mysql 分库分表分区总结
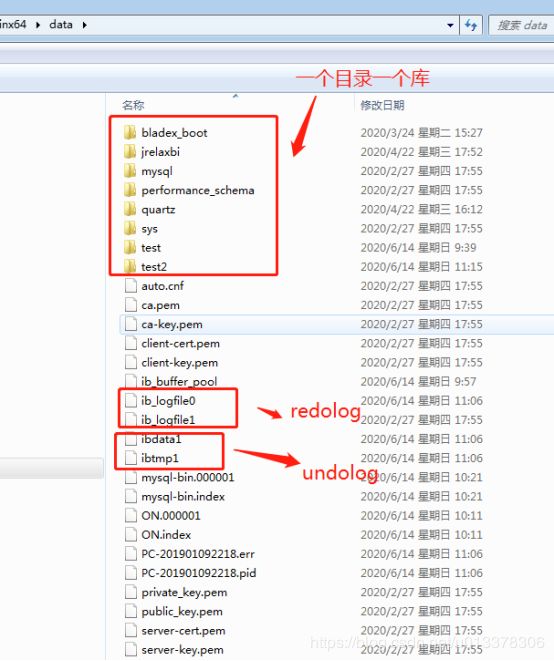
Mysql目录结构
一个库一个目录
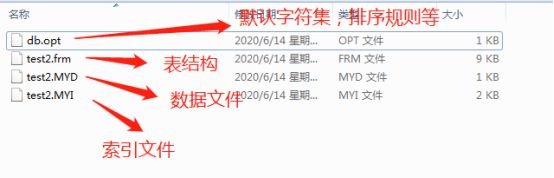
MyISAM引擎
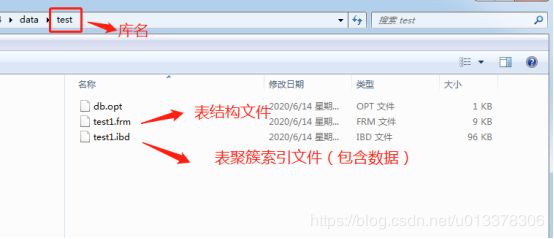
InnoDB引擎
分库分表分区总结
对于分区分表 都可以进行横向(按表字段分),纵向分(按数据行分),此文暂时值考虑横向分。
对于分库:分库
分区
说明
分区和分表类似,把原本的一个数据量很大的表,根据规则分成很多块。这些块可以跨磁盘分布。突破单磁盘IO的限制。

好处
- 分区为了突破IO瓶颈,可以把索引及数据文件放在不同磁盘。
- 可以根据自定义的分区方式 优化查询,比如根据分区列查询,就会定位到某个分区只查某分区的数据。
- 完全在数据库层面操作,与代码解耦,不需要java代码等进行逻辑处理,后期增加,拆分,合并,删除 方便。
- 不用关心跨分区统计查询问题,数据库层面已经处理好。
缺点
- 要事先预估数据量,后期可能会随着数据的增加而需要重新映射分区。
- 只能在一个数据库实例中,内存加载和计算只能在一台机器中。
分表
说明
分表是建立多张子表,每张表的表字段相同,根据映射算法把数据分到不同子表。数据文件只能在一个磁盘上,一个数据库实例中。
好处
- 可以根据自定义的表字段映射算法,把每次增删改查时的操作映射到的表,这样可以少查询数据。可以数据量很大的表表 横向拆分为多个子表。
缺点
- 需要java代码逻辑处理映射算法。比较复杂。
(2)只能在一个数据库实例中,只能在一个磁盘中,内存加载和计算只能在一台机器中。
(3)要事先预估数据量,后期可能会随着数据的扩容重新扩展映射表。
(4)对于跨子表的统计查询,会比较复杂。
分库
好处
分库 可以突破服务器单节点内存,和计算的的限制。具体可以通自定义程序逻辑实现。根据场景自己实现即可。
如:主从备份读写分离,数据库按业务进行分(纵向)。把一张很大的表横向切分 并放在不同的库中(映射方法类似于分表分区)。
缺点
分库要考虑跨库多表查询的问题。
要考虑分布式事务的问题。
分区
主要可以利用多个磁盘,提高IO性能。
分区把一个表数据和索引存储到多个不同的地方,跨磁盘,(可以跨文件系统,前提是当前系统可以看到此文件系统),可以指定每个分区文件存储的位置。
分区可以分为垂直分区(对一个大表,拆字段分别放在不同分区),和水平分区(把特定的某些行分开存放)。目前mysql只支持水平分区。
指定分区所在磁盘的文件:https://blog.csdn.net/xuheng8600/article/details/79817040
分区具体命令操作:https://blog.csdn.net/qq_35726305/article/details/81221721
分区可以调整(如把一个分区调整为2个),可以合并(如把两个分区合并为一个),可以追加,可以删除
在做分区前,也要先预估数据量,然后分为几个区。最好是按照时间分区,比如一年一个分区,这样就不用预估多少个分区,每一年开始就追加一个分区即可
Mysql分区类型
根据所使用的不同分区规则可以分成几大分区类型。
RANGE 分区:
基于属于一个给定连续区间的列值,把多行分配给分区。
LIST 分区:
类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
HASH分区:
基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL中有效的、产生非负整数值的任何表达式。
KEY
