OpenGL-基础知识总结
文章目录
- 图像渲染管线
- VAO,VBO,EBO之间的关系
- 顶点属性格式
- 坐标系统
- 正射投影和透视投影
- 将变换组合
- 右手坐标系
- 摄像机
- LookAt矩阵
- 欧拉角
- 词汇表一览
- 示例代码解读
- 资源参考
图像渲染管线
在OpenGL中,任何事物都在3D空间中,而屏幕和窗口却是2D像素数组,这导致OpenGL的大部分工作都是关于把3D坐标转变为适应你屏幕的2D像素。3D坐标转为2D坐标的处理过程是由OpenGL的图形渲染管线(Graphics Pipeline,大多译为管线,实际上指的是一堆原始图形数据途经一个输送管道,期间经过各种变化处理最终出现在屏幕的过程)管理的。图形渲染管线可以被划分为两个主要部分:第一部分把你的3D坐标转换为2D坐标,第二部分是把2D坐标转变为实际的有颜色的像素。
图形渲染管线接受一组3D坐标,然后把它们转变为你屏幕上的有色2D像素输出。图形渲染管线可以被划分为几个阶段,每个阶段将会把前一个阶段的输出作为输入。所有这些阶段都是高度专门化的(它们都有一个特定的函数),并且很容易并行执行。正是由于它们具有并行执行的特性,当今大多数显卡都有成千上万的小处理核心,它们在GPU上为每一个(渲染管线)阶段运行各自的小程序,从而在图形渲染管线中快速处理你的数据。这些小程序叫做着色器(Shader)。
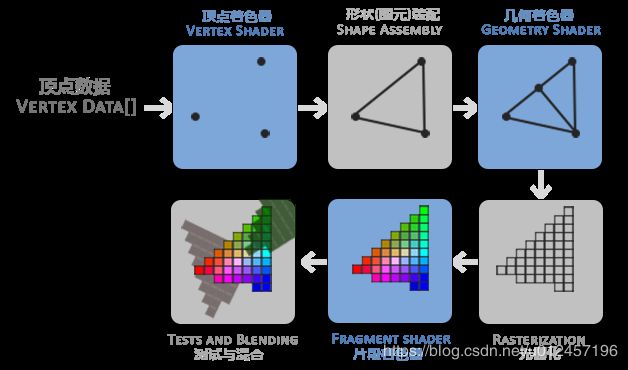
- 顶点着色器(Vertex Shader):它把一个单独的顶点作为输入。顶点着色器主要的目的是把3D坐标转为另一种3D坐标(后面会解释),同时顶点着色器允许我们对顶点属性进行一些基本处理。
- 图元装配(Primitive Assembly):阶段将顶点着色器输出的所有顶点作为输入(如果是GL_POINTS,那么就是一个顶点),并所有的点装配成指定图元的形状;本节例子中是一个三角形。
- 几何着色器(Geometry Shader):几何着色器把图元形式的一系列顶点的集合作为输入,它可以通过产生新顶点构造出新的(或是其它的)图元来生成其他形状。例子中,它生成了另一个三角形。
- 光栅化阶段(Rasterization Stage):这里它会把图元映射为最终屏幕上相应的像素,生成供片段着色器(Fragment Shader)使用的片段(Fragment)。在片段着色器运行之前会执行裁切(Clipping)。裁切会丢弃超出你的视图以外的所有像素,用来提升执行效率。
- 片段着色器:的主要目的是计算一个像素的最终颜色,这也是所有OpenGL高级效果产生的地方。通常,片段着色器包含3D场景的数据(比如光照、阴影、光的颜色等等),这些数据可以被用来计算最终像素的颜色。
- Alpha测试和混合(Blending):在所有对应颜色值确定以后,最终的对象将会被传到最后一个阶段,我们叫做Alpha测试和混合(Blending)阶段。这个阶段检测片段的对应的深度(和模板(Stencil))值(后面会讲),用它们来判断这个像素是其它物体的前面还是后面,决定是否应该丢弃。这个阶段也会检查alpha值(alpha值定义了一个物体的透明度)并对物体进行混合(Blend)。所以,即使在片段着色器中计算出来了一个像素输出的颜色,在渲染多个三角形的时候最后的像素颜色也可能完全不同。
VAO,VBO,EBO之间的关系
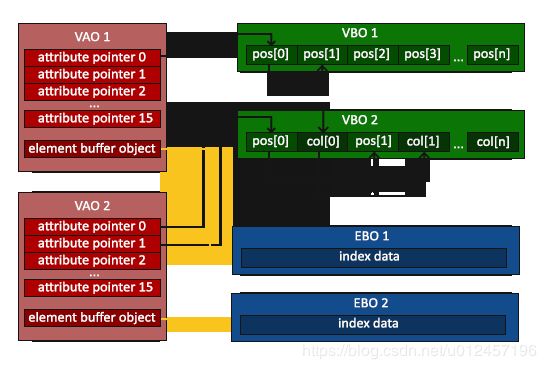
顶点属性格式
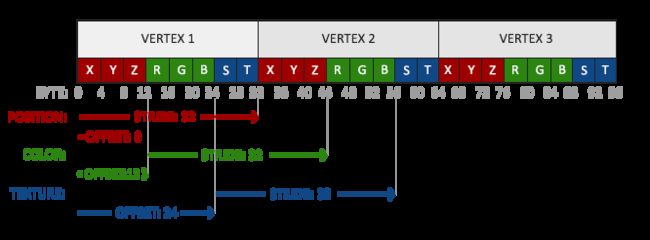
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 8 * sizeof(float), (void*)(6 * sizeof(float)));
