Android Paging library详解(二)
重要API及源码分析
文章目录
- 1.重要API介绍
- 1.1 DataSource
- 1.2 PageList
- 1.3 PagedListAdapter
- 2.源码解析
1.重要API介绍
Paging主要由三个部分组成:DataSource PageList PageListAdapter
1.1 DataSource
DataSource从字面意思理解是一个数据源,其中key对应加载数据的条件信息,Value对应加载数据的实体类。
DataSource是一个抽象类,但是我们不能直接继承它实现它的子类。但是Paging库里提供了它的三个子类供我们继承用于不同场景的实现:
PageKeyedDataSource:适用于目标数据根据页信息请求数据的场景,即Key 字段是页相关的信息。比如请求的数据的参数中包含类似next/previous页数的信息。
ItemKeyedDataSource:适用于目标数据的加载依赖特定item的信息, 即Key字段包含的是Item中的信息,比如需要根据第N项的信息加载第N+1项的数据,传参中需要传入第N项的ID时,该场景多出现于论坛类应用评论信息的请求。
PositionalDataSource:适用于目标数据总数固定,通过特定的位置加载数据,这里Key是Integer类型的位置信息,T即Value。 比如从数据库中的1200条开始加在20条数据。
1.2 PageList
PageList是一个List的子类,支持所有List的操作,除此之外它主要有五个成员:
mMainThreadExecutor: 一个主线程的Excutor, 用于将结果post到主线程。
mBackgroundThreadExecutor: 后台线程的Excutor.
BoundaryCallback:加载Datasource中的数据加载到边界时的回调.
Config: 配置PagedList从Datasource加载数据的方式, 其中包含以下属性:
pageSize:设置每页加载的数量
prefetchDistance:预加载的数量,默认为pagesize
initialLoadSizeHint:初始化数据时加载的数量,默认为pageSize*3
enablePlaceholders:当item为null是否使用PlaceHolder展示
PagedStorage: 用于存储加载到的数据,它是真正的蓄水池所在,它包含一个ArrayList 对象mPages,按页存储数据。
PagedList会从Datasource中加载数据,更准确的说是通过Datasource加载数据, 通过Config的配置,可以设置一次加载的数量以及预加载的数量。 除此之外,PagedList还可以向RecyclerView.Adapter发送更新的信号,驱动UI的刷新。
1.3 PagedListAdapter
PagedListAdapte是RecyclerView.Adapter的实现,用于展示PagedList的数据。它本身实现的更多是Adapter的功能,但是它有一个小伙伴PagedListAdapterHelper, PagedListAdapterHelper会负责监听PagedList的更新, Item数量的统计等功能。这样当PagedList中新一页的数据加载完成时, PagedAdapte就会发出加载完成的信号,通知RecyclerView刷新,这样就省略了每次loading后手动调一次notifyDataChanged().