分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
复合分区:
基于RANGE/LIST 类型的分区表中每个分区的再次分割。子分区可以是 HASH/KEY 等类型。
对表做range分区
create table t5 (a varchar(20) not null,b varchar(11) not null,id int not null) partition by range(id)
(
partition s1 values less than(2000000),
partition s2 values less than(4000000),
partition s3 values less than(10000000)
)
可见分为三个区后,在mysql的数据库目录下,多了三个ibd分区的文件,和一个frm的表信息文件。

不使用分区列查询,可以看到用到了三个分区
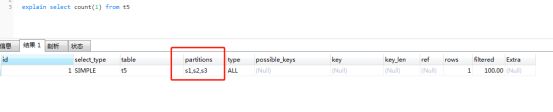
分区约束
- 在5.1版本中分区表对唯一约束有明确的规定,每一个唯一约束必须包含在分区表的分区键(也包括主键约束)。
- 还有很多约束,比如不能外键,以及innordb,MyISAM引擎上的约束等等。
分区后查询性能
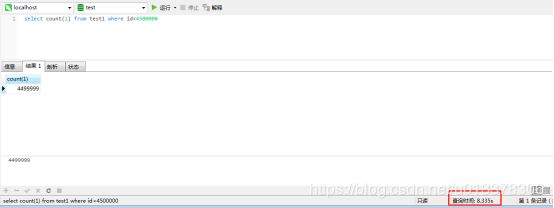
注意此处测试时,我所有分区都在一个磁盘,所以不考虑多个磁盘会提升IO性能的问题。
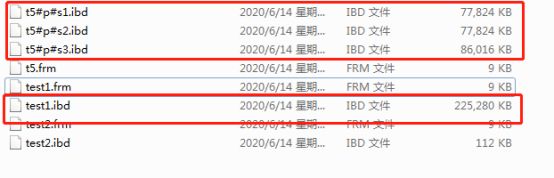
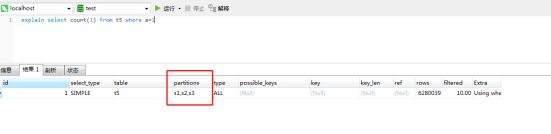
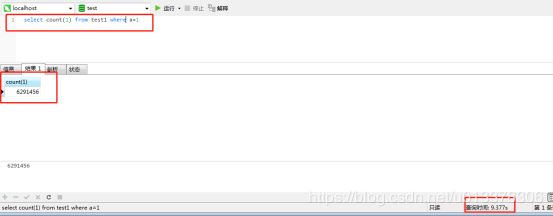
test1是没有分区的表,t5是分为三个区的表(按照id:<2000000,<4000000,<10000000)。两个表都没有索引,数据都一样,总量都为6291456条。
两个 表格式如下

条件不包含分区列
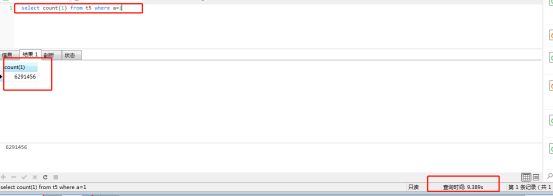
可以看到,条件如果没有分区列,则会查询三个分区。速度上两者差不多。
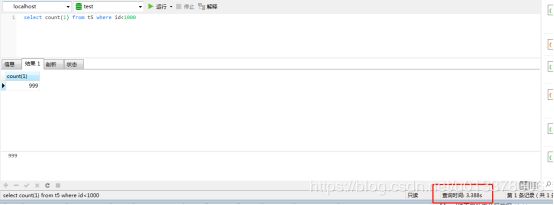
条件包含分区列
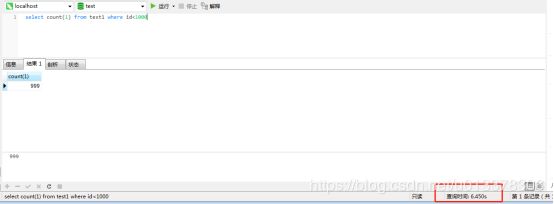
在一个分区内的数据查询
可以看到只使用一个分区。速度要比不分区要快的多。

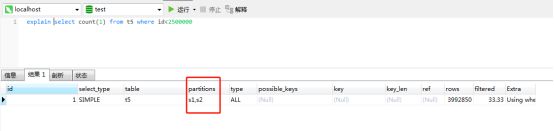
数据跨两个分区
可以看到id<2500000的数据跨了两个分区。同样比不分区要快。
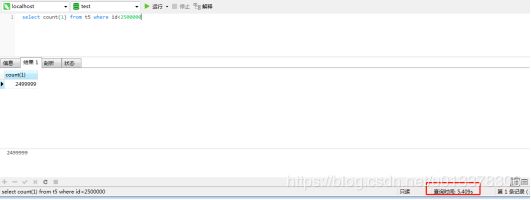
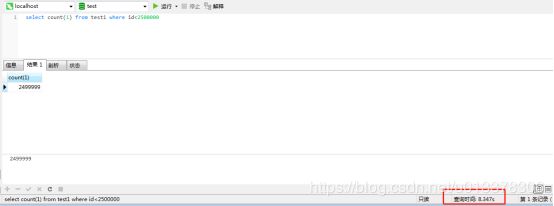
跨所有分区
当条件id<4500000时跨所有三个分区,速度上两者差不多。
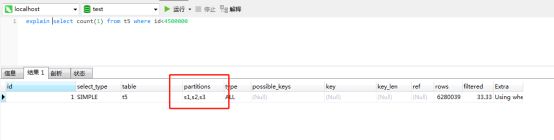
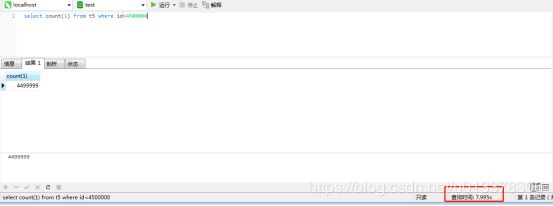
分表
分表有多种方式,目前我们只说两种。做分表前,最好要提前预估数据量(不然后面要增加子表需要重建映射关系),并根据数据量 确定使用的映射子表的算法。最好能够按年进行分表,这样就能很好的解决建多少张表的问题。
另外可以考虑一致性hash。
Merge引擎实现表合并(不推荐)
主要原理是利用MERGE引擎创建一个主表,把两张子表关联起来(方便总的统计查询)。这样只查询主表即可。但是由于主表插入的函数只有两个选项LAST或者FIRST(即插入到最后一个子表或者第一个子表)。因此需要自己再程序中创建映射子表的算法。
