfile -t mytable
就提供并行摄取的目的,没有必要创造更多的平板电脑比有物理机集群内合共摄取率是一个函数的物理机数量。请注意,合共摄取率仍然摄取客户的机器上运行的数量,分布的rowid桌子对面的。的聚集摄取率将是次优的,如果有许多插入一个小数目的rowid。
8.2。多个Ingester客户端
Accumulo 是能够扩展的摄取率非常高,这是取决于有多少人TabletServers运转中,但也摄取客户的数量。这是因为单个客户端,同时能配料突变和将它们发送 到所有TabletServers,是最终在一台机器可以处理的数据的量限制。合共摄取率的客户端数点在其中的总I / O的TabletServers或总的网络带宽容量达到线性扩展。
在高利率的摄取是最重要的操作设置,群集通常配置仅运行Ingester客户奉献一定数量的机器。客户最佳的摄食率必要TabletServers,精确的比率会有所不同,根据每台机器的资源和数据类型的分布。
8.3。大量摄取
Accumulo 支持的能力,如MapReduce的外部进程所产生的文件导入到现有的表。在某些情况下,它可能会更快加载数据,这种方式通过通过客户使用 BatchWriters摄入而非。这使得大量的机器格式化数据的方式Accumulo预期。的新文件,然后简单地介绍到Accumulo通过一个 shell命令。
要 配置的MapReduce准备批量加载数据格式化,作业应设置使用范围分区工具,而不是默认的哈希分区工具。范围分区工具使用分割点的Accumulo 表,将接收到的数据。分割点,可从外壳由MapReduce RangePartitioner的使用。请注意,这仅仅是有用的,如果现有的表已经分裂成多个片。
user@myinstance mytable> getsplits
aa
ab
ac
...
zx
zy
zz
运行MapReduce作业,使用创建文件的AccumuloFileOutputFormat被介绍给Accumulo的。一旦完成,文件可以添加到Accumulo通过壳:
user@myinstance mytable> importdirectory /files_dir /failures
需要注意的是引用的路径是目录,Accumulo运行在同一个HDFS实例。Accumulo将没有任何文件被添加到指定的第二个目录。
一个完整的例子,可以发现在使用大量摄取 accumulo /文档/例子/ README.bulkIngest
8.4。散装摄取的逻辑时间
逻 辑的时间是非常重要的大宗进口数据,客户端代码可能会选择一个时间戳。在批量导入时,用户可以选择被导入文件的集合时间,以使逻辑。当它的启 用,Accumulo使用迭代次批量导入的文件中懒洋洋地设置一个专门的系统。这种机制确保了时间不同步多节点应用程序(如运行MapReduce的)将 保持一定的因果顺序的假象。这减轻了问题的时间是错误的系统上创建该文件批量导入。导入该文件时,这些时间都没有设置,但只要它是读取扫描或压实。进口, 在一段时间内获得和总是使用由专门的系统迭代设置时间。
的时间戳分配的accumulo将在该文件中的每一个键是相同的。这可能会导致问题,如果文件中包含多个密钥是相同的时间戳除外。在这种情况下,按键的排序顺序是不确定的。这可能发生,如果在同一批量导入文件插入和更新。
8.5。MapReduce的摄取
这 是可能的,以有效地写入许多突变Accumulo的平行的方式从一个MapReduce作业。在这种情况下被写入MapReduce的数据处理,住在 HDFS中,写突变Accumulo使用AccumuloOutputFormat的。见的MapReduce下节分析的详细信息。
使用MapReduce的一个例子可以找到根据accumulo/docs/examples/README.mapred
9。Google Analytics(分析)
Accumulo支持更先进的数据处理不是简单的保持按键的排序和执行高效的查找。Google Analytics(分析)可以开发使用MapReduce和配合Accumulo表中的迭代器。
9.1。MapReduce的
Accumulo 表可以作为MapReduce作业的源和目标。与MapReduce作业要使用Accumulo的表(特别是新的Hadoop的API版本0.20),作 业参数配置,使用AccumuloInputFormat AccumuloOutputFormat。通过这两种格式类Accumulo具体参数可以设置,做到以下几点:
-
输入验证并提供用户凭据
-
限制扫描一定范围的行
-
限制输入可用列的一个子集
9.1.1。mapper和reducer类
要阅读从Accumulo表与下面的类的参数,并创建一个映射请务必配置AccumuloInputFormat的。