glEnableVertexAttribArray(2);
坐标系统
OpenGL希望在每次顶点着色器运行后,我们可见的所有顶点都为标准化设备坐标(Normalized Device Coordinate, NDC)。也就是说,每个顶点的x,y,z坐标都应该在-1.0到1.0之间,超出这个坐标范围的顶点都将不可见。我们通常会自己设定一个坐标的范围,之后再在顶点着色器中将这些坐标变换为标准化设备坐标。然后将这些标准化设备坐标传入光栅器(Rasterizer),将它们变换为屏幕上的二维坐标或像素。
将坐标变换为标准化设备坐标,接着再转化为屏幕坐标的过程通常是分步进行的,也就是类似于流水线那样子。在流水线中,物体的顶点在最终转化为屏幕坐标之前还会被变换到多个坐标系统(Coordinate System)。将物体的坐标变换到几个过渡坐标系(Intermediate Coordinate System)的优点在于,在这些特定的坐标系统中,一些操作或运算更加方便和容易,这一点很快就会变得很明显。对我们来说比较重要的总共有5个不同的坐标系统。
下面的这张图展示了整个流程以及各个变换过程做了什么:

coordinate_systems
- 局部坐标是对象相对于局部原点的坐标,也是物体起始的坐标。
- 下一步是将局部坐标变换为世界空间坐标,世界空间坐标是处于一个更大的空间范围的。这些坐标相对于世界的全局原点,它们会和其它物体一起相对于世界的原点进行摆放。
- 接下来我们将世界坐标变换为观察空间坐标,使得每个坐标都是从摄像机或者说观察者的角度进行观察的。
- 坐标到达观察空间之后,我们需要将其投影到裁剪坐标。裁剪坐标会被处理至-1.0到1.0的范围内,并判断哪些顶点将会出现在屏幕上。
- 最后,我们将裁剪坐标变换为屏幕坐标,我们将使用一个叫做视口变换(Viewport Transform)的过程。视口变换将位于-1.0到1.0范围的坐标变换到由glViewport函数所定义的坐标范围内。最后变换出来的坐标将会送到光栅器,将其转化为片段。
正射投影和透视投影
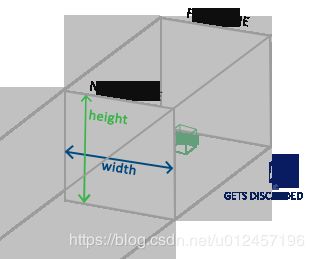

上面的平截头体定义了可见的坐标,它由由宽、高、近(Near)平面和远(Far)平面所指定。任何出现在近平面之前或远平面之后的坐标都会被裁剪掉。正射平截头体直接将平截头体内部的所有坐标映射为标准化设备坐标,因为每个向量的w分量都没有进行改变;如果w分量等于1.0,透视除法则不会改变这个坐标。
顶点坐标的每个分量都会除以它的w分量,距离观察者越远顶点坐标就会越小。这是也是w分量非常重要的另一个原因,它能够帮助我们进行透视投影。
将变换组合
上述的每一个步骤都创建了一个变换矩阵:模型矩阵、观察矩阵和投影矩阵。一个顶点坐标将会根据以下过程被变换到裁剪坐标:
V c l i p = M p r o j e c t i o n ∗ M v i e w ∗ M m o d e l ∗ V l o c a l V_{clip} = M_{projection} * M_{view} * M_{model}* V_{local} Vclip=Mprojection∗Mview∗Mmodel∗Vlocal
注意矩阵运算的顺序是相反的(记住我们需要从右往左阅读矩阵的乘法)。最后的顶点应该被赋值到顶点着色器中的gl_Position,OpenGL将会自动进行透视除法和裁剪。
右手坐标系
按照惯例,OpenGL是一个右手坐标系。简单来说,就是正x轴在你的右手边,正y轴朝上,而正z轴是朝向后方的。想象你的屏幕处于三个轴的中心,则正z轴穿过你的屏幕朝向你。坐标系画起来如下:

为了理解为什么被称为右手坐标系,按如下的步骤做:
- 沿着正y轴方向伸出你的右臂,手指着上方。
- 大拇指指向右方。
- 食指指向上方。
- 中指向下弯曲90度。
摄像机
当我们讨论摄像机/观察空间(Camera/View Space)的时候,是在讨论以摄像机的视角作为场景原点时场景中所有的顶点坐标:观察矩阵把所有的世界坐标变换为相对于摄像机位置与方向的观察坐标。要定义一个摄像机,我们需要它在世界空间中的位置、观察的方向、一个指向它右测的向量以及一个指向它上方的向量。细心的读者可能已经注意到我们实际上创建了一个三个单位轴相互垂直的、以摄像机的位置为原点的坐标系。
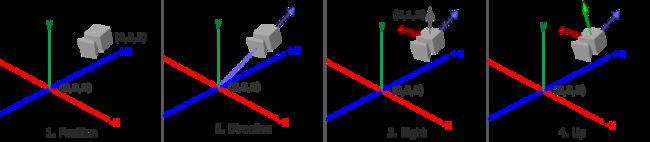
LookAt矩阵
使用矩阵的好处之一是如果你使用3个相互垂直(或非线性)的轴定义了一个坐标空间,你可以用这3个轴外加一个平移向量来创建一个矩阵,并且你可以用这个矩阵乘以任何向量来将其变换到那个坐标空间。这正是LookAt矩阵所做的,现在我们有了3个相互垂直的轴和一个定义摄像机空间的位置坐标,我们可以创建我们自己的LookAt矩阵了:
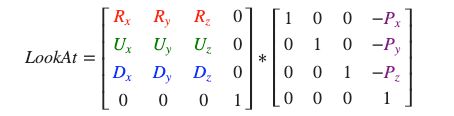
其中R是右向量,U是上向量,D是方向向量P是摄像机位置向量。注意,位置向量是相反的,因为我们最终希望把世界平移到与我们自身移动的相反方向。把这个LookAt矩阵作为观察矩阵可以很高效地把所有世界坐标变换到刚刚定义的观察空间。LookAt矩阵就像它的名字表达的那样:它会创建一个看着(Look at)给定目标的观察矩阵。
幸运的是,GLM已经提供了这些支持。我们要做的只是定义一个摄像机位置,一个目标位置和一个表示世界空间中的上向量的向量(我们计算右向量使用的那个上向量)。接着GLM就会创建一个LookAt矩阵,我们可以把它当作我们的观察矩阵。
欧拉角
欧拉角(Euler Angle)是可以表示3D空间中任何旋转的3个值,由莱昂哈德·欧拉(Leonhard Euler)在18世纪提出。一共有3种欧拉角:俯仰角(Pitch)、偏航角(Yaw)和滚转角(Roll),下面的图片展示了它们的含义:

词汇表一览
- OpenGL:一个定义了函数布局和输出的图形API的正式规范
- GLAD:一个拓展加载库,用来为我们加载并设定所有的OpenGL函数指针,从而让我们能够使用所有(现代)OpenGL函数。
- 视口(Viewport):我们需要渲染的窗口
- 图形管线(Graphics Pipeline):一个顶点在呈现为像素之前经过的全部过程
- 着色器(Shader):一个运行在显卡上的小型程序,很多阶段的图形管道都可以使用自定义的着色器来代替原有的功能
- 标准化设备坐标(Normalized Device Coordinates,NDC):顶点在通过在剪裁坐标系中剪裁与透视除法后最终呈现在的坐标系,所有位置在NDC下-1.0到1.0的顶点将不会被丢弃并且可见
- 顶点缓冲对象(Vertex Buffer Object,VBO):一个调用显存并存储所有顶点数据供显卡使用的缓冲对象
- 顶点数组对象(Vertex Array Object,VAO):存储缓冲区和顶点属性状态
- 索引缓冲对象(Element Buffer Object,EBO):一个存储索引供索引化绘制使用的缓冲对象
- Uniform:一个特殊类型的GLSL变量,它是全聚德(在一个着色器程序中每一个着色器都能够访问uniform变量),并且只需要被设定一次。
- 纹理(Texture):一种包裹着物体的特征类型图像,给物体精细的视觉效果。
- 纹理缠绕(Texture Wrapping):定义了一种当纹理顶点超出范围(0,1)时指定OpenGL如何采样纹理的模式
