贝壳找房基于 Flink 的实时平台建设
摘要:本文由贝壳找房实时计算负责人刘力云分享,主要内容为 Apache Flink 在贝壳找房业务中的应用,分为以下三方面:
-
业务规模与演进
-
Hermes 实时计算平台介绍
-
未来发展与规划
业务规模及演进
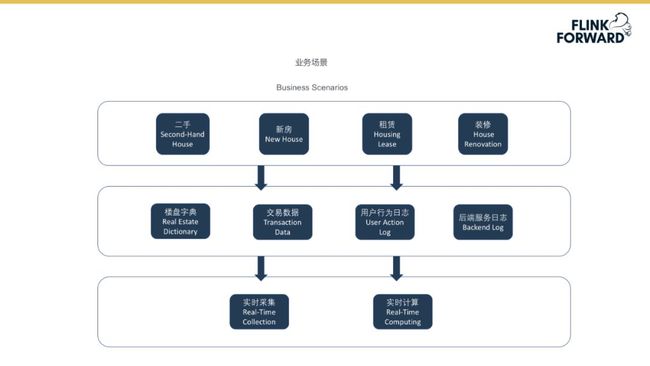
下图为贝壳找房的业务场景示意图。最上层为贝壳找房公司最为主体的四大业务:二手房交易、新房交易、租赁业务及装修业务。四大业务运营将产生图示中间部分的四大数据即楼盘字典、交易数据、用户行为日志与后端服务日志。图示最下面的部分代表公司实时数据采集、实时数据计算的业务模块,本文中的案例将重点介绍数据实时计算部分的设计、实现及应用。
发展历程
在 2018 年初,随着公司埋点治理规范的推进,我们建设了 DP 实时数据总线,统一承接各种埋点数据流的标准化处理,并对外提供清洗后的实时数据。随着维护的实时任务增加,面临着实时数据流稳定性以及任务管理方面的挑战,于是贝壳大数据部着手研发了 Hermes 实时计算平台,提供统一的实时任务管理平台。
在 2018 年 10 月,我们推出了 SQL V1 编辑器来方便用户开发实时计算任务。SQL V1 基于 Spark Structured Streaming 技术,用户可以使用 SQL 完成需求的开发,同时以界面拖拽的形式呈现给用户,使用户的操作更加便捷。在 2019 年 5 月,经过调研对比,我们引入了 Flink 技术栈,研发的 SQL V2 编辑器正式上线,SQL V2 全面支持 Flink SQL 的各种语法并设计了大量的自定义函数,兼容 Hive UDF 以及用户常用函数。目前我们已经在公司内进行实时数仓业务场景的探索应用。

应用规模
下图所示为目前实时计算在贝壳找房企业中的应用规模。目前平台支持 30 余个业务项目,流计算任务数达到 400 个,随着数仓的不断扩充,实时流计算的任务数将不断上升。每日处理的消息条数达到了 800 亿级别,效率十分可观。

支持的项目
从下图所示实时计算在企业中的支持项目可以看出,目前实时计算平台支持从风控、租赁到策略搜索再到新房交易等一系列业务项目,从各个维度支持起企业运营产生的数据实时计算的业务需求。