class MyMapper extends Mapper<Key,Value,WritableComparable,Writable> { public void map(Key k, Value v, Context c) { // transform key and value data here
}
}
要 写入一个Accumulo表,与下面的类的参数,并创建一个减速请务必配置AccumuloOutputFormat的。从减速机发射的关键标识被发送到 的表的突变。这允许一个单一的减速写信给一个以上的表,如果需要的。一个默认的表可以使用AccumuloOutputFormat配置,在这种情况下, 在输出表的名称没有被传递到减速机内的上下文对象。
class MyReducer extends Reducer<WritableComparable, Writable, Text, Mutation> { public void reduce(WritableComparable key, Iterable values, Context c) { Mutation m; // create the mutation based on input key and value
c.write(new Text("output-table"), m);
}
}
通过为输出文本对象应包含表的名称应采用这种突变。文本可以是空的,在这种情况下,突变将被应用到默认指定表名在AccumuloOutputFormat股权。
9.1.2。AccumuloInputFormat选择
Job job = new Job(getConf());
AccumuloInputFormat.setInputInfo(job, "user", "passwd".getBytes(), "table", new Authorizations());
AccumuloInputFormat.setZooKeeperInstance(job, "myinstance", "zooserver-one,zooserver-two");
可选设置:
Accumulo限制到一组行范围:
ArrayList ranges = new ArrayList();// populate array list of row ranges ...AccumuloInputFormat.setRanges(job, ranges);
accumulo限制到一个列表的列:
ArrayList>> columns = new ArrayList>();// populate list of columnsAccumuloInputFormat.fetchColumns(job, columns);
使用正则表达式来匹配行IDs:
AccumuloInputFormat.setRegex(job, RegexType.ROW, "^.*");
9.1.3. AccumuloOutputFormat options
boolean createTables = true;String defaultTable = "mytable";
AccumuloOutputFormat.setOutputInfo(job, "user", "passwd".getBytes(),
createTables,
defaultTable);
AccumuloOutputFormat.setZooKeeperInstance(job, "myinstance", "zooserver-one,zooserver-two");
可选设置:
AccumuloOutputFormat.setMaxLatency(job, 300); // millisecondsAccumuloOutputFormat.setMaxMutationBufferSize(job, 5000000); // bytes
一个示例使用MapReduce和Accumulo可以发现accumulo/docs/examples/README.mapred
d
9.2。合路
许多应用程序都可以从中受益的能力,总价值跨越常用键。这是可以做到通过合路器的迭代器,和类似的减少MapReduce的步骤。这提供了定义在线增量更新的分析能力,没有面向批处理的MapReduce作业相关的开销或延迟。
所有这一切都需要一个表的总价值来识别字段值将被分组,插入突变与这些领域的关键,组合迭代器支持所需的总结操作和配置表。
结合迭代的唯一限制是,组合开发人员不应该承担所有的值给定键已经看到,由于新的突变可以随时插入。这排除了如计算平均值时,例如在聚合中使用的值的总数。
9.2.1。特征向量
