NG机器学习总结-(五)正则化 Regularization
一、过拟合问题
在解释什么是过拟合问题之前,首先还是以房价预测为例。假设这里我们用三种不同的模型去拟合数据集,如下图三种情况:

从第一张图看,我们发现我们是用一条直线去拟合数据,但是这样的拟合效果并不好。从数据中,很明显随着房子面积的增大,房价的变化趋于稳定或者说越往后变化越平缓。这种情况属于模型并没有很好的拟合数据,我们称这种情况为欠拟合(underfitting)或者叫做高偏差。
从第二张图看,我们用的是一个二次函数模型去拟合数据,发现这样的二次曲线拟合数据的效果很好(just right)。
从第三张图看,我们用一个四次多项式模型去拟合数据,虽然它将数据集中所有的数据都拟合到没有差别,但是这样的模型对一个新的数据来说就有可能失去了有效性,我们称这种情况为过拟合(overfitting)或者叫做高方差。
所以过拟合问题会出现在:当我们数据集中有很多的特征时,虽然有时候我们的假设模型能够很好拟合训练集(也就是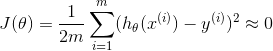 ),但是这样的模型可能并不能泛化到新的样本数据中去,所以并不能很好的预测新样本数据。当然这里的过拟合问题同样出现在逻辑回归中,如下图。
),但是这样的模型可能并不能泛化到新的样本数据中去,所以并不能很好的预测新样本数据。当然这里的过拟合问题同样出现在逻辑回归中,如下图。
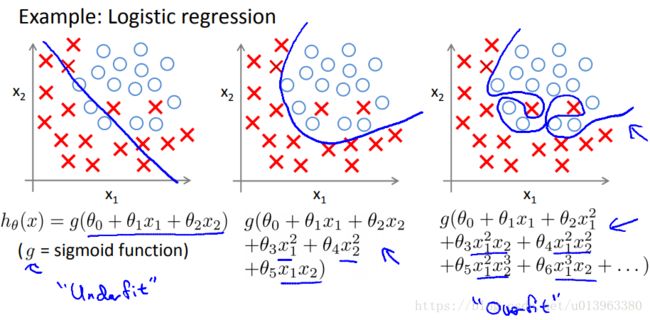
那么,如果发生了过拟合问题,我们应该怎么去处理?上面我们说到过多的特征,同时训练集的数据有限的时候,会导致过拟合问题,因此解决过拟合问题,一般有以下两个办法:
1.减少特征的数量
----人工手动挑选,保留重要的特征
----模型选择算法,这些算法会自动选择特征变量(暂不介绍)
2.正则化
----保留所有的特征变量,但是会适当减小特征变量的数量级(减小不重要特征的影响)
二、损失函数
正则化可以解决过拟合的问题,但是正则化到底怎么体现呢?
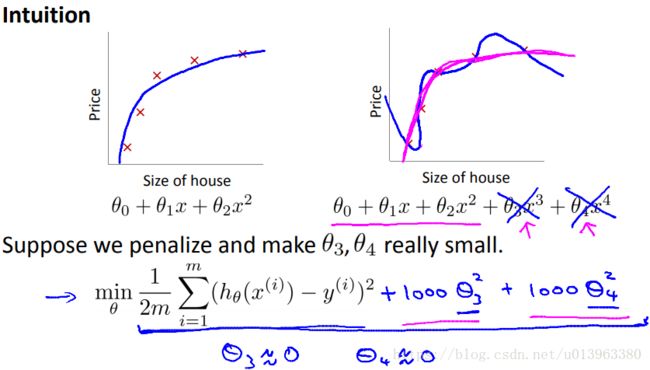
左右两个模型分别是二次函数模型和多项式模型来拟合数据集的结果,我们知道多项式模型发生了过拟合的问题,这个时候如果我们再多项式模型上加上惩罚项,使得参数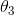 和
和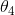 足够的小,那么多项式模型就会像二次函数模型一样了。比如上式中损失函数,我们加了两个惩罚项
足够的小,那么多项式模型就会像二次函数模型一样了。比如上式中损失函数,我们加了两个惩罚项![]() 和
和![]() ,这样的损失函数的值将会变的很大,当然,当我们在优化这个损失函数的时候,我们将会使得和的值接近于0,等同于我们忽略了这个参数一样,如果做到这一点,那么该多项式模型就会近似二次函数。
,这样的损失函数的值将会变的很大,当然,当我们在优化这个损失函数的时候,我们将会使得和的值接近于0,等同于我们忽略了这个参数一样,如果做到这一点,那么该多项式模型就会近似二次函数。
因此,我们这里可以得出正则化的一般思路:当模型中的特征参数对应一个较小的取值时,那么我们往往会得到一个形式更简单的模型(其中换种思路,就相当于其对应的特征不重要,特征的选择过程)。因此,当我们的特征有很多的时候,而我们并不知道如何选择关联更好的特征参数,如何减小参数的数目,在正则化中,我们要做的事情就是在模型的损失函数中加入参数项,如下图,这里的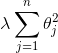 就是正则化项,
就是正则化项, 称为正则化参数(惩罚项系数)。
称为正则化参数(惩罚项系数)。
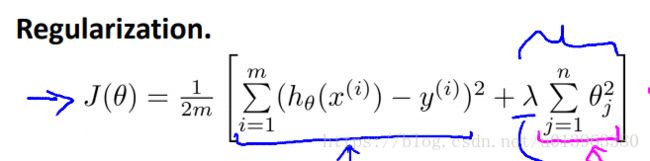
正则化参数平衡拟合训练数据的目标和保持参数值较小的目标。从而来保持假设的形式相对简单,来避免过度的拟合。如果这里的正则化参数取值很大的时候会出现什么情况呢?如下图:
我们将会非常大地惩罚参数θ1 θ2 θ3 θ4 … 也就是说,我们最终惩罚θ1 θ2 θ3 θ4 … 在一个非常大的程度,那么我们会使所有这些参数接近于零。