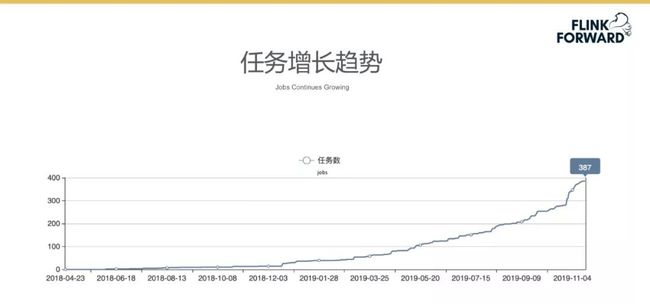
任务增长趋势
最开始平台上线时支持的任务增长较为缓慢,在 2019 年 6 月初,平台升级到 Flink 并全面支持 SQL 开发后,任务数量开始大规模的增长,在 2019 年 11 月份实时数仓建成后,平台所支持的任务数量有了十分明显的增长趋势。
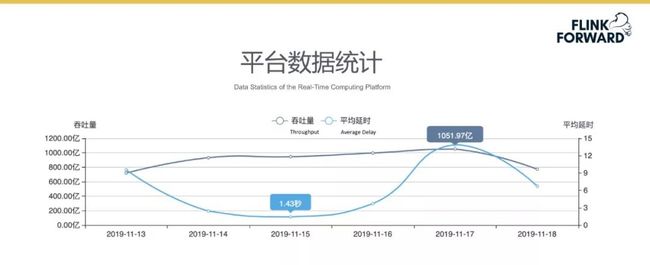
平台数据统计
下图所示为平台每日数据统计。目前平台每日可以处理 1000 亿条数据,一般数据任务的处理延迟在 40 毫秒左右。
Hermes 实时计算平台介绍
平台概览
Hermes 平台目前支持着公司实时任务的开发、编辑、部署、启停等管理功能及丰富的监控报警等服务。平台支持 Java、Scala、Python 等多种语言开发的实时任务,支持自定义任务、模板任务及场景任务三大任务类型,同时做到了各个项目的资源隔离,每个项目均有项目的专有队列,防止与其他项目在资源上发生竞争。平台同时为资源需求较小的项目提供了公共队列,通过公共队列对该种项目进行支持的方式,更为方便的实现任务的开发。

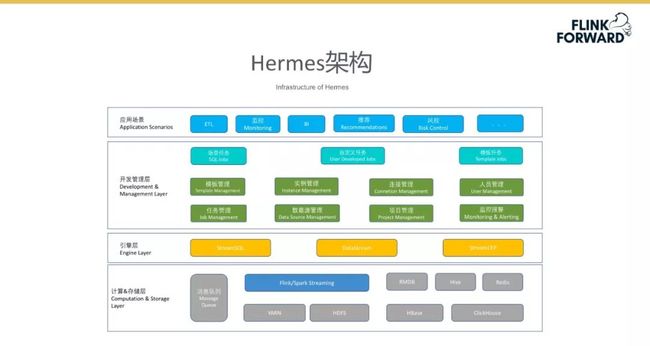
Hermes 架构
下图所示为 Hermes 平台的整体架构,架构分为 4 个层次,图中最下层深蓝条目代表架构中的计算引擎,目前计算引擎支持 Flink 与 Spark Streaming 技术,并通过消息队列、离线存储等技术辅助完成数据实时的存储。
-
在引擎层方面,架构采用 StreamSQL、DataStream、StreamCEP 等技术搭建,其中 StreamCEP 技术很好的支持了经纪人平台业务实时监控报警的需求。
-
功能组件层方面包括了任务实例的管理、项目管理及数据源管理等。
平台目前可以在同一任务中的不同任务快照间进行相互切换,当发现上线任务有问题时,可以回退到之前的快照。
SQL V1 编辑器
下图所示为 SQL V1 编辑器示意图。该编辑器对于大部分数据清洗及数据处理的业务场景可以实现简洁高效的编辑处理。用户在编辑器左侧可以定义编辑数据源、操作符及目标源等数据信息。中央面板上呈现的数据为 SQL V1 支持编辑的操作类型,选中面板中央的过滤器,即可在编辑器右侧添加相关的过滤条件,实现数据的相关过滤。在目标源层面,编辑器目前支持 Kafka、Druid 等多种目标源,大大提升了编辑器的兼容性。