相 结合的迭代器范围内Accumulo的表的一个有趣的用途是存储用于在机器学习算法的特征矢量。例如,许多算法,如k-means聚类,支持向量机,异常 检测等使用特征向量的概念和计算距离度量学习一个特定的模式。可用于列中一个Accumulo表中有效地存储稀疏特征和他们的重量,以通过使用一个组合的 迭代器进行增量更新。
9.3。统计建模
需要更新,由多台机器上并行的统计模型,可以类似地存储范围内Accumulo表。例如,可以有一个MapReduce的工作是一个全球性的统计模型迭代更新每个地图,或降低了工作人员的工作参考通过一个嵌入式Accumulo的客户端被读取和更新的模型零件的。
使用Accumulo这样小块的信息,在随机存取模式,这是相辅相成的MapReduce的顺序访问模式实现高效,快速的查找和更新。
10。安全
Accumulo 延伸BigTable的数据模型来实现的安全机制被称为单元级别的安全。每一个键 - 值对都有自己的安全标签,存储的密钥,该密钥是用来确定一个给定的用户是否满足安全要求的值读列下的可见性元素。这使得数据被存储在同一行内的多种安全级 别,以及不同程度的访问相同的表查询的用户,同时保持数据的机密性。
10.1。安全标签表达式
当突变的应用,用户可以指定一个安全标签的每个值。这样做是通过一个ColumnVisibility对象的put()方法创建的突变:
Text rowID = new Text("row1");Text colFam = new Text("myColFam");Text colQual = new Text("myColQual");ColumnVisibility colVis = new ColumnVisibility("public");long timestamp = System.currentTimeMillis();Value value = new Value("myValue");Mutation mutation = new Mutation(rowID);
mutation.put(colFam, colQual, colVis, timestamp, value);
10.2。安全标签表达式语法
防伪标签由一组所需要的值读标签是与用户定义的令牌。可以指定所需的令牌的集合,支持的令牌的逻辑“与”和“或”的组合,以及嵌套组的令牌一起使用的语法。
例如,假设在我们的组织,我们希望我们的数据值标签防伪标签用户角色定义。我们可能已经令牌,如:
管理员
审计
系统
这些可以单独指定,或结合使用逻辑运算符:
/ /用户必须具有管理员权限:
管理员
/ /用户必须具有管理员和审核权限
管理审计
/ / admin或审计权限的用户
管理|审计
/ /用户必须具有审计和管理员或系统中的一个或两个
(管理系统)及审计
当| 与运营商的使用,必须使用括号来指定优先级的运算符。
10.3。授权
当客户端试图读取数据从Accumulo,任何防伪标签进行检查对集时扫描仪或BatchScanner的创建通过客户端代码的授权。如果授权被确定为不足,以满足安全标签,该值被抑制结果发送回给客户端的一组。
指定授权用户拥有令牌作为一个逗号分隔的列表:
// user possesses both admin and system level accessAuthorization auths = new Authorization("admin","system");Scanner s = connector.createScanner("table", auths);
10.4。用户授权
每个accumulo用户具有一组相关联的安全性标签。要操纵这些在shell中使用setuaths和getauths命令。这些也可以使用java安全操作API修改。
当用户创建了一个扫描仪,通过一组授权。如果传递到扫描仪的授权用户授权的一个子集,然后将抛出一个异常。
为了防止用户写他们无法读取数据,添加的知名度约束到表中。使用EVC选项的CREATETABLE shell命令启用此约束。对于现有的表使用下面的shell命令到启用的知名度约束。确保约束不与任何现有的约束冲突。
config -t table -s table.constraint.1=org.apache.accumulo.core.security.VisibilityConstraint
ALTER TABLE权限的任何用户可以添加或删除此约束。此约束并不适用于大容量导入数据,如果这是一个关注,然后禁用批量的进口许可。
10.5。安全授权处理
对 于许多用户提供服务的应用程序,它并不期望将创建一个accumulo用户,每个应用程序用户。在这种情况下,任何的应用程序的用户所需要的所有授权的 accumulo用户必须被创建。服务查询,应用程序应该创建一个扫描仪应用程序用户的授权。这些授权可以得到可信的第三方。
