Matlab编程技巧:Excel表格数据导入
在MBD(基于模型的设计)开发中,经常需要用matlab读取表格中的数据进行处理。因此,本文专门研究了一下matlab语言中用于处理Excel表格的两个函数,总结其用法、输入输出变量以及它们的适用场景。
文章目录
- 1 函数
- 1.1 xlsread
- 1.2 readtable
- 2 两个函数的比较
- 2.1 xlsread
- 2.2 readtable
- 3 两个函数的不同的适用场景
1 函数
常用的读取Excel表格的函数有以下两个:
1.1 xlsread
语法为:[num,txt,raw] = xlsread(filename,sheet,xlRange)
假设有一表格文件“SourceData.xlsx”,工作表为“Sheet1”,如下图所示:
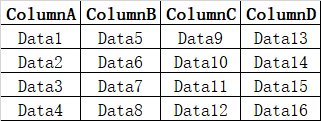
在Matlab命令行使用xlsread函数:
>> [num,txt,raw] = xlsread("SourceData.xlsx",'Sheet1');
>> raw
raw =
5×4 cell 数组
{'ColumnA'} {'ColumnB'} {'ColumnC'} {'ColumnD'}
{'Data1' } {'Data5' } {'Data9' } {'Data13' }
{'Data2' } {'Data6' } {'Data10' } {'Data14' }
{'Data3' } {'Data7' } {'Data11' } {'Data15' }
{'Data4' } {'Data8' } {'Data12' } {'Data16' }
返回的结果raw是个5×4的元胞数组。另外两个返回值num,txt分别为数值和文本。
1.2 readtable
语法为:T = readtable(filename)
该函数不仅可以读取表格文件,而且可以读取文本文件等其他格式,但是要定义分隔符等。
在Matlab命令行使用readtable函数:
>> T = readtable('SourceData.xlsx','sheet','Sheet1');
>> T
T =
4×4 table
ColumnA ColumnB ColumnC ColumnD
_______ _______ ________ ________
'Data1' 'Data5' 'Data9' 'Data13'
'Data2' 'Data6' 'Data10' 'Data14'
'Data3' 'Data7' 'Data11' 'Data15'
'Data4' 'Data8' 'Data12' 'Data16'
>> T.ColumnA
ans =
4×1 cell 数组
{'Data1'}
{'Data2'}
{'Data3'}
{'Data4'}
返回的结果是4×4的table格式,table格式中把列标签单独提取出来,每一列的内容转化成了一个元胞数组。
2 两个函数的比较
两个函数返回的数据格式分别为Cell和Table,因此处理起来比较不同。
2.1 xlsread
元胞数组的处理比较简单,直接用{}就可以取出其中的数据。例如取出元胞数组中第二行第三列,代码如下:
>> raw{2,3}
ans =
'Data9'
2.2 readtable
Table格式则必须根据列标签取出。同样是第二行第三列,对于Table来说,应该是ColumnC列的第一个元素,所以应该表达为:
>> T.ColumnC{1}
ans =
'Data9'
3 两个函数的不同的适用场景
在MBD的开发过程中,经常用Matlab来处理Excel表格,也踩过了不少坑。所以选择合适的方法来编程非常重要。
先说结论,在目标Excel有列标签的时候,尽量使用后者,也就是readtable来进行表格文件读取的处理。在没有标签的情况下才用前者。原因如下:
1.可读性更好
如上文所说,xlsread的方式需要用raw{2,3}来取出数值,readtable用 T.ColumnC{1}。后者一眼就能看出是ColumnC标签下的第一个元素,而前者没办法直观的看出其含义。
2.可维护性好
在工作中,需要处理的表格往往根据需求会不断地调整。假如我有一个新的需求,需要在例子中的B列和C列中插入一列,标签为ColumnB1,如图所示
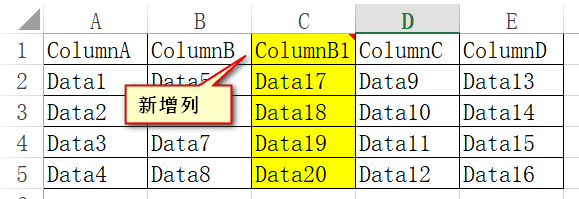
那么我之前写的Matlab脚本也需要随之更改。如果用的是xlsread的方式,则所有处理第三列的行为都要改成处理第四列,即raw{2,3}要改成raw{2,4};而table则完全不用为了适应列数变化而改变,因为列标签还是叫ColumnC。
>>返回个人博客总目录