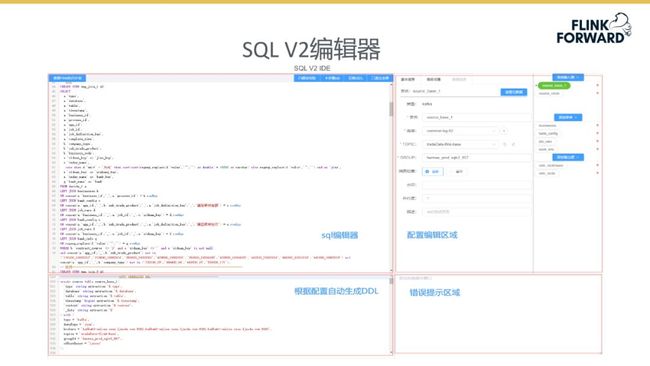
SQL V2 编辑器
下图所示为 SQL V2 编辑器示意图。目前 SQL V2 是基于 Flink SQL 技术较为完善的编辑器,左侧为用户进行代码编辑的部分,用户在此处可以编辑大量 SQL 语句以此助力不同业务场景。左下栏目中的数据为用户选中数据源自动生成的 DDL,通过 DDL 编辑器将操作数据的样式更清晰的展示给用户。SQL V2 支持了三大类型的数据表,分别是 source 表、sink 表及维表,以此方便用户的开发。编辑器右下角可以呈现 SQL 语法的检测情况,以此提示用户在编辑时出现的语法错误。
SQL V2 架构
SQL V2 工具整体架构如下图所示。前端 SQL 编辑器模块包括语法语义的检查、执行计划的查看、自动 DDL 的生成及任务调试的功能。用户通过任务调试功能可以查看任务执行结果。后台将引擎提交到 Yarn 集群上执行,引擎通过任务 id 回调后台接口获取需要执行的 SQL,对 SQL 做语法校验和语法解析,若出现维表关联则会额外对 SQL 做一层转换。

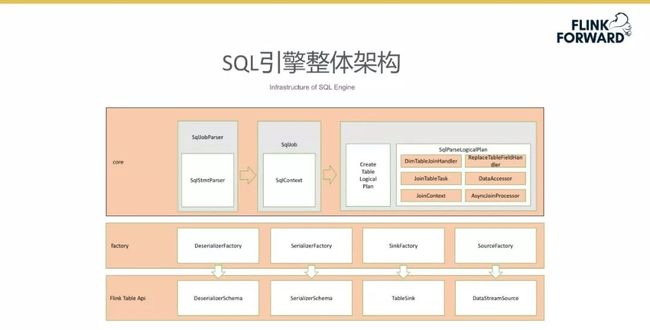
SQL 引擎整体架构
下图所示为 SQL 引擎的整体架构。整体架构分为三个层次,最底层为 Flink Table API。在 Flink 层之上企业设计了代码的封装,以 factory 的形式方便最上层的方法调用。最上层的 core 层负责整个系统的 SQL 解析。
维表关联
在 SQL 解析过程中,最为复杂的是维表的表格关联,下图为维表关联系统架构图。数据从数据源导入后,系统使用 Async I/O 技术访问后端,系统后端使用 Data Accessor 接口访问后端的存储。系统后端存储支持 HBase 与 Redis 存储技术,同时后端会将数据缓存于 LRU Cache 模块中。维表关联后的数据支持多种大数据工具的存储,从而大大增加了系统的兼容性。

丰富的内置函数
系统同时为用户提供了丰富的内置函数,包括时间函数、集合函数、Json 处理函数及字符串函数。丰富的内置函数可以方便用户的开发,省去用户自己去开发的时间。

