Spark Shuffle系列-----3. spark shuffle reduce操作RDD partition的生成
本篇文章以RDD.aggregateByKey引起的SortShuffleWriter为例说明Shuffle map端的原理和实现,为了便于说明问题这里的所有执行流程都是默认执行流程
为了便于说明问题,本文中Stage1是shuffle map操作所在的Stage,Stage2是shuffle reduce操作所在的Stage,本文中spark.shuffle.blockTransferService为默认方式netty
Shuffle map操作结束之后,Stage1结束,Spark的调度系统会启动Stage2,Stage2最首要的任务是根据ShuffledRDD和MapOutputTrackerMaster获取Stage2 partition的信息。具体流程可参见下面的时序图
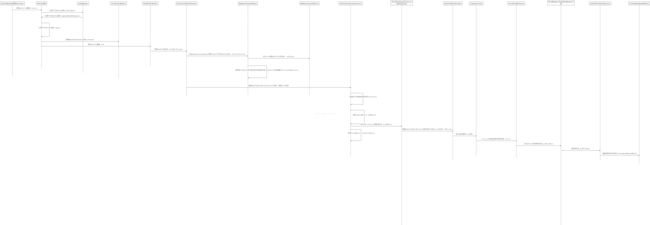
时序图对理解这个流程非常重要,放大后可清晰显示
ShuffleMapTask或者ResultTask在调用ShuffledRDD.iterator方法的时候执行到了ShuffledRDD.compute方法,计算和产生Stage2一个partition的数据
代码如下:
/*
* 从stage1生成的disk shuffle文件读取内容,读取后的内容产生Stage2的partition,并且最终将这个partition转换成Iterator
* */
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
.read()
.asInstanceOf[Iterator[(K, C)]]
}默认情况下,Spark使用SortShuffleManager管理Shuffle,在这里ShuffledRDD.computer方法先调用SortShuffleMananger.getReader方法创建HashShuffleReader对象,然后调用HashShuffleReader.read方法创建ShuffledRDD的分区
HashShuffleReader.read的源码如下:
override def read(): Iterator[Product2[K, C]] = {
/*
* 将Stage2 partition数据所在的每个块的数据转化成一个InputStream
* */
val blockStreams = BlockStoreShuffleFetcher.fetchBlockStreams(
handle.shuffleId, startPartition, context, blockManager, mapOutputTracker)
// Wrap the streams for compression based on configuration
val wrappedStreams = blockStreams.map { case (blockId, inputStream) =>
blockManager.wrapForCompression(blockId, inputStream)
}
val ser = Serializer.getSerializer(dep.serializer)
val serializerInstance = ser.newInstance()
// Create a key/value iterator for each stream
/*
* 对wrappedStream中的数据进行deserialize处理,Stage1 map操作将数据写入disk的时候,数据是序列化了的
* */
val recordIter = wrappedStreams.flatMap { wrappedStream =>
// Note: the asKeyValueIterator below wraps a key/value iterator inside of a
// NextIterator. The NextIterator makes sure that close() is called on the
// underlying InputStream when all records have been read.
serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator
}
// Update the context task metrics for each record read.
val readMetrics = context.taskMetrics.createShuffleReadMetricsForDependency()
val metricIter = CompletionIterator[(Any, Any), Iterator[(Any, Any)]](
recordIter.map(record => {
readMetrics.incRecordsRead(1)
record
}),
context.taskMetrics().updateShuffleReadMetrics())
// An interruptible iterator must be used here in order to support task cancellation
/*
* 将Stage2 partition的数据转化成Iterator
* */
val interruptibleIter = new InterruptibleIterator[(Any, Any)](context, metricIter)
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) {
// We are reading values that are already combined
val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]]
/*
* 如果在shuffle map操作已经在分区内部合并了相同Key的Value,则在这里合并不同分区间的Value
* */
dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context)
} else {
// We don't know the value type, but also don't care -- the dependency *should*
// have made sure its compatible w/ this aggregator, which will convert the value
// type to the combined type C
val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]]
/*
* 如果在shuffle map操作没有在分区内部合并相同Key的Value,则在这里合并Key相同的Value
* */
dep.aggregator.get.combineValuesByKey(keyValuesIterator, context)
}
} else {
require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!")
