【Python爬虫】批量抓取网页上的视频
1、为何学python
编程语言方面,本科这几年一直都用C/C++,因为研究生方向与机器学习相关,所以最近大部分时间在学机器学习,看了《机器学习实战》这本书,里面的实例都是用python来写,并且目前来说,对机器学习算法支持得比较多的语言是python,matlab/octave当然也很适合用于机器学习,但是毕竟是学术工具,速度等方面肯定不如python,工业开发还是用python、c++。
总之对于学习机器学习,python以及NumPy库要熟悉。
所以这两天决定学一下python,就找了个评价还不错的公开课看了两天,边看边敲代码,感觉python确实是一门很简单的语言,只要有点C++、C、Java或者其他语言基础,一两天完全可以入门python。当然入门简单,精通难,还是要靠多练。
下面简单的小爬虫程序是看完视频后写的,算是第一个小程序
2、爬虫小程序
因为刚好要看Andrew Ng的机器学习课程,所以就顺便用这个爬虫程序抓取了网页上的视频,网页地址:
http://v.163.com/special/opencourse/machinelearning.html
右键查看源代码,发现提供下载的视频格式都是“.mp4”后缀:

网页上提供下载的视频在源代码中都是这种式:href='http://mov.bn.netease.com/mobilev/2011/9/8/V/S7CTIQ98V.mp4'
据此可以写出所要匹配的正则表达式:r=r" href='(http.*\.mp4)' "
接下来的任务就是获取网页源代码,然后在源代码里面寻找所有匹配正则r的字符串。
抓取源代码可以利用urllib里的urlopen()方法:page=urllib.urlopen(url),返回的是一个页面的对象page,通过html=page.read()可以将页面源代码保存到html变量中。
源代码抓下来之后,就要寻找并获取里面所有的:
href
=' http://mov.bn.netease.com/mobilev/2011/9/8/V/S7CTIQ98V.mp4
'
可以通过正则r,以及正则模块re里的findall方法来获取:mp4List=re.findall(re_mp4,html)
findall返回的是列表,列表里的元素就是视频的地址了,比如下面就是一个视频地址: http://mov.bn.netease.com/mobilev/2011/9/8/V/S7CTIQ98V.mp4
视频的地址抓取下来后,利用模块urllib里的urlretrieve()方法通过视频地址将视频下载下来: urllib.urlretrieve(mp4url),
mp4url是mp4List里的元素。另外还可以给下载下来的视频命名:
urllib.urlretrieve(mp4url,"%s.mp4" %filename),这个filename是个变量,当下载完一个视频后,它就加1,这样所有视频被命名为1.mp4,2.mp4,3.mp4...........
为了便于查看下载进度,可以在urllib.urlretrieve(mp4url,"%s.mp4" %filename)后面加一句:
print 'file "%s.mp4" done' %filename,
这样下载完一个视频后就会输出一行提示
运行效果如下:

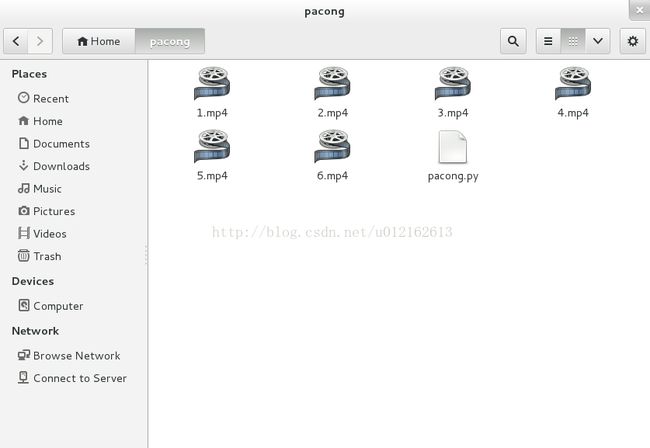
代码如下:(python2.6)
#!/usr/bin/python
import re
import urllib
def getHtml(url):
page=urllib.urlopen(url)
html=page.read()
return html
def getMp4(html):
r=r"href='(http.*\.mp4)'"
re_mp4=re.compile(r)
mp4List=re.findall(re_mp4,html)
filename=1
for mp4url in mp4List:
urllib.urlretrieve(mp4url,"%s.mp4" %filename)
print 'file "%s.mp4" done' %filename
filename+=1
url=raw_input("please input the source url:")
html=getHtml(url)
getMp4(html)