Hive 基础知识汇总
安装:
安装hive
注意跟Hadoop或者spark版本的对应问题
命令行变量
--hivevar key=value ,可以允许用户在命令行中声明变量,在hive脚本中使用,该变量声明之后,会放置到hivevar变量空间,下面给出hive中所有的命名空间,查看命名空间变量,在hive脚本中,使用set;会打印出所有命名空间的变量。

![]()
Hive 一次性命令
hive会将命令运行完后,将输出打印到标准输入输出,也支持重定向,重定向到文件也可以,可以添加-S ,来启动静默模式,静默模式不会打印出“OK”等多余的输出
hive -S -e "commond"
可是使用该命令来模糊查询命名空间里的变量,包含“warehouse”的变量:
hive -S -e "set" | grep warehouse
hive执行命令
hive -f 从文件中执行命令
hive dfs -ls /; 执行Hadoop命令,只需要去掉Hadoop开头,分号结尾即可。
hive !commond; 感叹号开头,分好结尾结束
hive数据类型
基本数据类型:
| 数据类型 | 所占字节 | 开始支持版本 |
| TINYINT | 1byte,-128 ~ 127 | |
| SMALLINT | 2byte,-32,768 ~ 32,767 | |
| INT | 4byte,-2,147,483,648 ~ 2,147,483,647 | |
| BIGINT | 8byte,-9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 | |
| BOOLEAN | ||
| FLOAT | 4byte单精度 | |
| DOUBLE | 8byte双精度 | |
| STRING | 无长度限制 | |
| BINARY | 无长度限制 | 从Hive0.8.0开始支持 |
| TIMESTAMP | 从Hive0.8.0开始支持 | |
| DECIMAL | 从Hive0.11.0开始支持 | |
| CHAR | 从Hive0.13.0开始支持 | |
| VARCHAR | 从Hive0.12.0开始支持 | |
| DATE | da | 从Hive0.12.0开始支持 |
集合数据类型
ARRAY:ARRAY类型是由一系列相同数据类型的元素组成,这些元素可以通过下标来访问。比如有一个ARRAY类型的变量fruits,它是由['apple','orange','mango']组成,那么我们可以通过fruits[1]来访问元素orange,因为ARRAY类型的下标是从0开始的;
MAP:MAP包含key->value键值对,可以通过key来访问元素。比如”userlist”是一个map类型,其中username是key,password是value;那么我们可以通过userlist['username']来得到这个用户对应的password;
STRUCT:STRUCT可以包含不同数据类型的元素。这些元素可以通过”点语法”的方式来得到所需要的元素,比如user是一个STRUCT类型,那么可以通过user.address得到这个用户的地址。
UNION: UNIONTYPE,他是从Hive 0.7.0开始支持的。
hive分隔符
分隔符为字段、行和集合等分隔符,hive在建表的时候可以自定义设定:

hive读时模式
传统数据库为写时模式,输入在写入的时候会校验数据的正确性,而hive为读时校验,读取的时候才会校验,极力恢复错误,如果无法恢复,一般情况显示null
hive常见操作
创建数据库
![]()
修改数据库目录位置

输出数据库存储位置信息

显示当前使用数据库名:
强制删除数据库
![]()
创建表

从已有的表进行拷贝结构数据

描述表的信息:
![]()
DESCRIBE FORMATTED mydb.employees;
创建并读取外部表

外部表只包含结构信息,内部数据还在源文件中
数据分区
数据分区之后,会将数据按照分区条件分文件夹存放,如果数据量巨大,能够有效的加快查询速度

分区查看
![]()
HIVE读写
hive 使用inputformat和inputformat来 在row和file之间进行转换
使用serDe(序列化和反序列化)在row和列之间转换
如果需要读取自定义格式的数据,可以使用自己编写的inputformat和inputformat
hive删除表
对于表内数据,外部表只删除元数据,内部表删除元数据和数据,可以开启Hadoop的回收站功能,一旦误删了重要表,可以手动恢复元数据,然后将HDFS回收站里的数据恢复即可。
hive表操作
ALERT TABLE 修改表的元数据
修改分区、修改表名、修改列信息、增加列等
只能修改表属性,无法删除表属性
HIVE数据装入
hive没有行级别的插入、删除和更新
导入数据到分区表:

通过查询来输入数据(overwrite更换为into 会以追加的方式插):
从外部表插入分区表:

动态分区插入(该功能默认不开启,即使开启也是严格模式,必须要求一列为静态分区字段,分区数也存在限制):
创建表并插入数据

导出数据

HIVE 查表
支持丰富的计算函数,基本可以表示所有的数学表达式


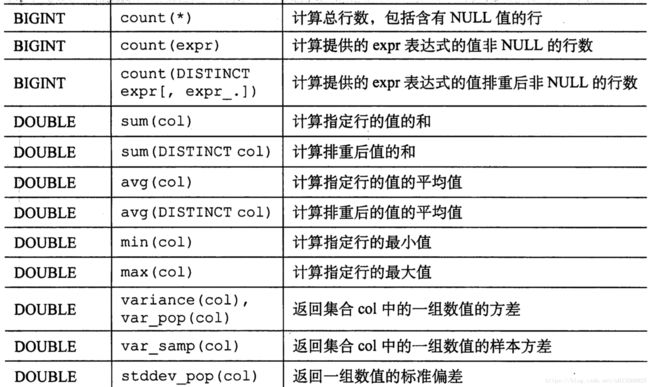
HIVE 聚合函数
包含的聚合函数也比较丰富:
均值方差类、协方差相关系数都挺有用处的


HIVE 聚合函数加速
数据会在map阶段进行聚合,而不是groupBy(reduce)阶段,代价是需要更大的内存
相当于在mapper阶段先进性聚合,将聚合结果向下传递

HIVE表生成函数
可以将一行一列中的一个数组元素,转换成多行,hive提供了几个这种函数,例如;M列转成N行
HIVE其他的内置函数
其他的内置函数包含:
1.编码函数 base64 ascii等
2.字符串处理函数:拼接、正则表达式替换等
3.时间处理函数:获取时间字符串中的年、月和日等,加减天数等
HIVE索引
hive索引现在还处于不成熟状态,尽力索引之后,需要手动将要查询的索引数据,切出来,实用性不强,不切出数据,索引无效果,https://www.cnblogs.com/cssdongl/p/6207697.html
HIVE分区杂谈
传统数据库应对单个表数据增量大的问题,一般都会新建表,表名后加时间戳,但是在hive中,按照时间作为分区,是比较好的选择,这就要牵扯到分区的时间粒度23问题了,如果分区的粒度过细,分区太多,会导致HDFS文件过多,久而久之,元信息将namenode撑爆的问题,而且会导致MapReduce task任务划分过细,和数据量不均衡的问题,数据倾斜,这时候分桶存储表示比较好的选择。
有时候按照分区来划分每天的数据也是比较合适的,不会导致数据覆盖
HIVE数据标准化
满足传统数据库范式的数据称之为标准数据,但是在大数据量的hive中,数据标准化有可能会导致效率低下问题
HIVE多任务
将多个任何合并,对某一个表的多次查询,合并为一次查询:

HIVE 分桶
当分区不合适的时候,一般为分区产生数据倾斜问题或者数据分数目过多的时候,表的数据分桶是比较合适的,设置桶的数目小于分桶标识,一个桶内会有多个分桶标识的数据

必须要打开强制分桶的设置,否则就需要自己设置reduce的数量,reduce的数量一般等于分桶数目

优势:
查询快
分桶之后,某些操作会加速,比如join,无需全局笛卡尔积
HIVE 增加列
![]()
HIVE 优化-本地运行查询提升速度
适用于小数据集:

HIVE 优化 - 并行执行HIVE job 阶段

HIVE 优化 - JVM 重用
针对小文件过多和task过得的时候,使用hive原生派生的jvm,频繁启动消耗过多的资源,在这种情况下,可以开启jvm重用
缺点是,jvm会一只占用,初始所有的任务全部完成。

HIVE相关问题:
1.hive 数据存储
内部表、外部表
表数据和元数据
行存储和列存储
https://blog.csdn.net/holandstone/article/details/77601338?locationNum=6&fps=1
2.HIVE JOIN 优化
https://blog.csdn.net/liyaohhh/article/details/50697519
3.HIVE自定义函数和UDF
https://blog.csdn.net/sqh201030412/article/details/78044160
4.HIVE CMD 执行流程
1) 启动cmd阶段
hiveconf 参数
sessionstate参数 -s -e等
初始化hive配置文件和hiverc
初始化命令行
2) 解析cmdline 运行阶段
cli.processCmd方法
(1)如果是quit或者exit,退出。
(2)source,执行文件中的HiveQL
(3)!,执行命令,如!ls,列出当前目录的文件信息。
(4)list,列出jar/file/archive。
(5)如果是其他,则生成调用相应的CommandProcessor处理。
https://www.cnblogs.com/cxzdy/p/4472207.html
HIVE压缩
hive存在压缩的三个地方:
1) 输入:
只要是Hadoop支持的压缩文件格式,hive都可支持,只不过如果需要直接读取的话,需要指定inputformat和outformat
lzo,snappy,gzip2都可以,但是为了mapper并行度,包含index的lzo和gzip2压缩格式更好一点
2) map输出和reduce输入:
只有在i/o 影响较为明显时候使用,snappy压缩格式就是一个不错的选择,CPU使用率低,压缩效率高
3) 输出:
hive需要在建表的时候说明输出的格式
4) 小文件问题:
小文件输入过多会导致mapper过多,所以可是设置hive,输入进行合并和压缩

该设置可以再mapper阶段合并小文件,但是所使用lzo压缩的时候,无法生效,推荐使用orc和lzo压缩格式
合并小文件
一篇关于hive压缩非常好的文章