- 纹理过滤(Texture Filtering):定义了一种当有多种纹理选择时指定OpenGL如何采样纹理的模式,通常在纹理被放大情况下发生
- 多级渐远纹理(Mipmaps): 被存储的材质的一些缩小版本,根据距观察者的距离会使用材质的合适大小。
- stb_image.h: 图像加载库。
- 纹理单元(Texture Units): 通过绑定纹理到不同纹理单元从而允许多个纹理在同一对象上渲染。
- 向量(Vector): 一个定义了在空间中方向和/或位置的数学实体。
- 矩阵(Matrix): 一个矩形阵列的数学表达式。
- GLM: 一个为OpenGL打造的数学库。
- 局部空间(Local Space): 一个物体的初始空间。所有的坐标都是相对于物体的原点的。
- 世界空间(World Space): 所有的坐标都相对于全局原点。
- 观察空间(View Space): 所有的坐标都是从摄像机的视角观察的。
- 裁剪空间(Clip Space): 所有的坐标都是从摄像机视角观察的,但是该空间应用了投影。这个空间应该是一个顶点坐标最终的空间,作为顶点着色器的输出。OpenGL负责处理剩下的事情(裁剪/透视除法)。
- 屏幕空间(Screen Space): 所有的坐标都由屏幕视角来观察。坐标的范围是从0到屏幕的宽/高。
- LookAt矩阵: 一种特殊类型的观察矩阵,它创建了一个坐标系,其中所有坐标都根据从一个位置正在观察目标的用户旋转或者平移。
- 欧拉角(Euler Angles): 被定义为偏航角(Yaw),俯仰角(Pitch),和滚转角(Roll)从而允许我们通过这三个值构造任何3D方向。
示例代码解读
这是一段使用鼠标键盘和滑轮在三维空间移动然后观察十个箱子的代码,附有代码解读。
#include
#include
#include "../../util/stb_image.h"
#include
#include
#include
#include "../../util/shader_s.h"
#include
void framebuffer_size_callback(GLFWwindow* window, int width, int height);
void mouse_callback(GLFWwindow* window, double xpos, double ypos);
void scroll_callback(GLFWwindow* window, double xoffset, double yoffset);
void processInput(GLFWwindow *window);
// 屏幕大小
const unsigned int SCR_WIDTH = 800;
const unsigned int SCR_HEIGHT = 600;
// camera
glm::vec3 cameraPos = glm::vec3(0.0f, 0.0f, 3.0f); // 世界空间中一个指向摄像机位置的向量
glm::vec3 cameraFront = glm::vec3(0.0f, 0.0f, -1.0f); // 摄像机的方向,指向Z负轴
glm::vec3 cameraUp = glm::vec3(0.0f, 1.0f, 0.0f); // 摄像机的上向量
bool firstMouse = true;
float yaw = -90.0f; // 偏航角 yaw is initialized to -90.0 degrees since a yaw of 0.0 results in a direction vector pointing to the right so we initially rotate a bit to the left.