interruptibleIter.asInstanceOf[Iterator[Product2[K, C]]]
}
// Sort the output if there is a sort ordering defined.
dep.keyOrdering match {
case Some(keyOrd: Ordering[K]) =>
// Create an ExternalSorter to sort the data. Note that if spark.shuffle.spill is disabled,
// the ExternalSorter won't spill to disk.
val sorter = new ExternalSorter[K, C, C](ordering = Some(keyOrd), serializer = Some(ser))
sorter.insertAll(aggregatedIter)
context.taskMetrics.incMemoryBytesSpilled(sorter.memoryBytesSpilled)
context.taskMetrics.incDiskBytesSpilled(sorter.diskBytesSpilled)
sorter.iterator
case None =>
aggregatedIter
}
}HashShuffleReader.read首先调用BlockStoreShuffleFetcher.fetchBlockStreams方法RPC创建InputStream,远程读取Shuffle Transfer Service的数据块,然后对InputStream中的数据解压缩和deserialize处理之后,将流中的数据转化成Iterator,再之后在这个Iterator中,对Stage1分区间的数据进行合并。
BlockStoreShuffleFetcher.fetchBlockStreams方法首先调用调用MapOutputTrackerWorker.getServerStatues方法获取Stage1 shuffle map操作产生的分区信息,但是这些信息在ShuffleMapTask执行完毕之后只是返回给了MapOutputTrackerMaster,MapOutputTrackerWorker中没有。需要调用MapOutputTrackerWorker.askTracker从MapOutputTrackerMaster远程读取Stage1 shuffle map操作产生的分区信息。MapOutputTrackerMaster返回这些信息后MapOutputTrackerWorker.convertMapStatues对进一步处理,得到Stage1 Shuffle map操作产生的数据所在的节点IP地址、这个节点上数据的大小、Shuffle id。经过这一步处理之后,Stage2知道了获取数据的目的节点,并且知道了在目的节点上需要读取多少数据,知道了怎么到Shuffle Transfer Service服务读取数据。
然后创建从Shuffle Transfer Service读取数据信息的对象ShuffleBlockFetcherIterator
相关代码如下:
def fetchBlockStreams(
shuffleId: Int,
reduceId: Int,//ShuffledRDD的partition index
context: TaskContext,
blockManager: BlockManager,
mapOutputTracker: MapOutputTracker)
: Iterator[(BlockId, InputStream)] =
{
logDebug("Fetching outputs for shuffle %d, reduce %d".format(shuffleId, reduceId))
val startTime = System.currentTimeMillis
val statuses = mapOutputTracker.getServerStatuses(shuffleId, reduceId)
logDebug("Fetching map output location for shuffle %d, reduce %d took %d ms".format(
shuffleId, reduceId, System.currentTimeMillis - startTime))
val splitsByAddress = new HashMap[BlockManagerId, ArrayBuffer[(Int, Long)]]
for (((address, size), index) <- statuses.zipWithIndex) {
splitsByAddress.getOrElseUpdate(address, ArrayBuffer()) += ((index, size))//index是stage1的partition index
}
/*
* 获取shuffle文件的块信息,包括块所在的ip地址
* 块信息由shuffle id, stage1的partition index, stage2的partition index确定
* blocksByAddress一个元素为(块的地址, Seq(Shuffle块id, 块大小)) 这里的块大小是Stage1一个partition shuffle到Stage2这个partition的数据大小
* */
val blocksByAddress: Seq[(BlockManagerId, Seq[(BlockId, Long)])] = splitsByAddress.toSeq.map {
case (address, splits) =>
(address, splits.map(s => (ShuffleBlockId(shuffleId, s._1, reduceId), s._2)))
}
val blockFetcherItr = new ShuffleBlockFetcherIterator(
context,
blockManager.shuffleClient,
blockManager,
blocksByAddress,
// Note: we use getSizeAsMb when no suffix is provided for backwards compatibility
SparkEnv.get.conf.getSizeAsMb("spark.reducer.maxSizeInFlight", "48m") * 1024 * 1024)
// Make sure that fetch failures are wrapped inside a FetchFailedException for the scheduler
blockFetcherItr.map { blockPair =>
val blockId = blockPair._1
val blockOption = blockPair._2
blockOption match {
case Success(inputStream) => {
(blockId, inputStream)
}
case Failure(e) => {
blockId match {
case ShuffleBlockId(shufId, mapId, _) =>
val address = statuses(mapId.toInt)._1