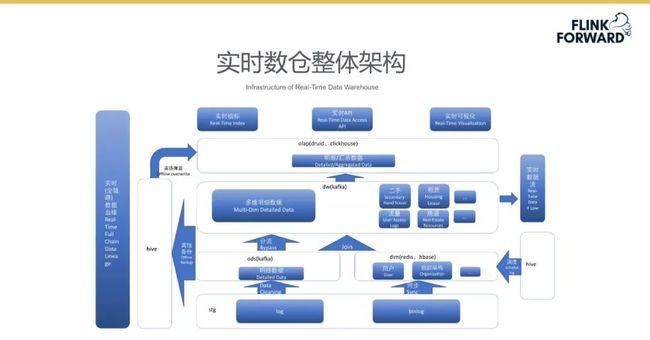
实时数仓整体架构
下图所示为实时数仓的整体架构,同时也是 SQL V2 系统落地的应用场景。各个层级间产生的数据被储存在了 Kafka Topic 中,同时数据也将被同步到 Hive 中备份。业务方可以查询实时备份数据进行数据验证及分析等操作。目前数仓的实时计算部分可以计算当天或过往几天的数据,实时计算平台正在与其他组件合作,开发实时与离线联合的分析查询,以此扩展实时数仓的使用范围。
实时数仓数据统计
下图所示为企业实时数仓的数据统计。从 2019 年 8 月,SQL V2 正式上线运营,至 2019 年 10 月平台开始支持实时数仓开发,系统的数据量开始加速增长。目前,实时数仓已经有 100 余个任务,数据吞吐量也达到了 21 亿条/天的数据级别,数据规模较为可观。

实时数仓案例
下图列举出实时数仓平台已经实现提供数据支持的应用案例。
1. 交易平台
交易平台实时大屏实时展示大区内的交易状况。在交易平台的建设中,开发团队通过数据回环将还未关联的数据返回储存模块进行重新关联,并通过检验该数据的生命周期判断是否关联成功,团队通过此种方式使得数据维表与事实表数据最终一致。
2. 经纪人行程量
经纪人行程量可以动态的展示当前经纪人对客户的维护情况,使企业可以掌握经纪人实时的工作状态。
3. 实时用户画像
实时用户画像可以实时地向企业呈现来自各个系统用户的数据信息,通过组合各个平台上用户的行为信息,提供全面、精准的用户画像。企业的算法策略部门将根据用户的实时画像进行相关信息、内容的推荐。

监控报警
下图为平台的监控报警页面截图。监控系统会实时监控平台任务的处理延时、 source 写入量及 sink 写出量三大指标。系统中同时可以设置平台数据的无心跳时间,当超出设置时限后,系统将会进行报警。

监控报警架构
下图为监控报警架构图。监控系统通过自定义的 Listener 对 Spark 进行监控,Listener 引入 SDK 收集 Spark 任务的信息及运行中的日志数据。用户在此处需要进行手动 SDK 的导入。在 Flink 应用模块中,系统设计支持了自定义 Report 数据的获取,并通过自动加载的方式直接载入 Flink 中进行数据的分析与计算,同时通过任务启动时注入 java 探针的方式获取任务的相关信息。所有的监控信息将被统一送到 Kafka Topic 中,经 Hermes 平台分析处理,触发相应的延时报警及心跳报警。

未来发展与规划
整体架构
实时计算平台的整体架构如下图所示。在架构中间部分,平台包含了实时事件中心、事件处理平台等系统来更好的处理未来企业中的业务场景需求,以通用服务平台的方式为更多的业务方提供统一的业务支撑。在引擎方面,未来会深入研究 Flink 的状态管理、端到端的精确一次等技术,提高数据处理的准确性和一致性。

未来发展
未来将会加强平台的资源动态分配能力,根据任务的历史运行情况自动分配资源。
-
用户可以在事件处理平台上定义各种事件,实时对事件进行分析,并产生相关的数据报表。用户通过实时规则引擎完成各种业务规则的配置,事件命中规则后触发相关的业务操作。
-
用户数据平台汇集各个产品、各个端的用户数据,提供用户行为的实时查询、分析,更加高效的支持营销、推荐等业务场景。
-
实时数仓建设方面会进行 KAPPA 模式的探索,推进流批一体化建设,提升历史数据的处理和查询能力。

往期推荐
1、HBase最佳实践 | 聊聊HBase核心配置参数
2、Apache Hudi:剑指数据湖的增量处理框架
3、Hadoop社区比 Ozone 更重要的事情
4、MapReduce Shuffle 和 Spark Shuffle 结业篇
