《人工智能》机器学习 - 第4章 决策树算法【分类】(二 ID3算法实现)
4.2决策树ID3实践
决策树算法最原始的版本是ID3算法,ID3算法由Ross Quinlan发明,建立在“奥卡姆剃刀”的基础上:越是小型的决策树越优于大的决策树(be simple简单理论)。ID3算法中根据信息增益评估和选择特征,每次选择信息增益最大的特征作为判断模块建立子结点。ID3算法可用于划分标称型数据集,没有剪枝的过程,为了去除过度数据匹配的问题,可通过裁剪合并相邻的无法产生大量信息增益的叶子节点(例如设置信息增益阀值)。使用信息增益的话其实是有一个缺点,那就是它偏向于具有大量值的属性。就是说在训练集中,某个属性所取的不同值的个数越多,那么越有可能拿它来作为分裂属性,而这样做有时候是没有意义的,另外ID3不能处理连续分布的数据特征,于是就有了C4.5算法。CART算法也支持连续分布的数据特征。
前文讲解了决策树的基础知识,决策树的实现主要有三个部分:特征选择、决策树的生成、决策树的修剪。接下来我们结合算法和实例,一步一步编程来实现决策树。
4.2.1决策树简单实例之电脑购买
首先笔者给出样本数据表1,我们通过一个人的年龄、学生与否等特征来判断是否购买电脑,好了,我们结合这个实例,如何使用决策树来判断购买电脑与否。
| RID | age | student | credit_rating | income | class_buys_computer |
| 1 | youth | no | fair | high | no |
| 2 | youth | no | excellent | high | no |
| 3 | middle_aged | no | fair | high | yes |
| 4 | senior | no | fair | medium | yes |
| 5 | senior | yes | fair | low | yes |
| 6 | senior | yes | excellent | low | no |
| 7 | middle_aged | yes | excellent | low | yes |
| 8 | youth | no | fair | medium | no |
| 9 | youth | yes | fair | low | yes |
| 10 | senior | yes | fair | medium | yes |
| 11 | youth | yes | excellent | medium | yes |
| 12 | middle_aged | no | excellent | medium | yes |
| 13 | middle_aged | yes | fair | high | yes |
| 14 | senior | no | excellent | medium | no |
4.2.1.1特征选择
特征选择问题希望选取对训练数据具有良好分类能力的特征,这样可以提高决策树学习的效率。如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。为了解决特征选择问题,找出最优特征,先要介绍一些信息论里面的概念。
**1.熵(entropy) **
熵是表示随机变量不确定性的度量。设X是一个取有限个值的离散随机变量,其概率分布为:
P ( X = x i = p i , i = 1 , 2... , n \color{red}P(X=x_i=p_i ,i=1,2...,n P(X=xi=pi,i=1,2...,n
则随机变量的熵定义为:
H ( X ) = − ∑ i = 1 n p i l o g p i \color{red}H(X)=-\sum_{i=1}^{n}p_ilogp_i H(X)=−∑i=1npilogpi
其中 n n n代表 X X X的 n n n种不同的离散取值。而 p i p_i pi代表了 X X X取值为 i i i的概率, l o g log log为以 2 2 2或者 e e e为底的对数。当对数的底为 2 2 2时,熵的单位为bit;为 e e e时,单位为nat。
熵越大,随机变量的不确定性就越大。从定义可验证:
0 < H ( p ) < l o g n \color{red}0<H(p)<logn 0<H(p)<logn
这些都是前文已经讲解过了,笔者在此放到这里,是为了行文的需要。好了,我们来计算熵。当然了,这数据量比较少,对概率分布可以很容易计算出来,但是编程就不会这样简单了,具体过程请看下文的代码,下面是根据概率计算熵。
![]()
因此,熵为0.94.接下来我们就通过python来实现。
我们先对数据集进行属性标注。
年龄:0代表青年,1代表中年,2代表老年;
有学生:0代表否,1代表是;
信誉等级:0代表不好,1代表良好;
收入情况:0代表一般,1代表好,2代表非常好;
类别(是否购买电脑):no代表否,yes代表是。
确定这些之后,那么使用python怎实现呢?代码如下,注释很清楚了,笔者就不在一一解释了。
# -*- coding: UTF-8 -*-
from math import log
"""
函数说明:创建测试数据集
Parameters:
无
Returns:
dataSet - 数据集
labels - 特征标签
"""
def createDataSet():
#数据集
dataSet = [[0, 0, 0, 2, 'no'],
[0, 0, 1, 2, 'no'],
[1, 0, 0, 2, 'yes'],
[2, 0, 0, 1, 'yes'],
[2, 1, 0, 0, 'yes'],
[2, 1, 1, 0, 'no'],
[1, 1, 1, 0, 'yes'],
[0, 0, 0, 1, 'no'],
[0, 1, 0, 0, 'yes'],
[2, 1, 0, 1, 'yes'],
[0, 1, 1, 1, 'yes'],
[1, 0, 1, 1, 'yes'],
[1, 1, 0, 2, 'yes'],
[2, 0, 2, 2, 'no']]
#特征标签
labels = ['age', 'student', 'credit_rating', 'income']
#返回数据集和分类属性
return dataSet, labels
"""
函数说明:计算给定数据集的经验熵(香农熵)
Parameters:
dataSet - 数据集
Returns:
shannonEnt - 经验熵(香农熵)
"""
def calcShannonEnt(dataSet):
#返回数据集的行数
numEntires = len(dataSet)
#保存每个标签(Label)出现次数的字典
labelCounts = {}
#对每组特征向量进行统计
for featVec in dataSet:
#提取标签(Label)信息
currentLabel = featVec[-1]
#如果标签(Label)没有放入统计次数的字典,添加进去
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 #Label计数
shannonEnt = 0.0 #经验熵(香农熵)
#计算香农熵
for key in labelCounts:
#选择该标签(Label)的概率
prob = float(labelCounts[key]) / numEntires
#利用公式计算
shannonEnt -= prob * log(prob, 2)
#返回经验熵(香农熵)
return shannonEnt
#测试
if __name__ == '__main__':
dataSet, features = createDataSet()
print(dataSet)
print(calcShannonEnt(dataSet))
结果如下所示。

可以看到,和前文手工计算的是一致的。
**2.条件熵(conditional entropy) **
设有随机变量 ( X , Y ) (X,Y) (X,Y),其联合概率分布为
P ( X = x i , Y = y j ) = p i j , i = 1 , 2 , . . . , n ; j = 1 , 2 , . . . , m \color{red}P(X=x_i,Y=y_j)=p_{ij},i=1,2,...,n;j=1,2,...,m P(X=xi,Y=yj)=pij,i=1,2,...,n;j=1,2,...,m
条件熵 H ( Y ∣ X ) H(Y|X) H(Y∣X)表示在已知随机变量 X X X的条件下随机变量 Y Y Y的不确定性。随机变量 X X X给定的条件下随机变量 Y Y Y的条件熵 H ( Y ∣ X ) H(Y|X) H(Y∣X),定义为 X X X给定条件下 Y Y Y的条件概率分布的熵对 X X X的数学期望。
H ( Y ∣ X ) = ∑ I = 1 n p i H ( Y ∣ X = x i ) \color{red}H(Y|X)=\sum_{I=1}^np_iH(Y|X=x_i) H(Y∣X)=∑I=1npiH(Y∣X=xi)
以年龄为例,计算得到的条件熵如下。

Python代码如下所示。
# -*- coding: utf-8 -*-
from math import log
import operator
"""
函数说明:创建测试数据集
Parameters:
无
Returns:
dataSet - 数据集
labels - 特征标签
"""
def createDataSet():
#数据集
dataSet = [[0, 0, 0, 2, 'no'],
[0, 0, 1, 2, 'no'],
[1, 0, 0, 2, 'yes'],
[2, 0, 0, 1, 'yes'],
[2, 1, 0, 0, 'yes'],
[2, 1, 1, 0, 'no'],
[1, 1, 1, 0, 'yes'],
[0, 0, 0, 1, 'no'],
[0, 1, 0, 0, 'yes'],
[2, 1, 0, 1, 'yes'],