生 产系统通常将整合公共密钥基础设施(PKI)和指定的客户端代码在查询使用PKI服务器层进行谈判,以验证用户身份并获取授权令牌(凭据)。这要求用户指 定所必需的信息,来验证自己的系统。用户身份一旦建立,他们的凭据可以访问客户端代码及用户之所及之外传递给Accumulo,。
10.6。查询服务层
由 于的主要方法的互动与Accumulo是通过Java API,生产环境中经常调用的执行查询层。这可以通过在容器中使用Web服务的Apache Tomcat这样的,但不是必需的。查询服务层提供面向用户的应用程序可以建立一个平台,提供了一种机制。这允许应用程序设计者隔离潜在的复杂的查询逻 辑,并执行基本的安全功能提供了一种方便点。
一些生产环境,选择在这一层,用户标识符用于检索的访问凭据,然后缓存在查询层,并提交到Accumulo通过授权机制来实现认证。
通常情况下,查询服务层位于在Accumulo和用户工作站之间。
11。管理
11.1。硬件
因为我们正在运行的基本上是两个或三个同时整个集群分层系统:HDFS,Accumulo和MapReduce,这是典型的由4至8核心,8到32 GB RAM的硬件。这是这样每个正在运行的过程中可以有至少一个芯和2 - 4 GB的。
运行HDFS的核心之一,通常可以保持2至4个磁盘忙,所以每台机器可能通常为2×300GB硬盘和多达4个1TB或2TB磁盘。
低 于这一标准,如与1U服务器2芯和4GB每个是可以做到的,但在这种情况下,建议只运行每台机器上的两个过程 - 即的DataNode和TabletServer的或的DataNode和MapReduce的工人,但不所有三个。这里的约束是有足够的可用堆空间,一 台机器上的所有进程。
11.2。网络
Accumulo通过远程过程调用两个传递数据和控制信息通过TCP / IP进行通信。此外,Accumulo使用HDFS客户沟通与HDFS。为了达到良好的采集和查询性能,足够的网络带宽必须可任意两台机器之间。
11.3。安装
选择目录安装Accumulo。这个目录将被引用环境变量$ ACCUMULO_HOME。运行以下命令:
$ tar xzf accumulo-assemble-1.5.0-bin.tar.gz # unpack to subdirectory
$ mv accumulo-assemble-1.5.0-bin $ACCUMULO_HOME # move to desired location
在群集内的每台机器重复此步骤。通常情况下,所有的机器有相同的$ ACCUMULO_HOME。
11.4。依赖关系
Accumulo 需要HDFS,ZooKeeper的配置和运行开始之前。密码应配置SSH至少Accumulo主和TabletServer机之间。在集群中运行网络时 间协议(NTP),以确保节点的时钟,不要太脱节,这可能会导致自动时间戳数据的问题,这也是一个不错的主意。
11.5。组态
Accumulo配置编辑几个壳牌和XML文件中发现 $ ACCUMULO_HOME / conf目录。其结构类似于Hadoop的配置文件。
11.5.1。编辑机密/ accumulo的env.sh
Accumulo需要知道在哪里可以找到它依赖于软件。编辑accumulo env.sh指定以下内容:
-
输入的安装目录Accumulo为ACCUMULO_HOME美元的位置
-
输入您系统的Java回家$ JAVA_HOME
-
Hadoop的输入位置为$ HADOOP_HOME
-
选择的位置Accumulo日志,并将其输入$ ACCUMULO_LOG_DIR“
-
输入的ZooKeeper为ZOOKEEPER_HOME美元的位置
通过默认Accumulo TabletServers被设置为使用1GB的内存。你可能会改变这个通过改变价值$ ACCUMULO_TSERVER_OPTS。注意语法是Java的JVM命令行选项。此值应小于物理内存的运行TabletServers机器。
有主人的内存使用和垃圾收集过程中的类似选项。如果他们超出物理RAM的硬件,减少这些,增加他们的物理RAM的范围内,如果一个进程失败,因为内存不足。
请 注意,您将指定Java堆空间,在accumulo env.sh。您应确保总的堆空间用于Accumulo TSERVER和在Hadoop的DataNode和TaskTracker必须是小于集群中的每个从节点上的可用内存。大型集群上,建议,都可以在不同 的机器上运行Hadoop的NameNode的Accumulo主,次要的NameNode,和Hadoop JobTracker的允许他们使用更多的堆空间。如果您运行的是一小簇在同一台机器上,同样确保他们的堆空间设置适合于可用的内存。
11.5.2。集群规范
在机器将作为的Accumulo主:
-
