Convolution Networks 和Deconvolution Networks
一.卷积的概念
卷积是分析数学中的一种重要运算,英文convolution。需要注意的是,以下我们考虑都是离散情况下的卷积操作。从概念上说,卷积是线性情况的下的滤波处理,性滤波处理经常被称为“掩码与图像的卷积”[1]。具体的操作则是,卷积是两个变量在某范围内相乘后求和的结果。如果卷积的变量是序列x(n)和h(n),则卷积的结果。
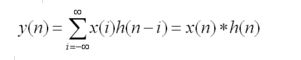
其中*表示卷积。
那对于二维图像上的卷积操作,是计算机视觉中的一个重要,常见的图像处理方法。离散卷积的计算过程是模板翻转,然后在原图像上滑动模板,把对应位置上的元素相乘后加起来,得到最终的结果。
给定![]()
滤波器:![]()
则有卷积公式为:
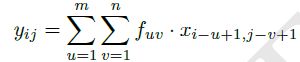
有些滤波算法就可以通过特殊的卷积滤波器来实现的,比如均值滤波(mean filter).算数均值滤波器是最简单的均值滤波器[2],也就是将当前位置的像素值设为滤波器窗口中所有像素的平均值,这个可以通过用value=1/mn的卷积模板来实现。
二.卷积操作的可视化表示
先来可视化化的看下卷积操作。具体看开源项目。
关于可视化的开源项目链接
其中的样历。
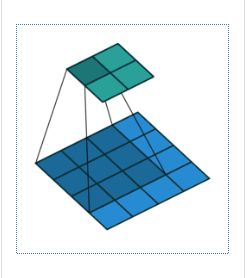

其中蓝色矩阵为输入值,绿色矩阵为输出值。(No padding, no strides)
三.卷积操作转化为矩阵乘积
以padding=‘FULL’的conv为例。此时,输入的大小为(width , height) , filter的大小为(f_w , f_h),输出的大小为(width+f_w -1 , height +f_h-1)。
可视化表示为:
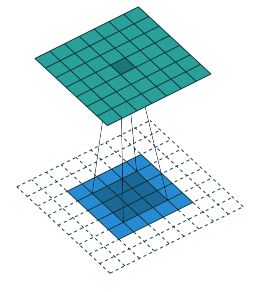
公式为:
具体例子(the mode of padding is “full”):

卷积神经网络中,大部分的框架中的卷积操作都是转化成了矩阵相乘(Matrix mutiplication)的形式。以caffe为例。
the convolution naturally gets reduced to a matrix multiplication[8]
Caffe的作者贾扬青也说明了自己对卷积操作的优化的一个过程[8]。其中一个操作,就是将卷积转化为矩阵相乘的形式,然后通过MKL,blas矩阵库来进行处理。
那卷积操作是怎么转化为Matrix multiolication的形式的呢?
3.1了解Toeplitz matrix(diagonal-constant matrix)
卷积的处理转化为Matrix multi的形式是和一个特殊的矩阵相关系的,这个矩阵就是Toeplitz matrix[7].那这个矩阵特殊在什么方面呢?
我们看wiki关于此的定义:
It is a matrix in which each descending diagonal from left to right is constant(恒量).也就是如果i,j element of A is denoted Aij.那么会有:
对于一个 n∗n 的矩阵:

3.2卷积(discrete)操作与Toeplitz matrix
定义y=h*x是h与x的卷积操作。则,将其中一个输入转化为Toeplitz matrix,另一个为列向量,则有。

