实例分析神经网络传播过程
- 神经网络简介
- 博客主要内容
- 神经网络框架
- 神经网络前向传播实例
- 神经网络反向传播实例
- 总结
- 引用
一.神经网络简介
今天,神经网络(nerual networks)已经是一个相当大的、多学科交叉的学科领域[1]。它不能用简单的用“一个算法”,“一个框架”,来总结它的内容。从早期神经元(neuron),到感知器(Perceptron),再到Bp神经网络,然后到今天的深度学习(deep learning),这是它的大致的一个演变的过程。虽然不同的年代换了不同的说法,不过,大致的思想,比如前向数值传播,反向误差传播等思想是大体一致的。
二.主要内容
本博客主要详细介绍神经网络的前向传播和误差的传播过程,通过简单的只有单层隐藏层的神经网络,然后利用详细的数值实例来进行演示。而且,每一个步骤,博主都提供了tensorflow[2]的实现代码。
三.神经网络框架


对于一个神经元有
![]()
tensorflow的代码
def multilayer_perceptron(x , weights , bias):
layer_1 = tf.add(tf.matmul(x , weights["h1"]) , bias["b1"])
layer_1 = tf.nn.sigmoid(layer_1)
out_layer = tf.add(tf.matmul(layer_1 , weights["out"]) , bias["out"])
layer_2 = tf.nn.sigmoid(out_layer)
return layer_2四.神经网络前向传播实例
(1)确定输入数据和GD
X = [[1 , 2] , [3 , 4]]
Y = [[0 , 1] , [0 , 1]]很明显 batch_size = 2. 其中第一次batch_size
X1 = 1
X2 = 2
(2)初始化权重和偏执
从图1看出 weights数目为8 偏执为4
weights = {
'h1': tf.Variable([[0.15 , 0.16], [0.17 , 0.18]] , name="h1"),
'out': tf.Variable([[0.15 , 0.16], [0.17 , 0.18]] , name="out")
}
biases = {
'b1': tf.Variable([0.1,0.1] , name="b1"),
'out': tf.Variable([0.1 ,.1] , name="out")
}
(3)前向传播实例
以第一个神经元为例:
有
![]()
有
![]()
最后,得到隐藏层 的输出
前向传播的 tensorflow的代码
import tensorflow as tf
import numpy as np
x = [1 , 2]
weights = [[0.15 , 0.16] , [0.17 , 0.18]]
b = [0.1 , 0.1]
X = tf.placeholder("float" , [None , 2])
W = tf.placeholder("float" , [2 , 2])
bias = tf.placeholder("float" , [None , 2])
mid_value = tf.add(tf.matmul(X , W) , b)
result = tf.nn.sigmoid(tf.add(tf.matmul(X , W) , b))
with tf.Session() as sess:
x = np.array(x).reshape(1 , 2)
print x
b = np.array(b).reshape(1 , 2)
result , mid_value = sess.run([result , mid_value] , feed_dict={X : x , W : weights , bias : b})
print mid_value
print result同样的道理,我们得到输出层的pred
(4)计算误差
误差函数的可选择性很多,本示例使用的均方误差函数(mean squared error)。
![]()
注意和平方误差的区别,下面是平方误差(sum-squared error)
![]()
根据均方误差计算产生的误差:
![]()
至此,前向传播过程完成。
五.神经网络反向传播实例
知道了默认的输出和我们期望产生的误差,那么我们就需要根据误差去优化神经网路的中的参数,而误差的传播,参数的更新是从输出层开始,往前进行的.这种优化方式,叫做反向传播算法,或者误差逆传播算法(BackPropagation,简称BP)。Bp算法是神经网络的核心部分,几乎所有的神经网络模型都是通过该算法或者改进算法进行训练优化的。BP算法是基于梯度下降(gradient descent)策略,以目标的负梯度方向传播的。
我们给定学习率为0.5 , 有每次更新。

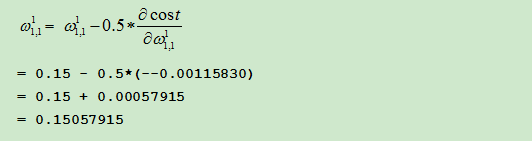
(1)先更新输出层的权重(weights)
根据链式法则有

第一项为对均方误差函数求导数

第二项为对激活函数的梯度

第三项

所以

进行更新

其他同理

(2)更新bias
根据链式法则有

更新

同理

(3)接下来更新隐藏层的weight
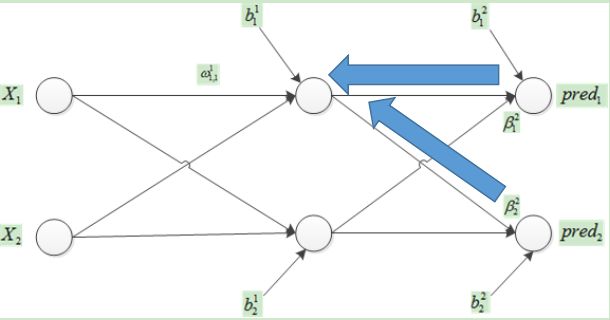
那么有

其中对于总的误差
![]()
有
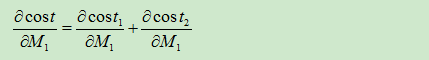
先求cost1

(其中的有些项在之前已经求过结果了,所以直接拿过来进行计算)
再求cost2

总的

然后计算第二项有

计算第三项有

合并计算

更新
同理,其他



(4)更新隐藏层的bias
同样根据链式法则有

更新

同理更新

六.总结
(1)到此,所有参数更新完毕,那么在下一个batch[3,4],通过新的参数的前向传播,产生的误差为
比第一次 0.254468的确小了,这也说明了梯度下降的有效性。
(2)我通过计算和代码的结果是有0.01的误差,我猜想的原因一个是我计算的错误,在一个是数值产生误差。
其中的错误,如果你发现,请给我提示,谢谢!
(3)代码细节
其中tensorflow中的优化方法
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)cost定义
cost = tf.reduce_mean(tf.pow(pred - y , 2))(4)梯度消失问题(Vanish Gradient Problem)
梯度消失问题是,在训练的过程中,梯度会变得很小,或者梯度变成了0,以至于参数更新过于缓慢,难以训练,这个对于过深的神经网络是不可避免的问题。梯度消失问题是与激活函数有一定的关系,通常我们使用relu或者relu的改进版(比如prelu[3])来缓和梯度消失问题,在我们本次的实例中,我们使用的是ligistic函数,它的导数是小于1的,当然tanh也是导数1的。我们可以从之前的运算中发现,在向后传到的过程中,都会有。
那么对于导数小于1的,误差向后传到的过程中,自然会越来越小。所以,为了解决这个问题,比如使用relu(导数为1)代替ligistic类型的函数,也就缓和了这种问题。
七.引用
[1]周志华.《机器学习》
[2]http://tensorflow.org/
[3]Kaiming He.Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification