SqueezeNet 神经网络简介与代码实战
1.介绍
SqueezeNet是2016提出的,虽然比较老,但也有值得学习的地方,比如通过1x1的卷积来减少 feature map 的维数,更加详细的介绍可以参见:SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE
2.模型结构
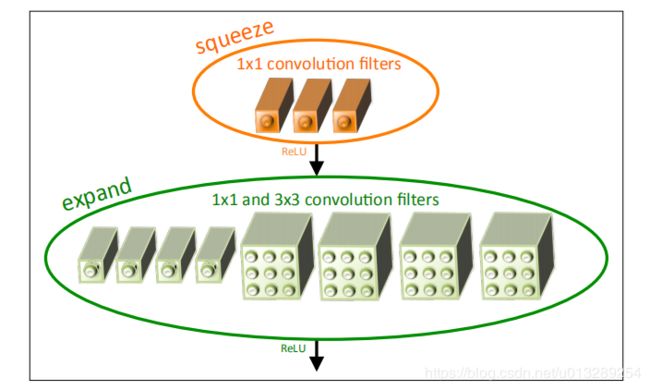
SqueezeNet 的核心在于 Fire module,Fire module 由两层构成,分别是 squeeze 层+expand 层,如下图 1 所示,squeeze 层是一个 1*1 卷积核的卷积层,expand 层是 1*1 和 3*3 卷积核的卷积层,expand 层中,把 1*1 和 3*3 得到的 feature map 进行 concat。
3.模型特点
(1)使用1∗1卷积代替3∗3 卷积:参数减少为原来的1/9
(2)减少输入通道数量:这一部分使用squeeze layers来实现
(3)将池化层操作延后,可以给卷积层提供更大的激活图:更大的激活图保留了更多的信息,可以提供更高的分类准确率
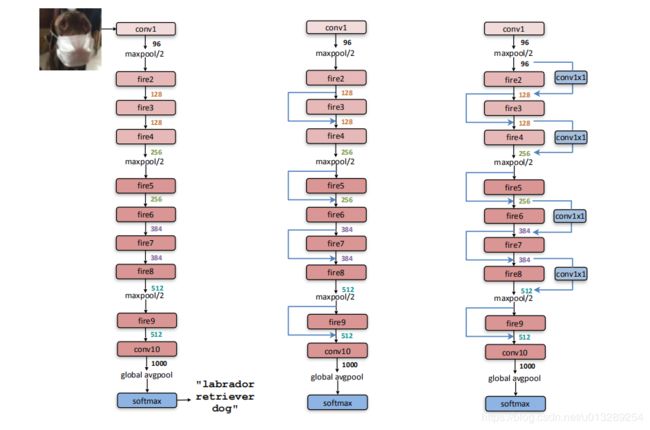
4.代码实现 pytorch
class Fire(nn.Module):
def __init__(self, inplanes, squeeze_planes,
expand1x1_planes, expand3x3_planes):
super(Fire, self).__init__()
self.inplanes = inplanes
self.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1)
self.squeeze_activation = nn.ReLU(inplace=True)
self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes,
kernel_size=1)
self.expand1x1_activation = nn.ReLU(inplace=True)
self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes,
kernel_size=3, padding=1)
self.expand3x3_activation = nn.ReLU(inplace=True)
def forward(self, x):
x = self.squeeze_activation(self.squeeze(x))
return torch.cat([
self.expand1x1_activation(self.expand1x1(x)),
self.expand3x3_activation(self.expand3x3(x))
], 1)
class SqueezeNet(nn.Module):
def __init__(self, version='1_0', num_classes=1000):
super(SqueezeNet, self).__init__()
self.num_classes = num_classes
if version == '1_0':
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=7, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(96, 16, 64, 64),
Fire(128, 16, 64, 64),
Fire(128, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 32, 128, 128),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(512, 64, 256, 256),
)
elif version == '1_1':
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(64, 16, 64, 64),
Fire(128, 16, 64, 64),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(128, 32, 128, 128),
Fire(256, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
Fire(512, 64, 256, 256),
)
else:
# FIXME: Is this needed? SqueezeNet should only be called from the
# FIXME: squeezenet1_x() functions
# FIXME: This checking is not done for the other models
raise ValueError("Unsupported SqueezeNet version {version}:"
"1_0 or 1_1 expected".format(version=version))
# Final convolution is initialized differently from the rest
final_conv = nn.Conv2d(512, self.num_classes, kernel_size=1)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
final_conv,
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d((1, 1))
)
for m in self.modules():
if isinstance(m, nn.Conv2d):
if m is final_conv:
init.normal_(m.weight, mean=0.0, std=0.01)
else:
init.kaiming_uniform_(m.weight)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return torch.flatten(x, 1)