[0, 1, 1, 1, 'yes'],
[1, 0, 1, 1, 'yes'],
[1, 1, 0, 2, 'yes'],
[2, 0, 2, 2, 'no']]
#特征标签
labels = ['age', 'student', 'credit_rating', 'income']
#返回数据集和分类属性
return dataSet, labels
"""
函数说明:按照给定特征划分数据集
Parameters:
dataSet - 待划分的数据集
axis - 划分数据集的特征
value - 需要返回的特征的值
Returns:
无
"""
def splitDataSet(dataSet, axis, value):
#创建返回的数据集列表
retDataSet = []
#遍历数据集
for featVec in dataSet:
if featVec[axis] == value:
#去掉axis特征
reducedFeatVec = featVec[:axis]
#将符合条件的添加到返回的数据集
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
#返回划分后的数据集
return retDataSet
"""
函数说明:计算X_i给定的条件下,Y的条件熵
Parameters:
dataSet - 待划分的数据集
i - 维度i
uniqueVals - 数据集特征集合
Returns:
newEntropy - 条件熵
"""
def calcConditionalEntropy(dataSet, i, uniqueVals):
#经验条件熵
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet)) # 极大似然估计概率
newEntropy += prob * calcShannonEnt(subDataSet) # 条件熵的计算
return newEntropy
#测试
if __name__ == '__main__':
dataSet, labels = createDataSet()
#特征数量
numFeatures = len(dataSet[0]) - 1
#遍历所有特征
for i in range(numFeatures):
#获取dataSet的第i个所有特征
featList = [example[i] for example in dataSet]
#创建set集合{},元素不可重复
uniqueVals = set(featList)
#经验条件熵
newEntropy = 0.0
newEntropy = calcConditionalEntropy(dataSet, i, uniqueVals)
print(newEntropy)
结果如下所示。

可以看出,第一个就是年龄特征的条件熵,还是和手工计算的一样。
3.信息增益(information gain)
信息增益表示得知特征 X X X的信息而使得类 Y Y Y的信息的不确定性减少的程度。特征 A A A对训练数据集 D D D的信息增益 g ( D , A ) g(D,A) g(D,A),定义为集合 D D D的经验熵 H ( D ) H(D) H(D)与特征 A A A给定条件下 D D D的经验条件熵 H ( D ∣ A ) H(D|A) H(D∣A)之差,即
g ( D , A ) = H ( D ) − H ( D ∣ A ) \color{red}g(D,A)=H(D)-H(D|A) g(D,A)=H(D)−H(D∣A)
这个差又称为互信息。信息增益大的特征具有更强的分类能力。
根据信息增益准则的特征选择方法是:对训练数据集(或子集)计算其每个特征的信息增益,选择信息增益最大的特征。
还是结合实例来讲解。年龄的增益如下。
![]()
类似,Gain(income) = 0.029, Gain(student) = 0.151, Gain(credit_rating)=0.048
所以,选择age作为第一个根节点

Python代码如下所示。
# -*- coding: utf-8 -*-
from math import log
import operator
"""
函数说明:创建测试数据集
Parameters:
无
Returns:
dataSet - 数据集
labels - 特征标签
"""
def createDataSet():
#数据集
dataSet = [[0, 0, 0, 2, 'no'],
[0, 0, 1, 2, 'no'],
[1, 0, 0, 2, 'yes'],
[2, 0, 0, 1, 'yes'],
[2, 1, 0, 0, 'yes'],
[2, 1, 1, 0, 'no'],
[1, 1, 1, 0, 'yes'],
[0, 0, 0, 1, 'no'],
[0, 1, 0, 0, 'yes'],
[2, 1, 0, 1, 'yes'],
[0, 1, 1, 1, 'yes'],
[1, 0, 1, 1, 'yes'],
[1, 1, 0, 2, 'yes'],
[2, 0, 2, 2, 'no']]
#特征标签
labels = ['age', 'student', 'credit_rating', 'income']
#返回数据集和分类属性
return dataSet, labels
"""
函数说明:计算给定数据集的经验熵(香农熵)
Parameters:
dataSet - 数据集
Returns:
shannonEnt - 经验熵(香农熵)
"""
def calcShannonEnt(dataSet):
#返回数据集的行数
numEntires = len(dataSet)
#保存每个标签(Label)出现次数的字典
labelCounts = {}
#对每组特征向量进行统计
for featVec in dataSet:
#提取标签(Label)信息
currentLabel = featVec[-1]
#如果标签(Label)没有放入统计次数的字典,添加进去
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 #Label计数
shannonEnt = 0.0 #经验熵(香农熵)
#计算香农熵
for key in labelCounts:
#选择该标签(Label)的概率
prob = float(labelCounts[key]) / numEntires
#利用公式计算
shannonEnt -= prob * log(prob, 2)
#返回经验熵(香农熵)
return shannonEnt
"""
函数说明:按照给定特征划分数据集
Parameters:
dataSet - 待划分的数据集
axis - 划分数据集的特征
value - 需要返回的特征的值
Returns:
无
"""
def splitDataSet(dataSet, axis, value):
#创建返回的数据集列表
retDataSet = []
#遍历数据集
for featVec in dataSet:
if featVec[axis] == value:
#去掉axis特征
reducedFeatVec = featVec[:axis]
#将符合条件的添加到返回的数据集
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
#返回划分后的数据集
return retDataSet
"""
函数说明:计算X_i给定的条件下,Y的条件熵
Parameters:
dataSet - 待划分的数据集
i - 维度i
uniqueVals - 数据集特征集合
Returns:
newEntropy - 条件熵
"""
def calcConditionalEntropy(dataSet, i, uniqueVals):
#经验条件熵
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet)) # 极大似然估计概率
newEntropy += prob * calcShannonEnt(subDataSet) # 条件熵的计算
return newEntropy
"""
函数说明:计算信息增益
Parameters:
dataSet - 数据集
baseEntropy - 数据集的信息熵
Returns:
bestIndex - 最好的特征索引
bestInfoGain - 最好的信息增益
"""
def calcInformationGain(dataSet, baseEntropy):
#最优特征的索引值
bestIndex = -1
#信息增益
bestInfoGain = 0.0
#特征数量
numFeatures = len(dataSet[0]) - 1
#遍历所有特征
for i in range(numFeatures):
#获取dataSet的第i个所有特征
featList = [example[i] for example in dataSet]
#创建set集合{},元素不可重复
uniqueVals = set(featList)
#经验条件熵
newEntropy = 0.0
#计算条件熵
newEntropy = calcConditionalEntropy(dataSet, i, uniqueVals)
#得到增益
infoGain = baseEntropy - newEntropy # 信息增益,就yes熵的减少,也就yes不确定性的减少
if (infoGain > bestInfoGain): #计算信息增益
#更新信息增益,找到最大的信息增益
bestInfoGain = infoGain
#记录信息增益最大的特征的索引值
bestIndex = i
return bestIndex, bestInfoGain
#测试
if __name__ == '__main__':
dataSet, labels = createDataSet()
ent = calcShannonEnt(dataSet)
index,gain = calcInformationGain(dataSet, ent)
print(gain)
结果如下所示。
![]()
结果和我们计算的一样。说明我们的代码是没有问题的。
好了,下面总结下计算信息增益的算法。
算法(计算信息增益)
输入:训练数据集 D D D和特征 A A A;
输出*:特征 A A A对训练数据集 D D D的信息增益 g ( D , A ) g(D,A) g(D,A)。
- Step1: 计算数据集 D D D的经验熵 H ( D ) H(D) H(D)

- Step2: 计算特征 A A A对数据集 D D D的经验条件熵 H ( D ∣ A ) H(D|A) H(D∣A)

- Step3: 计算信息增益

【注】以信息增益作为划分训练数据集的特征的算法称为ID3算法。
4.信息增益比(information gain ratio)
特征 A A A对训练数据集 D D D的信息增益比 g R ( D , A ) g_R(D,A) gR(D,A)定义为其信息增益 g ( D , A ) g(D,A) g(D,A)与训练数据集 D D D关于特征 A A A的值的熵 H A ( D ) H_A(D) HA(D)之比,即

其中, n n n是特征 A A A取值的个数。
用信息增益比来选择特征的算法称为C4.5算法。关于C4.5后文会介绍。
4.2.1.2 ID3算法的具体过程
我们已经学习了从数据集构造决策树算法所需要的子功能模块,包括经验熵的计算和最优特征的选择,其工作原理如下:得到原始数据集,然后基于最好的属性值划分数据集,由于特征值可能多于两个,因此可能存在大于两个分支的数据集划分。第一次划分之后,数据集被向下传递到树的分支的下一个结点。在这个结点上,我们可以再次划分数据。因此我们可以采用递归的原则处理数据集。
构建决策树的算法有很多,比如C4.5、ID3和CART,这些算法在运行时并不总是在每次划分数据分组时都会消耗特征。由于特征数目并不是每次划分数据分组时都减少,因此这些算法在实际使用时可能引起一定的问题。目前我们并不需要考虑这个问题,只需要在算法开始运行前计算列的数目,查看算法是否使用了所有属性即可。
决策树生成算法递归地产生决策树,直到不能继续下去未为止。这样产生的树往往对训练数据的分类很准确,但对未知的测试数据的分类却没有那么准确,即出现过拟合现象。过拟合的原因在于学习时过多地考虑如何提高对训练数据的正确分类,从而构建出过于复杂的决策树。解决这个问题的办法是考虑决策树的复杂度,对已生成的决策树进行简化。
ID3算法的核心是在决策树各个结点上对应信息增益准则选择特征,递归地构建决策树。具体方法是 :从根结点(root node)开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子节点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止,最后得到一个决策树。ID3相当于用极大似然法进行概率模型的选择。
算法(ID3算法)
输入:训练数据集 D D D,特征集 A A A,阈值 ϵ ϵ ϵ;
输出:决策树 T T T;
- step.1初始化信息增益的阈值 ϵ ϵ ϵ
- step.2判断样本 D D D是否为同一类输出 C k C_k Ck,若 T T T为单节点树 T T T,则将类 C k C_k Ck作为该节点的类标记,返回 T T T;
- step.3判断特征集 A A A是否为空,如果是空则返回单节点树 T T T,标记类别为样本中输出类别 C k C_k Ck实例数最多的类别返回 T T T;
- step.4计算 A A A中的各个特征(一共 n n n个)对输出 D D D的信息增益,选择信息增益最大的特征 A g A_g Ag ;
- step.5如果 A g A_g Ag的信息增益小于阈值 ϵ ϵ ϵ,则返回单节点树 T T T,标记类别为样本中输出类别 D D D实例数最多的类别 C k C_k Ck,返回 T T T。
- step.6否则,按特征 A g A_g Ag的不同取值 a i a_i ai将对应的样本输出 D D D分成若干个非空子集 D i D_i Di,将 D i D_i Di中实例数的做大的类作为标记,构建子节点,由节点及其子节点构成数 T T T,返回 T T T。
- step.7对第 i i i个子节点,以 D I D_I DI 为训练集,以 A − A- A−{ A g A_g Ag}为特征集,递归地调用步(2)~步(6),得到子树 T i T_i Ti,返回 T i T_i Ti。
根据前文的计算,选择信息增益最大的特征“年龄”作为结点的特征。由于“年龄”有三个可能取值,从这一结点引出三个子结点:一个对应“青年”的子结点,包含5个样本,它们属于同一类,所以这是一个叶结点;另一个是对应“中年”的子结点,包含4个样本,它们也属于同一类,所以这也是一个叶结点;还有一个节点就是“老年”。
好了,来看代码吧。
# -*- coding: utf-8 -*-
from math import log
import operator
"""
函数说明:创建测试数据集
Parameters:
无
Returns:
dataSet - 数据集
labels - 特征标签
"""
def createDataSet():
#数据集
dataSet = [[0, 0, 0, 2, 'no'],
[0, 0, 1, 2, 'no'],
[1, 0, 0, 2, 'yes'],
[2, 0, 0, 1, 'yes'],
[2, 1, 0, 0, 'yes'],
[2, 1, 1, 0, 'no'],
[1, 1, 1, 0, 'yes'],
[0, 0, 0, 1, 'no'],
[0, 1, 0, 0, 'yes'],
[2, 1, 0, 1, 'yes'],
[0, 1, 1, 1, 'yes'],
[1, 0, 1, 1, 'yes'],
[1, 1, 0, 2, 'yes'],
[2, 0, 2, 2, 'no']]
#特征标签
labels = ['age', 'student', 'credit_rating', 'income']
#返回数据集和分类属性
return dataSet, labels
"""
函数说明:计算给定数据集的经验熵(香农熵)
Parameters:
dataSet - 数据集
Returns:
shannonEnt - 经验熵(香农熵)
"""
def calcShannonEnt(dataSet):
#返回数据集的行数
numEntires = len(dataSet)
#保存每个标签(Label)出现次数的字典
labelCounts = {}
#对每组特征向量进行统计
for featVec in dataSet:
#提取标签(Label)信息
currentLabel = featVec[-1]
#如果标签(Label)没有放入统计次数的字典,添加进去
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 #Label计数
shannonEnt = 0.0 #经验熵(香农熵)
#计算香农熵
for key in labelCounts:
#选择该标签(Label)的概率
prob = float(labelCounts[key]) / numEntires
#利用公式计算
shannonEnt -= prob * log(prob, 2)
#返回经验熵(香农熵)
return shannonEnt
"""
函数说明:按照给定特征划分数据集
Parameters:
dataSet - 待划分的数据集
axis - 划分数据集的特征
value - 需要返回的特征的值
Returns:
无
"""
def splitDataSet(dataSet, axis, value):
#创建返回的数据集列表
retDataSet = []
#遍历数据集
for featVec in dataSet:
if featVec[axis] == value:
#去掉axis特征
reducedFeatVec = featVec[:axis]
#将符合条件的添加到返回的数据集
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
#返回划分后的数据集
return retDataSet
"""
函数说明:计算X_i给定的条件下,Y的条件熵
Parameters:
dataSet - 数据集
i - 维度i
uniqueVals - 数据集特征集合
Returns:
newEntropy - 条件熵
"""
def calcConditionalEntropy(dataSet, i, uniqueVals):
#经验条件熵
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet)) # 极大似然估计概率
newEntropy += prob * calcShannonEnt(subDataSet) # 条件熵的计算
return newEntropy
"""
函数说明:计算信息增益
Parameters:
dataSet - 数据集
baseEntropy - 数据集的信息熵
Returns:
bestIndex - 最好的特征索引
bestInfoGain - 最好的信息增益
"""
def calcInformationGain(dataSet):
#最优特征的索引值
bestIndex = -1
#信息增益
bestInfoGain = 0.0
baseEntropy = calcShannonEnt(dataSet)
#特征数量
numFeatures = len(dataSet[0]) - 1
#遍历所有特征
for i in range(numFeatures):
#获取dataSet的第i个所有特征
featList = [example[i] for example in dataSet]
#创建set集合{},元素不可重复
uniqueVals = set(featList)
#经验条件熵
newEntropy = 0.0
#计算条件熵
newEntropy = calcConditionalEntropy(dataSet, i, uniqueVals)
#得到增益
infoGain = baseEntropy - newEntropy # 信息增益,就yes熵的减少,也就yes不确定性的减少
#最优增益选择
if (infoGain > bestInfoGain):
#更新信息增益,找到最大的信息增益
bestInfoGain = infoGain
#记录信息增益最大的特征的索引值
bestIndex = i
return bestIndex, bestInfoGain
"""
函数说明:统计classList中出现此处最多的元素(类标签)
Parameters:
classList - 类标签列表
Returns:
sortedClassCount[0][0] - 出现此处最多的元素(类标签)
"""
def majorityCnt(classList):
classCount = {}
for vote in classList:
#统计classList中每个元素出现的次数
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True) #根据字典的值降序排序
#返回classList中出现次数最多的元素
return sortedClassCount[0][0]
"""
函数说明:创建决策树
Parameters:
dataSet - 训练数据集
labels - 分类属性标签
featLabels - 存储选择的最优特征标签
Returns:
myTree - 决策树
"""
def createTree(dataSet, labels, featLabels):
#取分类标签(是否放贷:yes or no)
classList = [example[-1] for example in dataSet]
#如果类别完全相同则停止继续划分
if classList.count(classList[0]) == len(classList):
return classList[0]
#遍历完所有特征时返回出现次数最多的类标签
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat, bestInfoGain= calcInformationGain(dataSet) #选择最优特征
bestFeatLabel = labels[bestFeat]#最优特征的标签
featLabels.append(bestFeatLabel)
myTree = {bestFeatLabel:{}} #根据最优特征的标签生成树
del(labels[bestFeat]) #删除已经使用特征标签
#得到训练集中所有最优特征的属性值
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues) #去掉重复的属性值
for value in uniqueVals: #遍历特征,创建决策树。
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), labels, featLabels)
return myTree
#测试
if __name__ == '__main__':
dataSet, labels = createDataSet()
featLabels = []
myTree = createTree(dataSet, labels, featLabels)
print(myTree)
结果如下。
![]()
决策树是出来了,那这也太抽象了,到底怎么分类的呢?好了,直接看代码吧。
"""
函数说明:使用决策树分类
Parameters:
inputTree - 已经生成的决策树
featLabels - 存储选择的最优特征标签
testVec - 测试数据列表,顺序对应最优特征标签
Returns:
classLabel - 分类结果
"""
def classify(inputTree, featLabels, testVec):
firstStr = next(iter(inputTree)) #获取决策树结点
secondDict = inputTree[firstStr] #下一个字典
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__ == 'dict':
classLabel = classify(secondDict[key], featLabels, testVec)
else:
classLabel = secondDict[key]
return classLabel
结果如下。

从实例可以判断是青年人,会购买,通过算法也表明要购买电脑。
【完整代码参考附件.\1.DT_buys_computer_Classifty\DT_buys_computer_Classifty_v1
\DT_buys_computer_Classifty_v1.0\ DT_buys_computer_Classifty_v1.0.py】
4.2.1.3决策树简单实例之电脑购买-调用sklearn库
前面几章都使用了sklearn来实现算法,这一章也不例外。直接看代码吧。
# -*- coding: utf-8 -*-
from sklearn import tree
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import preprocessing
#测试
if __name__ == '__main__':
## Step 1: load data
print("Step 1: load data...")
# Read in the csv file and put features into list of dict and list of class label
Data = open("C:/TensorFlow/data.csv", "rt")
#读取文件的原始数据
reader = csv.reader(Data)#返回的值是csv文件中每行的列表,将每行读取的值作为列表返回
#3.x版本使用该语法,2.7版本则使用headers=reader.next()
headers = next(reader)#读取行的文件对象,reader指向下一行
#headers存放的是csv的第一行元素,也是后文rowDict的键值
#print("headers :\n" + str(headers))
featureList = []
labelList = []
for row in reader:
labelList.append(row[len(row)-1])
rowDict = {}
for i in range(1, len(row)-1):
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
#print("featureList:\n" + str(featureList))
#print("labelList:\n" + str(labelList))
## Step 2: Vetorize data...
print("Step 2: Vetorize data...")
#提取数据
# Vetorize features
vec = DictVectorizer()#初始化字典特征抽取器
dummyX = vec.fit_transform(featureList).toarray()
# 查看提取后的特征值
#输出转化后的特征矩阵
#print("dummyX: \n" + str(dummyX))
#输出各个维度的特征含义
#print(vec.get_feature_names())
# vectorize class labels
lb = preprocessing.LabelBinarizer()# 将标签矩阵二值化
dummyY = lb.fit_transform(labelList)
#print("dummyY: \n" + str(dummyY))
## Step 3: init DT...
print("Step 3: init DT...")
# Using decision tree for classification
# http://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html#sklearn.tree.DecisionTreeClassifier
## criterion可选‘gini’, ‘entropy’,默认为gini(对应CART算法),entropy为信息增益(对应ID3算法)
clf = tree.DecisionTreeClassifier(criterion='entropy')
## Step 4: training...
print("Step 4: training...")
clf = clf.fit(dummyX, dummyY)
#预测数据
oneRowX = dummyX[0, :]
#print("oneRowX: " + str(oneRowX))
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX: " + str(newRowX))
## Step 5: testing
print("Step 5: testing...")
#predictedY = clf.predict([newRowX])#方法一
predictedLabel = clf.predict(newRowX.reshape(1,-1))#方法二
## Step 6: show the result
print("Step 4: show the result...")