写$ ACCUMULO_HOME / conf目录/硕士文件Accumulo主的IP地址或域名。
-
写的机器,这将是在$ ACCUMULO_HOME / conf目录/奴隶,每行一个TabletServers的IP地址或域名。
请注意,如果使用域名而不是IP地址,DNS必须配置正确参与集群中的所有机器。DNS可以是一个混乱的错误源。
11.5.3。Accumulo设置
指定适当的值ACCUMULO_HOME元/ conf目录/ accumulo的site.xml中的下列设置:
<property>
<name>zookeepername>
<value>zooserver-one:2181,zooserver-two:2181value>
<description>list of zookeeper serversdescription>property>
这使找到的ZooKeeper Accumulo。Accumulo使用ZooKeeper的协调过程,并有助于敲定TabletServer失败之间设置的。
<property>
<name>walogname>
<value>/var/accumulo/walogsvalue>
<description>local directory for write ahead logsdescription>property>
Accumulo预写日志记录所有变更表,然后将它们提交到表。“walog设置指定预写日志写入到每台机器上的本地目录。这个目录应该存在所有机器上作为TabletServers的。
<property>
<name>instance.secretname>
<value>DEFAULTvalue>property>
实例需要一个秘密,使服务器之间的安全通信。配置你的秘密,并确保不向其他用户可读,的site.xml accumulo的文件是。
可以修改某些设置通过Accumulo外壳,并立即生效,但一些设置需要一个过程重新启动才能生效。有关详细信息,请参阅“配置文件(可在监视器上的网页)。
11.5.4。部署配置
复制的主人,奴隶,env.sh accumulo,如果有必要,accumulo的site.xml从$ ACCUMULO_HOME / conf目录/所有的机器的奴隶文件中指定主目录。
11.6。初始化
必须初始化Accumulo创建的结构,它在内部使用定位数据在集群。HDFS是必须要配置和运行之前Accumulo可以初始化。
HDFS开始后,可以进行初始化通过执行 $ ACCUMULO_HOME /bin/ accumulo的初始化。这个脚本会提示输入名称此实例Accumulo。实例名称是用来确定一套表和特定于实例的设置。然后,该脚本将一些信息写入到HDFS,所以Accumulo可以正常启动。
初始化脚本会提示你设置root密码。一旦Accumulo初始化后,就可以开始。
11.7。运行
11.7.1。从Accumulo开始
确保上配置的Hadoop集群中的所有机器,包括访问共享HDFS实例。确保HDFS,ZooKeeper的运行。请确保ZooKeeper的配置和集群中的至少一台计算机上运行。启动Accumulo使用BIN /start-all.sh脚本。
为了验证,运行Accumulo,检查“状态”页面监控下 。此外,shell可提供一些信息表通过读取元数据表的状态。
11.7.2。停止Accumulo
要正常关机,运行的BIN /stop-all.sh和主协调所有的tablet服务器关机。的关机等待完成所有的小压实,所以它可能需要一些时间为特定的配置。
11.8。监控
主Accumulo监测的Accumulo组件的状态和健康提供了一个接口。这个接口可以访问指着Web浏览器http://accumulomaster:50095/status
11.9。记录
Accumulo处理每写一组日志文件。默认情况下,这些被发现下 $ ACCUMULO /logs/。
11.10。恢复
关闭Accumulo TabletServer故障或错误的情况下,有些突变可能不会一直未成年人正确压缩到HDFS。在这种情况下,将自动重新Accumulo这种突变的预写日志时,片从故障服务器重新分配由主,在一个单一的TabletServer故障的情况下,或下一次启动Accumulo,在发生故障时,关机期间。
要求预写日志记录器复制到HDFS进行恢复。复制日志,他们还整理,使平板电脑可以很容易地找到他们失踪的更新。在Accumulo监控状态页显示每个文件的复制/排序状态。一旦恢复完成涉及任何片应回到``在线“状态,到那时,这些药片将无法给客户。
Accumulo客户端库配置重试失败的突变,并在许多情况下,客户将能够继续处理后的恢复过程中,没有抛出任何异常。
你可能感兴趣的:(分布式系统基本原理)