深度学习中的正则化方法
引入正则化
在深度学习背景下,大多数正则化策略都会对估计进行正则化。估计的正则化以偏差的增加换取方差的减少。一个有效的正则化是有利的权衡,也就是能显著减少方差而不过度增加偏差。
参数范数惩罚
许多正则化方法通过对目标函数 J 添加一个参数范数惩罚 Ω(θ) ,限制模型的学习能力。正则化后的目标函数记为 J~
J~(θ;X,y)=J(θ;X,y)+αΩ(θ)
通常,在神经网络中只对每一层仿射变换的权重做惩罚而不对偏置做惩罚。精确拟合偏置所需的数据通常比拟合权重少得多。正则化偏置参数可能会导致明显的欠拟合。
在神经网络中,为了减少搜索空间,通常在所有层使用相同的权重衰减。
L2参数正则化
L2正则化通过向目标函数添加一个正则项 Ω(θ)=12||w||22 ,使权重更加接近原点,又称为岭回归或Tikhonov正则。
假定模型没有偏置参数,因此 θ 就是 w 。这样一个模型具有以下总的目标函数:
J~(w;X,y)=α2wTw+J(w;X,y)
与之对应的梯度为
∇wJ~(w;X,y)=αw+∇wJ(w;X,y)
使用单步梯度下降更新权重,即执行以下更新:
w←w−ϵ(αw+∇wJ(w;X,y))
换种写法:
w←(1−ϵα)w−ϵ∇wJ(w;X,y)
即在每步执行通常的梯度更新之前先收缩权重向量。
以上是单个步骤发生的变化,下面介绍在训练的整个过程会发生的变化。
在无助于目标函数减小的方向(对应Hessian矩阵较小的特征值)上改变参数不会显著增加梯度。这种不重要方向对应的分量会在训练过程中因正则化而衰减掉。
L1参数正则化
形式地,对模型参数 w 的L1正则化定义为:
Ω(θ)=||w1||=∑i|wi|
正则化的目标函数如下:
J~(w;X,y)=α||w1||+J(w;X,y)
与之对应的梯度(实际上是次梯度)
∇wJ~(w;X,y)=αsign(w)+∇wJ(w;X,y)
L1正则化不再是线性地缩放每一个 wi ;而是添加了一项与 sign(wi) 同号的常数。
L1正则化产生更稀疏的解。
许多正则化策略可以被解释为MAP贝叶斯推断。L1正则化相当于权重先验是各向同性的拉普拉斯分布。
Dropout
Dropout可以被认为是集成大量深层神经网络的实用Bagging方法。Dropout提供了一种廉价的Bagging集成近似,能够训练和评估指数级数量的神经网络。
Dropout在神经网络训练时以keep_prob的概率保留神经元,其他未保留的神经元失活。
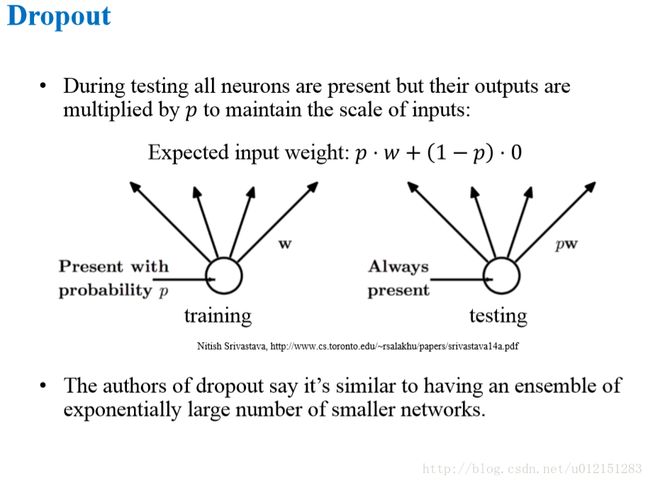
权重比例推断规则 inverted dropout(反向随机失活)
为了得到神经网络单元输出的正确期望值,在训练时将应用了dropout的单元的输出结果除以keep_prob来保持测试时一个单元的期望总输入与训练时该单元的期望总输入是大致相同用的。(测试时不使用dropout)。
对许多不具有非线性隐藏单元的模型族而言,权重比例推断规则是精确的。
对于非常大的数据集,正则化带来的泛化误差减少得很小。使用Dropout和更大规模得计算代价可能超过正则化带来的好处。
只有极少的训练样本可用时,Dropout不会很有效。
数据集增强
让机器学习模型泛化得更好得最好办法是使用更多得数据进行训练。
数据增强对一个具体得分类问题来说特别有效:对象识别。
不能使用会改变类别的转换。例如,光学字符识别任务需要识别到”b”和”d”以及”6”和”9”的区别,这类任务中水平翻转和旋转180度不是合适的方式。
在神经网络的输入层注入噪声也可以被看作是数据增强的一种方式。对于许多分类甚至回归任务,即使小的随机噪声被加到输入,任务仍应该是能够被解决的。
向隐藏层施加噪声也是可行的,可以被看作在多个抽象层上进行的数据集增强。
提前终止
当训练有足够的表示能力甚至会过拟合的大模型时,通常训练误差会随着时间的推移逐渐降低但验证集的误差会再次上升。
元算法
如果我们返回使验证集误差最低的参数设置,就可以获得更好的模型。在每次验证集误差有所改善后,我们存储模型参数的副本。当训练算法终止时,我们返回这些参数而不是最新的参数。当验证集上的误差在事先指定的循环次数内没有进一步改善时,算法就会终止。

训练步数仅是另一个超参数。“训练时间”是唯一只要跑一次训练就能尝试很多值得超参数。通过提前终止自动选择超参数的唯一显著的代价是训练期间定期评估验集。
在理想情况下,这可以并行在与主训练过程分离的机器上,或独立的CPU,或独立的GPU上完整。
另一个额外代价是需要保持最佳的参数副本。
提前终止对减少训练过程的计算成本是有用的。除了由于限制训练的迭代次数而明显减少的计算成本,还带来了正则化的好处(不需要添加惩罚项的代价函数或计算这种附加项的梯度)。
如何利用验证集数据训练
提前终止需要验证集,这意味着某些训练数据不能被馈送到模型。为了更好利用数据,可以在完成提前终止的首次训练后,进行额外的训练。在第二轮额外的训练你步骤中,所有的训练数据都包括在内。有两个基本的策略都可以用于第二轮训练过程。
再次初始化,使用所有数据训练相同步数
这种方法,无法直到重新训练时,对参数进行相同次数的更新和对数据集进行相同的遍数哪一个更好。由于训练集变大了,在第二轮训练时,每一次遍历数据集将会更多次地更新参数。

保持参数,使用所有数据继续训练,直到验证集误差和训练误差相同
此粗略避免了重新训练模型的高成本,但表现并没那么好。例如,验证集的目标不一定能达到之前的目标值,所以甚至不能保证终止。

其他方法
- 作为约束的范数惩罚
待补充 - 正则化和欠约束问题
- 噪声鲁棒性
- 半监督学习
- 多任务学习
- 参数绑定和参数共享
- 稀疏表示
- Bagging
- 对抗训练
- 切面距离,正切传播和流形正切分类器
参考资料
《深度学习》第7章