#print("predictedLabel" + str(predictedLabel))
if predictedLabel == 1:
print("要购买")
else:
print("不购买")
结果运行如下所示。

【完整代码参考附件1.DT_buys_computer_Classifty\DT_buys_computer_Classifty-sklearn_v2.0\DT_buys_computer_Classifty-sklearn_v2.0.0\ DT_buys_computer_Classifty-sklearn_v2.0.0.py】
4.2.1.4决策树的可视化
4.2.1.4.1决策树的可视化
决策树可视化需要Matplotlib,Matplotlib主要是用于可视化编程的API,在本章中可视化需要用到的函数如下:
getNumLeafs:获取决策树叶子结点的数目
getTreeDepth:获取决策树的层数
plotNode:绘制结点
plotMidText:标注有向边属性值
plotTree:绘制决策树
createPlot:创建绘制面板
Python实现如下。
# -*- coding: utf-8 -*-
import pandas as pd
from math import log
import operator
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
"""
函数说明:计算给定数据集的经验熵(香农熵)
Parameters:
dataSet - 数据集
Returns:
shannonEnt - 经验熵(香农熵)
"""
def calcShannonEnt(dataSet):
#返回数据集的行数
numEntires = len(dataSet)
#保存每个标签(Label)出现次数的字典
labelCounts = {}
#对每组特征向量进行统计
for featVec in dataSet:
#提取标签(Label)信息
currentLabel = featVec[-1]
#如果标签(Label)没有放入统计次数的字典,添加进去
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 #Label计数
shannonEnt = 0.0 #经验熵(香农熵)
#计算香农熵
for key in labelCounts:
#选择该标签(Label)的概率
prob = float(labelCounts[key]) / numEntires
#利用公式计算
shannonEnt -= prob * log(prob, 2)
#返回经验熵(香农熵)
return shannonEnt
"""
函数说明:按照给定特征划分数据集
Parameters:
dataSet - 待划分的数据集
axis - 划分数据集的特征
value - 需要返回的特征的值
Returns:
无
"""
def splitDataSet(dataSet, axis, value):
#创建返回的数据集列表
retDataSet = []
#遍历数据集
for featVec in dataSet:
if featVec[axis] == value:
#去掉axis特征
reducedFeatVec = featVec[:axis]
#将符合条件的添加到返回的数据集
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
#返回划分后的数据集
return retDataSet
"""
函数说明:计算X_i给定的条件下,Y的条件熵
Parameters:
dataSet - 数据集
i - 维度i
uniqueVals - 数据集特征集合
Returns:
newEntropy - 条件熵
"""
def calcConditionalEntropy(dataSet, i, uniqueVals):
#经验条件熵
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet)) # 极大似然估计概率
newEntropy += prob * calcShannonEnt(subDataSet) # 条件熵的计算
return newEntropy
"""
函数说明:计算信息增益
Parameters:
dataSet - 数据集
baseEntropy - 数据集的信息熵
Returns:
bestIndex - 最好的特征索引
bestInfoGain - 最好的信息增益
"""
def calcInformationGain(dataSet):
#最优特征的索引值
bestIndex = -1
#信息增益
bestInfoGain = 0.0
baseEntropy = calcShannonEnt(dataSet)
#特征数量
numFeatures = len(dataSet[0]) - 1
#遍历所有特征
for i in range(numFeatures):
#获取dataSet的第i个所有特征
featList = [example[i] for example in dataSet]
#创建set集合{},元素不可重复
uniqueVals = set(featList)
#经验条件熵
newEntropy = 0.0
#计算条件熵
newEntropy = calcConditionalEntropy(dataSet, i, uniqueVals)
#得到增益
infoGain = baseEntropy - newEntropy # 信息增益,就yes熵的减少,也就yes不确定性的减少
#最优增益选择
if (infoGain > bestInfoGain):
#更新信息增益,找到最大的信息增益
bestInfoGain = infoGain
#记录信息增益最大的特征的索引值
bestIndex = i
return bestIndex, bestInfoGain
"""
函数说明:统计classList中出现此处最多的元素(类标签)
Parameters:
classList - 类标签列表
Returns:
sortedClassCount[0][0] - 出现此处最多的元素(类标签)
"""
def majorityCnt(classList):
classCount = {}
for vote in classList:
#统计classList中每个元素出现的次数
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True) #根据字典的值降序排序
#返回classList中出现次数最多的元素
return sortedClassCount[0][0]
"""
函数说明:创建决策树
Parameters:
dataSet - 训练数据集
labels - 分类属性标签
featLabels - 存储选择的最优特征标签
Returns:
myTree - 决策树
"""
def createTree(dataSet, labels, featLabels):
#取分类标签(是否放贷:yes or no)
classList = [example[-1] for example in dataSet]
#如果类别完全相同则停止继续划分
if classList.count(classList[0]) == len(classList):
return classList[0]
#遍历完所有特征时返回出现次数最多的类标签
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat, bestInfoGain= calcInformationGain(dataSet) #选择最优特征
bestFeatLabel = labels[bestFeat]#最优特征的标签
featLabels.append(bestFeatLabel)
myTree = {bestFeatLabel:{}} #根据最优特征的标签生成树
del(labels[bestFeat]) #删除已经使用特征标签
#得到训练集中所有最优特征的属性值
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues) #去掉重复的属性值
for value in uniqueVals: #遍历特征,创建决策树。
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), labels, featLabels)
return myTree
"""
函数说明:使用决策树分类
Parameters:
inputTree - 已经生成的决策树
featLabels - 存储选择的最优特征标签
testVec - 测试数据列表,顺序对应最优特征标签
Returns:
classLabel - 分类结果
"""
def classify(inputTree, featLabels, testVec):
firstStr = next(iter(inputTree)) #获取决策树结点
secondDict = inputTree[firstStr] #下一个字典
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__ == 'dict':
classLabel = classify(secondDict[key], featLabels, testVec)
else:
classLabel = secondDict[key]
return classLabel
#############################可视化##############################
"""
函数说明:获取决策树叶子结点的数目
Parameters:
myTree - 决策树
Returns:
numLeafs - 决策树的叶子结点的数目
"""
def getNumLeafs(myTree):
#初始化叶子
numLeafs = 0
#python3中myTree.keys()返回的是dict_keys,
#不在是list,所以不能使用myTree.keys()[0]的方法获取结点属性,
#可以使用list(myTree.keys())[0]
firstStr = next(iter(myTree))
#获取下一组字典
secondDict = myTree[firstStr]
for key in secondDict.keys():
#测试该结点是否为字典,如果不是字典,代表此结点为叶子结点
if type(secondDict[key]).__name__=='dict':
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs
"""
函数说明:获取决策树的层数
Parameters:
myTree - 决策树
Returns:
maxDepth - 决策树的层数
"""
def getTreeDepth(myTree):
#初始化决策树深度
maxDepth = 0
#python3中myTree.keys()返回的是dict_keys,
#不在是list,所以不能使用myTree.keys()[0]的方法获取结点属性,
#可以使用list(myTree.keys())[0]
firstStr = next(iter(myTree))
#获取下一个字典
secondDict = myTree[firstStr]
for key in secondDict.keys():
#测试该结点是否为字典,如果不是字典,代表此结点为叶子结点
if type(secondDict[key]).__name__=='dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth #更新层数
return maxDepth
"""
函数说明:绘制结点
Parameters:
nodeTxt - 结点名
centerPt - 文本位置
parentPt - 标注的箭头位置
nodeType - 结点格式
Returns:
无
"""
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
arrow_args = dict(arrowstyle="<-") #定义箭头格式
font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14) #设置中文字体
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction', #绘制结点
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args, FontProperties=font)
"""
函数说明:标注有向边属性值
Parameters:
cntrPt、parentPt - 用于计算标注位置
txtString - 标注的内容
Returns:
无
"""
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0] #计算标注位置
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
"""
函数说明:绘制决策树
Parameters:
myTree - 决策树(字典)
parentPt - 标注的内容
nodeTxt - 结点名
Returns:
无
"""
def plotTree(myTree, parentPt, nodeTxt):
#设置结点格式
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
#设置叶结点格式
leafNode = dict(boxstyle="round4", fc="0.8")
#获取决策树叶结点数目,决定了树的宽度
numLeafs = getNumLeafs(myTree)
depth = getTreeDepth(myTree) #获取决策树层数
firstStr = next(iter(myTree)) #下个字典
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff) #中心位置
plotMidText(cntrPt, parentPt, nodeTxt) #标注有向边属性值
plotNode(firstStr, cntrPt, parentPt, decisionNode) #绘制结点
secondDict = myTree[firstStr] #下一个字典,也就是继续绘制子结点
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD #y偏移
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict': #测试该结点是否为字典,如果不是字典,代表此结点为叶子结点
plotTree(secondDict[key],cntrPt,str(key)) #不是叶结点,递归调用继续绘制
else: #如果是叶结点,绘制叶结点,并标注有向边属性值
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
"""
函数说明:创建绘制面板
Parameters:
inTree - 决策树(字典)
Returns:
无
"""
def createPlot(inTree):
fig = plt.figure(1, facecolor='white') #创建fig
fig.clf() #清空fig
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #去掉x、y轴
#获取决策树叶结点数目
plotTree.totalW = float(getNumLeafs(inTree))
#获取决策树层数
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0; #x偏移
plotTree(inTree, (0.5,1.0), '') #绘制决策树
plt.show()
#测试
if __name__ == '__main__':
## Step 1: load data
print("Step 1: load data...")