除此之外,当数据源变动产生新的PagedList,PagedAdapter会在后台线程中比较前后两个PagedList的差异,然后调用notifyItem…()方法更新RecyclerView.这一过程依赖它的另一个小伙伴ListAdapterConfig, ListAdapterConfig负责主线程和后台线程的调度以及DiffCallback的管理,DiffCallback的接口实现中定义比较的规则,比较的工作则是由PagedStorageDiffHelper来完成。
2.源码解析
下图为Paging工作的原理
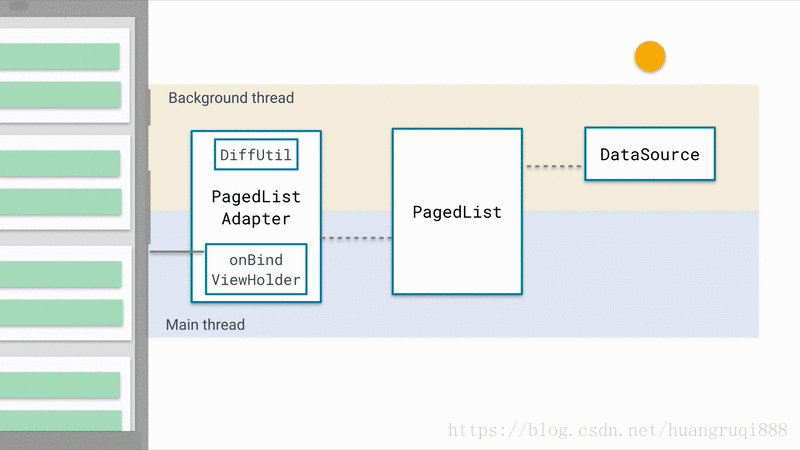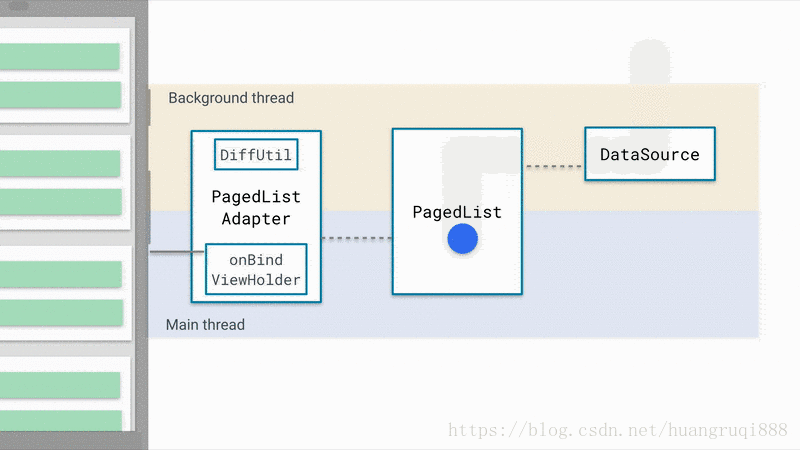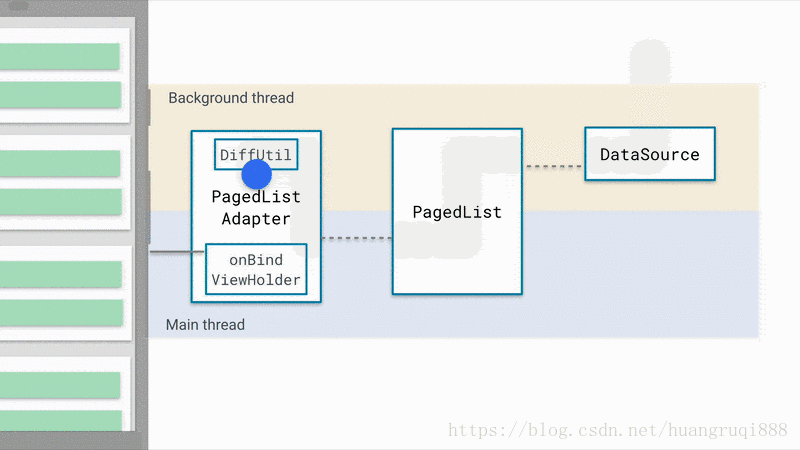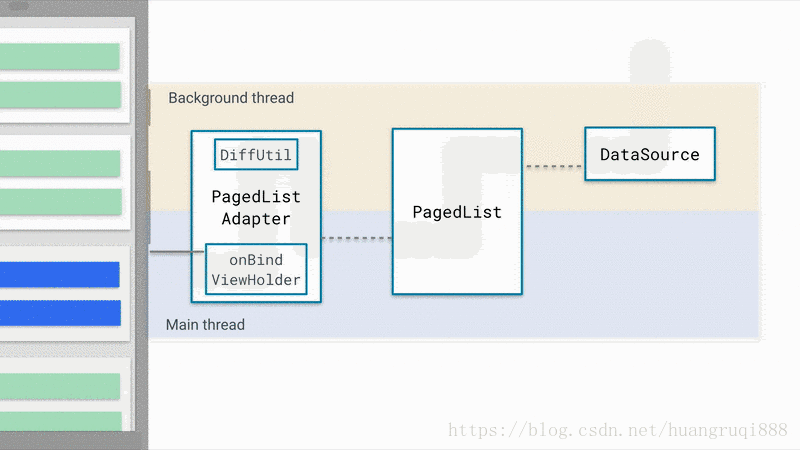
这是官方提供的非常棒的原理示意图,简单概括一下:
DataSource: 数据源,数据的改变会驱动列表的更新,因此,数据源是很重要的
PageList: 核心类,它从数据源取出数据,同时,它负责控制 第一次默认加载多少数据,之后每一次加载多少数据,如何加载等等,并将数据的变更反映到UI上。
PagedListAdapter: 适配器,RecyclerView的适配器,通过分析数据是否发生了改变,负责处理UI展示的逻辑(增加/删除/替换等)。
1.创建数据源
我们思考一个问题,将数据作为列表展示在界面上,我们首先需要什么。
数据源,是的,在Paging中,它被抽象为 DataSource , 其获取需要依靠 DataSource 的内部工厂类 DataSource.Factory ,通过create()方法就可以获得DataSource 的实例:
public abstract static class Factory<Key, Value> {
public abstract DataSource<Key, Value> create();
}
数据源一般有两种选择,远程服务器请求 或者 读取本地持久化数据——这些并不重要,本文我们以Room数据库为例:
@Dao
interface StudentDao {
@Query("SELECT * FROM Student ORDER BY name COLLATE NOCASE ASC")
fun getAllStudent(): DataSource.Factory<Int, Student>
}
Paging可以获得 Room的原生支持,因此作为示例非常合适,当然我们更多获取 数据源 是通过 API网络请求,其实现方式可以参考官方Sample,本文不赘述。
现在我们创建好了StudentDao,接下来就是展示UI了,在那之前,我们需要配置好PageList。
2.配置PageList
上文我说到了PageList的作用:
1.从数据源取出数据
2.负责控制 第一次默认加载多少数据,之后每一次加载多少数据,如何加载 等等
3.将数据的变更反映到UI上。
我们仔细想想,这是有必要配置的,因此我们需要初始化PageList:
val allStudents = LivePagedListBuilder(dao.getAllStudent(), PagedList.Config.Builder()
.setPageSize(15) //配置分页加载的数量
.setEnablePlaceholders(false) //配置是否启动PlaceHolders
.setInitialLoadSizeHint(30) //初始化加载的数量
.build()).build()
