Chris Richardson 微服务系列(二)
Chris Richardson 微服务系列(二)
- 5. 微服务的事件驱动数据管理
- 一、微服务以及分布式数据管理中存在的问题
- 二、事件驱动的架构
- 三、实现原子化
- 使用本地事务发布事件
- 挖掘数据库事务日志
- 使用事件源
- 四、总结
- 6. 选择微服务部署策略
- 一、诱因
- 二、单主机多服务实例模式
- 三、单主机单服务实例模式
- 单虚拟机单服务实例模式
- 单容器单服务实例模式
- 四、无服务器部署
- 总结
- 7. 将单体应用改造为微服务
- 本期内容
- 概述
- 策略一:停止挖坑
- 策略二:拆分前端和后端
- 策略三:提取微服务
- 为需要转化为微服务的模块设置优先级
- 如何提取模块
- 总结
- 附录
- 共享资源
作者介绍:Chris Richardson,是世界著名的软件大师,经典技术著作《POJOS IN ACTION》一书的作者,也是 cloudfoundry.com 最初的创始人,Chris Richardson 与 Martin Fowler、Sam Newman、Adrian Cockcroft 等并称为世界十大软件架构师。
来自 Nginx 官方博客:https://www.nginx.com/blog/introduction-to-microservices/
译文转载自daocloud:http://blog.daocloud.io/microservices-1/
5. 微服务的事件驱动数据管理
一、微服务以及分布式数据管理中存在的问题
单体应用通常使用单个关系型数据库,由此带来的好处在于应用能够使用 ACID 事务,后者提供了重要的操作特性:
- 原子性:原子粒度的更改
- 一致性:数据库的状态始终保持一致
- 隔离性:并发执行的事务显示为串行执行
- 持久性:事务一旦提交就不会被撤销
如此,应用能够简单地开始事务、更改(插入、更新和删除)多行、以及提交事务。
使用关系型数据库的另一大好处是它支持 SQL。SQL 是一门丰富、可声明的和标准化的查询预约。用户能够轻松通过查询将多个表中的数据组合起来,然后 RDBMS 查询调度器决定执行查询的最优方法。用户不必关心底层细节,比如如何访问数据库。此外,由于所有的应用数据在一个数据库中,很容易查询。
然而,微服务架构中的数据访问变得复杂许多。每个微服务拥有的数据专门用于该微服务,仅通过其 API 访问。这种数据封装保证了微服务松散耦合,并且可以独立更新。但如果多个服务访问相同数据,架构更新会耗费时间、也需要所有服务的协调更新。
更糟糕的是,不同的微服务通常使用不同类型的数据库。现代应用存储和处理各种类型的数据,而关系型数据库并非总是好选择。对于一些使用场景,特定的 NoSQL 数据库能提供更方便的数据模型、更好的性能和可扩展性。譬如,服务使用 Elasticsearch 这样的文本搜索引擎来存储和查询文本;同样地,存储社交图谱数据的服务可能需要使用 Neo4j 这样的图谱数据库。因此,基于微服务的应用通常会混合使用 SQL 和 NoSQL 数据库,即多语言留存(polyglot persistence approach)。
分区的、多语言留存的架构对于数据存储有很多好处,包括服务的松耦合、更好的性能和可扩展性。然而,它也确实给分布式数据管理带来了挑战。
第一个挑战就是如何实现业务逻辑,保持多种服务的一致性。为了说明为何这是一个问题,我们以在线 B2B 商店为例。Customer Service(下文使用客户服务)维护与用户有关的信息,包括信用信息。Order Service(下文使用订单服务)管理订单,验证新订单没有超出用户的信用额度。在单体应用里,订单服务可以简单地使用 ACID 事务来核对提供的信用信息和创建订单。
相反,在微服务架构中,如下图所示,订单表和客户表为各自对应的服务私有。
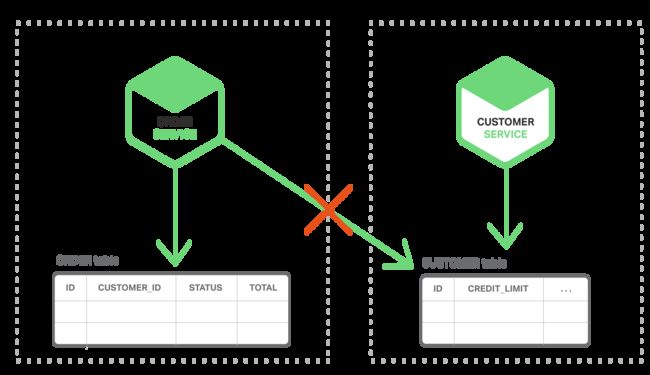