float pitch = 0.0f; // 俯仰角
float lastX = 800.0f / 2.0;
float lastY = 600.0 / 2.0;
float fov = 45.0f; // Field of view 视野的大小
// timing 计算时间差,它储存了渲染上一帧所用的时间。我们把所有速度都去乘以deltaTime值,结果就是,如果我们的deltaTime很大,就意味着上一帧的渲染花费了更多时间,所以这一帧的速度需要变得更高来平衡渲染所花去的时间
float deltaTime = 0.0f; // time between current frame and last frame
float lastFrame = 0.0f;
int main()
{
// glfw: 初始化配置
// ------------------------------
glfwInit();
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3); // 主版本
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3); // 次版本
glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE); // 使用核心模式
#ifdef __APPLE__ //苹果系统使用
glfwWindowHint(GLFW_OPENGL_FORWARD_COMPAT, GL_TRUE);
#endif
// glfw 创建窗口
// --------------------
GLFWwindow* window = glfwCreateWindow(SCR_WIDTH, SCR_HEIGHT, "LearnOpenGL", NULL, NULL);
if (window == NULL)
{
std::cout << "Failed to create GLFW window" << std::endl;
glfwTerminate();
return -1;
}
// 创建完窗口我们就可以通知GLFW将我们窗口的上下文设置为当前线程的主上下文了。
glfwMakeContextCurrent(window);
// 告诉GLFW我们希望每当窗口调整大小的时候调用这个函数:当窗口被第一次显示的时候framebuffer_size_callback也会被调用。对于视网膜(Retina)显示屏,width和height都会明显比原输入值更高一点。
glfwSetFramebufferSizeCallback(window, framebuffer_size_callback);
glfwSetCursorPosCallback(window, mouse_callback); // 鼠标位置的回调
glfwSetScrollCallback(window, scroll_callback); // 鼠标滚轮的回调
// 告诉 GLFW 捕捉鼠标
glfwSetInputMode(window, GLFW_CURSOR, GLFW_CURSOR_DISABLED);
// glad: load all OpenGL function pointers 加载所有的OpenGL函数指针,这样确保不同的平台函数是一样的
// ---------------------------------------
if (!gladLoadGLLoader((GLADloadproc)glfwGetProcAddress))
{
std::cout << "Failed to initialize GLAD" << std::endl;
return -1;
}
// 配置全局OpenGl状态
// -----------------------------
glEnable(GL_DEPTH_TEST); // 启动深度测试,这样有Z缓冲,控制3D物体的显示与遮挡
// 构建编译着色器程序,这里使用了自定义的着色器类
// ------------------------------------
Shader ourShader("shader/7.3.camera.vs", "shader/7.3.camera.fs");
// 设置顶点数组(和buffers)和配置顶点属性
// ------------------------------------------------------------------
float vertices[] = {
// 顶点坐标x,y,z,纹理坐标x1,y1
-0.5f, -0.5f, -0.5f, 0.0f, 0.0f,
0.5f, -0.5f, -0.5f, 1.0f, 0.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
-0.5f, 0.5f, -0.5f, 0.0f, 1.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 0.0f,
-0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
0.5f, -0.5f, 0.5f, 1.0f, 0.0f,
0.5f, 0.5f, 0.5f, 1.0f, 1.0f,
0.5f, 0.5f, 0.5f, 1.0f, 1.0f,
-0.5f, 0.5f, 0.5f, 0.0f, 1.0f,
-0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
-0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
-0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
-0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
-0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
0.5f, -0.5f, -0.5f, 1.0f, 1.0f,
0.5f, -0.5f, 0.5f, 1.0f, 0.0f,
0.5f, -0.5f, 0.5f, 1.0f, 0.0f,
-0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
-0.5f, 0.5f, -0.5f, 0.0f, 1.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
-0.5f, 0.5f, 0.5f, 0.0f, 0.0f,
-0.5f, 0.5f, -0.5f, 0.0f, 1.0f
};
// 我们的立方体在世界空间的坐标
glm::vec3 cubePositions[] = {
glm::vec3( 0.0f, 0.0f, 0.0f),
glm::vec3( 2.0f, 5.0f, -15.0f),