我们按照上面分的三个职责来讲:
-
从数据源取出数据
很显然,这对应的是 dao.getAllStudent() ,通过数据库取得最新数据,如果是网络请求,也应该对应API的请求方法,返回值应该是DataSource.Factory类型。 -
进行相关配置
PageList提供了 PagedList.Config 类供我们进行实例化配置,其提供了4个可选配置:
public static final class Builder {
// 省略其他Builder内部方法
private int mPageSize = -1; //每次加载多少数据
private int mPrefetchDistance = -1; //距底部还有几条数据时,加载下一页数据
private int mInitialLoadSizeHint = -1; //第一次加载多少数据
private boolean mEnablePlaceholders = true; //是否启用占位符,若为true,则视为固定数量的item
}
- 将变更反映到UI上
这个指的是 LivePagedListBuilder,而不是 PagedList.Config.Builder,它可以设置 获取数据源的线程 和 边界Callback,但是一般来讲可以不用配置,大家了解一下即可。
经过以上操作,我们的PageList设置好了,接下来就可以配置UI相关了。
3.配置Adapter
就像我们平时配置 RecyclerView 差不多,我们配置了ViewHolder和RecyclerView.Adapter,略微不同的是,我们需要继承PagedListAdapter:
class StudentAdapter : PagedListAdapter<Student, StudentViewHolder>(diffCallback) {
//省略 onBindViewHolder() && onCreateViewHolder()
companion object {
private val diffCallback = object : DiffUtil.ItemCallback<Student>() {
override fun areItemsTheSame(oldItem: Student, newItem: Student): Boolean =
oldItem.id == newItem.id
override fun areContentsTheSame(oldItem: Student, newItem: Student): Boolean =
oldItem == newItem
}
}
}
当然我们还需要传一个 DifffUtil.ItemCallback 的实例,这里需要对数据源返回的数据进行了比较处理, 它的意义是——我需要知道怎么样的比较,才意味着数据源的变化,并根据变化再进行的UI刷新操作。
ViewHolder的代码正常实现即可,不再赘述。
4.监听数据源的变更,并响应在UI上
这个就很简单了,我们在Activity中声明即可:
val adapter = StudentAdapter()
recyclerView.adapter = adapter
viewModel.allStudents.observe(this, Observer { adapter.submitList(it) })
这样,每当数据源发生改变,Adapter就会自动将 新的数据 动态反映在UI上。
为什么不能把所有功能都封装到一个 RecyclerView的Adapter里面呢,它包含 下拉刷新,上拉加载分页 等等功能?
