图像超分辨重构(SR)论文整理————适用于刚接触这个领域的初级研究者。(持续更新)
因为最近需要研究一下超分辨重构问题,因此将相关工作进行整理,选取了部分论文进行介绍。如有错误,烦请留言指正。如有版权问题,也请联系博主。
已盘点文章
SRCNN(16,PAMI)
VDSR(16,CVPR)
LapSRN(17,CVPR)
SRGAN(17,CVPR oral)
EDSR(17,CVPR workshop)
RDN(18,CVPR)
RCAN(18,ECCV)
ESRGAN(18,ECCV workshop)
图像的超分辨重构技术(Super-Resolution)是指从一张或多张低分辨率的图像中,重构出相应的高分辨率图像。主要分为两类,一是从单张低分辨率图像中重建出高分辨率图像。二是从多张低分辨率图像中重建出高分辨率图像。基于深度学习的SR,主要是基于单张图像的重构方法。其应用领域非常广泛,涉及军事、医学、地理等。
超分辨重构和去噪、去网格、去模糊等问题是类似的。对于一张低分辨图像,可能会有多张高分辨图像与之对应,因此通常在求解高分辨率图像时会加一个先验信息进行规范化约束。在传统的方法中,通常会先学习这个先验信息。而基于深度学习的SR方法,则是通过神经网络直接进行从低分辨图像到高分辨图像的端到端的学习。
接下来开始介绍已有论文的方法。
1、SRCNN
首先贴出论文与代码地址http://mmlab.ie.cuhk.edu.hk/projects/SRCNN.html
SRCNN是一个非常简单的超分辨重构网络,仅有三层。处理流程是
1、得到一张低分辨图像。
2、将得到的低分辨图像使用bicubic算法放大为目标尺寸,作为图像输入。
3、接下来使用卷积生成超分辨图像,并与ground truth进行loss计算。
该网络结构十分简单,仅仅用了三个卷积层。作者将三层卷积的结构解释成与传统SR方法对应的三个步骤。即
- 提取图像特征
- 非线性映射
- 重构图像
作者在讨论网络结构时也做出了一些分析。首先是未使用池化层和全连接层。第二,卷积核大小和数量。大小越大,实验效果越好。数量越多,实验效果越好。第三,网络层数并非越深越好,是由于没有池化和全连接,对于初始参数和学习率非常敏感。
实验结论
1、由于SR问题,问题可能存在无穷多解。以MSE方法得到的是平均解,导致得到的算法结果有些区域看起过于模糊而缺乏应有的细节。因此PSNR值不是唯一的评价指标,可能出现指标数值评估低,但肉眼看着效果更好的现象。因此作者选择了多重指标。
2、RGB三通道进行联合训练效果是最好的。而YCbCr通道下,Cb、Cr通道对性能提升基本无帮助,只基于Y通道的训练效果更好。
2、VDSR
论文全名是Accurate Image Super-Resolution Using Very Deep Convolutional Networks.