df=pd.read_csv('data.csv')
data=df.values[:-1,1:].tolist()
dataSet=data[:]
label=df.columns.values[1:-1].tolist()
labels=label[:]
#print(dataSet)
#print(labels)
## Step 2: training...
print("Step 2: training...")
featLabels = []
myTree = createTree(dataSet, labels, featLabels)
#print(myTree)
## Step 3: show pic
print("Step 3: show the picture...")
createPlot(myTree)
## Step 4: testing
print("Step 4: testing...")
#测试数据
testVec = ['middle_aged', 'yes', 'excellent', 'low']
print("测试实例:"+ str(testVec))
result = classify(myTree, featLabels, testVec)
## Step 5: show the result
print("Step 5: show the result...")
print("result:"+ str(result))
if result == 'yes':
print("要购买")
else:
print("不购买")
结果如下所示。
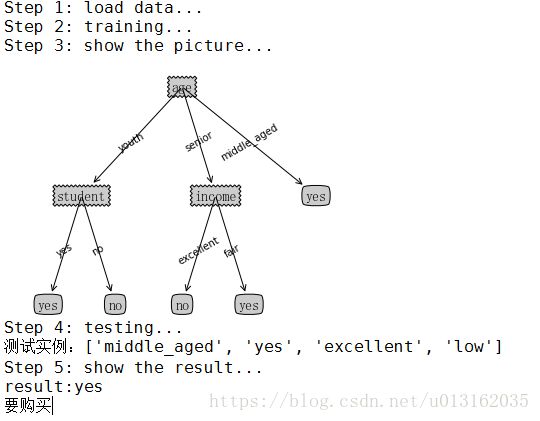
可以看到决策树绘制完成,从图中很清楚的看到中年人会购买电脑。
【完整代码参考附件1.DT_buys_computer_Classifty\DT_buys_computer_Classifty_v1
\DT_buys_computer_Classifty_v1.2\DT_buys_computer_Classifty_v1.2.py】
上面是使用Matplotlib来画决策树,代码比较多,那么有没有简单点的呢?答案是一定的,Graphviz提供了可视化的方法,下面笔者就带领大家来看看Graphviz怎么使用的。
4.2.1.4.2决策树的可视化只之使用Graphviz
首先需要安装Graphviz,笔者使用的是Anaconda集成环境,只需在在终端窗口输入:
conda install python-graphviz
需要在代码中添加如下代码。
# Visualize model
with open("Infor_Gain.dot", 'w') as f:
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f)
【完整代码参考附件1.DT_buys_computer_Classifty\DT_buys_computer_Classifty-sklearn_v2.0\DT_buys_computer_Classifty-sklearn_v2.0.1\ DT_buys_computer_Classifty-sklearn_v2.0.1.py】
运行成功后会在目录下生成Infor_Gain.dot的文件,需要转化dot文件至pdf可视化决策树。
dot -Tpdf Infor_Gain.dot -o output.pdf
结果如下。
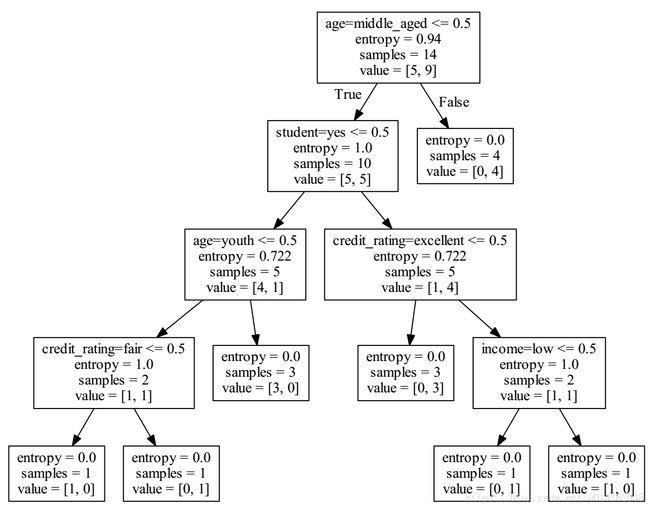
笔者觉得还是很麻烦,还有单独转化,有没有更加简单的呢,答案是有的。
代码如下。
# -*- coding: utf-8 -*-
import pandas as pd
import graphviz
from sklearn import tree
def createDataSet():
#数据集
dataSet = [[0, 0, 0, 2],
[0, 0, 1, 2],
[1, 0, 0, 2],
[2, 0, 0, 1],
[2, 1, 0, 0],
[2, 1, 1, 0],
[1, 1, 1, 0],
[0, 0, 0, 1],
[0, 1, 0, 0],
[2, 1, 0, 1],
[0, 1, 1, 1],
[1, 0, 1, 1],
[1, 1, 0, 2],
[2, 0, 2, 2]]
#特征标签
labels = [0,0,1,1,1,0,1,0,1,1,1,1,1,0]
#返回数据集和分类属性
return dataSet, labels
#测试
if __name__ == '__main__':
## Step 1: load data
print("Step 1: load data...")
#方式一
df=pd.read_csv('data.csv')
data=df.values[:-1,1:5]
dataSet=data[:]
labels=df.values[:-1,5:6]
#方式二
#dataSet,labels = createDataSet()
#print(dataSet)
#print(labels)
## Step 2: init DT...
print("Step 2: init DT...")
## criterion可选‘gini’, ‘entropy’,默认为gini(对应CART算法),entropy为信息增益(对应ID3算法)
clf = tree.DecisionTreeClassifier(criterion='entropy')
## Step 3: training...
print("Step 3: training...")
clf = clf.fit(dataSet, labels)
## Step 4: picture...
print("Step 4: picture...")