订单服务无法直接访问客户表,只能通过客户服务提供的 API。订购服务可能使用分布式事务,也被称为两步提交(2PC)。然而,2PC 通常不是现代应用的可行选项。CAP 定理需要用户在可用性和 ACID 风格的一致性中二选一,通常可用性是更好的选择。此外,许多现代技术,譬如大多数 NoSQL 数据库并不支持 2PC。维护整个服务和数据库中的数据一致性是至关重要的,因此我们需要另一种解决方案。
第二个挑战就是如何实现检索多个服务数据的查询。假设应用需要显示一位客户和他的最近的订单。如果订单服务为检索客户订单提供了 API,那么可以使用应用端获取该数据。应用通过客户服务检索该客户,通过订单服务检索该顾客的订单。但是假如订单服务只支持通过订单主键查询订单(可能使用仅支持键值检索的 NoSQL 数据库),这种情况下,就没有合适的方法来检索所需数据。
二、事件驱动的架构
对于许多应用,解决方案就是事件驱动的架构。在这一架构里,当有显著事件发生时,譬如更新业务实体,某个微服务会发布事件,其它微服务则订阅这些事件。当某一微服务接收到事件就可以更新自己的业务实体,实现更多事件被发布。
用户能够使用事件来实现跨多个服务的业务逻辑。事务由一系列步骤组成,每一步都有一个微服务更新业务实体,然后发布触发下一步的事件。下面的系列图展示了如何使用事件驱动的方法在创建订单时检查可用信用。微服务通过消息代理来交换事件。
- 订单服务创建状态为 NEW 的订单,并发布“订单已创建”事件。

- 客户服务获取“订单已创建”事件,为此订单保留信用,发布“信用保留”事件。

- 订单服务获取“信用保留”事件,把订单状态修改为 OPEN。

更为复杂的场景可能涉及更多的步骤,比如在核对客户信用的同时预留库存。
基于(a)每个服务自动更新数据库和发布事件,以及(b)消息代理确保事件传递至少一次,用户能够跨多个服务完成业务逻辑。注意它们并非 ACID 业务。这种模式提供弱确定性,比如最终一致性。这种事务模型也被称作 BASE 模型。
用户也可以使用事件来维护不同微服务拥有的预连接数据的物化视图。维护此视图的服务订阅相关事件,并更新视图。例如,维护客户订单视图的客户订单视图更新服务会订阅由客户服务和订单服务发布的事件。
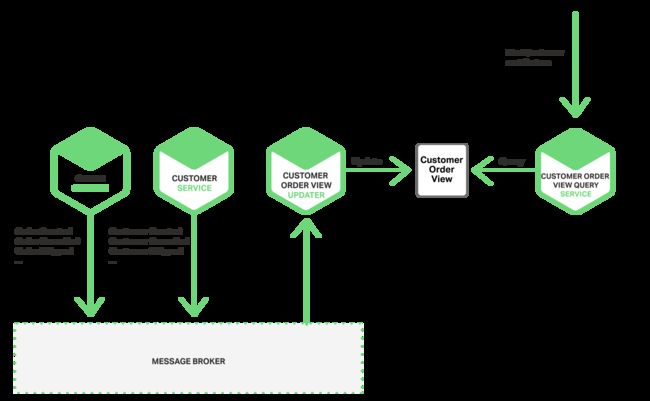
当客户订单查看更新服务收到客户或者订单事件,就会更新客户订单查看的数据存储。用户能够使用类似 MongoDB 的文档数据库查看用户订单,并为每位客户存储一个文档。用户订单预览查询服务通过客户订单预览数据存储,处理来自客户和最近订单的请求。
事件驱动的架构有优点也有缺点。它使得事务跨多个服务并提供最终一致性,也可以让应用维护物化视图。缺点之一在于,它的编程模型要比使用 ACID 事务的更加复杂。为了从应用级别的失效中恢复,还需要完成补偿性事务,例如,如果信用检查不成功则必须取消订单。此外,由于临时事务造成的改变显而易见,因而应用必须处理不一致的数据。此外,如果应用从物化视图中读取的数据没有更新时,也会遇到不一致的问题。此架构的另一缺点就是用户必须检测并忽略重复事件。
三、实现原子化
事件驱动的架构还存在以原子粒度更新数据库并发事件的问题。例如,订单服务必须在订单表中插入一行,然后发布“订单已创建”事件。这两个操作需要原子化实现。如果服务在更新数据库之后、发布事件之前崩溃,系统变得不一致。确保原子化的标准做法是使用包含数据库和消息代理的分布式事务。然而,基于以上描述的 CAP 理论,这并非我们所想。
使用本地事务发布事件
实现原子化的方法是使用多步骤进程来发布事件,该进程只包含本地事务。诀窍就是在存储业务实体状态的数据库中,有一个事件表来充当消息队列。应用启动一个(本地)数据库事务,更新业务实体的状态,在事件表中插入一个事件,并提交该事务。独立的应用线程或进程查询事件表,将事件发不到消息代理,然后使用本地事务标注事件并发布。下图展示了这一设计。
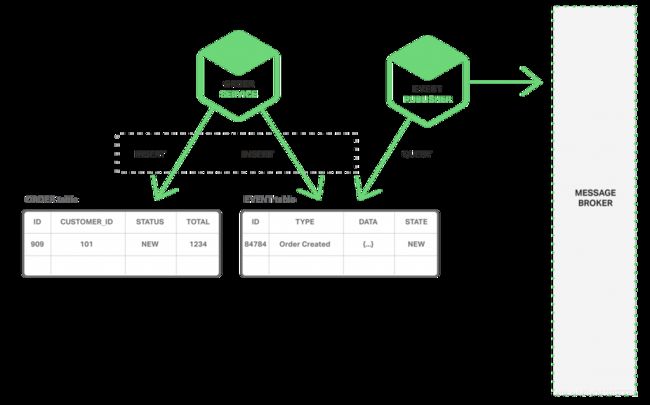