throw new FetchFailedException(address, shufId.toInt, mapId.toInt, reduceId, e)
case _ =>
throw new SparkException(
"Failed to get block " + blockId + ", which is not a shuffle block", e)
}
}
}
}
}def getServerStatuses(shuffleId: Int, reduceId: Int): Array[(BlockManagerId, Long)] = {
val statuses = mapStatuses.get(shuffleId).orNull
/*
* Shuffle reduce刚开始执行的时候,statues会为null,这个时候需要向Driver的MapOutputTrackerMaster发消息,获得Stage1
* 产生的shuffle信息
* */
if (statuses == null) {
logInfo("Don't have map outputs for shuffle " + shuffleId + ", fetching them")
var fetchedStatuses: Array[MapStatus] = null
fetching.synchronized {
// Someone else is fetching it; wait for them to be done
while (fetching.contains(shuffleId)) {
try {
fetching.wait()
} catch {
case e: InterruptedException =>
}
}
// Either while we waited the fetch happened successfully, or
// someone fetched it in between the get and the fetching.synchronized.
fetchedStatuses = mapStatuses.get(shuffleId).orNull
if (fetchedStatuses == null) {
// We have to do the fetch, get others to wait for us.
fetching += shuffleId
}
}
if (fetchedStatuses == null) {
// We won the race to fetch the output locs; do so
logInfo("Doing the fetch; tracker endpoint = " + trackerEndpoint)
// This try-finally prevents hangs due to timeouts:
try {
/*
*向Driver的MapOutputTrackerMaster发消息,获得Stage1
* 产生的shuffle信息
* */
val fetchedBytes = askTracker[Array[Byte]](GetMapOutputStatuses(shuffleId))
fetchedStatuses = MapOutputTracker.deserializeMapStatuses(fetchedBytes)
logInfo("Got the output locations")
mapStatuses.put(shuffleId, fetchedStatuses)
} finally {
fetching.synchronized {
fetching -= shuffleId
fetching.notifyAll()
}
}
}
if (fetchedStatuses != null) {
fetchedStatuses.synchronized {
return MapOutputTracker.convertMapStatuses(shuffleId, reduceId, fetchedStatuses)
}
} else {
logError("Missing all output locations for shuffle " + shuffleId)
throw new MetadataFetchFailedException(
shuffleId, reduceId, "Missing all output locations for shuffle " + shuffleId)
}
} else {
statuses.synchronized {
return MapOutputTracker.convertMapStatuses(shuffleId, reduceId, statuses)
}
}
}MapOutputTrackerWorker.convertMapStatues方法:
private def convertMapStatuses(
shuffleId: Int,
reduceId: Int,
statuses: Array[MapStatus]): Array[(BlockManagerId, Long)] = {
assert (statuses != null)
/*
* statuses是一个数组,status是这个数组中的一个元素,数组中的每个元素表示shuffle map阶段的一个partition shuffle到shuffle reduce阶段每个partition的数据量
* status.location是shuffle map 阶段的BlockManager.shuffleServerId
* status.getSizeForBlock(reduceId)表示partition index是redueceId在生成的Shuffle disk文件中得数据量
* */
statuses.map {
status =>
if (status == null) {
logError("Missing an output location for shuffle " + shuffleId)
throw new MetadataFetchFailedException(
shuffleId, reduceId, "Missing an output location for shuffle " + shuffleId)
} else {
(status.location, status.getSizeForBlock(reduceId))
}
}
}创建ShuffleBlockFetcherIterator对象的时候,会直接执行ShuffleBlockFetcherIterator.initialize方法,在这个方法里面首先调用ShuffleBlockFetcherIterator.splitLocalRemoteBlocks创建从远程读取数据块的FetchRequest对象和从本地读取数据块数组。然后调用ShuffleBlockFetcherIterator.sendRequest远程读取数据读取请求,再执行本地数据读取。代码如下:
private[this] def initialize(): Unit = {
// Add a task completion callback (called in both success case and failure case) to cleanup.