"""
dot_data = tree.export_graphviz(clf, out_file=None)
"""
#高级配置
dot_data = tree.export_graphviz(clf, out_file=None,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph.render("tree")
## Step 5: testing
print("Step 5: testing...")
test = [1,0,0,2]
predictedLabel = clf.predict([test])
# Step 6: show the result
print("Step 6: show the result...")
print("predictedLabel" + str(predictedLabel))
结果如下。

【完整代码参考附件1.DT_buys_computer_Classifty\DT_buys_computer_Classifty-sklearn_v2\DT_buys_computer_Classifty-sklearn_v2.1\DT_buys_computer_Classifty-sklearn_v2.1.py】
Graphviz官网: http://www.graphviz.org/
参考:
https://blog.csdn.net/WuchangI/article/details/79589542
https://pypi.org/project/pydotplus/
4.2.2决策树简单实例之鸢尾花卉分类
和前面几章一样,还是使用同样的数据来进行分类处理,看是否能进行分类。
# -*- coding: utf-8 -*-
from sklearn import datasets
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
def test_DT():
## Step 1: load data
print("Step 1: load data...")
#导入数据
iris = datasets.load_iris()
## Step 2: split data
print("Step 2: split data...")
#分离数据
# X = features
X = iris.data
# Y = label
Y = iris.target
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=.6)
## Step 3: init NB
print("Step 3: init NB...")
#初始化贝叶斯分类器
clf = tree.DecisionTreeClassifier(criterion='entropy')
## Step 4: training...
print("Step 4: training...")
#训练数据
clf.fit(X_train, Y_train)
## Step 5: testing
print("Step 5: testing...")
#预测数据
predictedLabel = clf.predict(X_test)
#predictedLabel = clf.fit(X_train, Y_train).predict(X_test)
## Step 6: show the result
print("Step 6: show the result...")
#求准确率
# http://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html
print(accuracy_score(Y_test, predictedLabel))
#print("predictedLabel is :")
#print(predictedLabel)
if __name__ == '__main__':
test_DT()
结果如下。

【完整代码参考附件2.DT_Iris_Classify\DT_Iris_Classify-sklearn_v1.0】
可以和前几个算法比较准确率。有兴趣的自行去比较吧,时间复杂度也可以比较。同样可以画出决策树。
# -*- coding: utf-8 -*-
from sklearn import datasets
from sklearn import tree
import graphviz
def test_DT():
## Step 1: load data
print("Step 1: load data...")
#导入数据
iris = datasets.load_iris()
## Step 2: split data
print("Step 2: split data...")
#分离数据
# X = features
X = iris.data
# Y = label
Y = iris.target
## Step 3: init NB
print("Step 3: init NB...")
#初始化贝叶斯分类器
clf = tree.DecisionTreeClassifier(criterion='entropy')
## Step 4: training...
print("Step 4: training...")
#训练数据
clf.fit(X, Y)
## Step 5: picture..
print("Step 5: picture...")
"""
dot_data = tree.export_graphviz(clf, out_file=None)
"""
#高级配置
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph.render("tree")
if __name__ == '__main__':
test_DT()
结果如下。
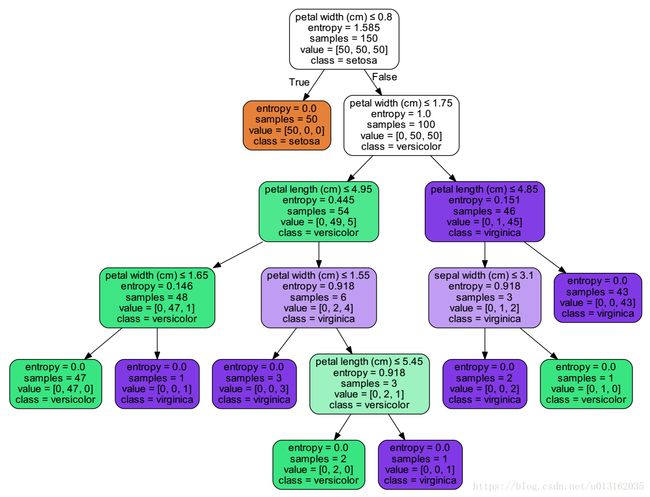
【完整代码参考附件2.DT_Iris_Classify\DT_Iris_Classify-sklearn_v2.0】
4.3决策树数据存储
构造决策树是很耗时的任务,即使处理很小的数据集,如前面的样本数据,也要花费几秒的时间,如果数据集很大,将会耗费很多计算时间。然而用创建好的决策树解决分类问题,则可以很快完成。因此,为了节省计算时间,最好能够在每次执行分类时调用已经构造好的决策树。为了解决这个问题,需要使用Python模块pickle序列化对象。序列化对象可以在磁盘上保存对象,并在需要的时候读取出来。
# -*- coding: utf-8 -*-
import pandas as pd
from math import log
import operator
import pickle
"""
函数说明:创建测试数据集
Parameters:
无
Returns:
dataSet - 数据集
labels - 特征标签
"""
def createDataSet():
#数据集
dataSet = [[0, 0, 0, 2, 'no'],
[0, 0, 1, 2, 'no'],
[1, 0, 0, 2, 'yes'],
[2, 0, 0, 1, 'yes'],
[2, 1, 0, 0, 'yes'],
[2, 1, 1, 0, 'no'],
[1, 1, 1, 0, 'yes'],
[0, 0, 0, 1, 'no'],
[0, 1, 0, 0, 'yes'],
[2, 1, 0, 1, 'yes'],
[0, 1, 1, 1, 'yes'],
[1, 0, 1, 1, 'yes'],
[1, 1, 0, 2, 'yes'],
[2, 0, 2, 2, 'no']]
#特征标签
labels = ['age', 'student', 'credit_rating', 'income']
#返回数据集和分类属性
return dataSet, labels
"""
函数说明:计算给定数据集的经验熵(香农熵)
Parameters:
dataSet - 数据集
Returns:
shannonEnt - 经验熵(香农熵)
"""
def calcShannonEnt(dataSet):
#返回数据集的行数
numEntires = len(dataSet)
#保存每个标签(Label)出现次数的字典
labelCounts = {}
#对每组特征向量进行统计
for featVec in dataSet:
#提取标签(Label)信息
currentLabel = featVec[-1]
#如果标签(Label)没有放入统计次数的字典,添加进去
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 #Label计数
shannonEnt = 0.0 #经验熵(香农熵)
#计算香农熵
for key in labelCounts:
#选择该标签(Label)的概率
prob = float(labelCounts[key]) / numEntires
#利用公式计算
shannonEnt -= prob * log(prob, 2)
#返回经验熵(香农熵)
return shannonEnt
"""
函数说明:按照给定特征划分数据集
Parameters:
dataSet - 待划分的数据集
axis - 划分数据集的特征
value - 需要返回的特征的值
Returns:
无
"""
def splitDataSet(dataSet, axis, value):
#创建返回的数据集列表
retDataSet = []
#遍历数据集
for featVec in dataSet:
if featVec[axis] == value:
#去掉axis特征
reducedFeatVec = featVec[:axis]
#将符合条件的添加到返回的数据集
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
#返回划分后的数据集
return retDataSet
"""
函数说明:计算X_i给定的条件下,Y的条件熵
Parameters:
dataSet - 数据集
i - 维度i
uniqueVals - 数据集特征集合
Returns:
newEntropy - 条件熵
"""
def calcConditionalEntropy(dataSet, i, uniqueVals):
#经验条件熵
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet)) # 极大似然估计概率
