Python中的re模块
Python中的re模块
文章目录
- Python中的re模块
- 常量
- 常用方法
- 编译
- 单次匹配
- 全文搜索
- 匹配替换
- 分割字符串
- 其他
- 编译后的对象支持方法和属性
- 属性
- match对象
- match的属性
- 常用方法
Python使用re模块提供了正则表达式处理的能力。
常量
| 常量 | 对应值 | 说明 |
|---|---|---|
| re.I re.IGNORECASE |
2 | 忽略大小写 |
| re.M re.MuLTILINE |
8 | 多行模式 |
| re.S re.DOTALL |
16 | 单行模式 |
| re.X re.VERBOSE |
64 | 忽略表达式中的空白字符 |
- 使用|或位运算可以开启多种选项。相加也可以。
- 注意:
- Python默认中re接受正则表达式中的命名分组格式为:(?P
exp) - 命名分组的反向引用为(?P=name)
- Python的后发断言(?<=exp)和(?
- Python默认中re接受正则表达式中的命名分组格式为:(?P
常用方法
编译
- re.compile(pattern,flags=0)->regex #将正则表达式模式编译成正则表达式对象。
- pattern #需要编译的正则表达式
- flags #正则表达式使用的模式。re.S|re.M 开启多行模式和单行模式
- 常用模式有:re.I,re.M,re.S,re.X
为了提高效率,正则表达式可以被编译,这些编译后的结果被保存,下次使用同样的pattern的时候,就不需要再次编译。
编译后的对象同样可以使用match(),search()方法进行匹配。
- 常用模式有:re.I,re.M,re.S,re.X
单次匹配
- re.match(pattern,string,flags=0)->match #匹配从字符串的开头匹配,返回match对象
- regex.match(string[,pos[,endpos]])->match #regex对象match方法可以重设定开始位置和结束位置。返回match对象
- pattern #正则表达式
- string #需要匹配的字符串
- flags #正则表达式使用的模式
- 常用模式有:re.I,re.M,re.S,re.X
- pos #匹配字符串的开始位置,默认从0索引位置开始匹配
- endpos #匹配字符串的结束位置(不包含结束位置),默认值为len(string)
- 注意:
- match会从字符串的开头开始查找,即使在re.M(多行模式)中。^符号也只表示字符串的开头,$符号也只表示字符串的结尾。即:多行模式re.M对match无效
- match只会从字符串的开始位置(开始位置可以是字符串的开头,也可以用pos指定)与正则表达式的第一个字符开始匹配。
- regex.match中指定开始位置和结束位置后启用多行模式,对^和$符号无影响,依然是指原字符串的开头和结尾
- re.match,re.search,re.fullmatch三个匹配方法中只有re.match忽略多行模式的影响。
简单示例1:
import re
str1 = """123
456"""
print(re.match("^\d*",str1,re.M))
print(re.match("^\d*",str1))
print(re.match("^[\d\n]*",str1,re.M))
regex = re.compile("^\d*")
print(regex.match(str1))
#注意regex可以重新指定字符串的开始位置,和结束位置(不包含结束位置)
print(regex.match(str1,0,2))
#注意:regex中开始位置和结束位置对^和$符号无影响,依然是指原字符串的开头和结尾
print(regex.match(str1,3)) #返回值为None,因为截开始的位置不是字符串的开头。所以无法匹配
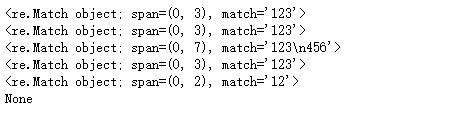
简单示例2:
import re
import re
str2 = """abc abc bcd eff aaa
abc bcd"""
print(re.match("bcd",str2)) #match只会从字符串的开头与正则表达式开始位置进行匹配。
print(re.match("^a",str2,re.M)) #依旧从开始位置查找,多行模式无影响
![]()
- re.search(pattern,string,flags=0)->match #从头搜索到第一个匹配
- regex.search(string[,pos[,endpos]])->match #从头搜索到第一个匹配
- pattern #正则表达式
- string #需要匹配的字符串
- flags #模式
- pos #匹配的起始位置
- endpos #匹配的结束位置(不包含结束位置)
import re str2 = """abc abc bcd eff aaa bc bcd""" print(re.search("bcd",str2)) #search从找到匹配的第一个结果返回。 print(re.search("^b",str2)) print(re.search("^b",str2,re.M)) #可以识别多行模式中的字符
- re.fullmatch(pattern,string,flags=0)->match #(整个字符串和正则表达式匹配)起始位置和结束位置的字符串和整个正则表达式匹配
- regex.fullmatch(string[,pos[,endpos]])->match #(整个字符串和正则表达式匹配)起始位置和结束位置的字符串和整个正则表达式匹配
- pattern #正则表达式
- string #需要匹配的字符串
- flags #模式
- pos #匹配的起始位置
- endpos #匹配的结束位置(不包含结束位置)
import re str2 = """abc abc bcd eff aaa bc bcd""" print(re.fullmatch("bcd",str2)) #fullmatch起始位置和结束位置的字符串和整个正则表达式匹配 print(re.fullmatch("a[\w \n]*",str2)) print(re.fullmatch("b[\w \n]*",str2,re.M)) print(re.compile("b[\w \n]*").fullmatch(str2,20)) #改变起始位置匹配 print(re.compile("^b[\w \n]*").fullmatch(str2,20)) #因为是单行模式,所有^只表示字符串的开始位置 print(re.compile("^b[\w \n]*",re.M).fullmatch(str2,20)) #可以识别多行模式
全文搜索
- re.findall(pattern,string,flags=0)->list #对整个字符串从左至右匹配,返回所有匹配项的列表
- regex.findall(string[,pos[,endpos]])->list #对整个字符串从左至右匹配,返回所有匹配项的列表
- pattern #正则表达式
- string #需要匹配的字符
- flags #模式
- pos #匹配的起始位置
- endpos #匹配的结束位置(不包含结束位置)
import re str1 = """abc abcd def dbc abc""" print(re.findall("\w+",str1)) repex = re.compile("\w+") print(repex.findall(str1)) print(repex.findall(str1,5)) print("-------------") print(re.findall("^\w+",str1)) print(re.findall("^\w+",str1,re.M))
- re.finditer(pattern,string,flags=0)->iterable #对整个字符串从左至右匹配,返回所有匹配选项,返回迭代器
- regex.finditer(string[,pos[,endpos]])->iterable ##对整个字符串从左至右匹配,返回所有匹配选项,返回迭代器
- pattern #正则表达式
- string #需要匹配的字符
- flags #模式
- pos #匹配的起始位置
- endpos #匹配的结束位置(不包含结束位置)
- 注意:每次迭代返回的是match对象
import re str1 = """abc abcd def dbc abc""" reiter = re.finditer("\w+",str1) print(type(reiter),reiter) a = next(reiter) print(type(i),i) for i in reiter: print(i.start(),i.end(),i.span(),i.group(0)) print(i)
匹配替换
-
re.sub(pattern,replacement,string,count=0,flags=0)->new_string #将匹配到的字符替换成指定字符
-
regex.sub(replacement,string,count=0)->new_string #将匹配到的字符替换成指定字符
- pattern #正则表达式
- replacement #替换字符串
- string #字符串(原始字符串)
- count #替换的次数,默认值为0 表示全部替换
- flags #模式
- 返回值new_string #替换后生成的新字符串
-
re.subn(pattern,replacement,string,count=0,flags=0)->(new_string,number_of_subs_made) #将匹配到的字符替换成指定字符
-
regex.subn(replacement,string,count=0)->(new_string,number_of_subs_made) #将匹配到的字符替换成指定字符
- pattern #正则表达式
- replacement #替换字符串
- string #字符串(原始字符串)
- count #替换的次数,默认值为0 表示全部替换
- flags #模式
- 返回值是个元组(new_string,number_of_subs_made)
- new_string #替换后生成的新字符
- number_of_subs_made #替换的次数
简单示例:
import re str1 = "a23asldkf234xdd" print(re.sub("\d","你",str1)) print(re.subn("\d","你",str1)) print(re.sub("\d","你",str1,2)) req = re.compile("\d") print(req.sub("爱",str1,3)) print(req.subn("爱",str1))
分割字符串
- re.split(pattern,string,maxsplit=0,flags=0)->list
- regex.split(string,maxsplit=0)->list
- pattern #正则表达式
- string #需要切割的字符串
- maxsplit=0 #最大切割次数,默认值为0,表示全部切割
- flags #模式
简单示例:
import re str1 = "a1dslkd3ksdk245ks5jdf" print(re.split("\d",str1)) print(re.split("\d",str1,2)) print("----------") rep = re.compile("\d") print(rep.split(str1)) print(rep.split(str1,1)) print("---------------") print(re.split("k(s)",str1))
其他
- re.escape(pattern) #转义特殊字符
- patern #将正则表达式中的特殊字符转义
>>> print(re.escape('python.exe')) python\.exe >>> legal_chars = string.ascii_lowercase + string.digits + "!#$%&'*+-.^_`|~:" >>> print('[%s]+' % re.escape(legal_chars)) [abcdefghijklmnopqrstuvwxyz0123456789!\#\$%\&'\*\+\-\.\^_`\|\~:]+ >>> operators = ['+', '-', '*', '/', '**'] >>> print('|'.join(map(re.escape, sorted(operators, reverse=True)))) /|\-|\+|\*\*|\*