glm::vec3(-1.5f, -2.2f, -2.5f),
glm::vec3(-3.8f, -2.0f, -12.3f),
glm::vec3( 2.4f, -0.4f, -3.5f),
glm::vec3(-1.7f, 3.0f, -7.5f),
glm::vec3( 1.3f, -2.0f, -2.5f),
glm::vec3( 1.5f, 2.0f, -2.5f),
glm::vec3( 1.5f, 0.2f, -1.5f),
glm::vec3(-1.3f, 1.0f, -1.5f)
};
unsigned int VBO, VAO; // 定义顶点缓冲对象和顶点数组对象,还有个EBO是索引缓冲对象,在用两个三角形画长方形定义绘制顺序的时候有用到
glGenVertexArrays(1, &VAO); // 使用函数生成VAO,第一个是生成数量,第二个是对象索引
glGenBuffers(1, &VBO); // 使用函数生成VBO
// 要想使用VAO,要做的只是使用glBindVertexArray绑定VAO。从绑定之后起,我们应该绑定和配置对应的VBO和属性指针,之后解绑VAO供之后使用。当我们打算绘制一个物体的时候,我们只要在绘制物体前简单地把VAO绑定到希望使用的设定上就行了。
glBindVertexArray(VAO);
glBindBuffer(GL_ARRAY_BUFFER, VBO); // 使用glBindBuffer函数把新创建的缓冲绑定到GL_ARRAY_BUFFER目标上
// 从这一刻起,我们使用的任何(在GL_ARRAY_BUFFER目标上的)缓冲调用都会用来配置当前绑定的缓冲(VBO),glBufferData函数,它会把之前定义的顶点数据复制到缓冲的内存中
// 三角形的位置数据不会改变,每次渲染调用时都保持原样,所以它的使用类型最好是GL_STATIC_DRAW。如果,比如说一个缓冲中的数据将频繁被改变,那么使用的类型就是GL_DYNAMIC_DRAW或GL_STREAM_DRAW,这样就能确保显卡把数据放在能够高速写入的内存部分。
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
//** 设置顶点属性指针
// 位置属性,第一个参数是顶点着色器layout的值,第二个参数是顶点属性大小3,第三个参数是指定数据的类型,第四个是否标准化,第五个是步长,连续顶点属性组之间的间隔,最后一个是位置数据在缓冲中起始位置的偏移量(offset)
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 5 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0); // 以顶点属性位置值作为参数,启用顶点属性;顶点属性默认是禁用的
// 纹理坐标属性2个
glVertexAttribPointer(1, 2, GL_FLOAT, GL_FALSE, 5 * sizeof(float), (void*)(3 * sizeof(float)));
glEnableVertexAttribArray(1);
// 加载和创建一个纹理
// -------------------------
unsigned int texture1, texture2; // 纹理是使用ID引用的
// texture 1
// ---------
glGenTextures(1, &texture1); // 第一个参数是生成纹理的数量,然后储存在第二个参数unsigned int数组中,这里就是单独的unsigned int。
glBindTexture(GL_TEXTURE_2D, texture1); // 绑定到GL_TEXTURE_2D上,这时,任何调用都会用来配置texture1
// 设置纹理环绕参数,纹理超出边界如何显示
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
// 设置纹理滤波参数,放大或缩小时如何处理
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
// 加载图片,创建纹理和生成多级渐远纹理
int width, height, nrChannels;
stbi_set_flip_vertically_on_load(true); // tell stb_image.h 在加载纹理时绕y轴翻转
unsigned char *data = stbi_load("resources/container.jpg", &width, &height, &nrChannels, 0);
if (data)
{
// 使用前面载入的图片数据生成一个纹理,第一个参数指定了纹理目标,设置为GL_TEXTURE_2D意味着会生成与当前绑定的纹理对象在同一个目标上的纹理
// 第二个参数为纹理指定多级渐远纹理的级别,如果你希望单独手动设置每个多级渐远纹理的级别的话。这里我们填0,也就是基本级别。
// 第三个参数告诉OpenGL我们希望把纹理储存为何种格式。我们的图像只有RGB值,因此我们也把纹理储存为RGB值。
// 第四个和第五个参数设置最终的纹理的宽度和高度
// 下个参数应该总是被设为0(历史遗留的问题)。
// 第七第八个参数定义了源图的格式和数据类型。我们使用RGB值加载这个图像,并把它们储存为char(byte)数组,我们将会传入对应值。
// 最后一个参数是真正的图像数据, 当调用glTexImage2D时,当前绑定的纹理对象就会被附加上纹理图像。然而,目前只有基本级别(Base-level)的纹理图像被加载了,
// 如果要使用多级渐远纹理,我们必须手动设置所有不同的图像(不断递增第二个参数)。或者,直接在生成纹理之后调用glGenerateMipmap。这会为当前绑定的纹理自动生成所有需要的多级渐远纹理。
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, data);
glGenerateMipmap(GL_TEXTURE_2D);
}
else
{
std::cout << "Failed to load texture" << std::endl;
}
stbi_image_free(data); // 生成了纹理和相应的多级渐远纹理后,释放图像的内存是一个很好的习惯。
// texture 2
// ---------
glGenTextures(1, &texture2);
glBindTexture(GL_TEXTURE_2D, texture2);
// set the texture wrapping parameters
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
// set texture filtering parameters
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
// load image, create texture and generate mipmaps