newEntropy += prob * calcShannonEnt(subDataSet) # 条件熵的计算
return newEntropy
"""
函数说明:计算信息增益
Parameters:
dataSet - 数据集
baseEntropy - 数据集的信息熵
Returns:
bestIndex - 最好的特征索引
bestInfoGain - 最好的信息增益
"""
def calcInformationGain(dataSet):
#最优特征的索引值
bestIndex = -1
#信息增益
bestInfoGain = 0.0
baseEntropy = calcShannonEnt(dataSet)
#特征数量
numFeatures = len(dataSet[0]) - 1
#遍历所有特征
for i in range(numFeatures):
#获取dataSet的第i个所有特征
featList = [example[i] for example in dataSet]
#创建set集合{},元素不可重复
uniqueVals = set(featList)
#经验条件熵
newEntropy = 0.0
#计算条件熵
newEntropy = calcConditionalEntropy(dataSet, i, uniqueVals)
#得到增益
infoGain = baseEntropy - newEntropy # 信息增益,就yes熵的减少,也就yes不确定性的减少
#最优增益选择
if (infoGain > bestInfoGain):
#更新信息增益,找到最大的信息增益
bestInfoGain = infoGain
#记录信息增益最大的特征的索引值
bestIndex = i
return bestIndex, bestInfoGain
"""
函数说明:统计classList中出现此处最多的元素(类标签)
Parameters:
classList - 类标签列表
Returns:
sortedClassCount[0][0] - 出现此处最多的元素(类标签)
"""
def majorityCnt(classList):
classCount = {}
for vote in classList:
#统计classList中每个元素出现的次数
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True) #根据字典的值降序排序
#返回classList中出现次数最多的元素
return sortedClassCount[0][0]
"""
函数说明:创建决策树
Parameters:
dataSet - 训练数据集
labels - 分类属性标签
featLabels - 存储选择的最优特征标签
Returns:
myTree - 决策树
"""
def createTree(dataSet, labels, featLabels):
#取分类标签(是否放贷:yes or no)
classList = [example[-1] for example in dataSet]
#如果类别完全相同则停止继续划分
if classList.count(classList[0]) == len(classList):
return classList[0]
#遍历完所有特征时返回出现次数最多的类标签
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat, bestInfoGain= calcInformationGain(dataSet) #选择最优特征
bestFeatLabel = labels[bestFeat]#最优特征的标签
featLabels.append(bestFeatLabel)
myTree = {bestFeatLabel:{}} #根据最优特征的标签生成树
del(labels[bestFeat]) #删除已经使用特征标签
#得到训练集中所有最优特征的属性值
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues) #去掉重复的属性值
for value in uniqueVals: #遍历特征,创建决策树。
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), labels, featLabels)
return myTree
"""
函数说明:存储决策树
Parameters:
inputTree - 已经生成的决策树
filename - 决策树的存储文件名
Returns:
无
"""
def storeTree(inputTree, filename):
with open(filename, 'wb') as fw:
pickle.dump(inputTree, fw)
#测试
if __name__ == '__main__':
## Step 1: load data
print("Step 1: load data...")
#方式一
#dataSet, labels = createDataSet()
#方式二
df=pd.read_csv('data.csv')
data=df.values[:-1,1:].tolist()
dataSet=data[:]
label=df.columns.values[1:-1].tolist()
labels=label[:]
#print(dataSet)
#print(labels)
## Step 2: training...
print("Step 2: training...")
featLabels = []
myTree = createTree(dataSet, labels, featLabels)
#print(myTree)
## Step 3: Storage tree ...
print("Step 3: Storage tree...")
storeTree(myTree, 'classifierStorage.txt')
运行代码,在该Python文件的相同目录下,会生成一个名为classifierStorage.txt的txt文件,这个文件二进制存储着我们的决策树。我们可以打开看下存储结果。
【注】打开classifierStorage.txt有要求,笔者使用的是Sublime Text 。
因为这个是个二进制存储的文件,我们也无需看懂里面的内容,会存储,会用即可。那么怎么用呢?使用pickle.load进行载入即可,编写代码如下。
# -*- coding: utf-8 -*-
import pickle
"""
函数说明:读取决策树
Parameters:
filename - 决策树的存储文件名
Returns:
pickle.load(fr) - 决策树字典
"""
def grabTree(filename):
fr = open(filename, 'rb')
return pickle.load(fr)
#测试
if __name__ == '__main__':
myTree = grabTree('classifierStorage.txt')
print(myTree)
结果如下。
![]()
4.4决策树ID3算法的不足
ID3算法虽然提出了新思路,但是还是有很多值得改进的地方。
A)ID3没有考虑连续特征,比如长度,密度都是连续值,无法在ID3运用。这大大限制了ID3的用途。
B)ID3采用信息增益大的特征优先建立决策树的节点。很快就被人发现,在相同条件下,取值比较多的特征比取值少的特征信息增益大。比如一个变量有2个值,各为1/2,另一个变量为3个值,各为1/3,其实他们都是完全不确定的变量,但是取3个值的比取2个值的信息增益大。如果校正这个问题呢?
C)ID3算法对于缺失值的情况没有做考虑;
D)没有考虑过拟合的问题。
ID3算法的作者昆兰基于上述不足,对ID3算法做了改进,这就是C4.5算法,也许你会问,为什么不叫ID4,ID5之类的名字呢?那是因为决策树太火爆,他的ID3一出来,别人二次创新,很快就占了ID4, ID5,所以他另辟蹊径,取名C4.0算法,后来的进化版为C4.5算法。在后文就会谈C4.5算法
参考文档:
英文文档:http://scikit-learn.org/stable/modules/tree.html
中文文档:http://sklearn.apachecn.org/cn/0.19.0/modules/tree.html
参考实例:
英文链接
中文链接
参考文献:
[1]《机器学习》周志华著
[2]《统计学习方法》李航著
[3]L. Breiman, J. Friedman, R. Olshen, and C. Stone. Classification and Regression Trees. Wadsworth, Belmont, CA, 1984.
[4] Quinlan, JR. (1986) Induction of Decision Trees. Machine Learning, 1, 81-106.
[5]J.R. Quinlan. C4. 5: programs for machine learning. Morgan Kaufmann, 1993.
[6]T. Hastie, R. Tibshirani and J. Friedman. Elements of Statistical Learning, Springer, 2009.
问题解决:
ValueError: Expected 2D array, got 1D array instead:
array=[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.].
Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
出现如上错误,这是使用的是一个新的scikit学习版本,它抛出了一个错误,因为在新版本中,所有东西都必须是一个二维矩阵,甚至是一个列或行。可以看到错误下的提示,就可解决问题。也就是用数组来重塑你的数据。如果您的数据有一个单独的特性或数组,那么重构(-1,1)。重构(1,-1)如果它包含一个单一的样本。逼着给出两种方法。
方法一:
predictedY = clf.predict([newRowX])
方法二:
predictedY = clf.predict(newRowX.reshape(1,-1))
参考:
https://blog.csdn.net/dongyanwen6036/article/details/78864585
本章参考附件
点击进入