订单服务在订单表中插入一行,然后在事件表中插入“订单已创建”的事件。时间发布线程或进程在事件表中查询未发布的事件并发布,然后更新事件表,将该事件标记为已发布。
这种方法优缺点兼具。优点之一是保证每个更新都有对应的事件发布,并且无需依赖 2PC。此外,应用发布业务级别的事件,消除了推断事件的需要。这种方法也有缺点。由于开发者必须牢记发布事件,因此有很大可能出错。此外这一方法对于某些使用 NoSQL 数据库的应用是个挑战,因为 NoSQL 本身交易和查询能力有限。
通过此方法,应用使用本地事务来更新状态和发布事件,排除了对 2PC 的需要。接下来,我们了解使用应用更新状态实现原子化的方法。
挖掘数据库事务日志
无需 2PC 实现原子化的另一种方式是由线程或者进程通过挖掘数据库事务或提交日志来发布事件。应用更新数据库,数据库的事务日志记录这些变更。事务日志挖掘线程或进程读取这些日志,并把事件发布到消息代理。如下图所示:
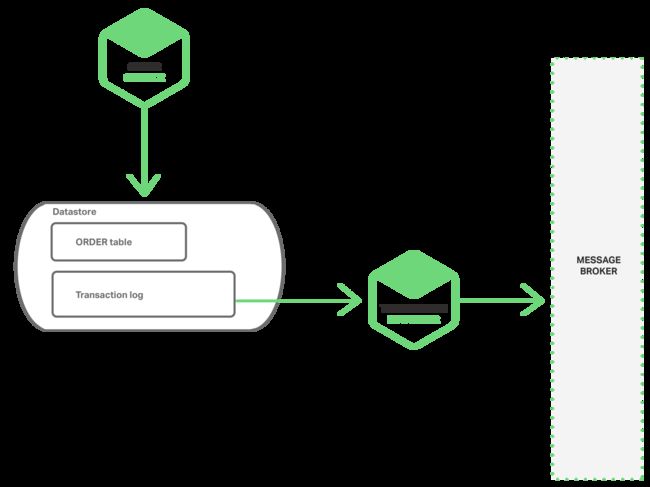
这一方法的范例是开源的 LinkedIn Databus 项目。Databus 挖掘 Oracle 事务日志并发布与之对应的事件。LinkedIn 使用 Databus 维持各种来源的数据存储与记录系统一致。
另一个范例则是 AWS DynamoDB 采用的流机制,AWS DynamoDB 是一个可管理的 NoSQL 数据库。每个 DynamoDB 流包括 DynamoDB 表在过去 24 小时之内的时序变化,包括创建、更新和删除操作。应用能够读取这些变更,将其作为事件发布。
事务日志挖掘具有多个优点。首先,它能保证无需使用 2PC 就能针对每个更新发布事件。其次,通过将日志发布于应用的业务逻辑分离,事务日志挖掘能够简化应用。事务日志挖掘也有缺点,主要缺点就是事务日志的格式与每个数据库对应,甚至随着数据库版本而变化。此外,很难从底层事务日志更新记录中逆向工程这些业务事件。
通过让应用更新数据库,事务日志挖掘消除了对 2PC 的需要。接下来我们会讨论另一种方法——消除更新,只依赖事件。
使用事件源
通过采用一种截然不同的、以事件为中心的方法来留存业务实体,事件源无需 2PC 实现了原子化。不同于存储实体的当前状态,应用存储状态改变的事件序列。应用通过重播事件来重构实体的当前状态。每当业务实体的状态改变,新事件就被附加到事件列表。鉴于保存事件是一个单一的操作,本质上也是原子化的。
要了解事件源如何运行,可以以订单实体为例。在传统的方法中,每个订单映射为订单表的一行,例如一个 ORDERLINEITEM 表。使用事件源的时候,订单服务以状态更改事件的方式存储订单,包括已创建、已批准、已发货、已取消等。每个事件都包含足够的数据去重建订单状态。

事件长期保存在事件数据库,使用 API 添加和检索实体的事件。事件存储类似上文提及的消息代理,通过 API 让服务订阅事件,将所有事件传达到所有感兴趣的订阅者。事件存储是事件驱动的微服务架构的支柱。
事件源有不少优点。它解决了实施事件驱动的微服务架构时的一个关键问题,能够只要状态改变就可靠地发布事件。另外,它也解决了微服务架构中的数据一致性问题。由于储存事件而不是域对象,它也避免了对象关系抗阻不匹配的问题(object‑relational impedance mismatch problem)。事件源提供了 100% 可靠的业务实体变化的审计日志,使得获取任何时间点的实体状态成为可能。事件源的另一大优势在于业务逻辑由松耦合的、事件交换的业务实体构成,便于从单体应用向微服务架构迁移。
事件源也有缺点。由于采用了不同或不熟悉的编程风格,会有学习曲线。事件存储只直接支持通过主键查询业务实体,用户还需要使用 Command Query Responsibility Segregation (CQRS) 来完成查询。因此,应用必须处理最终一致的数据。
四、总结
在微服务架构中,每个微服务都有其私有数据存储,不同的微服务可能使用不同的 SQL 和 NoSQL 数据库。这些数据库架构带来便利的同时,也给分布式数据管理带来挑战。第一个挑战就是如何实现业务事务,保持多个服务的一致性。第二个挑战就是如何从多个服务中检索数据,实现查询。
