分库分表后,测试人员如何面对多库多表中数据
最近工作的重心是容量规划,当系统数据量上来之后。对系统就需要使用分库分表了,分库分表选型的是 apache sharding jdbc,他是通过客户端来对数据源进行分库分表的。
1、遇到问题
但是在分库分表之后,不管是开发还是测试,当遇到问题需要查询数据库的时候面对多个库多个表那就比较痛苦了。
如何透明化分库分表所带来的影响,让使用方尽量像使用一个数据库一样使用水平分片之后的数据库集群。我们需要解决这个问题。
我们在开发的时候使用了 ShardingSphere 的客户端中间件,sharding-jdbc 来开发。当我们需要查询数据的时候可以使用它里面的另外一个中间件,基于服务端的中间件 sharding-proxy。
2、sharding proxy
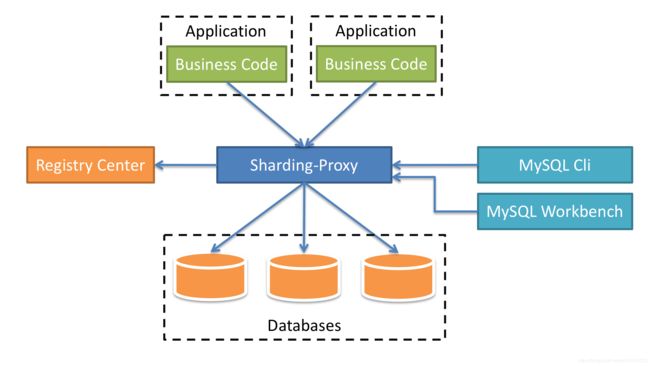
ShardingSphere-Proxy是ShardingSphere的第二个产品。 它定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前先提供MySQL/PostgreSQL版本,它可以使用任何兼容MySQL/PostgreSQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat等)操作数据,对DBA更加友好。
- 向应用程序完全透明,可直接当做MySQL/PostgreSQL使用。
- 适用于任何兼容MySQL/PostgreSQL协议的的客户端。
| ~ | ShardingSphere-JDBC | ShardingSphere-Proxy | ShardingSphere-Sidecar |
|---|---|---|---|
| 数据库 | 任意 | MySQL/PostgreSQL | MySQL/PostgreSQL |
| 连接消耗数 | 高 | 低 | 高 |
| 异构语言 | 仅Java | 任意 | 任意 |
| 性能 | 损耗低 | 损耗略高 | 损耗低 |
| 无中心化 | 是 | 否 | 是 |
| 静态入口 | 无 | 有 | 无 |
ShardingSphere-Proxy的优势在于对异构语言的支持,以及为DBA和测试人员提供可操作入口。
3、安装和配置
可以通过 官方下载路径 下载最新的 sharding-proxy 目录。

不过我们可以在本地从 github下载 sharding-sphere 项目.sharding-proxy 包含这个项目当中。在本地进行调试好了再把配置上文件上放置到 sharding proxy 里面这样就特别方便。因为 sharding proxy 是基于 spring boot 的项目,它可以很方便的进行启动。
3.1 sharding proxy 项目结构
下面就是 sharding proxy 的项目结构,其实和下载的启动配置类似,只不过这个是以 spring boot 的形式启动,而它是以 bat 或者 shell 文件启动。
sharding-proxy
--sharding-proxy-bootstrap
--src
--main
--java
--org.apache.shardingsphere.shardingproxy.Bootstrap // 启动类
--resources
-conf
--config-xxx.yaml // 配置分库分表规则
--server.yaml // 配置服务器信息
3.2 分片配置
下面是分库分表规则,这里只配置了从库,没有配置主库,因为在分片库里面的 id 都是基于数据库的自增生成的。当我们通过 navicat 进行修改数据的时候是通过 Id 修改的,所以当修改一个数据的时候其实是修改了很多数据。如果你的 ID 能够保证全局唯一可以配置主从规则。
config-pay-engine.yml
schemaName: pay-engine
dataSources:
pay_engine_0:
url: jdbc:mysql://localhost:3306/pay_engine_0?characterEncoding=utf8&useSSL=false
username: carl
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
pay_engine_1:
url: jdbc:mysql://localhost:3306/pay_engine_1?characterEncoding=utf8&useSSL=false
username: carl
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
shardingRule:
tables:
tb_collect_pay_order:
actualDataNodes: pay_engine_${0..1}.tb_collect_pay_order_${0..49}
databaseStrategy:
complex:
shardingColumns: pay_order_no,request_no
algorithmClassName: cn.carl.pay.engine.sharding.rule.CollectPayOrderModuloShardingDatabaseAlgorithm
tableStrategy:
complex:
shardingColumns: pay_order_no,request_no
algorithmClassName: cn.carl.pay.engine.sharding.rule.CollectPayOrderModuloShardingTableAlgorithm
sharding-proxy 的分库分表规则可以 sharding-proxy 官网配置手册。因为它的分片规则 demo 只是使用了 hint 分片,所以如果你遇到其它分片算法的话还需要参考 sharding-jdbc 官网配置手册。
3.3 服务端配置
server.yml
authentication:
users:
root:
password: root
sharding:
password: sharding
props:
executor.size: 16
sql.show: true
通过 sharding proxy 对分库分表的数据源进行代理之后,DBA 或者 测试人员连接代理服务器只会看到一个库一张表了。
服务端配置同样要参考 sharding-proxy 官方配置手册。
3.4 本地启动
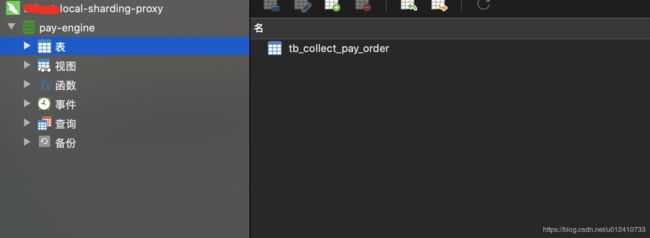
本地启动成功之后可以使用 navicat 连接服务器。

连接数据源发现只会存在一个库一张表:
4、服务器启动
其实服务器启动和本地启动类似,你可以把你本地启动的 sharing-proxy 打包成 jar 文件然后通过 java -jar sharding-proxy.jar 启动。
同时也可以使用 sharding-proxy 官方下载的压缩包启动,在 linux 上是以 shell 脚本启动的。只需要把我们刚才测试好的配置文件写入到:
- 下载ShardingSphere-Proxy的最新发行版。
- 解压缩后修改conf/server.yaml和以config-前缀开头的文件,如:conf/config-xxx.yaml文件,进行分片规则、读写分离规则配置
- Linux操作系统请运行bin/start.sh,Windows操作系统请运行bin/start.bat启动ShardingSphere-Proxy。如需配置启动端口、配置文件位置
如果后端连接PostgreSQL数据库,不需要引入额外依赖。
如果后端连接MySQL数据库,需要将mysql-connector-java-5.1.47.jar拷贝到 {shardingsphere-proxy}\lib目录。
如果算法类需要自己实现,也需要把算法类打成 jar 包拷贝到 {shardingsphere-proxy}\lib目录。
启动服务
使用默认配置项
${shardingsphere-proxy}\bin\start.sh
配置端口
${shardingsphere-proxy}\bin\start.sh ${port}
引用文章:
- sharding proxy 简介
- sharding proxy 配置手册
- sharding jdbc YML 配置手册