编译后的对象支持方法和属性
编译后的对象Pattern,在本文中使用regex代替。
即:re.complie()->regex
属性
- regex.flags #编译后的正则表达式的模式
- regex.groups #模式中捕获组的数量
- regex.groupindex #是一个字典,用来映射模式中命名组与对应索引的键值对。如果没有命名组,则字典为空
- regex.pattern #编译对象中的正则表达式对象。
>>> rep = re.compile(r"(\d+)\.(?P\d+)" )
>>> print(rep.pattern)
(\d+)\.(?P<name>\d+)
>>> rep.groups,rep.groupindex
(2, mappingproxy({'name': 2}))
match对象
re.match与re.search函数可以返回match对象,re.finditer可迭代对象返回的也是match对象。如果pattern(正则表达式)中使用了分组,如果有匹配结果,会在match对象中。
1. 使用group(N)方式可以获取对应分组,1到N是对应的分组,0返回整个匹配的字符串,也就是默认分组Match,N默认的缺省值为0。
2. 如果使用了命名分组,可以使用group(“name”)的方式获取分组
3. 也可以使用groups()返回所有组
4. 使用groupdict()返回所有命名的分组,和组名的对应关系组成的字典
match的属性
- Match.string #传递进来的字符串,即调用re.match()和re.search()对应时传递的字符串string参数
- Match.pos #正则表示的的查找的起始索引值。类似于regex.match(string[,pos[,endpos]])中的pos所指定的值
- Match.endpos #正则表达式查找的结束索引值。类型于regex.match(string[,pos[,endpos]])中的endpos所指定的值
- Match.lastindex #匹配正则表达式中最后一个组的索引值。如果没有匹配任何组返回None
- Match.lastgroup #匹配正则表达式中最后一个有名称的组名,如果没有组名称,或没有组返回None
- Match.re #re.match()和re.search()等生产的正则表达式对象re。相当于re.compile生成对象一样。
常用方法
- Match.start([group=0]) #获取组所表示字符串的起始索引,默认值为0,表示获取默认组Match组
- Match.end([group=0]) #获取组所表示字符串的结束索引(不包含结束索引位置的值),默认值为0,表示获取默认组Match组
- Match.span([group=0])->(Match.start,Match.end) #获取所对应组的字符串起始位置和结束位置的元组。
- Match.group([group1,…]) #获取指定组的元素,如果指定多个组,返回一个元组
- group1 #组的id或者名称
>>> m = re.match(r"(\d+)\.(?P\d+)" ,"24.356") >>> m.group(1),m.group("name"),m.group(1,"name") ('24', '356', ('24', '356')) - Match.getitem(g) #与m.group(g)相同,可以直接使用Match对象想数组一样访问单个组
>>> m = re.match(r"(\w+) (\w+)", "Isaac Newton, physicist") >>> m[0] # The entire match 'Isaac Newton' >>> m[1] # The first parenthesized subgroup. 'Isaac' >>> m[2] # The second parenthesized subgroup. 'Newton' - Match.groups(default=None)->tuple #返回所有组组成的tuple,但不包含默认组0的值。
- default默认值为None,如果返回的组中有的组没有值,用默认值default代替。
>>> m = re.match(r"(\d+)\.(\d+)", "24.1632") >>> m.groups() ('24', '1632') >>> m = re.match(r"(\d+)\.?(\d+)?", "24") >>> m.groups() # Second group defaults to None. ('24', None) >>> m.groups('0') # Now, the second group defaults to '0'. ('24', '0') - Match.groupdict(default=None)->dict #获取所有命名分组的组名和值的对应关系组成的字典
>>> m = re.match(r"(?P\w+) (?P , "Malcolm Reynolds") >>> m.groupdict() {'first_name': 'Malcolm', 'last_name': 'Reynolds'}\w+)" - Match.expand(template)->string #将匹配到的分组带入template中然后返回新的字符串
- template 需要替换代替的字符串
- 语法:\id或\g
\g 表示应用Match中的指定的组,但不能使用编号0。\id与\g是等价的;但\10被认为是第10个分组,如果想要表达\1后是字符‘0’,只能使用<1>0来表示。
- 语法:\id或\g
- python3.5更改:未匹配的组用空字符串替代
>>> m = re.match(r"(\d+)\.(?P\d+)","24.356") >>> m.expand(r"ab\1bcd\g ") 'ab24bcd356' - template 需要替换代替的字符串