对于许多应用,解决方案就是使用事件驱动的架构。事件驱动的架构带来的挑战是如何原子化地更新状态和发布事件。有几个方法可以做到这一点,包括把数据库用作消息队列、事务日志挖掘和事件源。
原文
译文
6. 选择微服务部署策略
一、诱因
部署单体应用意味着运行大型应用的多个相同副本,通常提供若干台(N)服务器(物理机或虚拟机),在每台服务器上运行若干个(M)应用实例。部署单体应用并不总是简单明了,但还是比部署微服务应用简单。
微服务应用由几十甚至数百个服务组成。服务用不同的语言和框架写成,每个都是一个小应用,包括特定的部署、资源、扩展和监控需求,例如,根据服务需求运行若干数量的服务实例。此外,每个服务实例必须配套提供适当的 CPU、内存 和 I/O 资源。更具挑战性的是,尽管如此复杂,部署服务还必须快速、可靠和性价比高。
微服务部署模式有多个,先从单主机多个服务实例开始讲起。
二、单主机多服务实例模式
部署微服务的方法之一是使用单主机多服务实例模式。使用此模式,用户要提供一到多台物理或虚拟主机,在每个主机上运行多个服务实例。很多情况下,这是传统的应用部署方法。每个服务实例在一个或多个主机的已知端口上运行,主机通常被看做宠物。
下图展示了这一模式的结构。
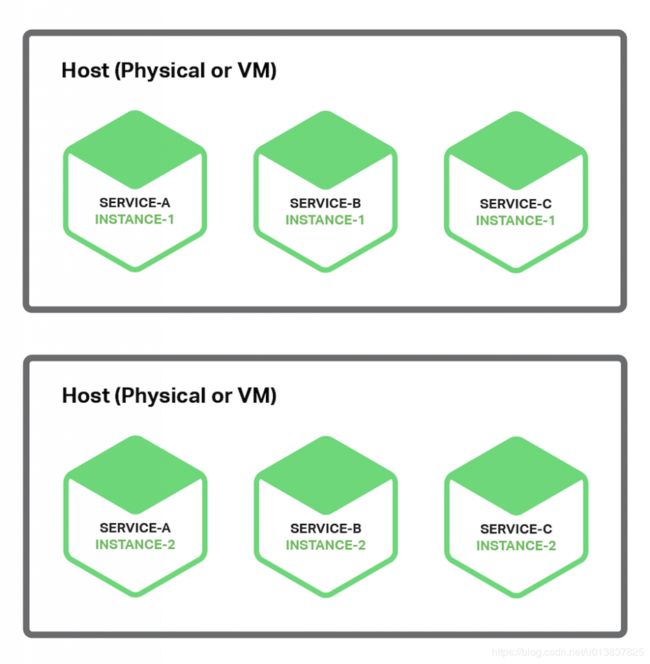
这一模式有几个变型。其中一个变型是服务实例作为进程或进程组。例如,在 Apache Tomcat 服务器上部署 Java 服务实例作为网页应用,Node.js 服务实例可能包括一个父进程和一个或多个子进程。
这一模式的另一个变型是在同一进程或进程组中运行多个服务实例。例如,在同一台 Apache Tomcat 服务器上部署多个 Java 网页应用,或者在同一个 OSGI 容器中运行多个 OSGI 捆绑组件。
单主机多服务实例模式有诸多优点。一个主要优点就是资源利用相对高效,多服务实例共享服务器及其操作系统。如果进程或进程组运行多个服务实例,效率更高,比如共享同一个 Apache Tomcat 服务器和 JVM 的多个网页应用。
这个模式的另一大优点是部署服务实例更快,只需将服务复制到主机并启动。如果服务用 Java 写成,复制 JAR 或者 WAR 文件;对于其它语言,如果是 Node.js 或者 Ruby,复制源代码。在这两种情况下,通过网络复制的字节数比较小。
此外,由于没有太多开销,启动服务通常很快。如果服务自包含进程,只需要启动。如果是运行在同一容器进程或进程组的服务实例,则需要动态部署到容器中,或者重启容器。
除了上述吸引力之外,单主机多服务实例模式也有一些显著缺点。主要缺点在于,除非每个服务实例是一个单独的进程,否则会甚少或者没有隔离。虽然能够准确监控每个服务实例的资源利用率,但是并不能限制每个实例使用的资源;很有可能一个异常的服务实例会消耗主机的所有内存和 CPU。
运行在同一进程的多个服务实例没有隔离,所有实例可能共享同一个 JVM 堆。出现异常的服务实例能够轻易中断运行在同一进程中的其它服务。此外,也无法监控每个服务使用的资源。
这种方法的另一显著问题是,部署服务的运维团队需要了解部署的具体细节。服务可能用各种语言和框架写成,因而开发团队必须与运维团队沟通诸多细节。这种复杂性增加了部署中出错的风险。
尽管单主机多服务实例模式颇为友好,但仍有显著缺点。接下来介绍其它的部署方式,能够避免这些缺点。
三、单主机单服务实例模式
部署微服务的另一种方法是单主机单服务实例模式。在此模式中,每台主机上运行独立的服务实例。这一模式有两种不同实现——单虚拟机单服务实例和单容器单服务实例。
单虚拟机单服务实例模式
使用单虚拟机单服务实例模式时,把每个服务大包围一个虚拟机镜像,类似 Amazon EC2 AMI。每个服务实例就是一台使用此镜像启动的虚拟机,譬如 EC2 实例。下图展示了此模式的结构。

这也是 Netflix 在部署视频流媒体服务时采用的主要方式。Netflix 使用 Aminator 把每个服务实例打包成 EC2 AMI,每个正在运行的服务实例就是一个 EC2 实例。