data = stbi_load("resources/awesomeface.png", &width, &height, &nrChannels, 0);
if (data)
{
// note that the awesomeface.png has transparency and thus an alpha channel, so make sure to tell OpenGL the data type is of GL_RGBA
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, width, height, 0, GL_RGBA, GL_UNSIGNED_BYTE, data);
glGenerateMipmap(GL_TEXTURE_2D);
}
else
{
std::cout << "Failed to load texture" << std::endl;
}
stbi_image_free(data);
// tell opengl for each sampler to which texture unit it belongs to (only has to be done once)
// 告诉opengl对于每个sampler哪个纹理单元的所属(只需要被做一次)
// 我们还要通过使用glUniform1i设置每个采样器的方式告诉OpenGL每个着色器采样器属于哪个纹理单元。我们只需要设置一次即可,所以这个会放在渲染循环的前面:
// -------------------------------------------------------------------------------------------
ourShader.use(); // 别忘记在激活着色器前先设置uniform!
ourShader.setInt("texture1", 0); //设置纹理属于哪个纹理单元GL_TEXTURE0,GL_TEXTURE1
ourShader.setInt("texture2", 1);
// render loop
// -----------
while (!glfwWindowShouldClose(window))
{
// per-frame time logic 每帧的逻辑
// --------------------
float currentFrame = glfwGetTime();
deltaTime = currentFrame - lastFrame;
lastFrame = currentFrame;
// input
// -----
processInput(window);
// render
// ------
glClearColor(0.2f, 0.3f, 0.3f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT); // 使用对应颜色清除颜色和深度缓冲
// 将纹理绑定到对应的纹理单元
// 使用glUniform1i,我们可以给纹理采样器分配一个位置值,这样的话我们能够在一个片段着色器中设置多个纹理。一个纹理的位置值通常称为一个纹理单元(Texture Unit)。
// 一个纹理的默认纹理单元是0,它是默认的激活纹理单元,所以教程前面部分我们没有分配一个位置值。纹理单元的主要目的是让我们在着色器中可以使用多于一个的纹理。
// 通过把纹理单元赋值给采样器,我们可以一次绑定多个纹理,只要我们首先激活对应的纹理单元。就像glBindTexture一样,我们可以使用glActiveTexture激活纹理单元,传入我们需要使用的纹理单元:
// 激活纹理单元之后,接下来的glBindTexture函数调用会绑定这个纹理到当前激活的纹理单元,纹理单元GL_TEXTURE0默认总是被激活,所以我们在前面的例子里当我们使用glBindTexture的时候,无需激活任何纹理单元。
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, texture1);
glActiveTexture(GL_TEXTURE1);
glBindTexture(GL_TEXTURE_2D, texture2);
// 确保在调用任何glUniform之前激活shader
ourShader.use();
// 传递投影矩阵到shader中(注意这个例子中它可能每帧都改变)
glm::mat4 projection = glm::perspective(glm::radians(fov), (float)SCR_WIDTH / (float)SCR_HEIGHT, 0.1f, 100.0f);
ourShader.setMat4("projection", projection);
// camera/view transformation 摄像机视角变换
glm::mat4 view = glm::lookAt(cameraPos, cameraPos + cameraFront, cameraUp);
ourShader.setMat4("view", view);
// render boxes 渲染盒子
// 任何随后的顶点属性调用都会储存在这个VAO中,这样的好处就是,当配置顶点属性指针时,你只需要将那些调用执行一次,之后再绘制物体的时候只需要绑定相应的VAO就行了。
// 这使在不同顶点数据和属性配置之间切换变得非常简单,只需要绑定不同的VAO就行了。刚刚设置的所有状态都将存储在VAO中。
// 一个顶点数组对象会储存以下这些内容:
// - glEnableVertexAttribArray和glDisableVertexAttribArray的调用。
// - 通过glVertexAttribPointer设置的顶点属性配置。
// - 通过glVertexAttribPointer调用与顶点属性关联的顶点缓冲对象。
glBindVertexArray(VAO); //当我们打算绘制一个物体的时候,我们只要在绘制物体前简单地把VAO绑定到希望使用的设定上就行了
for (unsigned int i = 0; i < 10; i++)
{
// 在绘制之前为每个物体计算模型矩阵然后传递到shader
glm::mat4 model = glm::mat4(1.0f); // 首先确保初始化为单位矩阵
model = glm::translate(model, cubePositions[i]);
float angle = 20.0f * i;
model = glm::rotate(model, glm::radians(angle), glm::vec3(1.0f, 0.3f, 0.5f));
ourShader.setMat4("model", model);
glDrawArrays(GL_TRIANGLES, 0, 36);
}
// glfw:使用的双缓冲所以交换buffers然后获取IO事件(keys pressed/released, mouse moved etc.)
