大数据导入EXCEL
最近上头给我派了一个活,oracle数据导入excel,接任务的时候,我感觉比较轻松,心里想,这很简单,三下五除二,一个上午就可以搞定,因为之前实现过嘛!
但是在加上“大数据”烙印之后,就不是那么简单的一回事了,实现过程中,出现最常见的两个问题:超出行数限制和内存溢出!
18天的数据,总共是500w条,如何将500w条记录存入excel中,我当时想过两种实现方式:PLSQL DEVELOPER和Java poi!
PLSQL DEVELOPER
有两种实现方法:
1、在新建一个SQL WINDOW,执行你要导出数据的查询语句,查询完之后,在结果显示的地方点击向下的箭头,让它全部显示,这可能需要一点点时间,显示结束后,右键点击显示结果的地方,选中 copy to excel(xls和xlsx,前者是03及以前版本,每个sheet只能显示65535条记录;后者是07及以后版本每个sheet可以显示1048576条记录)。
2、在新建一个REPORT WINDOW,执行你要导出数据的查询语句,查询完之后,点击屏幕右边绿色圆饼状图标(export results),后面的操作就很简单了,不再废话。
两种方式比较实现起来简单,易操作,但是有很严重的弊端:其一,PLSQL DEVELOPER一次导出excel数据有限,只有几十万条,超出范围,则内存溢出;其二,如果分页查询或者条件查询,则分批的数据又不能导入同一个excel中。挺痛苦的~
在简单方法行不通的时候,只能走向更加复杂的程序之路...
Java poi
在使用Java poi之前,尝试过JXL,但是个人觉得Java poi更加顺手,这并不是说JXL不好用,JXL更多地面向的是底层,比较麻烦点,但更加灵活;而Java poi封装地更多,使用起来更加顺手。
其实这些都不是重点!
重点是在实现过程中如何处理上面两个最常见的问题:超出行数限制和内存溢出!
内存溢出:
一个经常处理大数据,公司硬件却跟不上的软肋,真心耗费时间!最常用的解决途径就是分批处理,结合Java 虚拟机观察一次处理中在不导致内存溢出的前提下,最大能处理的数据量,以达到虚拟机的充分利用。
在oracle查询数据这一段,写个分页查询,分页查询完后,都放入到一个集合中,具体实现过程,暂且不表!
超出行数限制:
如果将oracle中查询出500w数据一股脑儿导入excel,又会遇到另一个棘手问题:超出行数限制。
如果到的是xls格式,我就让程序循环跑起来,循环一次,导入65535条;xlsx格式的,就让它循环一次,导入1048576条,如此循环下去,直到程序跑完!
请看本人代码示例:
public class XlsDto2Excel {
@Autowired
private ToDBDao toDBDao;
/**
*
* @param xls
* XlsDto实体类的一个对象
* @throws Exception
* 在导入Excel的过程中抛出异常
*/
public void toExcel(String date, int count) {
int PAGESIZE = 65535;
// declare a new workbook 声明一个工作簿
HSSFWorkbook wb = new HSSFWorkbook();
// declare a row object reference 声明一个新行
HSSFRow r = null;
// declare a cell object reference 声明一个单元格
HSSFCell c0, c1, c2, c3, c4, c5 = null;
HSSFCell[] firstcell = new HSSFCell[6];
// create 2 cell styles 创建2个单元格样式
HSSFCellStyle cs = wb.createCellStyle();
HSSFCellStyle cs2 = wb.createCellStyle();
// create 2 fonts objects 创建2个单元格字体
HSSFFont f = wb.createFont();
HSSFFont f2 = wb.createFont();
// Set font 1 to 12 point type, blue and bold 设置字体类型1到12号,蓝色和粗体
f.setFontHeightInPoints((short) 12);
f.setColor(HSSFColor.RED.index);
f.setBoldweight(HSSFFont.BOLDWEIGHT_BOLD);
// Set font 2 to 10 point type, red and bold 设置字体类型2到10号,黑色和粗体
f2.setFontHeightInPoints((short) 10);
f2.setColor(HSSFColor.BLACK.index);
f2.setBoldweight(HSSFFont.BOLDWEIGHT_BOLD);
// Set cell style and formatting 设置单元格样式和格式
cs.setFont(f);
// 水平布局:居中
cs.setAlignment(HSSFCellStyle.ALIGN_CENTER);
// cs.setDataFormat(df.getFormat("#,##0.0"));
// Set the other cell style and formatting 设置其他单元格样式和格式
cs2.setBorderBottom(cs2.BORDER_THIN);
cs2.setDataFormat(HSSFDataFormat.getBuiltinFormat("text"));
cs2.setFont(f2);
// 水平布局:居中
cs2.setAlignment(HSSFCellStyle.ALIGN_CENTER);
// 从数据库,获取总的集合大小
List list = this.toDBDao.selectFatherData(date);
// 获取循环次数(在此结果上+1),一次循环下,子循环PAGESIZE次,最后一次循环,子循环mod次
int circleCount = list.size() / PAGESIZE;
int mod = list.size() % PAGESIZE;
String firstOrderId = "";
String orderTime = "";
for (int i = 0; i < circleCount + 1; i++) {
// create a new sheet 创建一个新工作表,但一个sheet加载满65535条记录后,自动生成一个新的sheet,以保证不会超出行数限制
HSSFSheet sheet = wb.createSheet("第" + i+ "页");
/*
* 设置表头
*/
HSSFRow firstrow = sheet.createRow(0); // 下标为0的行开始
String[] names = new String[6];
names[0] = "访问编号";
names[1] = "浏览数";
names[2] = "平均访问时长";