有多种工具可用来搭建自己的虚拟机。用户能够配置持续集成(CI)服务器(例如 Jenkins)来调用 Aminator,把服务打包为 EC2 AMI。Packer.io 是另一个自动化创建虚拟机镜像的工具。不同于 Aminator,它支持包括 EC2、DigitalOcean、VirtualBox 和 VMware 在内的多种虚拟化技术。
Boxfuse 这家公司使用令人信服的方式构建虚拟机镜像,克服了我上文描述的虚拟机的缺点。Boxfuse 把 Java 应用打包为一个最小的虚拟机镜像。这些镜像能够快速构建、启动,并且由于只暴露了有限的端口,也更安全。
CloudNative 提供 Bakery 这款 SaaS 工具来创建 EC2 AMI。用户的微服务通过测试,能够配置 CI 服务器来调用 Bakery,后者把服务打包为 AMI。使用 Bakery 这样的 SaaS 工具意味着你不需要浪费宝贵的时间来设置创建 AMI 的基础设施。
单虚拟机单服务实例有许多优点。一大好处就是每个服务实例完全隔离运行,每个实例都有固定的 CPU 和内存,不会被别的服务占用资源。
把微服务作为虚拟机部署的另一个优势就是能够充分利用成熟的云基础设施。AWS 这样的云服务提供了负载均衡和自动扩展这样实用的功能。
再一个优势就是封装了服务的实施技术。一旦服务被打包成虚拟机,就变成了黑盒,虚拟机的管理 API 成为部署该服务的 API。部署变得更简单可靠。
单虚拟机单服务实例模式也有缺点。缺点之一就是资源利用率低。每个服务实例占用包括操作系统在内的整个虚拟机的开销。此外,在典型的公有 IaaS,虚拟机资源固定,很难被充分利用。
此外,公有 IaaS 通常依据虚拟机数量收费,不考虑其繁忙与否。AWS 这类的 IaaS 提供了自动扩展,但是很难针对需求快速反应;因而很容易过度配置虚拟机,增加部署成本。
这种方法的另一个缺点是,部署服务的新版本通常很缓慢。由于体积较大,虚拟机镜像构建缓慢。同样,由于体积较大,虚拟机的实例化也比较缓慢。此外,操作系统也需要时间启动。然而,鉴于存在由 Boxfuse 构建的轻量级的虚拟机,这一规律也并非普遍适用。
单虚拟机单服务实例的另一个缺点就是,用户或组织中的其他人要负责大量无差别的沉重的工作。除非使用 Boxfuse 这样的工具来解决构建和管理虚拟机的开销,否则这种必要且耗时的工作会占用你处理核心业务的时间。
下面来了解另一种部署微服务的方法,它比虚拟机轻量,但具有其优点。
单容器单服务实例模式
使用单容器单服务实例模式,每个服务实例运行在自有容器中。容器是操作系统级别的虚拟化机制。每个容器包含一个或多个运行在沙盒中的进程。从进程的角度看,它们有着自己的端口命名空间和根文件系统。用户能够限制容器的内存和 CPU 资源,有些容器还能限制 I/O 速率。容器技术的代表包括 Docker 和 Solaris Zone。
下图显示了这种模式的结构:

使用这一模式时,用户将服务打包为容器镜像。每个容器镜像就是一个文件系统镜像,由应用和运行服务所需的库构成。有的容器镜像还包括完整的 Linux 根文件系统,有的则更轻量。以部署 Java 服务为例,构建的容器镜像包括 Java 运行时、Apache Tomcat 服务器、以及编译好的 Java 应用。
一旦将服务打包为容器镜像,就启动一到多个容器。通常每个物理机或虚拟主机上会运行多个容器,会用到 Kubernetes 或 Marathon 这样的集群管理工具来管理容器。集群管理工具把主机看做资源池,根据每个容器需要的资源和每个主机上可用的资源来调度容器。
单容器单服务实例模式有缺点兼备。容器的优点与虚拟机类似,服务实例之间完全隔离,也能轻松监控每个容器的资源消耗。此外,与虚拟机相似,容器能够封装执行服务的技术。容器管理 API 也可用作管理服务的 API。
不同于虚拟机,容器技术更为轻量,容器镜像构建速度更快。只用短短五秒就可以在笔记本电脑上把 Spring Boot 应用打包为 Docker 容器。由于没有冗长的操作系统启动机制,容器启动也非常迅速。容器启动,服务立刻运行。