Sql语句
- 创建两张子表(必须使用MyISAM引擎),并添加数据
- mysql> CREATE TABLE IF NOT EXISTS `user1` (
- -> `id` int(11) NOT NULL AUTO_INCREMENT,
- -> `name` varchar(50) DEFAULT NULL,
- -> `sex` int(1) NOT NULL DEFAULT '0',
- -> PRIMARY KEY (`id`)
- -> ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ;
- Query OK, 0 rows affected (0.05 sec)
- mysql> CREATE TABLE IF NOT EXISTS `user2` (
- -> `id` int(11) NOT NULL AUTO_INCREMENT,
- -> `name` varchar(50) DEFAULT NULL,
- -> `sex` int(1) NOT NULL DEFAULT '0',
- -> PRIMARY KEY (`id`)
- -> ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ;
- Query OK, 0 rows affected (0.01 sec)
- mysql> INSERT INTO `user1` (`name`, `sex`) VALUES('张映', 0);
- Query OK, 1 row affected (0.00 sec)
- mysql> INSERT INTO `user2` (`name`, `sex`) VALUES('tank', 1);
- Query OK, 1 row affected (0.00 sec)
- 创建主表(必须使用MRG_MYISAM引擎)
- ysql> CREATE TABLE IF NOT EXISTS `alluser` (
- -> `id` int(11) NOT NULL AUTO_INCREMENT,
- -> `name` varchar(50) DEFAULT NULL,
- -> `sex` int(1) NOT NULL DEFAULT '0',
- -> INDEX(id)
- -> ) TYPE=MERGE UNION=(user1,user2) INSERT_METHOD=NO AUTO_INCREMENT=1 ;
- Query OK, 0 rows affected, 1 warning (0.00 sec)
上述sql 中TYPE=MERGE表示使用MERGE存储引擎; UNION=(user1,user2) 表示要把两张表组合一起,INSERT_METHOD=NO 表示不允许插入主表。使用first或last值使得插入被相应地做在第一或最后一个表上。如果你没有指定insert_method选项,或你用一个no值指定该选,则表示不允许插入主表。
总结
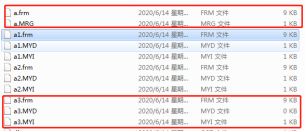
a1,a2,a3为子表,a为主表。数据文件如下
基于MERGE创建的分表,子表必须是myisam, 主表必须是mrg_myisam。此分表只有一个作用,就是利用MERGE合并表的方式,能够统计所有分表的信息(其实完全可以使用sql语句union all)。完全不建议使用。
完全基于自定义映射算法
通过预估数据量,指定数据映射算法,对每次增删改查操作映射到不同的子表上,减少查询数据量。