原因很简单,因为这样做会将业务层代码和UI层混在一起造成耦合 ,最直接就导致了 难 以通过代码进行单元测试。
UI层 和 业务层 代码的隔离是优秀的设计,这样更便于 测试, 从Google官方文档也可以看出。指导文档包括UI组件和数据组件。
接下来,我会尝试站在设计者的角度,尝试去理解 Paging 如此设计的原因。
1.PagedListAdapter:基于RecyclerView的封装
将分页数据作为List展示在界面上,RecyclerView 是首选,那么实现一个对应的 PagedListAdapter 当然是不错的选择。
Google对 PagedListAdapter 的职责定义的很简单,仅仅是一个被代理的对象而已,所有相关的数据处理逻辑都委托给了 AsyncPagedListDiffer:
/* Advanced users that wish for more control over adapter behavior, or to provide a specific base
* class should refer to {@link AsyncPagedListDiffer}, which provides the mapping from paging
* events to adapter-friendly callbacks.
*
* @param Type of the PagedLists this Adapter will receive.
* @param A class that extends ViewHolder that will be used by the adapter.
*/
public abstract class PagedListAdapter<T, VH extends RecyclerView.ViewHolder>
extends RecyclerView.Adapter<VH> {
private final AsyncPagedListDiffer<T> mDiffer;
private final AsyncPagedListDiffer.PagedListListener<T> mListener =
new AsyncPagedListDiffer.PagedListListener<T>() {
@Override
public void onCurrentListChanged(@Nullable PagedList<T> currentList) {
PagedListAdapter.this.onCurrentListChanged(currentList);
}
};
/**
* Creates a PagedListAdapter with default threading and
* {@link android.support.v7.util.ListUpdateCallback}.
*
* Convenience for {@link #PagedListAdapter(AsyncDifferConfig)}, which uses default threading
* behavior.
*
* @param diffCallback The {@link DiffUtil.ItemCallback DiffUtil.ItemCallback} instance to
* compare items in the list.
*/
protected PagedListAdapter(@NonNull DiffUtil.ItemCallback<T> diffCallback) {
mDiffer = new AsyncPagedListDiffer<>(this, diffCallback);
mDiffer.mListener = mListener;
}
@SuppressWarnings("unused, WeakerAccess")
protected PagedListAdapter(@NonNull AsyncDifferConfig<T> config) {
mDiffer = new AsyncPagedListDiffer<>(new AdapterListUpdateCallback(this), config);
mDiffer.mListener = mListener;
}
/**
* Set the new list to be displayed.
*
* If a list is already being displayed, a diff will be computed on a background thread, which
* will dispatch Adapter.notifyItem events on the main thread.
*
* @param pagedList The new list to be displayed.
*/
public void submitList(PagedList<T> pagedList) {
mDiffer.submitList(pagedList);
}
@Nullable
protected T getItem(int position) {
return mDiffer.getItem(position);
}
@Override
public int getItemCount() {
return mDiffer.getItemCount();
}
/**
* Returns the PagedList currently being displayed by the Adapter.
*
* This is not necessarily the most recent list passed to {@link #submitList(PagedList)},
* because a diff is computed asynchronously between the new list and the current list before
* updating the currentList value. May be null if no PagedList is being presented.
*
* @return The list currently being displayed.
*/
@Nullable
public PagedList<T> getCurrentList() {
return mDiffer.getCurrentList();
}
/**
* Called when the current PagedList is updated.
*
* This may be dispatched as part of {@link #submitList(PagedList)} if a background diff isn't
* needed (such as when the first list is passed, or the list is cleared). In either case,
* PagedListAdapter will simply call
* {@link #notifyItemRangeInserted(int, int) notifyItemRangeInserted/Removed(0, mPreviousSize)}.
*
* This method will notbe called when the Adapter switches from presenting a PagedList
* to a snapshot version of the PagedList during a diff. This means you cannot observe each
* PagedList via this method.
*
* @param currentList new PagedList being displayed, may be null.