使用容器也有一些缺点。虽然容器架构迅速成长,然而并不如虚拟机架构那般成熟。此外,由于容器之间共享主机操作系统的内核,因而也没有虚拟机安全。
容器的另一个缺点是,管理容器镜像是一项无差别的繁重工作。除非能使用 Google Container Engine 或 Amazon EC2 容器服务(ECS),否则需要同时管理容器基础设施和虚拟机基础设施。
此外,容器通常部署在以每台虚拟机定价的基础设施上,为了处理负载高峰,你可能会过度配置虚拟机,带来额外的成本。
有趣的是,容器和虚拟机之间的区别并非泾渭分明。如前文所述,Boxfuse 能够快速构建和启动虚拟机,Clear Container 项目则致力于创建轻量级的虚拟机,此外 unikernel 技术也引起大家注意。Docker 近期(注:2016 年 1 月 21 日)收购了 Unikernel Systems。
无服务器部署的概念也崭露头角,日渐流行。无服务器部署不需要选择将服务部署在容器还是服务器。
四、无服务器部署
AWS Lambda 就是无服务器部署的例子。它支持 Java、Node.js 和 Python 服务。要部署微服务,把服务打包为 ZIP 文件并上传到 AWS Lambda。用户也可以提供元数据,指定函数名称,后者被用于处理请求(即事件)。
Lambda 函数是无状态的服务,通过调用 AWS 服务处理请求。例如,当镜像被上传到 S3 存储桶,Lambda 函数被调用,在 DynamoDB 镜像中插入一项条目,并向 Kinesis 流发布消息,触发镜像处理。Lambda 函数也可以调用第三方网页服务。
有以下四种方法来调用 Lambda 函数:
- 直接调用,直接使用网页服务请求
- 自动调用,自动响应由 S3、DynamoDB、Knesis、或 Simple Email Service 等 AWS 服务生成的事件
- 自动调用,自动通过 AWS API 网关处理来自应用客户端的 HTTP 请求
- 定期调用,通过类似 Cron 的定时任务实现
可以看出,AWS Lambda 是部署微服务的便捷途径。基于请求的定价方式意味着用户只需要为服务实际运行的业务付费。此外,由于无需考虑 IT 基础设施,用户也能专注于应用开发。
然而,AWS Lambda 也有一些明显的局限。它并不适合被用来部署长期运行的服务,比如读取来自第三方消息代理的信息。请求需要在 300 秒内完成。由于 AWS Lambda 理论上能够针对每个请求运行单独的实例,因此服务必须保持无状态。此外,它们还必须用某一种支持的语言完成。服务也需要快速启动,然而有时候会有超时和停止。
总结
部署微服务应用充满挑战。几十个甚至上百个服务用不同的语言和框架写成,每个服务都是一个自带特定部署、资源、扩展和监控需求的微型应用。微服务部署的模式有多种,包括单虚拟机单服务实例和单容器单服务实例。另一个让人倍感兴趣的微服务部署方法则是 AWS Lambda,无服务器部署方案的代表。在本系列的最后一篇,我们将分析如何将单体应用迁移到微服务架构。
原文
译文
7. 将单体应用改造为微服务
本期内容
这一系列文章有助于读者更好地了解微服务架构及其优缺点,以及何时使用这一架构。微服务架构可能适合你的应用。
然而,你仍有很大可能去开发大型、复杂的单体应用,每天的开发和部署缓慢且痛苦。微服务看起来是遥远的「天堂」。幸运的是,你可以采用一些策略来摆脱单体应用的痛苦。在本篇文章中,我会介绍如何逐步把单体应用重构为微服务。
概述
将单体应用转变为微服务的过程也是将应用现代化的过程,数十年来开发者们一直致力于此。因此,当把应用重构为微服务的时候,我们可以借鉴其中的理念。
首先不要大规模地重写代码。大规模重写代码意味着你需要集中全部开发力量、从头构建全新的基于微服务的应用;听起来吸引人,但是充满风险,有可能以失败告终。正如 Martin Fowler 所言,“大规模重写唯一能够保证的只有大规模!”