所以,我们的卷积操作,就可以转化为,一个Toeplitz matrix与另一个矩阵的乘积。
3.3一维卷积转化矩阵乘积
Python中signal有一维卷积操作,scipy 调用toeplitz()将普通矩阵转化为Toeplitz matrix。细节部分,请看代码实现。
import numpy as np
from scipy import signal
import scipy
import os
import cv2
x = [1 , 8 , 3 , 5 , 2 , 7]
x = np.array(x)
y = [3 , 5 , 2 , 3]
y = np.array(y)
print "conv:\n" , signal.convolve(x , y , 'full')
padding = np.zeros(x.shape[0] - 1 , x.dtype)
padding2 = np.zeros(x.shape[0] - 1, x.dtype)
first_col = np.r_[y[1] , padding2]
first_raw = np.r_[y , padding]
y = scipy.linalg.toeplitz(first_raw , first_col)
print "Matrix multi: \n" , np.dot(y , x)3.4二维卷积转化矩阵乘积
从代码中看,一维卷积转化为矩阵乘积是很相对简单的事情,但是我们考虑的是对二维图像的处理,那么现在就分析二维卷积怎么转化为矩阵的乘积呢?
基本原理介绍:二维卷积转化为矩阵相乘,和一维相似,其中一个输入数据也要转化为Toeplitz matrix,另一个reshape成列向量,然后进行乘积。
但是其中将二维矩阵A(以A为例)转化为Toeplitz matrix不像一维那样直接转化。假如A的行数为a,那么就以每一行作为一个独立的一维矩阵,然后将其转化为Tm矩阵,H1,H2…Ha.然后,这些Tm矩阵,再作为单个元素,再一次组成Tm矩阵,其余补0,最后结果就是我们想要的Tm矩阵[8]。
下面介绍详细的例子。
使用矩阵乘法计算两个矩阵的卷积结果。
![]()
![]()
其中X的m,n对应 M1×N1 .h的m,n对应 M2×N2 The convolution between x[m,n] and h[m,n] is denoted Y[m,n].Y[m,n]的m,n对应 M3×N3 。
有:
其中:
M1 = 2;N1 = 2;M2 =2;N2 = 2;
M3=M1+M2 -1=3(full convolution);N3=N1+N2-1=3.
根据我们的之前的理论分析。
(1)分块转化
先将X根据行数划分为两个矩阵H1=[1,2];H2[3 ,4]
对于H1,将其转化为Tm矩阵,其余的值全部填0。
得到

同理

(2)将H1,H2作为基本元素,组成新的Tm矩阵A(其余补零)。

等价于

A就是我们想要的Toeplitz matrix。
(3)Matrix multiplication
先将h(2,2)转化为列向量。

有:

根据M3=N3=3,则,reshape Y得到最后,根据矩阵相乘的结果为。

可以验证下,是完全正确的. 实例介绍完毕。
3.4转化为矩阵乘积的缺点
虽然有些深度学习框架将卷积转化为矩阵乘积来做,但很明显的就是Toeplitz matrix会需要更大的存储,如果数据量过大的话,这种方式就是不可取的了。
四.卷积的效果以及代码
我们调用python接口,实现图像的一般卷积效果。
import numpy as np
from scipy import signal
import os
import cv2
filename = "/home/jaychao/test.jpg"
x = [[1 , 0 , 0 , 0] , [0 , 1 , 0 , 0] , [0 , 0 , 3 , 0] , [0 , 0 , 0 , 1]]
x = np.array(x)
y = [[4 , 5] , [3 , 4]]
y = np.array(y)
print "conv:" , signal.convolve2d(x , y , 'full')
image = cv2.imread(filename , 1)
cv2.imshow("before" , image)
image = cv2.filter2D(image ,ddepth=-1 , kernel=np.array([[1 , 1] , [1 , 1]]))
cv2.imshow("after" , image)
cv2.waitKey()卷积前:

卷积后

对比上下图,可以看到使用一般filter的卷积的效果。
五.卷积的傅里叶变换(Fourier transforms)实现
通过上文,了解了卷积的一般的实现,和对图片的处理效果,那么有没有其他的方法或者trick来实现卷积呢?
答案就是:傅里叶变换实现卷积操作。
我们之前讨论卷积的概念和操作,都是从空间域上所介绍的。那如何理解空间域呢?空间域图像处理是直接对图像像素操作的过程。当然除此之外,还有频率域图像。
傅里叶变换的基本原理是:非周期的函数(有限曲线)也可以用正弦和或余弦乘以加权函数的积分来表示。对空间域的图像原函数进行傅里叶变换转化为频率域的图像函数,其中傅里叶函数的范围值为频率域。当然也有反傅里叶变换(inverse Fourier transforms)来还原成原函数。我们主要是对图像进行离散的傅里叶变换。
一个图像尺寸为MxN的函数f(x,y)的离散傅里叶变换由以下等式给出:
其中:u=0,1,2….,M-1.v=0,1,2…N-1.u和v是频率变量;x,y是空间变 量。需要注意的是,频率域的值是有实部和虚部组成的。
现在我们理解了傅里叶的原理,那如何在频率域对图像进行处理呢?
在傅里叶变换中,低频部分主要决定图像在平滑区域中的总体灰度级的显示,而高频决定了图像的细节部分,如边缘和噪声。使低频通过而是高频衰减的滤波器的滤波器成为“低通滤波器”,相反,就是“高通滤波器”。使用低通滤波器处理的图像,会比原始图像减少一些尖锐的细节部分。使用高通滤波器处理的图像,会比原始图像会突出边缘灰度级的细节变换,则显得更为锐化。所以,通过不同的滤波,在频率域对图像进行一定的处理,处理完之后在通过反傅里叶变换回到空间域。
现在再来考虑傅里叶来实现卷积操作的问题。根据Convolution theorem[3].有如下等式。
其中: f∗g 表示空间域的convolution ; F−1 表示反傅里叶变换, F :傅里叶变换。
则,空间域的卷积等价于:对图像先进行傅里叶变换,对滤波器也进行傅里叶变换,然后两者进行叉乘,结果经过反傅里叶变换就是我们想要的卷积结果。
完整代码实现。
import sysfrom scipy import signal
from scipy import linalgimport numpy as np
x = [[1 , 0 , 0 , 0] , [0 , -1 , 0 , 0] , [0 , 0 , 3 , 0] , [0 , 0 , 0 , 1]]
x = np.array(x)
y = [[4 , 5] , [3 , 4]]
y = np.array(y)
print "conv:" , signal.convolve2d(x , y , 'full')
s1 = np.array(x.shape)
s2 = np.array(y.shape)
size = s1 + s2 - 1
fsize = 2 ** np.ceil(np.log2(size)).astype(int)
fslice = tuple([slice(0, int(sz)) for sz in size])
new_x = np.fft.fft2(x , fsize)
new_y = np.fft.fft2(y , fsize)
result = np.fft.ifft2(new_x*new_y)[fslice].copy()
print "fft for my method:" , np.array(result.real , np.int32)
print "fft:" , np.array(signal.fftconvolve(x ,y) , np.int32)傅里叶变换来做卷积数值的操作,其中就有fast Fourier transform[4],降级了卷积的计算复杂度。Opencv的卷积操作filter2D()接口在卷积核较大的情况是,就是通过傅里叶变换来实现的(DFT-based algorithm)[5]。
六.反卷积的概念和定义
我们看2010年cvpr[13]对deconvolution 的定义为:
it seeks to generate the input signal by a sum over convolutions of the feature maps (as opposed to the input) with learned filters.
从以下几个方面来介绍反卷积和卷积的共同点和区别。
(1)从概念上来说
从定义上来看,所谓的“反卷积”也是卷积操作。
(2)从数据处理层面
上文介绍的了卷积的矩阵表达公式为:
对于图像的卷积操作,X:input Matrix , Y : filter(convolution kernel).
那么在卷积神经网络中,这个是卷积层基本操作,我们想通过卷积操作,获取输出值,也就是想要的feature map.而对于deconvolution,目的则是相反的——通过输入feature map ,对 feature map 也进行卷积操作,输出value,而输出值则是我们期待得到的图像的原始值。所以,从目的上来讲,我们想通过反卷积还原特征值到原输入。
反卷积公式定义如下:
所以,从实质上来说,所谓的“deconvolution”也还是卷积操作。很多论文也提到了,将该过程称为“deconvolution”是不合适的,应该叫做,transposed convolutional layer,也有叫Backward strided convolution ,upconvoution, upsample convolution。
(3)从公式的角度
从上文了解到卷积一般转化为矩阵的乘积。则有。