context.addTaskCompletionListener(_ => cleanup())
// Split local and remote blocks.
val remoteRequests = splitLocalRemoteBlocks()
// Add the remote requests into our queue in a random order
fetchRequests ++= Utils.randomize(remoteRequests)
// Send out initial requests for blocks, up to our maxBytesInFlight
while (fetchRequests.nonEmpty &&
(bytesInFlight == 0 || bytesInFlight + fetchRequests.front.size <= maxBytesInFlight)) {
sendRequest(fetchRequests.dequeue())//获取远程读取数据块InputStream
}
val numFetches = remoteRequests.size - fetchRequests.size
logInfo("Started " + numFetches + " remote fetches in" + Utils.getUsedTimeMs(startTime))
// Get Local Blocks
fetchLocalBlocks()//获取本地读取数据块InputStream
logDebug("Got local blocks in " + Utils.getUsedTimeMs(startTime))
}ShuffleBlockFetcherIterator.sendRequest方法首先调用ShuffleClient.fetchBlocks方法(在这里ShuffleClient实际是NettyBlockTransferService对象)读取远程的Block。
NettyBlockTransferService.fetchBlocks方法通过创建OneForOneBlockFetcher对象并且调用OneForOneBlockFetcher.start方法向远程Shuffle Transfer Service读取远程的块。OneForOneBlockFetcher对象的时候,这个对象的openMessage成员设置成OpenBlocks类型,这样远程Shuffle Transfer Service会接收到OpenBlocks消息。代码如下:
public class OneForOneBlockFetcher {
private final Logger logger = LoggerFactory.getLogger(OneForOneBlockFetcher.class);
private final TransportClient client;
private final OpenBlocks openMessage;
private final String[] blockIds;
private final BlockFetchingListener listener;
private final ChunkReceivedCallback chunkCallback;
private StreamHandle streamHandle = null;
public OneForOneBlockFetcher(
TransportClient client,
String appId,
String execId,
String[] blockIds,
BlockFetchingListener listener) {
this.client = client;
//消息类型是OpenBlocks类型
this.openMessage = new OpenBlocks(appId, execId, blockIds);
this.blockIds = blockIds;
this.listener = listener;
this.chunkCallback = new ChunkCallback();
}
/** Callback invoked on receipt of each chunk. We equate a single chunk to a single block. */
private class ChunkCallback implements ChunkReceivedCallback {
@Override
public void onSuccess(int chunkIndex, ManagedBuffer buffer) {
// On receipt of a chunk, pass it upwards as a block.
listener.onBlockFetchSuccess(blockIds[chunkIndex], buffer);
}
@Override
public void onFailure(int chunkIndex, Throwable e) {
// On receipt of a failure, fail every block from chunkIndex onwards.
String[] remainingBlockIds = Arrays.copyOfRange(blockIds, chunkIndex, blockIds.length);
failRemainingBlocks(remainingBlockIds, e);
}
}
/**
* Begins the fetching process, calling the listener with every block fetched.
* The given message will be serialized with the Java serializer, and the RPC must return a
* {@link StreamHandle}. We will send all fetch requests immediately, without throttling.
*/
public void start() {
if (blockIds.length == 0) {
throw new IllegalArgumentException("Zero-sized blockIds array");
}
//发送OpenBlocks消息到远程Shuffle Transfer service
client.sendRpc(openMessage.toByteArray(), new RpcResponseCallback() {
@Override
public void onSuccess(byte[] response) {
try {
streamHandle = (StreamHandle) BlockTransferMessage.Decoder.fromByteArray(response);
logger.trace("Successfully opened blocks {}, preparing to fetch chunks.", streamHandle);
// Immediately request all chunks -- we expect that the total size of the request is
// reasonable due to higher level chunking in [[ShuffleBlockFetcherIterator]].
for (int i = 0; i < streamHandle.numChunks; i++) {
client.fetchChunk(streamHandle.streamId, i, chunkCallback);
}
} catch (Exception e) {
logger.error("Failed while starting block fetches after success", e);
failRemainingBlocks(blockIds, e);
}
}
@Override
public void onFailure(Throwable e) {
logger.error("Failed while starting block fetches", e);
failRemainingBlocks(blockIds, e);
}
});
}
/** Invokes the "onBlockFetchFailure" callback for every listed block id. */
private void failRemainingBlocks(String[] failedBlockIds, Throwable e) {
for (String blockId : failedBlockIds) {
try {
listener.onBlockFetchFailure(blockId, e);
} catch (Exception e2) {
logger.error("Error in block fetch failure callback", e2);
}
}
}
}
NettyBlockRpcServer对象实现了来客户端的RPC请求的处理,它在NettyBlockTransferService.init方法中创建之后通过调用NettyBlockTransferService.createServer方法将它设置为RPC请求的处理对象,代码如下:
override def init(blockDataManager: BlockDataManager): Unit = {
val rpcHandler = new NettyBlockRpcServer(serializer, blockDataManager)
var serverBootstrap: Option[TransportServerBootstrap] = None
var clientBootstrap: Option[TransportClientBootstrap] = None
if (authEnabled) {
serverBootstrap = Some(new SaslServerBootstrap(transportConf, securityManager))
clientBootstrap = Some(new SaslClientBootstrap(transportConf, conf.getAppId, securityManager,
securityManager.isSaslEncryptionEnabled()))
}
transportContext = new TransportContext(transportConf, rpcHandler)
clientFactory = transportContext.createClientFactory(clientBootstrap.toList)
/*
* 创建rpc请求服务,它会调用TransportContext.createServer方法,在这个方法会把前面
* 创建的rpcHandler(NettyBlockRpcServer对象)作为rpc服务的处理对象
* */
server = createServer(serverBootstrap.toList)
appId = conf.getAppId
logInfo("Server created on " + server.getPort)
}NettyBlockRpcServer.receive方法接收到OpenBlocks消息后,调用BlockManager.getBlockData读取块信息,返回读取块信息的InputStream,代码如下:
override def receive(
client: TransportClient,
messageBytes: Array[Byte],
responseContext: RpcResponseCallback): Unit = {
val message = BlockTransferMessage.Decoder.fromByteArray(messageBytes)
logTrace(s"Received request: $message")
message match {
case openBlocks: OpenBlocks =>
val blocks: Seq[ManagedBuffer] =
openBlocks.blockIds.map(BlockId.apply).map(blockManager.getBlockData)//调用BlockManager.getBlockData读取块信息,返回InputStream
val streamId = streamManager.registerStream(blocks.iterator)
logTrace(s"Registered streamId $streamId with ${blocks.size} buffers")
responseContext.onSuccess(new StreamHandle(streamId, blocks.size).toByteArray)
case uploadBlock: UploadBlock =>
// StorageLevel is serialized as bytes using our JavaSerializer.
val level: StorageLevel =
serializer.newInstance().deserialize(ByteBuffer.wrap(uploadBlock.metadata))
val data = new NioManagedBuffer(ByteBuffer.wrap(uploadBlock.blockData))
blockManager.putBlockData(BlockId(uploadBlock.blockId), data, level)
responseContext.onSuccess(new Array[Byte](0))
}
}
override def getBlockData(blockId: ShuffleBlockId): ManagedBuffer = {
// The block is actually going to be a range of a single map output file for this map, so
// find out the consolidated file, then the offset within that from our index
val indexFile = getIndexFile(blockId.shuffleId, blockId.mapId)
val in = new DataInputStream(new FileInputStream(indexFile))
try {
ByteStreams.skipFully(in, blockId.reduceId * 8)
val offset = in.readLong()//根据Stage2 分区的id(rediceId)读取从index文件要读取的数据块在shuffle数据文件的起始地址
val nextOffset = in.readLong()//根据Stage2 分区的id(rediceId)读取从index文件要读取的数据块在shuffle数据文件的结束地址
new FileSegmentManagedBuffer(
transportConf,
getDataFile(blockId.shuffleId, blockId.mapId),
offset,
nextOffset - offset)
} finally {
in.close()
}
}至此,Stage2 Shuffle reduce操作分区的生成分析完成。Stage2生成了它的分区之后,一个崭新的Stage开始执行。
总结一下:Stage2根据Stage1生成的Shuffle数据index文件和Shuffle数据存储文件重新生成了RDD分区,在这里面MapOutputTracker和ShuffledRDD是Stage1和Stage2的桥梁。