kafka数据处理框架
kafka数据处理框架
kafka框架:https://blog.csdn.net/weixin_40596016/article/details/79164680
kafka
高吞吐量分布式的消息发布和订阅系统,提供一个分布式的,可划分的,冗余备份的持久性的日志服务。主要用于处理活跃的流式数据。
在大数据系统中,经常碰到一个问题,整个大数据是由各个子系统组成,且数据需要在各个子系统中高性能,低延时的不停流转。这时候kafka相当于起到了整个大数据系统的数据总线的作用,它提供了固定的接口,有效降低系统组网的复杂度,避免各个子系统之间相互协调接口。
kafka的主要特点
1、同时为发布和订阅提供高吞吐量。据了解,Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB)。
2、可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。通过将数据持久化到硬盘以及replication防止数据丢失。
3、分布式系统,易于向外扩展。所有的producer、broker和consumer都会有多个,均为分布式的。无需停机即可扩展机器。
4、消息被处理的状态是在consumer端维护,而不是由server端维护。当失败时能自动平衡。
5、支持online和offline的场景。
kafka架构

Kafka的整体架构非常简单,是显式分布式架构,producer、broker(kafka)和consumer都可以有多个。producer,consumer实现Kafka注册的接口,数据从producer发送到broker,broker承担一个中间缓存和分发的作用。broker分发注册到系统中的consumer。broker的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存。客户端和服务器端的通信,是基于简单,高性能,且与编程语言无关的TCP协议。
几个基本概念:
1、Topic:特指Kafka处理的消息源(feeds of messages)的不同分类。
2、Partition:Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。
3、Message:消息,是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。
4、Producers:消息和数据生产者,向Kafka的一个topic发布消息的过程叫做producers。
5、Consumers:消息和数据消费者,订阅topics并处理其发布的消息的过程叫做consumers。
6、Broker:缓存代理,Kafka集群中的一台或多台服务器统称为broker。
消息发送的流程
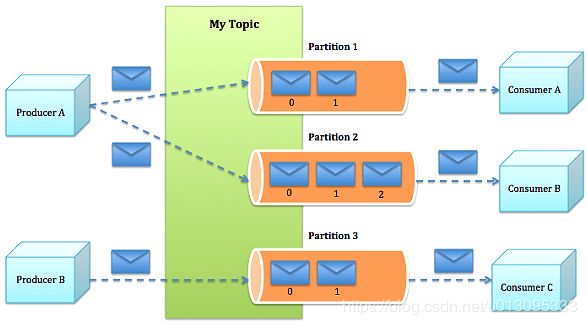
- Producer根据指定的partition方法(round-robin、hash等),将消息发布到指定topic的partition里面。
- kafka集群接收到Producer发过来的消息后,将其持久化到硬盘,并保留消息指定时长(可配置),而不关注消息是否被消费。
- Consumer从kafka集群pull数据,并控制获取消息的offset。
kafka的设计
吞吐量
高吞吐量是kafka需要实现的核心目标之一
1、数据在磁盘上进行持久化:消息不在内存中cache,直接写入到磁盘,充分利用磁盘的顺序读写性能
2、zero-copy(零拷贝),减少IO
3、数据批量发送
4、数据压缩
5、Topic划分为多个partition,提高parallelism
负载均衡
1、producer根据用户指定的算法,将消息发送到指定的partition
2、存在多个partiiton,每个partition有自己的replica,每个replica分布在不同的Broker节点上
3、多个partition需要选取出lead partition,lead partition负责读写,并由zookeeper负责fail over
4、通过zookeeper管理broker与consumer的动态加入与离开
拉取系统
由于kafka broker会持久化数据,broker没有内存压力,因此,consumer非常适合采取pull的方式消费数据,具有以下几点好处:
1、简化kafka的设计
2、consumer根据消费能力自主控制消息拉取速度
3、consumer根据自身情况自主选择消费模式,比如批量,重复消费,从尾端开始消费等
可扩展性
当需要增加broker结点时,新增的broker会向zookeeper注册,而producer及consumer会根据注册在zookeeper上的watcher感知这些变化,并及时作出调整。