// -------------------------------------------------------------------------------
glfwSwapBuffers(window);
glfwPollEvents();
}
// optional: de-allocate all resources once they've outlived their purpose:
// ------------------------------------------------------------------------
glDeleteVertexArrays(1, &VAO);
glDeleteBuffers(1, &VBO);
// glfw: terminate, clearing all previously allocated GLFW resources.
// ------------------------------------------------------------------
glfwTerminate();
return 0;
}
// process all input: query GLFW whether relevant keys are pressed/released this frame and react accordingly
// ---------------------------------------------------------------------------------------------------------
void processInput(GLFWwindow *window)
{
if (glfwGetKey(window, GLFW_KEY_ESCAPE) == GLFW_PRESS)
glfwSetWindowShouldClose(window, true);
// float cameraSpeed = 2.5 * deltaTime;
float cameraSpeed = 10 * deltaTime;
if (glfwGetKey(window, GLFW_KEY_W) == GLFW_PRESS)
cameraPos += cameraSpeed * cameraFront;
if (glfwGetKey(window, GLFW_KEY_S) == GLFW_PRESS)
cameraPos -= cameraSpeed * cameraFront;
if (glfwGetKey(window, GLFW_KEY_A) == GLFW_PRESS)
cameraPos -= glm::normalize(glm::cross(cameraFront, cameraUp)) * cameraSpeed;
if (glfwGetKey(window, GLFW_KEY_D) == GLFW_PRESS)
cameraPos += glm::normalize(glm::cross(cameraFront, cameraUp)) * cameraSpeed;
}
// glfw: whenever the window size changed (by OS or user resize) this callback function executes
// ---------------------------------------------------------------------------------------------
void framebuffer_size_callback(GLFWwindow* window, int width, int height)
{
// make sure the viewport matches the new window dimensions; note that width and
// height will be significantly larger than specified on retina displays.
glViewport(0, 0, width, height);
}
// glfw: whenever the mouse moves, this callback is called
// -------------------------------------------------------
void mouse_callback(GLFWwindow* window, double xpos, double ypos)
{
if (firstMouse)
{
lastX = xpos;
lastY = ypos;
firstMouse = false;
}
float xoffset = xpos - lastX;
float yoffset = lastY - ypos; //反过来因为y坐标从下到上
lastX = xpos;
lastY = ypos;
float sensitivity = 0.1f; // 根据自己喜好调整
xoffset *= sensitivity;
yoffset *= sensitivity;
yaw += xoffset;
pitch += yoffset;
// make sure that when pitch is out of bounds, screen doesn't get flipped
if (pitch > 89.0f)
pitch = 89.0f;
if (pitch < -89.0f)
pitch = -89.0f;
glm::vec3 front;
front.x = cos(glm::radians(yaw)) * cos(glm::radians(pitch));
front.y = sin(glm::radians(pitch));
front.z = sin(glm::radians(yaw)) * cos(glm::radians(pitch));
cameraFront = glm::normalize(front);
}
// glfw: whenever the mouse scroll wheel scrolls, this callback is called
// ----------------------------------------------------------------------
void scroll_callback(GLFWwindow* window, double xoffset, double yoffset)
{
fov -= (float)yoffset;
if (fov < 1.0f)
fov = 1.0f;
if (fov > 45.0f)
fov = 45.0f;
}
资源参考
LearnOpenGL