*/
@SuppressWarnings("WeakerAccess")
public void onCurrentListChanged(@Nullable PagedList<T> currentList) {
}
}
当数据源发生改变时,实际上会通知 AsyncPagedListDiffer 的 submitList() 方法通知其内部保存的 PagedList 更新并反映在UI上:
//实际上内部存储了要展示在UI上的数据源PagedList分页加载如何触发的呢?
如果你认真思考了,肯定是在我们滑动list的时候加载到某一项的时候触发的,当RecyclerView滑动的时候会触发getItem()执行
public T getItem(int index) {
if (mPagedList == null) {
if (mSnapshot == null) {
throw new IndexOutOfBoundsException(
"Item count is zero, getItem() call is invalid");
} else {
return mSnapshot.get(index);
}
}
mPagedList.loadAround(index);
return mPagedList.get(index);
}
其中, 触发下一页加载的就是PagingList中的loadAround(int index) 方法。
/**
* Load adjacent items to passed index.
*
* @param index Index at which to load.
*/
public void loadAround(int index) {
mLastLoad = index + getPositionOffset();
loadAroundInternal(index);
mLowestIndexAccessed = Math.min(mLowestIndexAccessed, index);
mHighestIndexAccessed = Math.max(mHighestIndexAccessed, index);
/*
* mLowestIndexAccessed / mHighestIndexAccessed have been updated, so check if we need to
* dispatch boundary callbacks. Boundary callbacks are deferred until last items are loaded,
* and accesses happen near the boundaries.
*
* Note: we post here, since RecyclerView may want to add items in response, and this
* call occurs in PagedListAdapter bind.
*/
tryDispatchBoundaryCallbacks(true);
}
PagedList,也有很多种不同的 数据分页策略:

这些不同的 PagedList 在处理分页逻辑上,可能有不同的逻辑,那么,作为设计者,应该做到的是**,把异同的逻辑抽象出来交给子类实现(即loadAroundInternal方法),而把公共的处理逻辑暴漏出来**,并向上转型交给Adapter(实际上是 AsyncPagedListDiffer)去执行分页加载的API,也就是loadAround方法。
好处显而易见,对于Adapter来说,它只需要知道,在我需要请求分页数据时,调用PagedList的loadAround方法即可,至于 是PagedList的哪个子类,内部执行什么样的分页逻辑,Adapter并不关心。
这些PagedList的不同策略的逻辑,是在PagedList.create()方法中进行的处理:
/**
* Create a PagedList which loads data from the provided data source on a background thread,
* posting updates to the main thread.
*
*
* @param dataSource DataSource providing data to the PagedList
* @param notifyExecutor Thread that will use and consume data from the PagedList.
* Generally, this is the UI/main thread.
* @param fetchExecutor Data loading will be done via this executor -
* should be a background thread.
* @param boundaryCallback Optional boundary callback to attach to the list.
* @param config PagedList Config, which defines how the PagedList will load data.
* @param Key type that indicates to the DataSource what data to load.
* @param Type of items to be held and loaded by the PagedList.
*
* @return Newly created PagedList, which will page in data from the DataSource as needed.