如果我们这么做,那么就是我们的假设中相当于去掉了这些项,并且使我们只是留下了一个简单的假设,这个假设只能表明房屋价格等于 θ0 的值,那就是类似于拟合了一条水平直线,对于数据来说这就是一个欠拟合 (underfitting)。这种情况下这一假设它是条失败的直线,对于训练集来说这只是一条平滑直线,它没有任何趋势,它不会去趋向大部分训练样本的任何值。因此当正则化参数取值很大的时候,会出现如下这些问题:

因此,为了使正则化运作良好,我们应当注意一些方面,应该去选择一个不错的正则化参数 。当我们以后讲到多重选择时我们将讨论一种方法来自动选择正则化参数 ,为了使用正则化,接下来我们将把这些概念应用到到线性回归和逻辑回归中去,那么我们就可以让他们避免过度拟合了。
三、正则线性回归
线性回归的损失函数如下:
加上了正则化项:

![J(\theta)=\frac{1}{2m}\left [ \sum_{i=1}^{m}(h_{\theta}(x^{(i)}-y^{(i)})^{2} + \lambda \sum_{j=1}^{n}\theta_{j}^{2} \right ]](http://img.e-com-net.com/image/info8/11883315d32b4432bfaa21a9816599dd.gif)
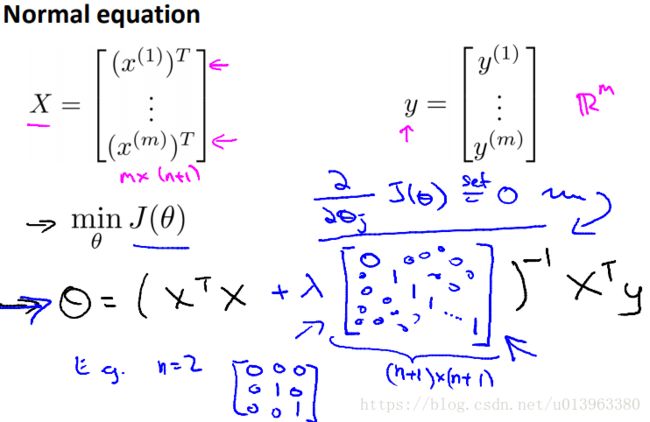
然后根据梯度下降算法:

对于标准方程来说,当然前提是中间的矩阵可逆,建议加上正则化手推一遍。
四、正则逻辑回归
逻辑回归的损失函数如下:
加上正则化项:
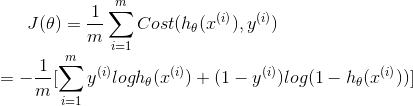
![J(\theta)==-\frac{1}{m}[\sum_{i=1}^{m}y^{(i)}logh_{\theta}(x^{(i)})+(1-y^{(i)})log(1-h_{\theta}(x^{(i)}))]+\frac{\lambda }{2m}\sum_{j=1}^{n}\theta_{j}^{2}](http://img.e-com-net.com/image/info8/5cab7e4531444711b1e97b927564cd29.gif)
梯度下降算法求解:

TIPS:有关正则化项的问题,其实有很多的知识,比如选择不同正则化项,L1范数,L2范数等,NG视频没有涉及这些,只是方便初学者大致了解过拟合怎么样用正则化来解决。