names[3] = "订单编号";
names[4] = "下单时间";
names[5] = "初始时间";
for (int j = 0; j < 6; j++) {
firstcell[j] = firstrow.createCell(j);
firstcell[j].setCellValue(new HSSFRichTextString(names[j]));
firstcell[j].setCellStyle(cs2);
}
//最后一次循环
if (i == circleCount) {
for (int rownum = 1; rownum < mod; rownum++) {
// 获取行对象
r = sheet.createRow(rownum);
HashMap father = (HashMap) list.get(rownum + PAGESIZE * i);
for (int cellnum = 0; cellnum < 6; cellnum++) {
/*
* 获取列对象
*/
c0 = r.createCell(0);
c1 = r.createCell(1);
c2 = r.createCell(2);
c3 = r.createCell(3);
c4 = r.createCell(4);
c5 = r.createCell(5);
/*
* 给列对象赋值
*/
c0.setCellValue(father.get("sessionId").toString());
c0.setCellStyle(cs2);
c1.setCellValue(father.get("visitPages").toString());
c1.setCellStyle(cs2);
c2.setCellValue(father.get("perVisitsTime").toString());
c2.setCellStyle(cs2);
if (null != father.get("firstOrderId")) {
firstOrderId = father.get("firstOrderId")
.toString();
}
c3.setCellValue(firstOrderId);
c3.setCellStyle(cs2);
if (null != father.get("orderTime")) {
orderTime = father.get("orderTime").toString();
}
c4.setCellValue(orderTime);
c4.setCellStyle(cs2);
c5.setCellValue(father.get("initTime").toString());
c5.setCellStyle(cs2);
}
}
} else {
for (int rownum = 1; rownum <= PAGESIZE; rownum++) {
// 获取行对象
r = sheet.createRow(rownum);
HashMap father = (HashMap) list.get(rownum + PAGESIZE * i);
for (int cellnum = 0; cellnum < 6; cellnum++) {
/*
* 获取列对象
*/
c0 = r.createCell(0);
c1 = r.createCell(1);
c2 = r.createCell(2);
c3 = r.createCell(3);
c4 = r.createCell(4);
c5 = r.createCell(5);
/*
* 给列对象赋值
*/
c0.setCellValue(father.get("sessionId").toString());
c0.setCellStyle(cs2);
c1.setCellValue(father.get("visitPages").toString());
c1.setCellStyle(cs2);
c2.setCellValue(father.get("perVisitsTime").toString());
c2.setCellStyle(cs2);
if (null != father.get("firstOrderId")) {
firstOrderId = father.get("firstOrderId")
.toString();
}
c3.setCellValue(firstOrderId);
c3.setCellStyle(cs2);
if (null != father.get("orderTime")) {
orderTime = father.get("orderTime").toString();
}
c4.setCellValue(orderTime);
c4.setCellStyle(cs2);
c5.setCellValue(father.get("initTime").toString());
c5.setCellStyle(cs2);
}
}
}
sheet.autoSizeColumn((short) 0); // 根据内容调整第一列宽度,不过不设置,默认情况下,按照表头自动调整宽度
sheet.autoSizeColumn((short) 4); // 根据内容调整第五列宽度,不过不设置,默认情况下,按照表头自动调整宽度
sheet.autoSizeColumn((short) 5); // 根据内容调整第六列宽度,不过不设置,默认情况下,按照表头自动调整宽度
}
// Save保存
FileOutputStream out;
try {
out = new FileOutputStream("d://workbook.xls");
wb.write(out);
out.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("--执行完毕--");
}
}
说明:虽然,用xlsx格式方式可以一次导入100w条记录,但是代码执行要慢上许多,我也没搞清楚具体原因。不过,大家可以在导入同样多数据情况下,用xls和xlsx两种方式对比一下。
其实除了以上两种方式之外,经本人查找资料,还找到了另一个更加方便的方式,那就是搭建数据源ODBC,连接excel,数据传输。
如何搭建oracle ODBC,网上资料一查一大把,这里我就不再赘述!
搭建完之后,我们就来操作excel,新建一个excel,07版的更好,选中数据。
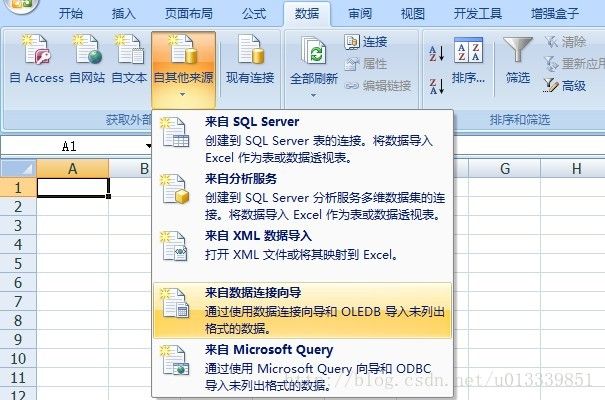
选择来自数据连接向导—>其他/高级—>选择带有oracle的选项,接着输入用户名、密码和连接地址,连接成功后,会显示oracle中的所有表名,注意这些表明排列是没有顺序的,但是我们可以快速索引到我们想要导出数据的表名,比如一个表名叫做father_user_behavior,我们可以这样定位:先按f,再按a,再按t,这样基本上可以直接定位到你想要的表名,接下来的操作就很简单了,不多说!
需要注意的是,当数据超出1048576条,同样会出现问题(它不会自动生成第二个sheet):
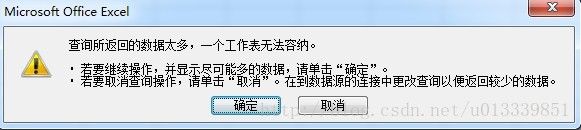
所以这种方式,也有其弊端。