相反,应当采取逐步重构单体应用的策略。逐步构建一个由微服务构成的应用,与单体应用并行运行;随着时间推移,原先由单体应用实现的功能不断收缩,最后或者完全消失,或者转变为微服务。这一方法虽然充满挑战,但风险远小于大规模重写代码。
Martin Fowler 将这一应用现代化的策略称为“杀手应用”。这一名称源自热带雨林中的杀手藤。杀手藤附生于树,直达树冠上方;树死后,留下树状的藤蔓。应用的现代化也是遵循这一模式。微服务构成的新应用围绕着遗留应用,后者最终完全不复存在。

接下来了解不同的实现策略。
策略一:停止挖坑
挖坑第一法则指出,如果发现自己掉坑里,马上停止。这一忠告也适用于难以管理的单体应用。换句话说,应该停止让单体应用继续变大,也就是在实现新功能的时候,不应该再增加代码。相反,这一策略的理念在于,把这部分新代码开发称为独立的微服务。下图展示了采用此方法的系统架构。

除了新服务和遗留应用,这个系统还包括另外两个组件。其一是请求路由,处理传入(HTTP)请求,与之前文章中描述的 API 网关类似。路由将与新功能对应的请求发送到新服务,将遗留请求发送到已有的单体应用。
另一组件是胶水代码(glue code),负责集成微服务与单体应用。微服务很少孤立存在,通常需要访问单体应用拥有的数据。胶水代码存在于单体应用或微服务中,或者两者兼有,负责数据集成。微服务使用胶水代码来读取和写入单体应用拥有的数据。
微服务可以通过以下三种方式访问单体应用的数据:
- 调用由单体应用提供的远程 API
- 直接访问单体应用的数据
- 维护一份数据拷贝,与单体应用的数据库保持同步
胶水代码也被称作防崩溃层(anti-corruption layer)。对于拥有自己全新领域模型的微服务,胶水代码能够阻止其受到遗留单体应用的领域模型的污染,并且为这两种模型提供转换。防崩溃层这一术语最早出现于 Eric Evans 撰写的必读书 Domain Driven Design 中,并被提炼成为白皮书。开发防崩溃层是项不平凡的工作,要想远离单体应用的泥淖,创建防崩溃层必不可少。
以轻量级微服务的方式实现新功能有诸多优点。它能够防止单体应用变得不可管理。微服务能够独立于单体服务进行开发、部署和扩展。采用微服务能让开发者切身感受其好处。
然而,这一方法并没有解决单体应用的问题。要想解决这些问题,需要分解单体应用。
策略二:拆分前端和后端
缩小单体应用的策略之一是将表示层(presentation layer)与业务逻辑和数据访问层分离。典型的企业应用包括至少三类组件:
- 表示层:处理 HTTP 请求并实现 (REST)API 或基于 HTML 的 Web UI。对于包含复杂用户接口的应用,表示层往往是代码的实体部分。
- 业务逻辑层:应用的核心,实现业务逻辑
- 数据访问层:访问诸如数据库和消息代理这样的基础架构组件
在表示逻辑与业务和数据访问逻辑之间,有着清晰的间隔。业务层的粗粒度的 API 由若干方面组成,内部封装业务逻辑组件。这个 API 是一道天然分界线,将单体应用分割成两个较小的应用。一个应用包含表示层,另一个应用包含业务和数据访问逻辑。拆分后,表示逻辑应用对业务逻辑应用远程调用。下图展示了重构前后的构架。
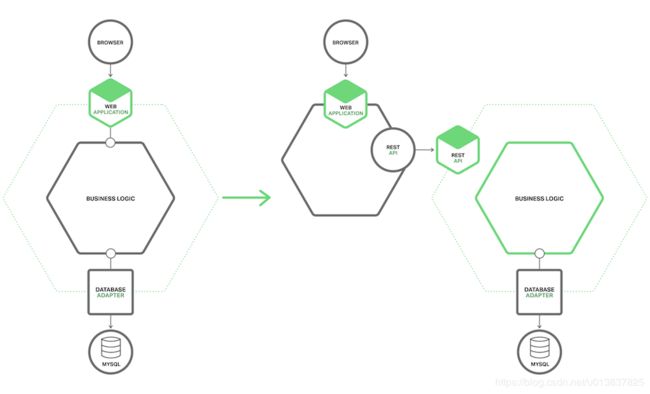
以这种方式切割单体应用有两大好处。首先,它使得这两个应用的开发、部署和扩展用各自独立。尤其是,它使得表示层的开发人员能够快速迭代用户接口,轻松进行 A|B 测试。其次,它暴露了远程 API,能够被微服务调用。
这种策略也只是部分解决方案,很有可能其中一个应用或两个应用变成难以管理的单体应用。这时需要使用第三种策略来消除剩余的单体应用。
策略三:提取微服务
第三种重构策略是将单体应用内现有的模块转变为独立的微服务。每当提取模块并将其转化为服务,单体应用就会收缩。一旦转化了足够的模块,单体应用也不再是问题,它或者彻底消失,或者小到成为另一个微服务。
为需要转化为微服务的模块设置优先级