*/
@NonNull
private static <K, T> PagedList<T> create(@NonNull DataSource<K, T> dataSource,
@NonNull Executor notifyExecutor,
@NonNull Executor fetchExecutor,
@Nullable BoundaryCallback<T> boundaryCallback,
@NonNull Config config,
@Nullable K key) {
if (dataSource.isContiguous() || !config.enablePlaceholders) {
int lastLoad = ContiguousPagedList.LAST_LOAD_UNSPECIFIED;
if (!dataSource.isContiguous()) {
//noinspection unchecked
dataSource = (DataSource<K, T>) ((PositionalDataSource<T>) dataSource)
.wrapAsContiguousWithoutPlaceholders();
if (key != null) {
lastLoad = (int) key;
}
}
ContiguousDataSource<K, T> contigDataSource = (ContiguousDataSource<K, T>) dataSource;
return new ContiguousPagedList<>(contigDataSource,
notifyExecutor,
fetchExecutor,
boundaryCallback,
config,
key,
lastLoad);
} else {
return new TiledPagedList<>((PositionalDataSource<T>) dataSource,
notifyExecutor,
fetchExecutor,
boundaryCallback,
config,
(key != null) ? (Integer) key : 0);
}
}
PagedList是一个抽象类,实际上它的作用是 通过Builder实例化PagedList真正的对象:
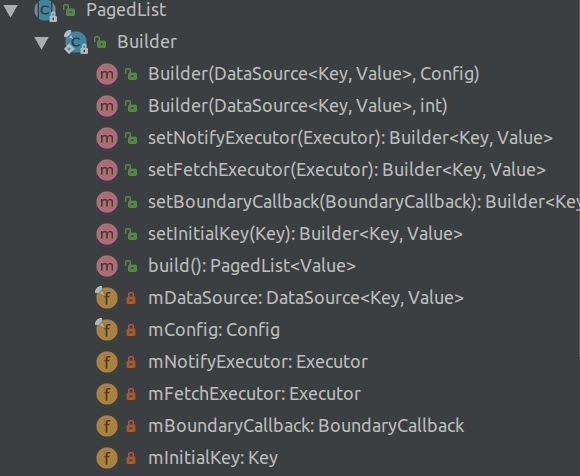
通过Builder.build()调用create()方法,决定实例化哪个PagedList的子类:
public PagedList<Value> build() {
// TODO: define defaults, once they can be used in module without android dependency
if (mNotifyExecutor == null) {
throw new IllegalArgumentException("MainThreadExecutor required");
}
if (mFetchExecutor == null) {
throw new IllegalArgumentException("BackgroundThreadExecutor required");
}
//noinspection unchecked
return PagedList.create(
mDataSource,
mNotifyExecutor,
mFetchExecutor,
mBoundaryCallback,
mConfig,
mInitialKey);
}
}
Builder模式是非常耳熟能详的设计模式,它的好处是作为API的门面,便于开发者更简单上手并进行对应的配置。
不同的PagedList对应不同的DataSource,比如:
ContiguousPagedList 对应ContiguousDataSource
ContiguousPagedList(
@NonNull ContiguousDataSource<K, V> dataSource,
@NonNull Executor mainThreadExecutor,
@NonNull Executor backgroundThreadExecutor,
@Nullable BoundaryCallback<V> boundaryCallback,
@NonNull Config config,
final @Nullable K key,
int lastLoad)
TiledPagedList 对应 PositionalDataSource
@WorkerThread
TiledPagedList(@NonNull PositionalDataSource<T> dataSource,
@NonNull Executor mainThreadExecutor,
@NonNull Executor backgroundThreadExecutor,
@Nullable BoundaryCallback<T> boundaryCallback,
@NonNull Config config,
int position)
回到create()方法中,我们看到dataSource此时也仅仅是抽象类型的声明:
private static <K, T> PagedList<T> create(@NonNull DataSource<K, T> dataSource,
@NonNull Executor notifyExecutor,
@NonNull Executor fetchExecutor,
@Nullable BoundaryCallback<T> boundaryCallback,
@NonNull Config config,
@Nullable K key)
实际上,create方法的作用是,通过将不同的DataSource,作为依赖实例化对应的PagedList,除此之外,还有对DataSource的对应处理,或者Wrapper(再次包装,详情请参考源码的create方法,篇幅所限本文不再叙述)。
这个过程中,通过Builder,将 多种数据源(DataSource),多种分页策略(PagedList) 互相进行组合,并 向上转型 交给 适配器(Adapter) ,然后Adapter将对应的功能 委托 给了 代理类的AsyncPagedListDiffer 处理——这之间通过数种设计模式的组合,最终展现给开发者的是一个 简单且清晰 的API接口去调用,其设计的精妙程度,远非普通的开发者所能企及。
数据库分页实现源码
public abstract class LimitOffsetDataSource<T> extends PositionalDataSource<T> {
private final RoomSQLiteQuery mSourceQuery;
private final String mCountQuery;
private final String mLimitOffsetQuery;
private final RoomDatabase mDb;
@SuppressWarnings("FieldCanBeLocal")
private final InvalidationTracker.Observer mObserver;
private final boolean mInTransaction;
protected LimitOffsetDataSource(RoomDatabase db, SupportSQLiteQuery query,
boolean inTransaction, String... tables) {