那么,反向传播过程中。假如,我们已经有从更深层的网络中得到的,根据矩阵微分公式
![]()
那么有
从中可以看出,在求误差bp的过程,是与A的转置的乘积。
而,反卷积(deconvolution)与卷积的正好相反——前向传播,与A的转置的乘积,反向传播,则是与A的转置[7]。这就是为什么反卷积其实叫transport convolution更为合适的原因了。
(4)可视化的角度
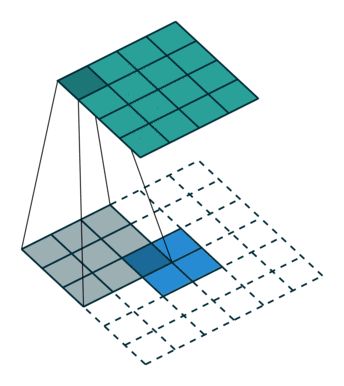
for a transposed convolution with stride one and no padding
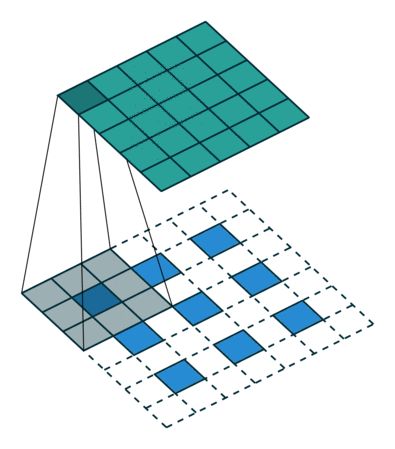
In case of stride two and padding
(5)从功能的角度
我们从[6]已经了解到,反卷积的目的是想要还原源输入,那么一般情况下,反卷积的输出的维度是要大于输入值的(feature map)。这一点,从可视化的角度可以很明显的体会到。
(6)从应用的角度
反卷积的有以下几个重要的应用:
(1)可视化[6][9],通过反卷积,来可视化feature map ,是个重要的应用,我们可以根据可视化的效果,了解我们的卷积到底学到了怎么的特征。
(2)Adversarial networks[10],对抗网络是最近很火的生成模型,也是一个无监督的学习过程,其中的generative model就是使用反卷积的一个neural network,通过反卷积来生成接近自然情况下的图片。关于对抗网络,可以查看我的博客。链接为[11].也可以查看关于对抗网络的开源项目[12]。
引用
[1]冈萨雷斯,数字图像处理(第二版).92页.
[2]冈萨雷斯,数字图像处理(第二版)
[3]https://en.wikipedia.org/wiki/Convolution_theorem#Convolution_theorem_for_inverse_Fourier_transform
[4]https://en.wikipedia.org/wiki/Fast_Fourier_transform
[5]http://docs.opencv.org/2.4/modules/imgproc/doc/filtering.html#cv2.filter2D
[6]https://github.com/Yangqing/caffe/wiki/Convolution-in-Caffe:-a-memo
[7]https://en.wikipedia.org/wiki/Toeplitz_matrix
[8]Digital Image Processing.(作者:Jayaraman;Google book)
[9]Visualizing and Understanding Convolutional Networks.
[10]Unsupervised representation learning with deep convolutional generative convolutional generative adversarial networks.
[11]http://blog.csdn.net/u013139259/article/details/52729191
[12]https://github.com/zhangqianhui/AdversarialNetsPapers
[13]Matthew D.Deconvolutional Networks.CVPR2010
补充
关于conv层参数padding类型的说明。
pad : int, iterable of int, ‘full’, ‘same’ or ‘valid’ (default: 0)
By default, the convolution is only computed where the input and the filter fully overlap (a valid convolution). When stride=1, this yields an output that is smaller than the input by filter_size - 1. The pad argument allows you to implicitly pad the input with zeros, extending the output size.
An integer or a 1-element tuple results in symmetric zero-padding of the given size on both borders.
‘full’ pads with one less than the filter size on both sides. This is equivalent to computing the convolution wherever the input and the filter overlap by at least one position.
‘same’ pads with half the filter size (rounded down) on both sides. When stride=1 this results in an output size equal to the input size. Even filter size is not supported.
‘valid’ is an alias for 0 (no padding / a valid convolution).