代码地址是https://github.com/huangzehao/caffe-vdsr
在现在看来,SRCNN有几个非常显著的问题。
首先网络训练收敛非常慢,第二网络仅能用于单一尺度,第三非常依赖于小图像区域的上下文信息。
而VDSR则是针对这几点问题提出了解决方法。首先更深的网络可以使用较大的感受野,可以充分考虑图像的上下文信息,其次,使用了残差学习和极大的学习率,加速了网络收敛。第三,仅使用一个网络就可以进行多尺度的图像超分辨重构。
与SRCNN对比
1)模型层数 (20 vs 3),感受野(41*41 vs 13*13)
2)输出大小 (相同 vs 不同), vdsr采用了补0策略
3)收敛速度(快 vs 慢),vdsr采用了residual learning, high lr, gradient clipping等策略
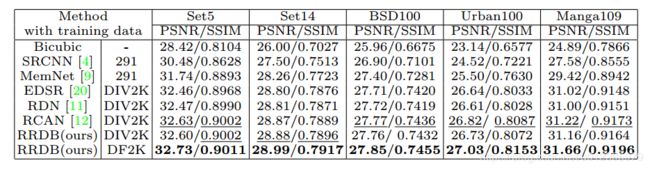
贴上benchmark的结果
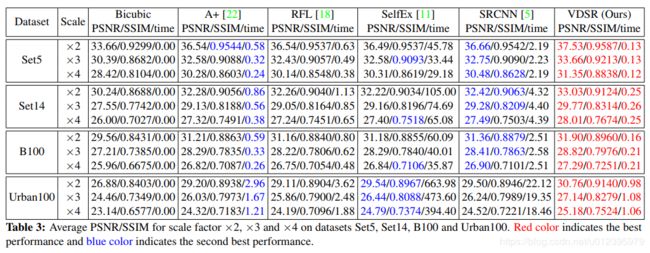
3、LapSRN
论文全名是Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution
代码地址是https://github.com/phoenix104104/LapSRN
这篇论文着重关注于之前的深度学习方法中存在的问题,比如,损失函数均使用L2 loss函数(L2函数不够理想主要是因为其往往使重构结果过于平滑,不符合人类视觉),使用插值将低分辨率图片转换到指定尺寸,还有无法产生中间的超分辨结果。
该篇论文主要有以下的创新点
1、级联结构(金字塔)
具体见下图右侧,在指定层(指定scale)会输出残差结果,逐步学习,最终得到各个scale的重构结果。
2、新的loss 函数
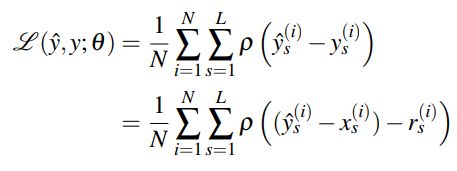
贴上论文中的loss函数公式,其中,x表示LR,y表示HR,r即是残差,s表示对应的scale。对于不同scale的ground truth,用线性插值将HR图像resize到对应的scale。L即是要构建的scale数量,N是每个batch中图片的数量。然后这个p字母的函数不是L2 loss,而是使用的Charbonnier penalty function,L1范数的偏微分。具体表达形式可以查一下。训练目的就是将各个scale的loss和最低。
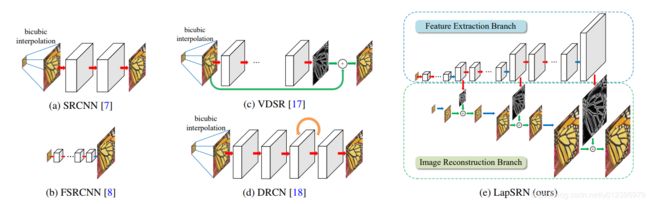
上图就是论文提供的与其它方法的结构对比。
4、SRGAN
论文名称是Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial
代码地址是https://github.com/buriburisuri/SRGAN
顾名思义,SRGAN这篇论文讲的就是如何将GAN应用于超分辨重构问题,由于传统的方法中使用MSE损失函数易使恢复后的图像显得过于平滑,缺少细节。因此作者尝试用GAN来生成图像中的细节。
作者使用了感知损失和对抗损失两种损失来提升和恢复图片的真实感。感知损失即是比较 训练图片和GroundTruth图片经过卷积神经网络 输出后的特征差别。 对抗损失即是GAN网络中的Gnet和Dnet之间的博弈,Gnet生成一个高分辨图像,Dnet判断是Gnet生成的还是GroundTruth. 当Gnet生成的图像能骗过Dnet时,就能完成超分辨任务了。
贴上论文中的网络结构图,网络结构非常清晰,一目了然。
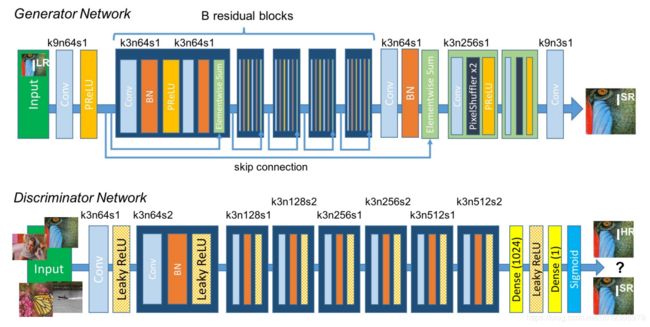
在实验部分。与对比算法相比,作者指出了SRGAN虽然PSNR 、SSIM等指标值虽然不高,但是视觉效果明显高于其他算法,如SRResNet。对于细节的保留更好。
5、EDSR
论文名称是 Enhanced Deep Residual Networks for Single Image Super-Resolution
代码地址是https://github.com/thstkdgus35/EDSR-PyTorch
这篇论文是当时NTIRE2017超分辨竞赛时的冠军算法。做出的主要改进是在残差结构上,由于残差本身的提出是用于目标检测/识别等High-level视觉问题,而对于像超分辨重构这种Low-level视觉问题不能直接套用。因此作者移除了残差中的一些模块,比如BN层,实验证明这样确实有效。
另外论文还提到了一个Trick,就是在进行inference时,有一个称为self-ensemble的技巧,能够对测试结果略有提高,即文中提到的EDSR+, MDSR+.