this(db, RoomSQLiteQuery.copyFrom(query), inTransaction, tables);
}
protected LimitOffsetDataSource(RoomDatabase db, RoomSQLiteQuery query,
boolean inTransaction, String... tables) {
mDb = db;
mSourceQuery = query;
mInTransaction = inTransaction;
mCountQuery = "SELECT COUNT(*) FROM ( " + mSourceQuery.getSql() + " )";
mLimitOffsetQuery = "SELECT * FROM ( " + mSourceQuery.getSql() + " ) LIMIT ? OFFSET ?";
mObserver = new InvalidationTracker.Observer(tables) {
@Override
public void onInvalidated(@NonNull Set<String> tables) {
invalidate();
}
};
db.getInvalidationTracker().addWeakObserver(mObserver);
}
/**
* Count number of rows query can return
*/
@SuppressWarnings("WeakerAccess")
public int countItems() {
final RoomSQLiteQuery sqLiteQuery = RoomSQLiteQuery.acquire(mCountQuery,
mSourceQuery.getArgCount());
sqLiteQuery.copyArgumentsFrom(mSourceQuery);
Cursor cursor = mDb.query(sqLiteQuery);
try {
if (cursor.moveToFirst()) {
return cursor.getInt(0);
}
return 0;
} finally {
cursor.close();
sqLiteQuery.release();
}
}
@Override
public boolean isInvalid() {
mDb.getInvalidationTracker().refreshVersionsSync();
return super.isInvalid();
}
@SuppressWarnings("WeakerAccess")
protected abstract List<T> convertRows(Cursor cursor);
@Override
public void loadInitial(@NonNull LoadInitialParams params,
@NonNull LoadInitialCallback<T> callback) {
int totalCount = countItems();
if (totalCount == 0) {
callback.onResult(Collections.<T>emptyList(), 0, 0);
return;
}
// bound the size requested, based on known count
final int firstLoadPosition = computeInitialLoadPosition(params, totalCount);
final int firstLoadSize = computeInitialLoadSize(params, firstLoadPosition, totalCount);
List<T> list = loadRange(firstLoadPosition, firstLoadSize);
if (list != null && list.size() == firstLoadSize) {
callback.onResult(list, firstLoadPosition, totalCount);
} else {
// null list, or size doesn't match request - DB modified between count and load
invalidate();
}
}
@Override
public void loadRange(@NonNull LoadRangeParams params,
@NonNull LoadRangeCallback<T> callback) {
List<T> list = loadRange(params.startPosition, params.loadSize);
if (list != null) {
callback.onResult(list);
} else {
invalidate();
}
}
/**
* Return the rows from startPos to startPos + loadCount
*/
@Nullable
public List<T> loadRange(int startPosition, int loadCount) {
final RoomSQLiteQuery sqLiteQuery = RoomSQLiteQuery.acquire(mLimitOffsetQuery,
mSourceQuery.getArgCount() + 2);
sqLiteQuery.copyArgumentsFrom(mSourceQuery);
sqLiteQuery.bindLong(sqLiteQuery.getArgCount() - 1, loadCount);
sqLiteQuery.bindLong(sqLiteQuery.getArgCount(), startPosition);
if (mInTransaction) {
mDb.beginTransaction();
Cursor cursor = null;
try {
cursor = mDb.query(sqLiteQuery);
List<T> rows = convertRows(cursor);
mDb.setTransactionSuccessful();
return rows;
} finally {
if (cursor != null) {
cursor.close();
}
mDb.endTransaction();
sqLiteQuery.release();
}
} else {
Cursor cursor = mDb.query(sqLiteQuery);
//noinspection TryFinallyCanBeTryWithResources
try {
return convertRows(cursor);
} finally {
cursor.close();
sqLiteQuery.release();
}
}
}
}
3.更多
实际上,笔者上文所叙述的内容只是 Paging 的冰山一角,其源码中,还有很多很值得学习的优秀思想,本文无法一一列举,比如 线程的切换(加载分页数据应该在io线程,而反映在界面上时则应该在ui线程),再比如库 对多种响应式数据类型的支持(LiveData,RxJava),这些实用的功能实现,都通过 Paging 优秀的设计,将其复杂的实现封装了起来,而将简单的API暴露给开发者调用,有兴趣的朋友可以去研究一下。