大型、复杂的单体应用由数十甚至数百个模块组成,每个都是提取的对象。要弄清楚哪些模块首先被转化,往往具有挑战性。从易于提取的模块开始是个好方法,它能让开发者熟悉微服务和提取过程。然后就应该转化能从中获益最多的模块。
鉴于把模块转变为微服务非常耗时,一般会根据获益程度来给模块排序。从频繁更改的模块开始会让用户收获不菲。一旦把模块转化为微服务,也就能独立开发和部署,从而加速开发进度。
将资源需求大不相同的模块优先转化,也颇有好处。例如,把内存数据库模块转化为微服务,能够被部署在大内存主机上。同样,将实现计算算法的模块提取出来也是非常值得,这一微服务能够部署在拥有大量 CPU 的主机上。通过将对资源有着特殊需求的模块转变为微服务,应用能够易于扩展。
找出哪些模块需要优先提取后,找出现有粗粒度的边界(即分界线)也大有裨益。这些边界让模块转变为微服务更加简单、省力。例如,通过异步消息与应用的其它部分通信的模块能够相对省力、简便地转化为微服务。
如何提取模块
模块提取的第一步是定义模块和单体应用间的粒度接口。由于单体应用和微服务互相需要对方拥有的数据,因此更像是双向 API。由于模块和应用其它部分之间存在着互相依赖和细粒度的交互模型,因此实现这样的 API 充满挑战。对于重构微服务,通过领域模型实现的业务逻辑尤为挑战,开发人员需要大刀阔斧地修改代码来打破这些依赖。
粗粒度接口一旦完成,模块也就变成了独立的微服务。要做到这一点,开发人员必须编写代码,能够让单体应用和微服务通过 API 通信,API 使用进程间通信(IPC)机制。 下图展示了重构前、重构中和重构后的不同架构。
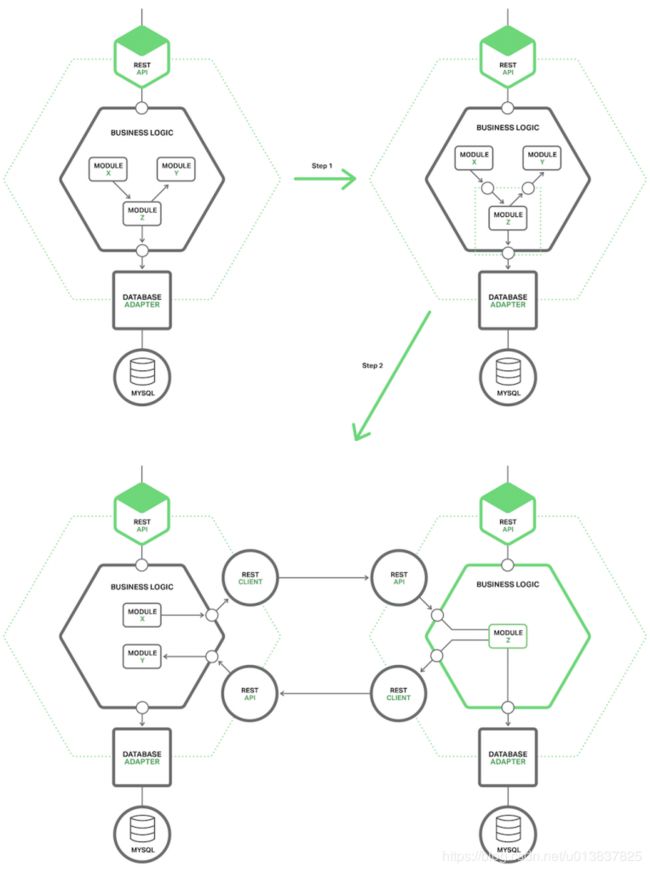
在图片中,模块 Z 将要被重构,它用到了模块 Y 的组件,同时它的组件被模块 X 使用。重构的第一步就是定义一对粗粒度 API。第一个接口是模块 X 使用的对内接口,用来唤醒模块 Z。第二个接口是模块 Z 使用的对外接口,唤醒模块 Y。
重构的第二步则是把模块转变为独立的微服务。对内和对外接口通过 IPC 机制的代码实现,开发人员可能只需要将模块 Z 与微服务支撑框架(Microservice Chassis framework)组合起来构建微服务。微服务支撑框架处理与割接相关的问题,比如服务发现。
一旦将模块提取完毕,相当于得到一个微服务,能够独立于单体应用和其它微服务进行开发、部署和扩展。如果要从头重写微服务代码,集成微服务和单体应用的 API 代码会成为这两个领域模型之间的防崩溃层。每重构一个组件,就向着微服务的方向又迈进了一步。随着时间推移,单体应用逐渐消失,微服务则越来越多。
总结
将现有单体应用迁移到微服务架构是应用的现代化。实现这一结果并不需要从头重写代码,相反,只需要渐进式地将应用重构为一组微服务。其中有三种策略可以采纳:使用微服务实现新功能、将表示组件与业务和数据访问组件拆分、以及将现有应用内的模块转变为微服务。随着时间推移,大量微服务形成,团队的敏捷和效率也会提升。
原文
译文
附录
http://www.gaoxuan1989.com/2017/07/27/refactoring-a-monolith-into-microservices/
https://insights.thoughtworks.cn/serverless-microservices-architecture-case/
https://martinfowler.com/articles/microservices.html
http://blog.cuicc.com/blog/2015/07/22/microservices/
https://mp.weixin.qq.com/s?__biz=MjM5MjEwNTEzOQ==&mid=401500724&idx=1&sn=4e42fa2ffcd5732ae044fe6a387a1cc3#rd
共享资源
http://note.youdao.com/noteshare?id=a089ca7438f2f589c938dc72b86e44a4