技巧是将测试图像进行旋转和翻转,总共得到八张图片,分别输入网络然后变换回原始位置。8张图像再取平均。
贴上EDSR和MDSR的网络结构图。看着有点头晕,具体细节可以看论文。上面是EDSR,下面是MDSR

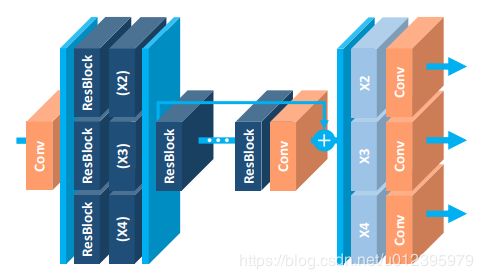
6、RDN
论文名称是Residual Dense Network for Image Super-Resolution
代码地址是https://github.com/yulunzhang/RDN
这篇论文半年前刚放上Arxiv时就关注了,顾名思义,看论文名字就知道作者使用的是结合了skipped connection的Dense结构。但是又有一些区别。
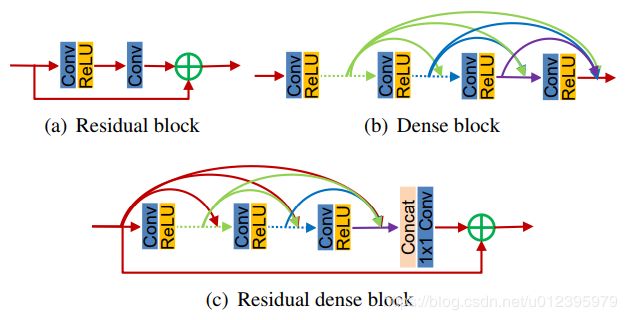
上图就是三者的结构区别,作者在论文中提到了三个概念。Contiguous memory, Local feature fusion, Local residual learning.
结合论文的结构图来细说一下
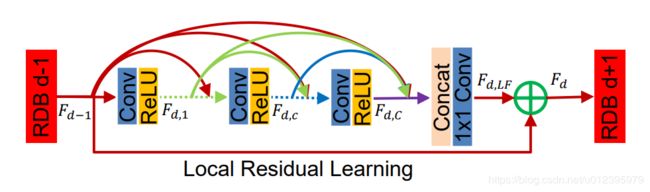
Contiguous memory就是指的将每个block里面的层特征都利用起来,即紫色箭头处四层特征的融合(Fd-1,Fd1,Fdc,FdC)。
Local feature fusion指的是concat后1*1的卷积操作,该操作有助于训练更大growth rate的RDB模块。
Local residual learning指的是将绿色十字圆圈处的特征融合(Fd-1,FdLF),这样能提升模型的表达能力。
当然论文也提到了与DenseBlock, SRDenseNet,Memnet的区别。这里不再赘述。最后说一下论文提到的训练集的制作。通过三种方式处理得到的。
1)BI方式,即通过bicubic下采样得到。
2)BD方式,即先对原图片做7*7,sigma=1.6的高斯滤波,再下采样。
3)DN方式,即先做bicubic下采样,再加30%的高斯噪声。
7、RCAN
论文名称是Image Super-Resolution Using Very Deep Residual Channel Attention Networks
代码地址是https://github.com/yulunzhang/RCAN
出自RDN的作者之手的另一篇作品。是作者对于残差网络(skipped connection)进一步的探索,从直观上,简单的将残差模块进行拼接几乎不能带来更好的效果,因此作者介绍了RIR(residual in residual)模块以及Long skip connection等方法。其次,是引入了通道注意力机制,对提取的不同channel 特征图不进去统一对待,而是加入了权重。这样可以增加特征的多样性。
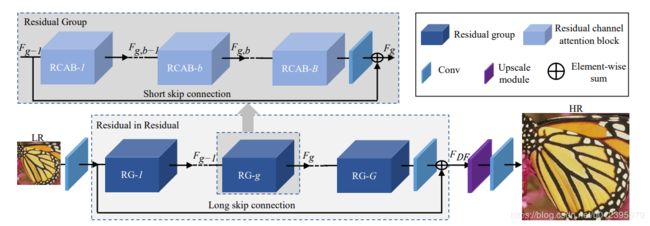
上面的网络结构图非常的清晰明了。RCAN网络总共由四个部分组成,浅层的特征提取(conv),用于深度特征提取的RIR模块,上采样模块(Upscale module)和重构模块(Conv)。
这篇文章有两点是值得借鉴
1、skipped connection可用于训练深层网络,在处理SR问题时,可以加入一个long skipped connection,用于将图像的低频信息直接传递到最后。
2、通道注意力机制可以提高网络的判别能力,可视为一个选择语义属性的过程。
8、ESRGAN
论文名称是ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks
代码地址是 https://github.com/xinntao/ESRGAN
看文章应该是出自港中文和商汤联合实验室的作品。这是来自PIRM2018-SR比赛的冠军算法。因此在网络结构上多是参照已有的研究成果,不过在实践方面还是提供了许多具有参考的内容。所以这里将这篇文章也拿出来盘点一下。
首先第一点,在网络模块上做了改进

其实基本的结构与之前的SRGAN基本一致,只是在basic block这里进行了设计替换。作者给出了对比图
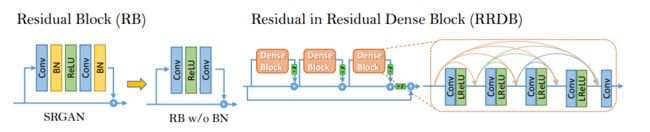
左边是SRGAN的RB模块,右边是作者设计的RRDB模块。区别在于两点,一是去除了BN层,这是因为在以PSNR为衡量指标的任务中,移除BN层已经被证明能够提升模型性能并减少复杂度。二是增加了一个残差尺度参数,可以保证训练更加稳定。
第二点,使用了相对判别器的判别网络
相对判别器在原判别器的基础上增加了对真实图像相对生成结果,更加真实的概率。论文中的对比如下
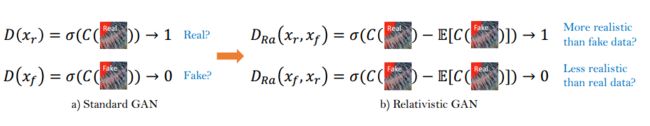
第三点,改进了感知损失
作者通过实验发现,网络末尾的激活函数对于结果输出有负面影响,因此作者选用了去掉末尾激活函数的感知损失。
第四点,训练一个网络来插值
在图像重构部分,为了去除GAN带来的噪声,作者提出了一种高效的插值策略,即网络插值(Network Interpolation)。
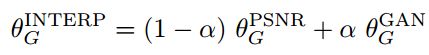
上面公式中Gpsnr表示一个以psnr为任务导向的超分辨重构网络,Ggan表示一个在GAN网络中调优得到的超分辨重构网络。最后的插值就是结合两个网络的参数。其实a属于(0,1)。
最后,贴上论文中的结果图,不管是客观指标还是主观视觉,效果都非常鲁棒。